Use VGG model to fight cat and dog
import numpy as np
import matplotlib.pyplot as plt
import os
import shutil,os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# Determine whether there is a GPU device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())

Download data
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip ! unzip dogscats.zip
Download the test set from the official website of the competition
! wget https://static.leiphone.com/cat_dog.rar
! unrar x cat_dog.rar
shutil.move("./cat_dog/test","./dogscats")

data processing
datasets is a package in torchvision, which can be used to load image data. It can read data from the hard disk in the form of multi thread and transmit it to GPU in the form of mini batch in network training. When using CNN to process images, preprocessing is required. The pictures will be sorted into 224 × 224 × 3 224\times 224 \times 3 two hundred and twenty-four × two hundred and twenty-four × 3, and will be normalized at the same time.
Torchvision supports some complex preprocessing / transformation of input data (normalization, clipping, flipping, jittering, etc.). For details, please refer to the official documentation of torchvision.tranforms.
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './dogscats'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'valid','test']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid','test']}
dset_classes = dsets['train'].classes
# You can view some properties of dsets through the following code
print(dsets['train'].classes)
print(dsets['train'].class_to_idx)
print(dsets['train'].imgs[:5])
print('dset_sizes: ', dset_sizes)

loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(dsets['test'], batch_size=5, shuffle=False, num_workers=6)
'''
valid There are a total of 2000 figures, each batch There are 5, so the following traversal will output a total of 400
At the same time, put the first one batch Save to inputs_try, labels_try,View separately
'''
count = 1
for data in loader_valid:
print(count, end='\n')
if count == 1:
inputs_try,labels_try = data
count +=1
print(labels_try)
print(inputs_try.shape)
# Display picture applet
def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Show labels_ Five pictures of try, that is, the five pictures of the first batch in valid out = torchvision.utils.make_grid(inputs_try) imshow(out, title=[dset_classes[x] for x in labels_try])

Create VGG Model
torchvision integrates many general CNN models pre trained on ImageNet (1.2 million training data), which can be downloaded and used directly.
In this course, we directly use the pre trained VGG model. At the same time, in order to show the prediction results of VGG model on this data, the JSON files of 1000 classes of Imagenet are also downloaded.
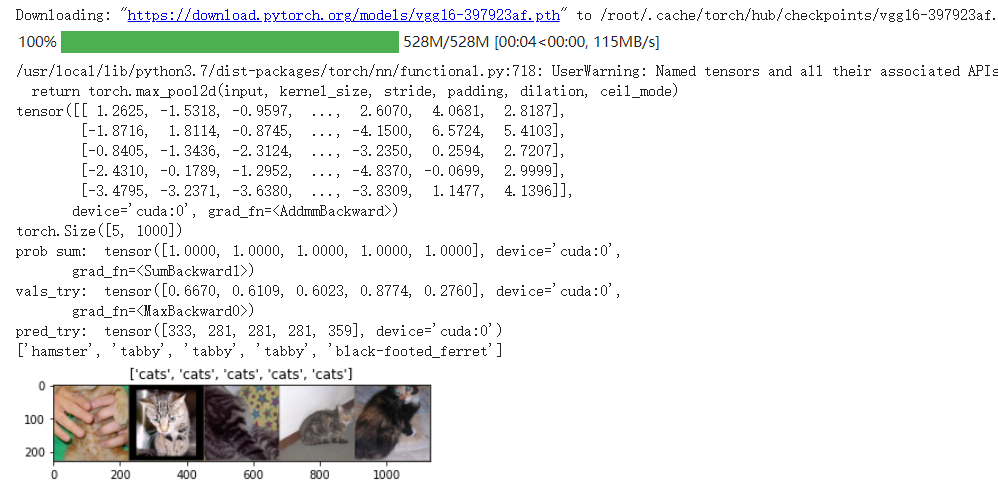
In this part of the code, the five input pictures are predicted by VGG model, and the results are processed by softmax. Then the recognition results are displayed. It can be seen that the recognition result is very accurate.
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
print(outputs_try)
print(outputs_try.shape)
'''
You can see that the result is 5 rows and 1000 columns of data, and each column represents the result of each target recognition.
But I can also observe that the results are very wonderful. There are negative numbers and positive numbers,
In order to VGG The output of the network is transformed into the prediction probability of each class, and we input the results into Softmax function
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print( 'prob sum: ', torch.sum(probs,1))
print( 'vals_try: ', vals_try)
print( 'pred_try: ', pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])
Modify the last layer and freeze the parameters of the previous layer
The VGG model is shown in the figure below. Note that the network consists of three elements:
- Convolution layer (CONV) is a pattern that finds parts in an image
- Full connection layer (FC) is to establish the association of features globally
- Pool is the invariance to reduce the dimension of the image to improve the feature
Our goal is to use the pre trained model. Therefore, we need to replace the last nn.Linear layer with class 2 from class 1000. In order to freeze the parameters of the previous layer during training, you need to set required_grad=False. In this way, when back propagating the training gradient, the weight of the previous layer will not be updated automatically. During training, only the parameters of the last layer will be updated.
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
Train and test the full connection layer
It includes three steps: Step 1, create loss function and optimizer; Step 2, training model; Step 3, test the model.
'''
Step 1: create loss function and optimizer
loss function NLLLoss() The input is a logarithmic probability vector and a target label.
It doesn't calculate the logarithmic probability for us. The last layer is log_softmax()Network.
'''
criterion = nn.NLLLoss()
# Learning rate
lr = 0.001
# Random gradient descent
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
Step 2: Training Model
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# model training
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])

Prediction of test data set
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_test,size=dset_sizes['test'])
The results are exported in cats_ vs_ In dogs.csv
import csv
with open('./dogscats/cats_vs_dogs.csv','w',newline="")as f:
writer = csv.writer(f)
for index,cls in enumerate(predictions):
path = datasets.ImageFolder(os.path.join(data_dir,'test'),vgg_format).imgs[index][0]
l = path.split("/")
img_name = l[-1]
order = int(img_name.split(".")[0])
writer.writerow([order,int(predictions[index])])
Submit results
Submit the result after sorting the csv file
