The fourth big assignment
Assignment 1
1.1 experimental topic
-
Requirements: master the serialization output method of Item and Pipeline data in the scene; Scrapy+Xpath+MySQL database storage technology route crawling Dangdang website book data
-
Candidate sites: http://search.dangdang.com/?key=python&act=input
-
Key words: students can choose freely
-
Output information: the output information of MySQL is as follows

1.2 ideas
1.2.1 analysis and search process
By checking the page, we can find that the information of each book is stored under the li tag

Therefore, the content of each li tag is crawled and stored in lis
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
Then analyze the content under each li tag and get the content of the required part through xpath
title = li.xpath("./a[position()=1]/@title").extract_first() #title
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() #Price
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()#author
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()#date
publisher =li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()#press
detail = li.xpath("./p[@class='detail']/text()").extract_first()#brief introduction
After crawling a page of information, turn the page. The number of pages is limited by the size of the flag. Here, only three pages of information are crawled
if self.flag<2: self.flag+=1 url = response.urljoin(link) yield scrapy.Request(url=url, callback=self.parse)
1.2.2 write items.py
title = scrapy.Field() author = scrapy.Field() date = scrapy.Field() publisher = scrapy.Field() detail = scrapy.Field() price = scrapy.Field()
1.2.3 pipeline.py preparation
Connect to the database first, and if the table does not exist, create the table. If the table exists, delete the table first and then create it
self.con = sqlite3.connect("dangdand.db")
self.cursor = self.con.cursor()
# Create table
try:
self.cursor.execute("drop table book")
except:
pass
self.cursor.execute(
"create table book(bTitle varchar(512), bAuthor varchar(256),bPublisher varchar(256), bDate varchar(32), bPrice varchar(16), bDetail varchar(1024))")
Close the database and spider
if self.opened: self.con.commit() self.con.close() self.opened = False
Insert data into a table
if self.opened:
#insert data
self.cursor.execute("insert into book(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(?,?,?,?,?,?)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
1.2.4 running the script framework code
Method 1: write a function in the scratch framework
from scrapy import cmdline
cmdline.execute("scrapy crawl Myspider -s LOG_ENABLED=False".split())
Among them, Myspider should be changed according to the name in the python of the spider you created
name = 'Myspider'
It is modified according to the name in this sentence, not all MySpider
Method 2: in the command line, enter the spider framework and enter spider crawl Myspider to run. Similarly, Myspider should be modified according to its own requirements.
1.2.5 operation results
Results in database
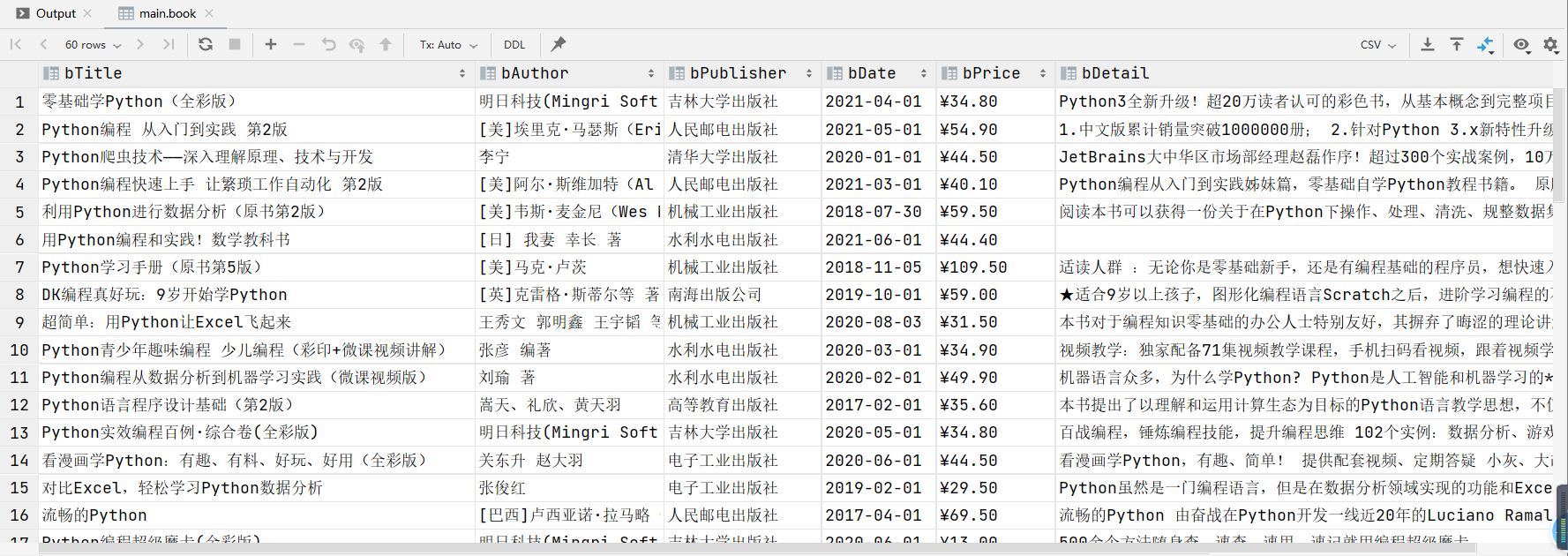
Command line output results

1.3 complete code
https://gitee.com/q_kj/crawl_project/tree/master/dangdang
1.4 summary
The first problem is to reproduce the code. At the beginning, the problem is the start in the generated spider framework_ Url = [''] there will be errors in the process of splicing into a complete code. Remove [] and you can run normally. There are no other problems.
Assignment 2
2.1 experimental topics
-
Requirements: master the serialization output method of Item and Pipeline data in the scene; Crawl the foreign exchange website data using the technology route of "scratch framework + Xpath+MySQL database storage".
-
Candidate website: China Merchants Bank Network: http://fx.cmbchina.com/hq/
-
Output information: MySQL database storage and output format
Id Currency TSP CSP TBP CBP Time 1 HKD 86.60 86.60 86.26 85.65 15: 36: 30 2......
2.2 ideas
2.2.1 analysis and search process
By checking the page, you can find that the information of each currency is stored under the tr tag
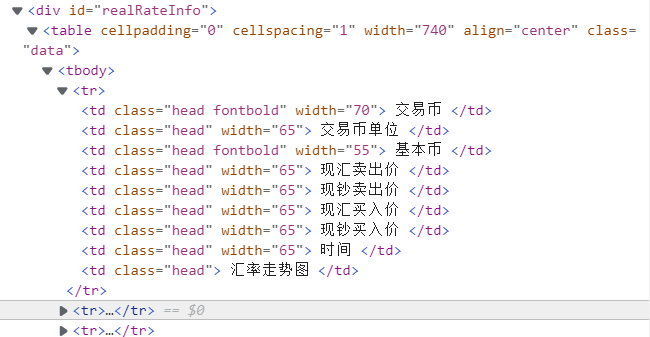
During the inspection, it is found that it is in the tr tag under tbody, so / / * [@ id="rightbox"]/table/tbody/tr is used to match, and the result is empty. Then find out by looking at the source code of the page

There is no tbody tag, so finally use following code to match tr tag
trs = selector.xpath('//div[@id="realRateInfo"]/table/tr')
Then match the required content under the tr tag
name = tr.xpath('.//TD [1] / text()). Extract() # transaction currency
TSP = tr.xpath('.//TD [4] / text()). Extract() # spot exchange selling price
CSP = tr.xpath('.//TD [5] / text()). Extract() # cash selling price
TBP = tr.xpath('.//TD [6] / text()). Extract() # spot exchange purchase price
CBP = tr.xpath('.//TD [7] / text()). Extract() # cash purchase price
time = tr.xpath('.//TD [8] / text() '. Extract() # time
However, the content in the first tr tag is the header, which is unnecessary, so it needs to be filtered again. By initially setting count=0, skip when count=0, and set count to 1, and the remaining content can be stored in item for subsequent work.
2.2.2settings.py settings
View user through F12_ Agent content, and modify the corresponding location content in settings

Modify the robots protocol to False

Remove the comments in the following section

2.2.3 writing items.py
currency = scrapy.Field() TSP = scrapy.Field() CSP = scrapy.Field() TBP =scrapy.Field() CBP = scrapy.Field() Time = scrapy.Field()
2.2.4 pipeline.py preparation
Connect to the database first, and if the table does not exist, create the table. If the table exists, delete the table first and then create it
self.con = sqlite3.connect("bank.db")
self.cursor = self.con.cursor()
# Create table
try:
self.cursor.execute("drop table bank")
except:
pass
self.cursor.execute("create table bank(Id int,Currency varchar(32), TSP varchar(32),CSP varchar(32), TBP varchar(32), CBP varchar(32), Time varchar(32))")
Close the database and spider
if self.opened: self.con.commit() self.con.close() self.opened = False
Insert data into a table
if self.opened:
#insert data
self.cursor.execute("insert into bank(Id,Currency,TSP,CSP,TBP,CBP,Time) values(?,?,?,?,?,?,?)",(self.count,item["currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
self.count += 1
2.2.5 results
Database result information
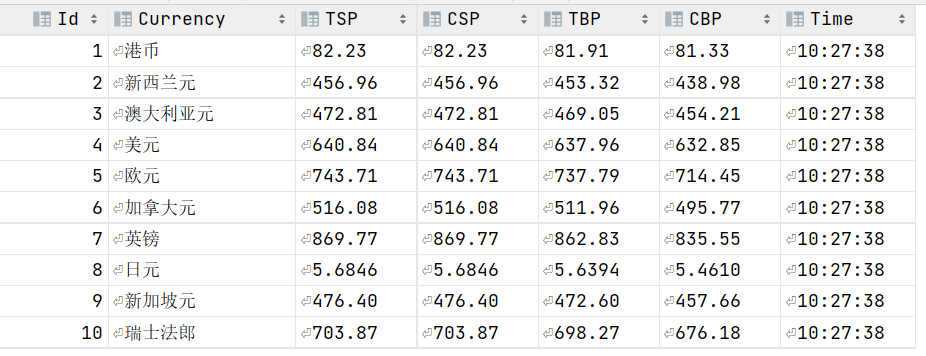
Console input information
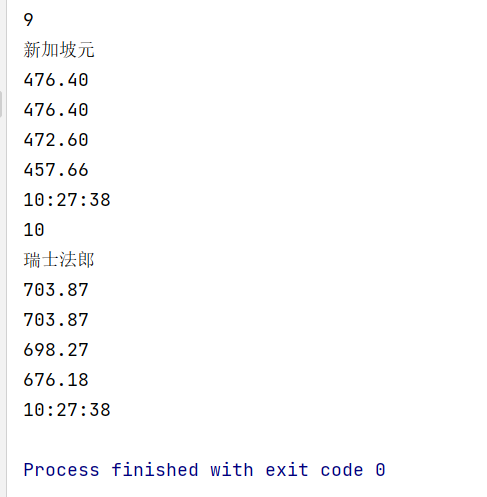
2.3 complete code
https://gitee.com/q_kj/crawl_project/tree/master/zsBank
2.4 summary
The main problem of this problem is that when looking for the tr tag, you can find that there is a tbody tag in the inspection, but you can't match the result through it. However, you can find that there is no tbody tag in the page source code, so you can correctly match the result by removing it. Therefore, you can better see the hierarchy by viewing the page source code. What you see in the inspection may not be the real content.
Assignment 3
3.1 experimental topic
-
Requirements: be familiar with Selenium's search for HTML elements, crawling Ajax web page data, waiting for HTML elements, etc; Use Selenium framework + MySQL database storage technology route to crawl the stock data information of "Shanghai and Shenzhen A shares", "Shanghai A shares" and "Shenzhen A shares".
-
Candidate website: Dongfang fortune.com: http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
Output information: the storage and output format of MySQL database is as follows. The header should be named in English, such as serial number id, stock code: bStockNo..., which is defined and designed by students themselves:
Serial number Stock code Stock name Latest quotation Fluctuation range Rise and fall Turnover Turnover amplitude highest minimum Today open Received yesterday 1 688093 N Shihua 28.47 62.22% 10.92 261 thousand and 300 760 million 22.34 32.0 28.08 30.2 17.55 2......
3.2 ideas
3.2.1 Analysis page
By checking the page, you can find that the information of each currency is stored under the tr tag

Then analyze each tr tag to get the required content
try: id=tr.find_element(by=By.XPATH,value='.//td[1]').text except: id=0
Because there is a lot of content required, only one example is given here, and the rest are in the code.
3.2.2 create table
Because the information of three plates needs to be crawled, three tables are created to store the information of three plates
#Create connection with database
self.con = sqlite3.connect("stock.db")
self.cursor = self.con.cursor()
#If the table hushen exists, delete it. Otherwise, do nothing
try:
self.cursor.execute("drop table hushen")
except:
pass
#Create hushen table
try:
self.cursor.execute("create table hushen(Id varchar (16),bStockNo varchar(32),bStockName varchar(32),bNewPirce varchar(32),bUP varchar(32),bDowm varchar(32),bNum varchar(32),bCount varchar(32),bampl varchar (32),bHighest varchar(32),bMin varchar(32),bTodayOpen varchar(32),bYClose varchar(32))")
except:
pass
# If the table shangzheng exists, delete it. Otherwise, do nothing
try:
self.cursor.execute("drop table shangzheng")
except:
pass
#Create shangzheng table
try:
self.cursor.execute("create table shangzheng(Id varchar (16),bStockNo varchar(32),bStockName varchar(32),bNewPirce varchar(32),bUP varchar(32),bDowm varchar(32),bNum varchar(32),bCount varchar(32),bampl varchar (32),bHighest varchar(32),bMin varchar(32),bTodayOpen varchar(32),bYClose varchar(32))")
except:
pass
# If the table shenzheng exists, it will be deleted, otherwise nothing will be done
try:
self.cursor.execute("drop table shenzheng")
except:
pass
#Create shenzheng table
try:
self.cursor.execute("create table shenzheng(Id varchar (16),bStockNo varchar(32),bStockName varchar(32),bNewPirce varchar(32),bUP varchar(32),bDowm varchar(32),bNum varchar(32),bCount varchar(32),bampl varchar (32),bHighest varchar(32),bMin varchar(32),bTodayOpen varchar(32),bYClose varchar(32))")
except:
pass
3.2.3 closing the database
try: self.con.commit() self.con.close() self.driver.close() except Exception as err: print(err)
3.2.4 inserting data into tables
Because there are three tables, flag is used to label different tables and insert data into different tables.
if flag==1:
try:
self.cursor.execute("insert into hushen(Id,bStockNo,bStockName,bNewPirce,bUP,bDowm,bNum,bCount,bampl,bHighest,bMin,bTodayOpen,bYClose) values (?,?,?,?,?,?,?,?,?,?,?,?,?)", (Id,bStockNo,bStockName,bNewPirce,bUP,bDowm,bNum,bCount,bampl,bHighest,bMin,bTodayOpen,bYClose))
print("Insert data succeeded")
except Exception as err:
print(err)
# If the flag is 2, insert data into the shangzheng table
elif flag==2:
try:
self.cursor.execute(
"insert into shangzheng(Id,bStockNo,bStockName,bNewPirce,bUP,bDowm,bNum,bCount,bampl,bHighest,bMin,bTodayOpen,bYClose) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(
Id, bStockNo, bStockName, bNewPirce, bUP, bDowm, bNum, bCount,bampl, bHighest, bMin, bTodayOpen, bYClose))
print("Insert data succeeded")
except Exception as err:
print(err)
# If the flag is 3, insert data into the shenzheng table
elif flag==3:
try:
self.cursor.execute(
"insert into shenzheng(Id,bStockNo,bStockName,bNewPirce,bUP,bDowm,bNum,bCount,bampl,bHighest,bMin,bTodayOpen,bYClose) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(
Id, bStockNo, bStockName, bNewPirce, bUP, bDowm, bNum, bCount,bampl, bHighest, bMin, bTodayOpen, bYClose))
print("Insert data succeeded")
except Exception as err:
print(err)
3.2.5 realize page turning
Only two pages of information are crawled here to prove that you can turn the page
if self.count < 1: self.count += 1 nextPage = self.driver.find_element(by=By.XPATH, value='//*[@id="main-table_paginate"]/a[2]') time.sleep(10) nextPage.click() self.processSpider(flag)
3.2.6 realize the crawling of different plates
nextStock=self.driver.find_element(by=By.XPATH,value='//*[@id="nav_sh_a_board"]/a')
self.driver.execute_script("arguments[0].click();", nextStock)
3.2.7 results
hushen table
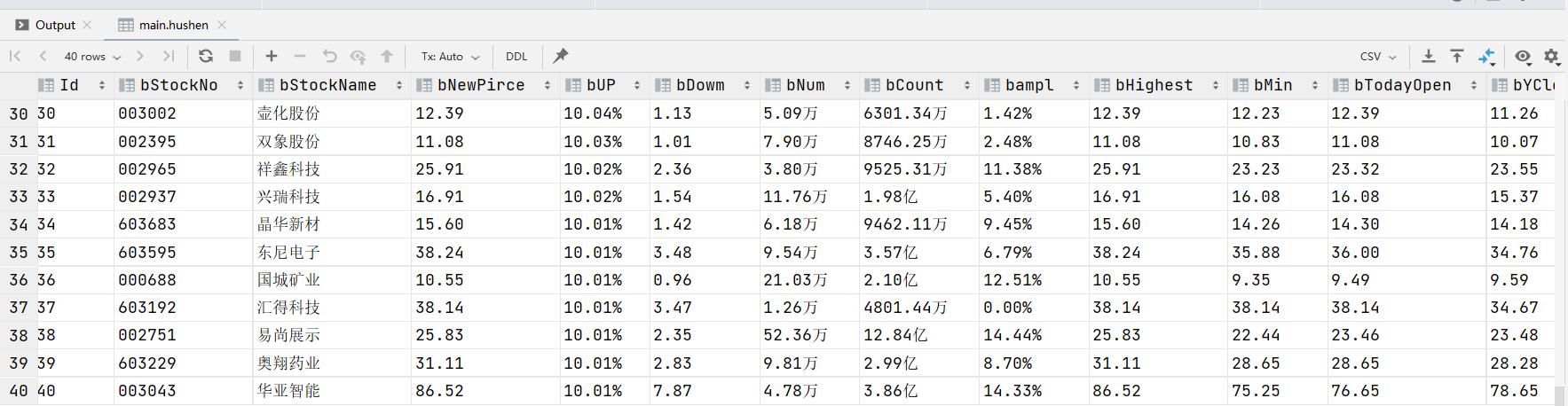
shangzheng table
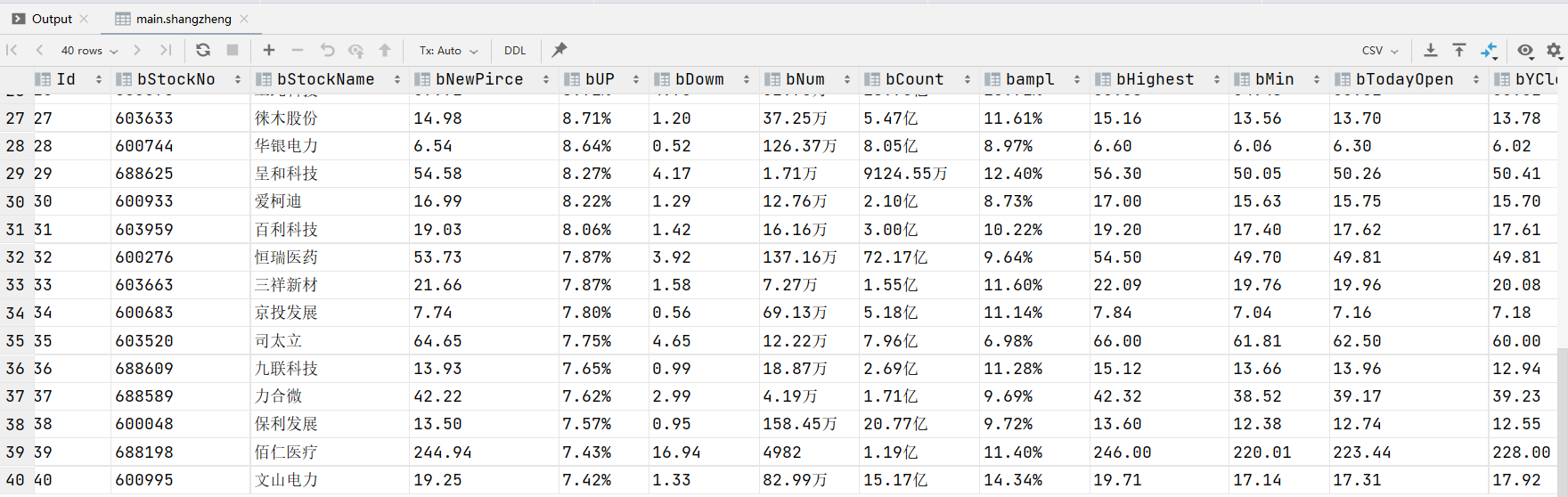
shenzheng table
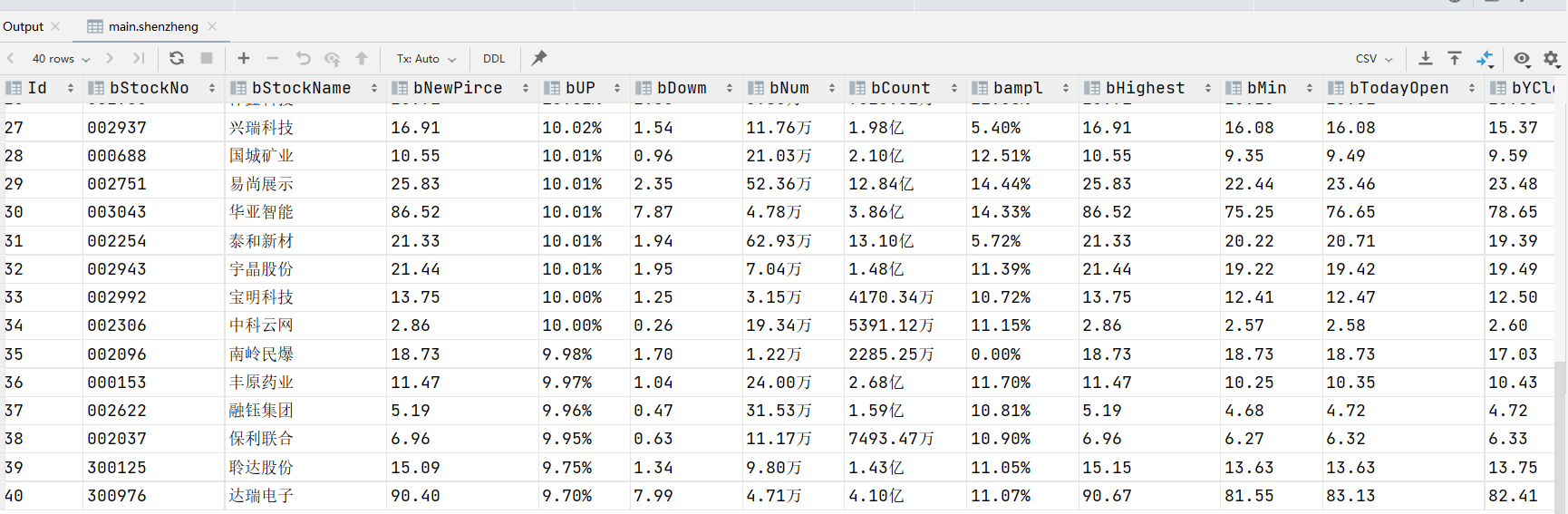
3.3 complete code
https://gitee.com/q_kj/crawl_project/tree/master/forth
3.4 summary
Error encountered while clicking(). element click intercepted, passed https://laowangblog.com/selenium-element-click-intercepted.html Change next.click() to self.driver.execute_script("arguments[0].click();", next) successfully solved the problem. Selenium is often unsuccessful in crawling. It may be because the page has not been loaded, so you need to sleep, and you may be able to crawl and retrieve the results normally