background
Developer feedback system is particularly slow to execute a stored procedure, which is checked because of the need to insert a large amount of data into the new task table during the execution of the stored procedure. The primary key of the task table is clustered index. Why does clustering index cause slow insertion? How much impact does clustering index have on data insertion?
principle
- In a non-clustered index, the storage order of physical data is different from that of an index. The lowest level of the index contains pointers to rows on the data page.
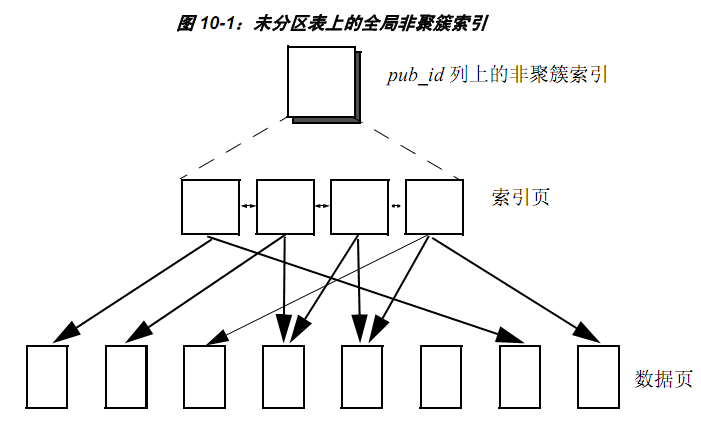
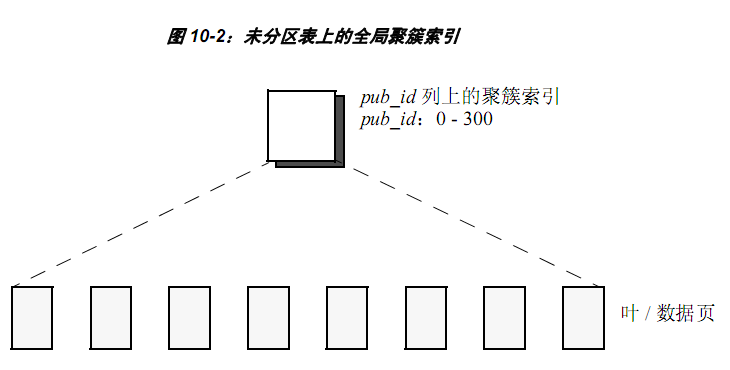
- In clustered index, physical data is stored in the same order as index, and the lowest level of index contains actual data pages.
Cluster indexing results in data records having to be stored in order of key size, while insertion and deletion require mobile data records, resulting in additional disk IO.
test
Basic environmental information
- View Operating System Version
[root@npfydev01 home]# lsb_release -a
LSB Version: :base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0-noarch:graphics-4.0-amd64:graphics-4.0-noarch:printing-4.0-amd64:printing-4.0-noarch
Distributor ID: CentOS
Description: CentOS release 6.4 (Final)
Release: 6.4
Codename: Final
- View Disk Information
[root@npfydev01 home]# cat /proc/scsi/scsi
Attached devices:
Host: scsi0 Channel: 02 Id: 00 Lun: 00
Vendor: IBM Model: ServeRAID M5110 Rev: 3.24
Type: Direct-Access ANSI SCSI revision: 05
Host: scsi1 Channel: 00 Id: 00 Lun: 00
Vendor: IBM SATA Model: DEVICE 81Y3674 Rev: IB01
Type: CD-ROM ANSI SCSI revision: 05- View Disk Read-Write Speed
[root@npfydev01 home]# time dd if=/dev/zero of=/home/4kb.1GBFILE bs=4k count=262144
262144+0 records in
262144+0 records out
1073741824 bytes (1.1 GB) copied, 1.58541 s, 677 MB/s
real 0m1.589s
user 0m0.050s
sys 0m1.533s- View the database version
1> select @@version
2> go
--------------------------------------------------------------------------------------
Adaptive Server Enterprise/15.7/EBF 21708 SMP SP110 /P/x86_64/Enterprise Linux/ase157sp11x/3546/64-bit/FBO/Fri Nov 8 05:39:38 2013
(1 row affected)
II. Data preparation
- Create a clustered index table (sybase primary key defaults to clustered index)
USE DB_TASK
GO
CREATE TABLE T_TASKITEM_CI (
C_BH char(32) primary key,
C_BH_TASK char(32) null,
C_BH_AJ varchar(32) null,
N_AJBS numeric(15,0) null,
C_AJLB varchar(6) null,
N_JBFY int null,
N_ZT int null,
C_AH varchar(75) null
)
go- Establishing Non-Cluster Index Table
USE DB_TASK
go
CREATE TABLE T_TASKITEM_NCI (
C_BH char(32) NOT NULL,
C_BH_TASK char(32) null,
C_BH_AJ varchar(32) null,
N_AJBS numeric(15,0) null,
C_AJLB varchar(6) null,
N_JBFY int null,
N_ZT int null,
C_AH varchar(75) null
)
go
CREATE UNIQUE INDEX PK_TASKITEM ON DB_TASK.dbo.T_TASKITEM_NCI (C_BH)
go
- Constructing data
Construct an isomorphic data table T_TASKITEM_CC, and use the following SQL to construct about 50W data to the table.
SELECT newid ()
, a.C_BH
, 1 AS N_ZT
, a.N_AJBS
, a.N_JBFY
, '5813b6d7ce8847d68b34daa956776659' AS C_BH_TASK
, (CASE WHEN (a.N_YWLX = 20100) THEN '0201' WHEN (a.N_YWLX = 20200) THEN '0202' WHEN (a.N_YWLX = 20304) THEN '0207' WHEN (a.N_YWLX = 20501) THEN '0210' WHEN (a.N_YWLX = 20801) THEN '0224' WHEN (a.N_YWLX = 20601) THEN '0214' WHEN (a.N_YWLX = 20603) THEN '0216' WHEN (a.N_YWLX = 20602) THEN '0215' END) AS C_AJLB
, a.C_AH
FROM YWST..T_XS_AJ a
Data amount is 501132
III. Insert Contrast
- Non-clustered index table
1> insert into T_TASKITEM_NCI SELECT newid(),C_BH_TASK,C_BH_AJ,N_AJBS,C_AJLB,N_JBFY,N_ZT,C_AH FROM T_TASKITEM_CC
2> GO
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Table: T_TASKITEM_NCI scan count 0, logical reads: (regular=2025588 apf=0 total=2025588), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Table: T_TASKITEM_CC scan count 1, logical reads: (regular=10957 apf=27 total=10984), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Total writes for this command: 3538
Execution Time 97.
Adaptive Server cpu time: 9688 ms. Adaptive Server elapsed time: 13381 ms.
(501132 rows affected)- Cluster Index Table
1> insert into T_TASKITEM_CI SELECT newid(),C_BH_TASK,C_BH_AJ,N_AJBS,C_AJLB,N_JBFY,N_ZT,C_AH FROM T_TASKITEM_CC
2> GO
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Table: T_TASKITEM_CI scan count 0, logical reads: (regular=6422447 apf=0 total=6422447), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Table: T_TASKITEM_CC scan count 1, logical reads: (regular=10957 apf=27 total=10984), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Total writes for this command: 11945
Execution Time 176.
Adaptive Server cpu time: 17350 ms. Adaptive Server elapsed time: 28206 ms.
(501132 rows affected)| category | Cluster Index | Non-clustered index |
|---|---|---|
| Write in | 11945 | 3538 |
| Read in | 6422447 | 2025588 |
| execution time | 28206 ms | 13381 ms |
Conclusion: Inserting the same amount of data, the time of non-clustered index table is twice as fast as that of clustered index table, and IO decreases by 2/3.
IV. Delete Contrast
- Construct deleted data
Sort by index field C_BH, and get the physical location of 100 rows, 200 rows. Five thousand rows of C_BH, the numbers to be deleted are stored in T_DELETE_CI_BH and T_DELETE_NCI_BH tables, respectively.
select C_BH,N_ORDER = identity(10) INTO T_ALL_CI_BH FROM T_TASKITEM_CI ORDER BY C_BH asc
SELECT C_BH,N_ORDER INTO T_DELETE_CI_BH FROM T_ALL_CI_BH WHERE N_ORDER%100 = 0
select C_BH,N_ORDER = identity(10) INTO T_ALL_NCI_BH FROM T_TASKITEM_NCI ORDER BY C_BH asc
SELECT C_BH,N_ORDER INTO T_DELETE_NCI_BH FROM T_ALL_NCI_BH WHERE N_ORDER%100 = 0- Cluster index table deletion
1> DELETE FROM T_TASKITEM_CI where C_BH IN (SELECT C_BH FROM T_DELETE_CI_BH)
2> go
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Table: T_TASKITEM_CI scan count 0, logical reads: (regular=20004 apf=0 total=20004), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Table: T_DELETE_CI_BH scan count 1, logical reads: (regular=31 apf=0 total=31), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Table: T_TASKITEM_CI scan count 5001, logical reads: (regular=15070 apf=0 total=15070), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Total writes for this command: 241
Execution Time 1.
Adaptive Server cpu time: 128 ms. Adaptive Server elapsed time: 379 ms.
(5001 rows affected)
- Delete non-clustered index tables
1> DELETE FROM T_TASKITEM_NCI where C_BH IN (SELECT C_BH FROM T_DELETE_NCI_BH)
2> go
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Parse and Compile Time 0.
Adaptive Server cpu time: 0 ms.
Table: T_TASKITEM_NCI scan count 0, logical reads: (regular=20004 apf=0 total=20004), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Table: T_DELETE_NCI_BH scan count 1, logical reads: (regular=31 apf=0 total=31), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Table: T_TASKITEM_NCI scan count 5001, logical reads: (regular=15070 apf=0 total=15070), physical reads: (regular=0 apf=0 total=0), apf IOs used=0
Total writes for this command: 242
Execution Time 1.
Adaptive Server cpu time: 128 ms. Adaptive Server elapsed time: 403 ms.
(5001 rows affected)
CONCLUSION: Cluster index and non-cluster index IO have the same efficiency as index field deletion.
Ranking Cluster Index
Cluster index table inserts unordered primary key (GUID/UUID) data, which will result in additional disk IO and time consumption. The project design using unordered primary key (GUID/UUID) prohibits the use of cluster index. So how to sort out the tables that illegally use cluster index in the project? Retrieval using sp_dba_citable stored procedure produced by DBA team
Core code:
use sybsystemprocs
GO
if object_id('sp_dba_citable') is not null
drop procedure sp_dba_citable
GO
create procedure sp_dba_citable
AS
--View Cluster Index Table
--add by wangzhen 2017-07-17
begin
declare @temp_sql varchar(500)
declare @sql varchar(1000)
declare @dbname varchar(100)
declare dbname_cursor cursor for select name from master..sysdatabases
create table #objectinfo (
dbname varchar(100),
objid int,
tablename varchar(300),
indexid int,
indexname varchar(300),
keycnt int,
indextype varchar(100)
)
set @temp_sql = 'insert into #objectinfo '
+ 'select ''@dbname#'' , '
+ 'obj.id , '
+ 'obj.name , '
+ 'ind.indid , '
+ 'ind.name , '
+ 'ind.keycnt , '
+ '''culster index'' '
+' from @dbname#..sysindexes ind left join @dbname#..sysobjects obj on ind.id = obj.id '
+' where (ind.status2 & 512 = 512 or ind.indid = 1) and obj.type = ''U'' '
open dbname_cursor
while @@sqlstatus =0
BEGIN
FETCH dbname_cursor into @dbname
set @sql = str_replace(@temp_sql,'@dbname#',@dbname)
EXECUTE(@sql)
END
close dbname_cursor
select
t.dbname as "Library name",
t.objid as "object ID",
t.tablename as "Table name",
t.indexname as "Index Name"
from #objectinfo t where t.dbname not in ('master','tempdb','sybsecurity','sybsystemdb','sybsystemprocs') group by t.dbname,t.objid,t.tablename,t.indexname,t.keycnt,t.indextype order by t.dbname asc,t.tablename asc
end
go summary
In clustered index, the storage order of physical data is the same as that of index. The lowest level of index contains actual data pages. Using clustered index to insert large amounts of data on unordered fields (GUID/UUID) is twice as slow as non-clustered index and three times as high as IO. In fact, NP has stipulated at the beginning of its design that physical primary keys (including clustered indexes) should not be defined in business tables, but logical primary keys (unique constraints + indexes + not empty). For projects using disordered primary keys (GUID/UUID), you can use sp_dba_citable to rank clustered index tables!