This is an interview question a few years ago. The answers on the Internet are generally
1. execute can only submit tasks of Runnable type with no return value. Submit can submit both Runnable and Callable tasks and return Future type.
2. The task exception submitted by the execute method is thrown directly, while the submit method captures the exception. The exception will be thrown only when the get method of FutureTask is called.
We may have seen n times but forgot to add n once more, so how can we fully understand and remember the difference between the two? This starts from the root of ThreadPoolExecutor. What is the root? It is the inheritance system in the following figure:
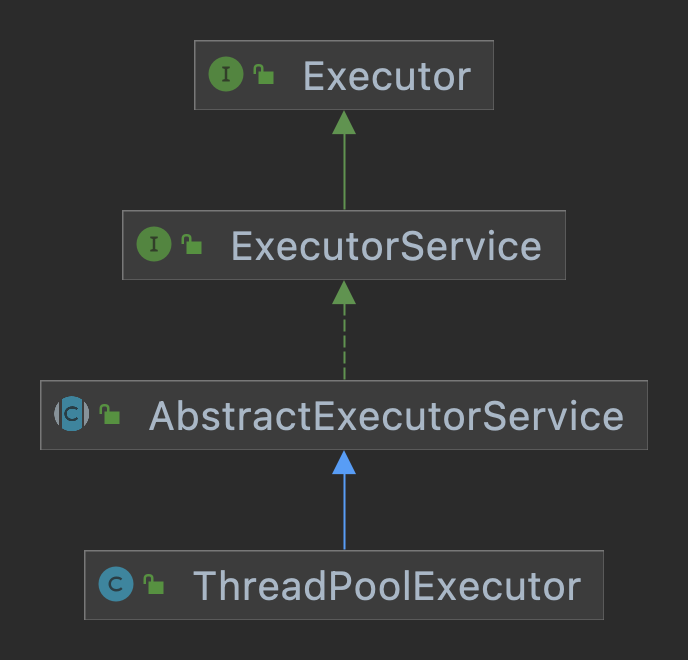
You can see that there are two interfaces at the root of ThreadPoolExecutor, namely Executor and ExecutorService. The methods in the interface are as follows:

You can clearly see the first difference between execute and submit from the figure,
execute is the method of the Executor interface, submit is the method of the ExecutorService, and the ExecutorService interface inherits the Executor interface.
Next, we will analyze these four classes in turn.
Executor
The Executor interface source code is pasted below. There are many comments on the source code, and the example part is deleted.
/**
* An object that executes submitted {@link Runnable} tasks. This
* interface provides a way of decoupling task submission from the
* mechanics of how each task will be run, including details of thread
* use, scheduling, etc. An {@code Executor} is normally used
* instead of explicitly creating threads.
*
* @since 1.5
* @author Doug Lea
*/
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
As can be seen from the class annotation, the function is to decouple task submission and task execution. For example, when executing a Runnable task, you may use
new Thread(new(RunnableTask())).start()
After using the Executor, you can write like this
Executor executor = anExecutor; executor.execute(new RunnableTask());
It seems that the amount of code has increased, but it is not. For the first method, the task submission and execution are fixed, and only a new thread can run, which can be said to have no scalability; In the second way, we can easily change the execution mode of tasks by switching from anexecution to otherexecutor, such as direct run, starting a new thread and saving priority queue. This is the advantage of decoupling task submission and execution.
Finally, we can see from the method definition that the input parameter is of Runnable type and has no return value.
ExecutorService
ExecutorService provides more functions on the basis of Executor, such as managing the life cycle of Executor and executing asynchronous tasks. The code is as follows. Comments and methods that have little to do with local topics are deleted
/**
* An {@link Executor} that provides methods to manage termination and
* methods that can produce a {@link Future} for tracking progress of
* one or more asynchronous tasks.
* <p>Method {@code submit} extends base method {@link
* Executor#execute(Runnable)} by creating and returning a {@link Future}
* that can be used to cancel execution and/or wait for completion.
*
* @since 1.5
* @author Doug Lea
*/
public interface ExecutorService extends Executor {
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
}
ExecutorService adds three submit methods, all of which can return a Future object. Through the Future object, you can do more things: obtain the task execution result, judge whether the task is completed, cancel the task, and so on.
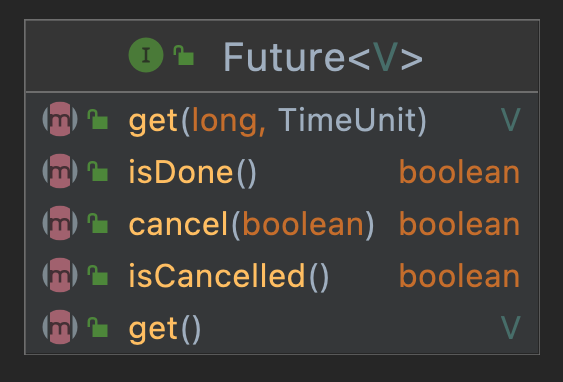
In this way, we find the second difference between execute and submit,
execute only accepts the Runnable parameter and has no return value; The submit can accept the Runnable parameter and Callable parameter, and return the Future object. You can cancel the task, obtain the task result, and judge whether the task is completed / cancelled.
AbstractExecutorService
AbstractExecutorService is an abstract class according to the class name. It implements the ExecutorService interface and provides some general method implementations, including three submit methods.
public abstract class AbstractExecutorService implements ExecutorService {
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
}
In the submit method, first judge whether the input parameter is null. If so, throw a null pointer exception. Obviously, the thread pool does not allow null tasks to be submitted.
Then, in the second step, whether the input parameter is Runnable or Callable, it is encapsulated into a task of RunnableFuture type, that is, the submit method will adapt the task once. RunnableFuture can be known by its name that it inherits both the Runnable interface and the Future interface, so it can be used as the return value.
The third step is to call the execute method. It turns out that submit will call the execute method, but AbstractExecutorService does not implement the execute method. Obviously, it is left to subclasses to implement. The template method mode is used here.
Finally, ftask is returned. As mentioned above, ftask is both Runnable and Future, so we can obtain the final task result through ftask.
In this way, we find a connection between execute and submit,
submit encapsulates the Runnable or Callable input parameters into a RunnableFuture object, calls the execute method and returns.
It is also worth mentioning that the newTaskFor method here returns the FutureTask object, that is, FutureTask implements the RunnableFuture interface, and the newTaskFor method is protected, that is, we can override this method in subclasses to achieve our special purpose.
ThreadPoolExecutor
Finally, the protagonist of this article - thread pool.
public class ThreadPoolExecutor extends AbstractExecutorService {
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
}
ThreadPoolExecutor finally implements the execute method, and the comments on the method also explain clearly how the thread pool handles the submitted tasks. I have to praise the comments on the JDK source code, which are often longer than the code.
Only one thing that is easy to ignore or cannot be understood here is a sub branch when the task is placed in the blocking queue
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
Here, why judge the number of workers again after putting the blocking queue, and call the addworker method if it is 0.
In fact, it is clear from a practical example that when we create a thread pool, we may want to not maintain the core thread and start the thread when a task arrives, that is
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(0, 2, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(size));
In this way, when the first task arrives, because the number of core threads has been reached (actually 0), the task will be automatically placed in the blocking queue. Won't it never be executed? Therefore, it will judge whether there is a current worker thread. If not, it will add one, and it is not necessary to specify the initial task for the added worker thread, because it will automatically get the task from the just blocked queue.
What is the worker here? In fact, we can understand it as the encapsulation of a thread. The key code is as follows
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
}
runWorker is the method of ThreadPoolExecutor
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
You can see that in runWorker, the loop continuously obtains tasks from the blocking queue and simply through task Run() to execute the task. If an exception occurs, it will be thrown out, that is, execute the task, and the execution thread will throw an exception.
FutureTask
How to execute the task submitted by submit? We need to check the FutureTask returned by newTaskFor. The key part of the code is as follows
public class FutureTask<V> implements RunnableFuture<V> {
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
runner = null;
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
}
You can see the difference between FutureTask and runWorker. runWorker catch es exceptions and throws them out without taking the pot at all; FutureTask is to save the exception caught and judge the task execution status when get ting. If the task status is abnormal, an ExecutionException will be thrown.
So the third difference between execute and submit is
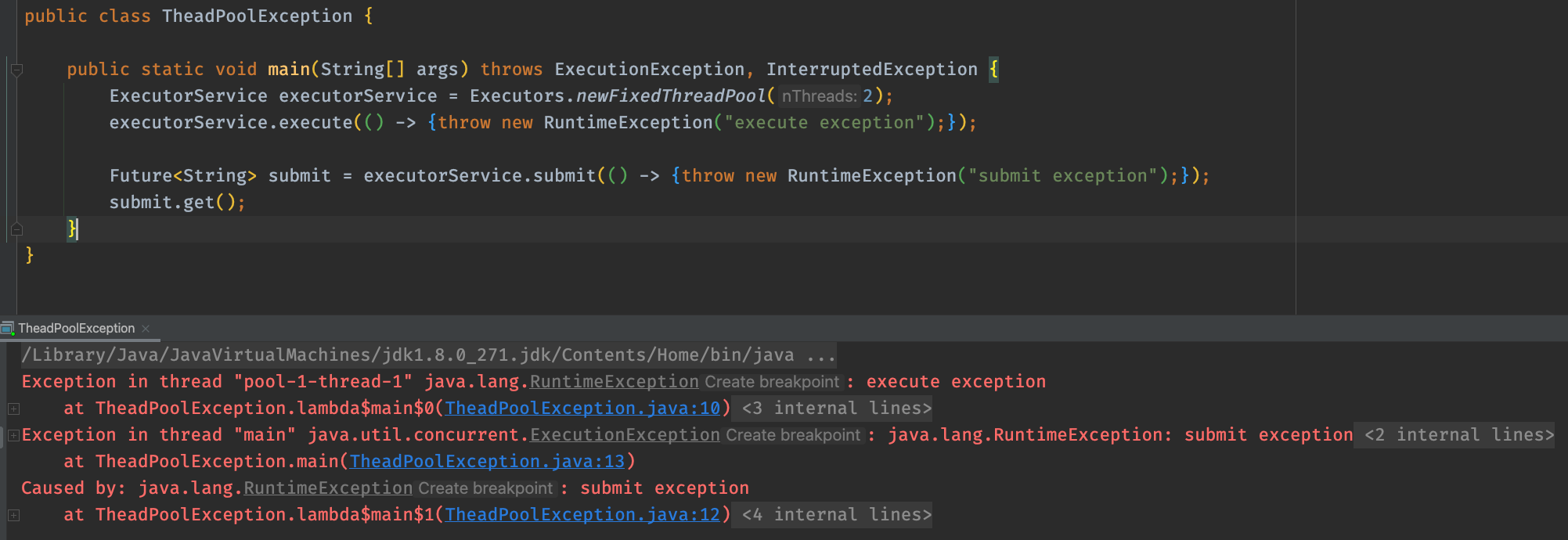
If an exception occurs in the task submitted through the execute method, the original exception will be thrown directly, which is in the thread in the thread pool; The submit method catches exceptions. The ExecutionException exception will be thrown only when calling the get method of Future, and it is the thread calling the get method.
The actual effect is shown in the figure
summary
Through the above analysis, we can see the difference between execute and submit
1. execute is the method of the Executor interface, and submit is the method of the ExecutorService, and the ExecutorService interface inherits the Executor interface.
2. execute only accepts the Runnable parameter and has no return value; The submit can accept the Runnable parameter and Callable parameter, and return the Future object. You can cancel the task, obtain the task result, and judge whether the task is completed / cancelled. Among them, submit will encapsulate the Runnable or Callable input parameters into a RunnableFuture object, call the execute method and return.
3. If an exception occurs in the task submitted through the execute method, the original exception will be thrown directly, which is in the thread in the thread pool; The submit method catches exceptions. The ExecutionException exception will be thrown only when calling the get method of Future, and it is the thread calling the get method.
Finally, the class diagram related to the process pool is attached to clearly understand the relationship between these classes
