The first step from introduction to prison
Abstract: this content only has the basic knowledge of reptiles. It is only suitable for novices to learn reptiles. If you are a big man, please detour and leave. It's mainly for yourself. I'm afraid I'll forget it
Catalogue
- python packages required for installation
- Steps for reptiles
- Website analysis
- Use of requests
- Crawling content
- Storage mode
Installation
The main python packages used are requests, re, pandas, and time
Open CMD - > Input
pip install requests pip install re pip install pandas
Open package
import requests import re import time import pandas as pd
(you can open the bag according to the bag you need to crawl)
Steps for reptiles
- Analyze the website first: check where the target to crawl is on the website
- After finding the target, what form is displayed: usually in the form of direct text, URL, URL file, etc
- Write crawl code
Website analysis
Website parsing may feel that you must understand the language of the website, but you don't need to. Of course, understanding will make it easier for you to be in the crawler. If you don't understand it, don't be afraid. I don't know much about HTML,CSS and JS. But I can climb to what I want. As long as you know what you want to put there, and the structure of links, you can climb to the desired content.
All documents have absolute paths and links on the website. You can climb to the downloaded files as long as you know their links.
Therefore, it is mainly to find the corresponding link URLs, and then make an access to these URLs. As long as the access is successful, you can climb down.
However, there will also be encryption. There are CSS encryption and JS encryption, not to mention. It requires deeper crawlers to learn.
If you don't climb the websites of big companies, the structure of other websites is relatively simple and easy to climb down.
Utilization of network
The website's network is a simple tool for crawling packages. Loading data packets can be found here, and we can get the corresponding URL for crawling some contents of the website.

- Fetch/XHR: it is mainly used to load text data. Its URL will be displayed in the form of XHR or JSON after it is opened
- JS: it is a programming language that can move the website,
- CSS: the style display of the website appears only to beautify the website
- I MG: all the pictures loaded on the website can be found here
As long as you click, you can quickly sort, find what you want faster, and store it in that data packet.
Request
There are two basic crawling methods to access websites in python: get and post. I understand it this way. Get, we go to the server to get things, and post, we give things to the server. Most use get.
Let's use an example to illustrate. Suppose we want to access it in python https://www.baidu.com/
url = 'https://www.baidu.com/'
We also need to set a header before visiting the website, which is set by the method of dictionary
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Cookie': 'BIDUPSID=2A7A4CF29AEF7C307EF129AE0E15B742; PSTM=1609848264; BD_UPN=12314753; BDUSS=9FMlRRMFFBOEV0R29rTXJXR20td2FGVEE5WHdKb2FoeHlKOEQ1Rn5YaGs4akJnSVFBQUFBJCQAAAAAAQAAAAEAAAAD4woGAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGRlCWBkZQlgT2; BDUSS_BFESS=9FMlRRMFFBOEV0R29rTXJXR20td2FGVEE5WHdKb2FoeHlKOEQ1Rn5YaGs4akJnSVFBQUFBJCQAAAAAAQAAAAEAAAAD4woGAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGRlCWBkZQlgT2; __yjs_duid=1_656489a63aff4a00db25c98347131c2d1617941644108; BAIDUID=69F8BB689CC2F279E2B2902E4C9AA2D9:FG=1; BCLID_BFESS=11583441835844288591; BDSFRCVID_BFESS=trDOJexroG0Y_ARe1brQk_OQMgKK0gOTDYLEOwXPsp3LGJLVgVBXEG0Pt_NFmZK-oxmHogKK3mOTHmDF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tbutoK8XJDD3jt-k5brBhnL-hp_X5-CstbTl2hcH0KLKbDoo0lK-bqDy3tCtQPJX25KL5Joy2fb1MRjvDfvP0nKIjx5d-MT75erl_l5TtUJcSDnTDMRh-4ApQnoyKMnitKj9-pPKWhQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuDjtBDT30DGRabK6aKC5bL6rJabC3f-oeXU6q2bDeQN3kyMoN5R6aQfjoXh7G8J3oyT3JXp0vWtv4WbbvLT7johRTWqR4eUQtWMonDh83BPTl2lTiHCOOWlnO5hvvhn6O3M7VQMKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRIjVIOP; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS=107316_110085_127969_128698_164869_168388_170704_175649_175668_175755_176398_176553_176677_177007_177371_177412_178005_178329_178530_178632_179201_179347_179368_179380_179402_179454_180114_180276_180407_180434_180436_180513_180655_180698_180758_180869_181207_181259_181329_181401_181429_181432_181483_181536_181589_181611_181710_181791_181799_182000_182026_182061_182071_182077_182117_182191_182233_182321_182576_182598_182715_182847_182921_183002_183329_183433; MCITY=-%3A; BAIDUID_BFESS=B23738E9C47D22324B926F5D72B96F85:FG=1; BD_HOME=1; H_PS_PSSID=34398_34369_31253_34374_33848_34092_34106_34111_26350_34246; BA_HECTOR=a5agal0l81al8025ha1gh949e0r',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
Get method:
Open F12 - > Network - > click any one in name, open - > headers, and paste it according to the copy given by him,

You can also add headers in python according to its header. In the same way, suppose I want to add a Referer, as follows
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Cookie': '.....',#Omitted because it's too long
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
'Referer' : 'https://www.baidu. COM / '# < --- just add it in the way of dictionary
}
In this way, it can be added. Sometimes something will be used when crawling. You can add it in this way. If you change it according to the method of the dictionary, the value of the surface will change.
We use get to access.
r = requests.get(url = url, headers = headers)
html = r.content.decode('utf-8')
Content: obtain the website content in binary form, which is the HTML structure of the website.
decode: the code is' utf-8 'to prevent garbled codes
print(r)
The result of 200 is equal to successful access
<Response [200]>
We can also print html to see
print(html)
You can see the code of the website. I won't demonstrate it. I can implement it myself and deepen the image.
<>
The use of Post is one more data than get, and the writing method of data is the same as that of headers
data = {
'VIEWSTATE': '...', #Drop slightly
'EVENTVALIDATION': '...',#Drop slightly
'PREVIOUSPAGE': '...' #Drop slightly
}
r = requests.get(url, headers = headers,data = data)
html = r.content.decode('utf-8')
Get method:

The corresponding data can also be obtained by using re
VIEWSTATE = re.findall(r'<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="(.*?)" />', str(html)) EVENTVALIDATION = re.findall(r'input type="hidden" name="__EVENTVALIDATION" id="__EVENTVALIDATION" value="(.*?)" />', str(html)) PREVIOUSPAGE = re.findall(r'<input type="hidden" name="__PREVIOUSPAGE" id="__PREVIOUSPAGE" value="(.*?)" />',str(html))
Crawling content
1. Text crawling
This is the simplest. If you visit the website according to the above method, you can crawl to the original code of the website and only do regular operation. There are many extracted teaching and python packages on the Internet, but I mainly use RE regular extraction.
We can go to the regular website to do the test first, and the use method can be checked by ourselves
Regular test website: https://regexr-cn.com/
I mainly use the following core methods:
text = "I'm Chen Dawen" find = re.findall(r"I am(.*?)large",str(text)) #"I am" is used to locate (. *?) Used to extract the desired content, "big" is the final positioning #find is a list print(find[0])
The above is just an example. You can test it and you will find that you can walk around the world as long as you use this sentence
2. Image crawling
At present, images are rarely encrypted, so just find the corresponding link, request the link, and save it in the binary way of content. Later, the storage method will talk about how to save it
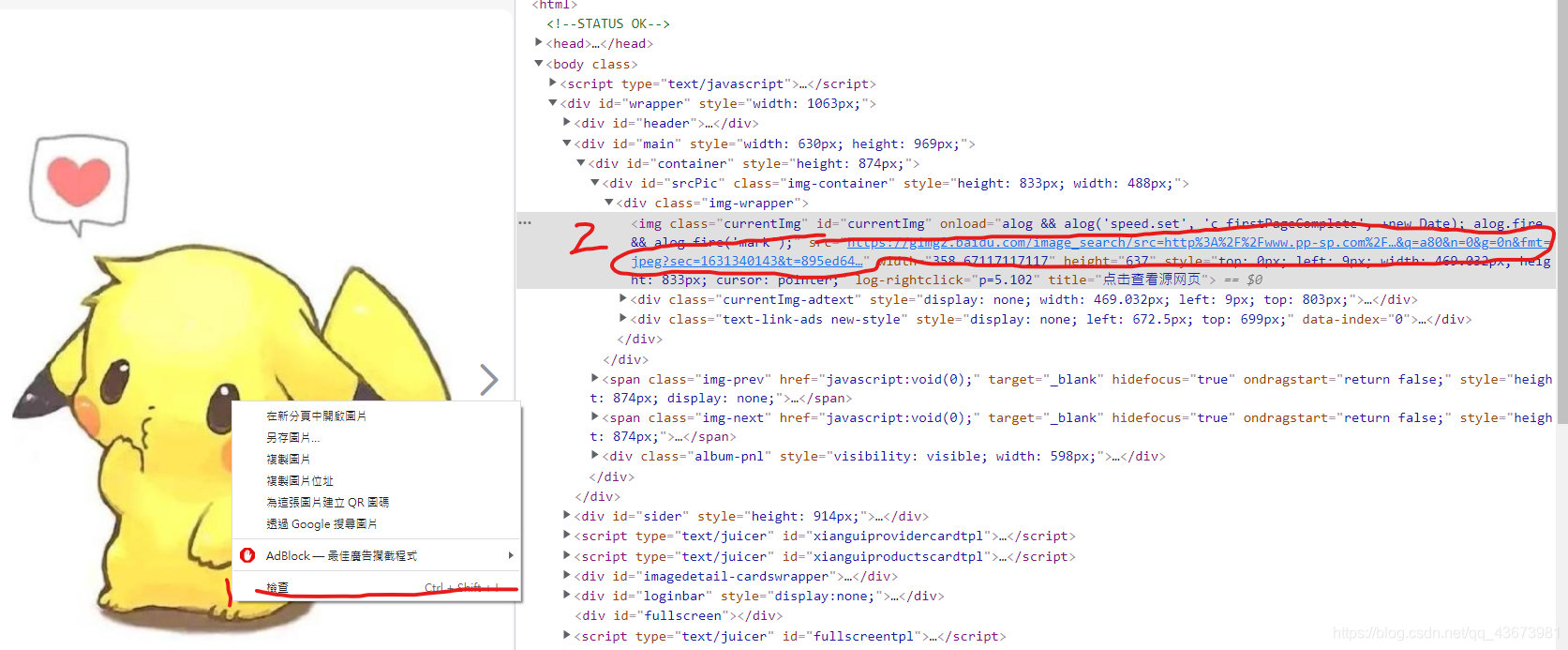
The following example: first, right click - > check to find the corresponding link. As long as get is the condition to crawl the graph.
Storage mode
Files can be jpg .pdf .xlsx can be saved as long as you change the suffix name.
Important: it must be in binary form
path = 'File name.Suffix' #The storage address is set by yourself + 'Document type suffix' #The suffix must be the same as the crawled document, otherwise an error will occur #For example, the picture path = 'pic jpg' with open(path,'wb') as f: f.write(r.content) f.close()
example
Let me take this picture as an example

When we found this picture on the website, we opened F12 and found a link to this picture
https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.pp-sp.com%2FUploadFiles%2Fimg_0_1579101990_2165129230_26.jpg&refer=http%3A%2F%2Fwww.pp-sp.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1631340143&t=895ed6441a5d8af0b2e9d15150a9fb60
We can open this picture

This will appear after opening. All files can be opened in this form, which is the ultimate goal of our crawling.
import requests
url = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.pp-sp.com%2FUploadFiles%2Fimg_0_1579101990_2165129230_26.jpg&refer=http%3A%2F%2Fwww.pp-sp.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1631340143&t=895ed6441a5d8af0b2e9d15150a9fb60'
r = requests.get(url) #The header is only needed when visiting the website, and this link can be used without headers or with headers
html = r.content
with open('Pikachu .jpg','wb') as f:
f.write(html)
f.close()
Run~~~

So the picture can be saved