reference resources Training image classifier
introduce
The image classification model has millions of parameters. Training from scratch requires a lot of labeled training data and a lot of computing power. Transfer learning is a skill that greatly simplifies the process by adopting a model that has been trained on related tasks and reusing it in a new model.
This paper demonstrates how to extract five kinds of features from the generic image set of kingsflow through the pre training of kingsflow. Alternatively, the feature extractor can be trained ("fine tuned") with the newly added classifier.
Looking for tools?
This is a TensorFlow coding tutorial. If you want a tool that can only be used to build TensorFlow or TF Lite models for it, please check the make tool installed by the PIP package TensorFlow hub [make_image_classifier]_ image_ Classifier command line tool, or view it in this TF Lite collaboration lab.
Setup settings
import itertools
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
print("TF version:", tf.__version__)
print("Hub version:", hub.__version__)
print("GPU is", "available" if tf.test.is_gpu_available() else "NOT AVAILABLE")
TF version: 2.4.1
Hub version: 0.11.0
WARNING:tensorflow:From <ipython-input-1-0831fa394ed3>:12: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
GPU is available
Select the TF2 SavedModel module to use
For beginners, please use https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v2_100_224/feature_vector/4 . You can use the same URL in your code to identify the SavedModel and use the same URL in your browser to display its documents. (note that the model of TF1 Hub format does not work here.)
You can here Find more TF2 models that generate image feature vectors.
There are many possible models to try. All you need to do is select a different in the cells below and continue using the notebook.
model_name = "mobilenet_v3_small_100_224" # @param ['bit_s-r50x1', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'inception_v3', 'inception_resnet_v2', 'mobilenet_v2_100_224', 'mobilenet_v2_130_224', 'mobilenet_v2_140_224', 'mobilenet_v3_large_100_224', 'mobilenet_v3_large_075_224', 'mobilenet_v3_small_100_224', 'mobilenet_v3_small_075_224', 'nasnet_large', 'nasnet_mobile', 'pnasnet_large', 'resnet_v1_50', 'resnet_v1_101', 'resnet_v1_152', 'resnet_v2_50', 'resnet_v2_101', 'resnet_v2_152']
model_handle_map = {
"efficientnet_b0": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b0/feature-vector/1",
"efficientnet_b1": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b1/feature-vector/1",
"efficientnet_b2": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b2/feature-vector/1",
"efficientnet_b3": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b3/feature-vector/1",
"efficientnet_b4": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b4/feature-vector/1",
"efficientnet_b5": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b5/feature-vector/1",
"efficientnet_b6": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b6/feature-vector/1",
"efficientnet_b7": "https://hub.tensorflow.google.cn/tensorflow/efficientnet/b7/feature-vector/1",
"bit_s-r50x1": "https://hub.tensorflow.google.cn/google/bit/s-r50x1/1",
"inception_v3": "https://hub.tensorflow.google.cn/google/imagenet/inception_v3/feature-vector/4",
"inception_resnet_v2": "https://hub.tensorflow.google.cn/google/imagenet/inception_resnet_v2/feature-vector/4",
"resnet_v1_50": "https://hub.tensorflow.google.cn/google/imagenet/resnet_v1_50/feature-vector/4",
"resnet_v1_101": "https://hub.tensorflow.google.cn/google/imagenet/resnet_v1_101/feature-vector/4",
"resnet_v1_152": "https://hub.tensorflow.google.cn/google/imagenet/resnet_v1_152/feature-vector/4",
"resnet_v2_50": "https://hub.tensorflow.google.cn/google/imagenet/resnet_v2_50/feature-vector/4",
"resnet_v2_101": "https://hub.tensorflow.google.cn/google/imagenet/resnet_v2_101/feature-vector/4",
"resnet_v2_152": "https://hub.tensorflow.google.cn/google/imagenet/resnet_v2_152/feature-vector/4",
"nasnet_large": "https://hub.tensorflow.google.cn/google/imagenet/nasnet_large/feature_vector/4",
"nasnet_mobile": "https://hub.tensorflow.google.cn/google/imagenet/nasnet_mobile/feature_vector/4",
"pnasnet_large": "https://hub.tensorflow.google.cn/google/imagenet/pnasnet_large/feature_vector/4",
"mobilenet_v2_100_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v2_100_224/feature_vector/4",
"mobilenet_v2_130_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v2_130_224/feature_vector/4",
"mobilenet_v2_140_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v2_140_224/feature_vector/4",
"mobilenet_v3_small_100_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v3_small_100_224/feature_vector/5",
"mobilenet_v3_small_075_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v3_small_075_224/feature_vector/5",
"mobilenet_v3_large_100_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v3_large_100_224/feature_vector/5",
"mobilenet_v3_large_075_224": "https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v3_large_075_224/feature_vector/5",
}
model_image_size_map = {
"efficientnet_b0": 224,
"efficientnet_b1": 240,
"efficientnet_b2": 260,
"efficientnet_b3": 300,
"efficientnet_b4": 380,
"efficientnet_b5": 456,
"efficientnet_b6": 528,
"efficientnet_b7": 600,
"inception_v3": 299,
"inception_resnet_v2": 299,
"nasnet_large": 331,
"pnasnet_large": 331,
}
model_handle = model_handle_map.get(model_name)
pixels = model_image_size_map.get(model_name, 224)
print(f"Selected model: {model_name} : {model_handle}")
IMAGE_SIZE = (pixels, pixels)
print(f"Input size {IMAGE_SIZE}")
BATCH_SIZE = 32
Selected model: mobilenet_v3_small_100_224 : https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v3_small_100_224/feature_vector/5 Input size (224, 224)
Set up flower dataset
The input will be adjusted according to the size of the selected module. Data set enhancement (that is, random distortions occur every time the image is read) can improve the training effect, especially. When fine tuning.
data_dir = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 14s 0us/step
datagen_kwargs = dict(rescale=1./255, validation_split=.20)
dataflow_kwargs = dict(target_size=IMAGE_SIZE, batch_size=BATCH_SIZE,
interpolation="bilinear")
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
**datagen_kwargs)
valid_generator = valid_datagen.flow_from_directory(
data_dir, subset="validation", shuffle=False, **dataflow_kwargs)
do_data_augmentation = False
if do_data_augmentation:
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=40,
horizontal_flip=True,
width_shift_range=0.2, height_shift_range=0.2,
shear_range=0.2, zoom_range=0.2,
**datagen_kwargs)
else:
train_datagen = valid_datagen
train_generator = train_datagen.flow_from_directory(
data_dir, subset="training", shuffle=True, **dataflow_kwargs)
Found 731 images belonging to 5 classes. Found 2939 images belonging to 5 classes.
Define model
All you have to do is feature_extractor_layer places a linear classifier on the top of the Hub module.
In order to improve speed, we never train features_ extractor_ Layer starts, but you can also enable fine tuning to improve accuracy.
do_fine_tuning = False
Do not use fine_tuning
model structure model: tf.keras.layers.InputLayer hub.KerasLayer Dropout Dense model.build((None,)+IMAGE_SIZE+(3,))
print("Building model with", model_handle)
model = tf.keras.Sequential([
# Explicitly define the input shape so the model can be properly
#Explicitly define the input shape so that the model can run correctly
# loaded by the TFLiteConverter
tf.keras.layers.InputLayer(input_shape=IMAGE_SIZE + (3,)),
hub.KerasLayer(model_handle, trainable=do_fine_tuning),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(train_generator.num_classes,
kernel_regularizer=tf.keras.regularizers.l2(0.0001))
])
model.build((None,)+IMAGE_SIZE+(3,))
model.summary()
Building model with https://hub.tensorflow.google.cn/google/imagenet/mobilenet_v3_small_100_224/feature_vector/5 Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1024) 1529968 _________________________________________________________________ dropout (Dropout) (None, 1024) 0 _________________________________________________________________ dense (Dense) (None, 5) 5125 ================================================================= Total params: 1,535,093 Trainable params: 5,125 Non-trainable params: 1,529,968 _________________________________________________________________
Training model
model.compile( optimizer=tf.keras.optimizers.SGD(lr=0.005, momentum=0.9), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True, label_smoothing=0.1), metrics=['accuracy'])
steps_per_epoch = train_generator.samples // train_generator.batch_size
validation_steps = valid_generator.samples // valid_generator.batch_size
hist = model.fit(
train_generator,
epochs=5, steps_per_epoch=steps_per_epoch,
validation_data=valid_generator,
validation_steps=validation_steps).history
For each round of training of the generator, how many steps, that is, how many batches_ size
steps_per_epoch = samples divided by batch_size
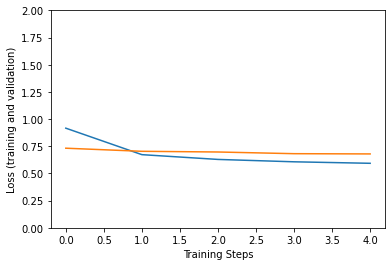
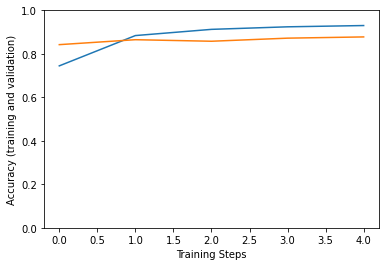
Epoch 1/5 91/91 [==============================] - 30s 174ms/step - loss: 1.1899 - accuracy: 0.5899 - val_loss: 0.7321 - val_accuracy: 0.8423 Epoch 2/5 91/91 [==============================] - 15s 160ms/step - loss: 0.6630 - accuracy: 0.8935 - val_loss: 0.7036 - val_accuracy: 0.8651 Epoch 3/5 91/91 [==============================] - 14s 158ms/step - loss: 0.6405 - accuracy: 0.9095 - val_loss: 0.6973 - val_accuracy: 0.8580 Epoch 4/5 91/91 [==============================] - 15s 160ms/step - loss: 0.6143 - accuracy: 0.9156 - val_loss: 0.6817 - val_accuracy: 0.8722 Epoch 5/5 91/91 [==============================] - 15s 160ms/step - loss: 0.5917 - accuracy: 0.9323 - val_loss: 0.6795 - val_accuracy: 0.8778
Draw a picture
plt.figure()
plt.ylabel("Loss (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(hist["loss"])
plt.plot(hist["val_loss"])
plt.figure()
plt.ylabel("Accuracy (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(hist["accuracy"])
plt.plot(hist["val_accuracy"])
[<matplotlib.lines.Line2D at 0x7f0f2030b198>]
Test the model on the image from the validation data:
Perform steps
Define string and index Converted function next ,from valid_Generator Get a sample from x,y x,y Remove dimension display plt.imshow() model.predict forecast(image To expand a dimension) Get maximum label index =np.argmax Carry string string and index Conversion of
# This is an incoming index, that is, the maximum label index of the prediction vector, to obtain the class_ Function of index string
# valid_generator.class_indices.items() is a dictionary with correspondence between string and index
def get_class_string_from_index(index):
for class_string, class_index in valid_generator.class_indices.items():
if class_index == index:
return class_string
x, y = next(valid_generator)
image = x[0, :, :, :]
true_index = np.argmax(y[0])
plt.imshow(image)
plt.axis('off')
plt.show()
# Expand the validation image to (1, 224, 224, 3) before predicting the label
prediction_scores = model.predict(np.expand_dims(image, axis=0))
predicted_index = np.argmax(prediction_scores)
print("True label: " + get_class_string_from_index(true_index))
print("Predicted label: " + get_class_string_from_index(predicted_index))

True label: daisy Predicted label: daisy
Finally, the trained model can be saved for deployment to TF Serving or TF Lite (on mobile devices), as shown below.
saved_model_path = f"/tmp/saved_flowers_model_{model_name}"
tf.saved_model.save(model, saved_model_path)
INFO:tensorflow:Assets written to: /tmp/saved_flowers_model_mobilenet_v3_small_100_224/assets INFO:tensorflow:Assets written to: /tmp/saved_flowers_model_mobilenet_v3_small_100_224/assets
Optional: deploy to TensorFlow Lite
TensorFlow Lite Enables you to deploy TensorFlow models to mobile and IoT devices. The following code shows how to convert the trained model into TF Lite and apply it TensorFlow Model Optimization Toolkit Post training tools in. Finally, it runs in the TF Lite interpreter to check the final quality
- The conversion can be carried out without optimization, and the result is the same as before (maximum rounding error).
- When the neural network is optimized, it will still be used to convert the weight of 8-bit to floating-point data, but it will not be used to calculate the weight. This reduces the model size by nearly four times and improves CPU latency on mobile devices.
- Most importantly, if a small reference data set is provided to calibrate the quantization range, the calculation of neural network activation can also be quantified as an 8-bit integer. On mobile devices, this can further speed up reasoning and enable it to run on accelerators such as EdgeTPU.
Optimize settings
optimize_lite_model = False
num_calibration_examples = 60
representative_dataset = None
if optimize_lite_model and num_calibration_examples:
# Use a bounded number of training examples without labels for calibration.
# TFLiteConverter expects a list of input tensors, each with batch size 1.
representative_dataset = lambda: itertools.islice(
([image[None, ...]] for batch, _ in train_generator for image in batch),
num_calibration_examples)
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)
if optimize_lite_model:
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if representative_dataset: # This is optional, see above.
converter.representative_dataset = representative_dataset
lite_model_content = converter.convert()
with open(f"/tmp/lite_flowers_model_{model_name}.tflite", "wb") as f:
f.write(lite_model_content)
print("Wrote %sTFLite model of %d bytes." %
("optimized " if optimize_lite_model else "", len(lite_model_content)))
Wrote TFLite model of 6097236 bytes.
interpreter = tf.lite.Interpreter(model_content=lite_model_content) # This little helper wraps the TF Lite interpreter as a numpy-to-numpy function. def lite_model(images): interpreter.allocate_tensors() interpreter.set_tensor(interpreter.get_input_details()[0]['index'], images) interpreter.invoke() return interpreter.get_tensor(interpreter.get_output_details()[0]['index'])
num_eval_examples = 50
eval_dataset = ((image, label) # TFLite expects batch size 1.
for batch in train_generator
for (image, label) in zip(*batch))
count = 0
count_lite_tf_agree = 0
count_lite_correct = 0
for image, label in eval_dataset:
probs_lite = lite_model(image[None, ...])[0]
probs_tf = model(image[None, ...]).numpy()[0]
y_lite = np.argmax(probs_lite)
y_tf = np.argmax(probs_tf)
y_true = np.argmax(label)
count +=1
if y_lite == y_tf: count_lite_tf_agree += 1
if y_lite == y_true: count_lite_correct += 1
if count >= num_eval_examples: break
print("TF Lite model agrees with original model on %d of %d examples (%g%%)." %
(count_lite_tf_agree, count, 100.0 * count_lite_tf_agree / count))
print("TF Lite model is accurate on %d of %d examples (%g%%)." %
(count_lite_correct, count, 100.0 * count_lite_correct / count))
TF Lite model agrees with original model on 50 of 50 examples (100%). TF Lite model is accurate on 47 of 50 examples (94%).
summary
From two dictionaries model_handle_map :get model of hub address model_image_size_map:Get the input corresponding to the model image_size of pixels get ready IMAGE_SIZE= (pixels, pixels) ,BATCH_SIZE = 32 --- Create parameter transfer dictionary datagen_kwargs ,dataflow_kwargs use**datagen_kwargs,**dataflow_kwargs Pass it in Get data tf.keras.utils.get_file() Read picture tf.keras.preprocessing.image.ImageDataGenerator(**datagen_kwargs) valid_datagen.flow_from_directory(**dataflow_kwargs) Picture builder has properties num_class train_generator.num_classes steps_per_epoch = train_generator.samples // train_generator.batch_size validation_steps = valid_generator.samples // valid_generator.batch_size hist = model.fit( steps_per_epoch #How many steps per round History directly gets the list of history records Save model tf.saved_model.save(model,saved_model_path)