#The implementation mechanism of Linux 0.11 file system
##1, Overview
Linux 0.11 file system is similar to Minix 1.0 file system, which is an index file system. For Linux, everything is a file. Generally, there are common files, character device files, block device files, symbolic links, directory files, named pipes, etc. This is implemented by the file system, which abstracts the underlying layer and provides a unified access interface, such as open, read, write and other system calls. In fact, for the file system, each device has a unique identification mark, that is, the device number. Device number is a very important concept in Linux. For the same kind of device, such as two hard disks, the primary device number is the same, but the secondary device number is different. Because the drivers of the same kind of devices are similar, but we need to distinguish different hard disk partitions, so that we can implement a specific driver for each device, and then pass the secondary device number. For different hard disk partitions, the file systems on them are not necessarily the same. Linux does not have the concept of drive letter under Windows. Linux has only one root file system, that is, only one directory tree. How are other devices with file systems accessed? This is achieved by mounting the device in a directory of the root file system. This directory is the mount point, and it is also the root directory of the device. When we don't use the device, we have to unload it. In many modern new versions of Linux desktop system, the function of auto mount has been realized, such as CD, USB, etc.
The mount function of Linux solves the problem of accessing multiple devices. The mount function of Linux requires that it must be able to identify multiple file systems, so there must be multiple device drivers. However, it is impossible for Linux to compile all drivers into the kernel. In this way, the kernel will be very large, so the concept of module appears in modern Linux system.
The running speed of block device files is very slow, which is far behind the speed of memory. In order to reduce the number of accesses to block devices, Linux file system provides memory cache. In this way, when reading the data of the block device, first find it in the buffer, return it immediately if there is one, read it in the buffer if there is none, and then copy it to the user data buffer. Of course, the buffer is limited. When the buffer memory is not enough, the dirty buffer block that has not been used for a long time must be written to the disk. It is obvious that buffer can only have write operation in some cases, so when we want to unplug a device, we should uninstall it first, so that we can write to the disk, otherwise the data may be lost and the file system may be damaged.
File system unifies the use of a variety of devices and provides a unified interface for the upper layer. What is the concept of file system? From the perspective of the device, it is a format for storing data on the device. This format plans how to store common data and metadata, and improves the utilization rate of the device. In terms of driver, it is a software, including how to identify the path name, how to get the stored data, how to save the data, which users can access which data, how to share the data, etc.
This article explores the implementation mechanism of the file system from the top down through the source code of Linux 0.11. Similar articles have been written for the use of character device files. This article is not in-depth study, and can be referred to The use of Linux 0.11 character device
##2, Write data to block device
###2.1 equipment function
In system calls such as sys_read or sys_write, the specific file types are identified by depending on the mode attribute of the inode node, and then the specific device read and write function is called. For block devices, there are three types in Linux: virtual memory disk, hard disk and floppy disk. The write function is located in fs/block_dev.c(p293, Line 14). This is mainly about write operation, not read operation. It is mainly because write operation needs to read data to buffer first, then write to buffer, and finally buffer will write to disk at some time. This process is comprehensive and complex. Once understood, it is no problem to understand the source code of read function.
int block_write(int dev, long * pos, char * buf, int count) { int block = *pos >> BLOCK_SIZE_BITS; int offset = *pos & (BLOCK_SIZE-1); int chars; int written = 0; struct buffer_head * bh; register char * p; while (count>0) { chars = BLOCK_SIZE - offset; if (chars > count) chars=count; if (chars == BLOCK_SIZE) bh = getblk(dev,block); else bh = breada(dev,block,block+1,block+2,-1); block++; if (!bh) return written?written:-EIO; p = offset + bh->b_data; offset = 0; *pos += chars; written += chars; count -= chars; while (chars-->0) *(p++) = get_fs_byte(buf++); bh->b_dirt = 1; brelse(bh); } return written; }
First, block? Size? Bits, block? Size is located in include/linux/fs.h (p394, line 49):
#define BLOCK_SIZE 1024 #define BLOCK_SIZE_BITS 10
Here, the whole device is regarded as a large file, and pos is the offset of this file. It starts from the first block of the whole device, regardless of whether the boot block or super block is used. But for block devices, the basic unit of operation is block. Here, we define a block size of 1024KB, that is, two sectors. Map the pos to the offset offset of the specific block, read the disk data to the buffer block, copy the user's data to the buffer block, similar to overwrite, and finally release the buffer block (the count attribute minus one). The idea of ahead of time reading is used here, reading two blocks ahead of time (breada), so that the next time you can get directly from the buffer (getblk).
##3, Cache
###3.1 get a buffer block getblk
getblk is located in fs/buffer.c (p247, 206):
/* * Ok, this is getblk, and it isn't very clear, again to hinder * race-conditions. Most of the code is seldom used, (ie repeating), * so it should be much more efficient than it looks. * * The algoritm is changed: hopefully better, and an elusive bug removed. */ #define BADNESS(bh) (((bh)->b_dirt<<1)+(bh)->b_lock) struct buffer_head * getblk(int dev,int block) { struct buffer_head * tmp, * bh; repeat: if ((bh = get_hash_table(dev,block))) return bh; tmp = free_list; do { if (tmp->b_count) continue; if (!bh || BADNESS(tmp)<BADNESS(bh)) { bh = tmp; if (!BADNESS(tmp)) break; } /* and repeat until we find something good */ } while ((tmp = tmp->b_next_free) != free_list); if (!bh) { sleep_on(&buffer_wait); goto repeat; } wait_on_buffer(bh); if (bh->b_count) goto repeat; while (bh->b_dirt) { sync_dev(bh->b_dev); wait_on_buffer(bh); if (bh->b_count) goto repeat; } /* NOTE!! While we slept waiting for this block, somebody else might */ /* already have added "this" block to the cache. check it */ if (find_buffer(dev,block)) goto repeat; /* OK, FINALLY we know that this buffer is the only one of it's kind, */ /* and that it's unused (b_count=0), unlocked (b_lock=0), and clean */ bh->b_count=1; bh->b_dirt=0; bh->b_uptodate=0; remove_from_queues(bh); bh->b_dev=dev; bh->b_blocknr=block; insert_into_queues(bh); return bh; }
This function first checks whether the buffer block already exists through get hash table, and returns directly if it exists. Otherwise, traverse the free list. When all the buffer blocks of the free list are used (count > 0), it will go to sleep and be added to the buffer wait list. It will start again later. Otherwise, wait for unlocking. The competition conditions are considered here. There are multiple repeated judgments, and the conditions that are satisfied are judged again after each sleep. When the data block is not used, but the dirty flag is set, all inode s and blocks of the corresponding devices of the block are written to disk (write disk request is initiated). Here, wait ﹣ on ﹣ buffer will cause sleep, because the disk will be locked during write. After the write disk is finished, it is necessary to judge whether it is in the hash queue. If it is, it will start again. Otherwise, it will get a clean buffer block. Remove the buffer block from the old queue and add it to the new queue, i.e. the head of the hash table and the tail of the idle table. In this way, the existing block can be quickly found and the latest one is written.
The hash function uses the exclusive or of device number and logical block number, and the queue is a two-way linked list. The free list is a two-way circular list. The final returned block data may already exist, or it may return an unused block without data.
###3.2 other buffer related functions
The hash function is defined as follows:
#define _hashfn(dev,block) (((unsigned)(dev^block))%NR_HASH) #define hash(dev,block) hash_table[_hashfn(dev,block)]
find_buffer traverses the hash queue to see if the buffer block exists. Note that this function is static and will not be used by external files.
static struct buffer_head * find_buffer(int dev, int block) { struct buffer_head * tmp; for (tmp = hash(dev,block) ; tmp != NULL ; tmp = tmp->b_next) if (tmp->b_dev==dev && tmp->b_blocknr==block) return tmp; return NULL; }
Get hash table encapsulates the find buffer. Considering the competition conditions, add one to the reference count first. When the buffer block is in the queue, if it is locked, it needs to sleep and wait. After that, it needs to check whether the corresponding block has been modified. If not, it returns.
/* * Why like this, I hear you say... The reason is race-conditions. * As we don't lock buffers (unless we are readint them, that is), something might happen to it while we sleep (ie a read-error will force it bad). This shouldn't really happen currently, but the code is ready. */ struct buffer_head * get_hash_table(int dev, int block) { struct buffer_head * bh; for (;;) { if (!(bh=find_buffer(dev,block))) return NULL; bh->b_count++; wait_on_buffer(bh); if (bh->b_dev == dev && bh->b_blocknr == block) return bh; bh->b_count--; } }
Wait on buffer is used to make the current process sleep when the data is being read or when the write disk is waiting to use the buffer block. Note that when multiple processes request the same blocked buffer block, a sleep chain will be formed.
static inline void wait_on_buffer(struct buffer_head * bh) { cli(); while (bh->b_lock) sleep_on(&bh->b_wait); sti(); }
Sync? Dev will write all dirty blocks and inode s of the specified device to disk to generate write requests.
int sync_dev(int dev) { int i; struct buffer_head * bh; bh = start_buffer; for (i=0 ; i<NR_BUFFERS ; i++,bh++) { if (bh->b_dev != dev) continue; wait_on_buffer(bh); if (bh->b_dev == dev && bh->b_dirt) ll_rw_block(WRITE,bh); } sync_inodes(); bh = start_buffer; for (i=0 ; i<NR_BUFFERS ; i++,bh++) { if (bh->b_dev != dev) continue; wait_on_buffer(bh); if (bh->b_dev == dev && bh->b_dirt) ll_rw_block(WRITE,bh); } return 0; }
Remove from queues is mainly to remove bh from hash queue and idle linked list.
static inline void remove_from_queues(struct buffer_head * bh) { /* remove from hash-queue */ if (bh->b_next) bh->b_next->b_prev = bh->b_prev; if (bh->b_prev) bh->b_prev->b_next = bh->b_next; if (hash(bh->b_dev,bh->b_blocknr) == bh) hash(bh->b_dev,bh->b_blocknr) = bh->b_next; /* remove from free list */ if (!(bh->b_prev_free) || !(bh->b_next_free)) panic("Free block list corrupted"); bh->b_prev_free->b_next_free = bh->b_next_free; bh->b_next_free->b_prev_free = bh->b_prev_free; if (free_list == bh) free_list = bh->b_next_free; }
Insert > into > queues inserts bh at the end of the free list, the head of the hash queue.
static inline void insert_into_queues(struct buffer_head * bh) { /* put at end of free list */ bh->b_next_free = free_list; bh->b_prev_free = free_list->b_prev_free; free_list->b_prev_free->b_next_free = bh; free_list->b_prev_free = bh; /* put the buffer in new hash-queue if it has a device */ bh->b_prev = NULL; bh->b_next = NULL; if (!bh->b_dev) return; bh->b_next = hash(bh->b_dev,bh->b_blocknr); hash(bh->b_dev,bh->b_blocknr) = bh; bh->b_next->b_prev = bh; }
###3.3 read more breada
This function first obtains the corresponding block, and determines whether the block has been updated, that is, it can be read. If it can be read, it is the existing block in the hash queue. Otherwise, a read request must be generated with ll? RW? Block. The bh in the following function loop should be tmp. A read request is generated for another consecutive buffer block, but only wait for the first buffer block to unlock, and wait for the data to be read from the disk. This function is the interface provided by the buffer.
/* * Ok, breada can be used as bread, but additionally to mark other * blocks for reading as well. End the argument list with a negative * number. */ struct buffer_head * breada(int dev,int first, ...) { va_list args; struct buffer_head * bh, *tmp; va_start(args,first); if (!(bh=getblk(dev,first))) panic("bread: getblk returned NULL\n"); if (!bh->b_uptodate) ll_rw_block(READ,bh); while ((first=va_arg(args,int))>=0) { tmp=getblk(dev,first); if (tmp) { if (!tmp->b_uptodate) ll_rw_block(READA,bh); tmp->b_count--; } } va_end(args); wait_on_buffer(bh); if (bh->b_uptodate) return bh; brelse(bh); return (NULL); }
##4, Block device underlying operation
###4.1 upper interface ll? RW? Block
The ll? RW? Block function is located in kernel / BLK? DRV / ll? RW? Block. C (p153, line 145)
void ll_rw_block(int rw, struct buffer_head * bh) { unsigned int major; if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV || !(blk_dev[major].request_fn)) { printk("Trying to read nonexistent block-device\n\r"); return; } make_request(major,rw,bh); }
Where rw represents a read or write request, and bh is used to transfer data or save data. First, judge whether it is a valid device through the primary device number, and whether the request function exists at the same time. If it is a valid device and the function exists, i.e. there is a driver, the request is added to the related linked list.
###4.2 make request
This function first determines whether to read or write ahead of time. If so, it depends on whether bh is locked. If the lock is applied, it will return directly, because it is unnecessary to operate in advance. Otherwise, it will be translated into recognizable reading or writing. **Then lock the buffer. **If it is a write operation but the buffer is not dirty, or a read operation but the buffer has been updated, it is returned directly.
Then look for a request, and notice that the last 1 / 3 is reserved for the read operation. If it is not found, it will return directly for early reading. Otherwise, it will enter sleep and be added to the wait for request list. Finally, the req is filled with the information of the bh header, the block number is transformed into the sector number, two sectors are read and added to the request list of the corresponding device.
static void make_request(int major,int rw, struct buffer_head * bh) { struct request * req; int rw_ahead; /* WRITEA/READA is special case - it is not really needed, so if the buffer is locked, we just forget about it, else it's a normal read */ if ((rw_ahead = (rw == READA || rw == WRITEA))) { if (bh->b_lock) return; if (rw == READA) rw = READ; else rw = WRITE; } if (rw!=READ && rw!=WRITE) panic("Bad block dev command, must be R/W/RA/WA"); lock_buffer(bh); if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) { unlock_buffer(bh); return; } repeat: /* we don't allow the write-requests to fill up the queue completely: we want some room for reads: they take precedence. The last third of the requests are only for reads. */ if (rw == READ) req = request+NR_REQUEST; else req = request+((NR_REQUEST*2)/3); /* find an empty request */ while (--req >= request) if (req->dev<0) break; /* if none found, sleep on new requests: check for rw_ahead */ if (req < request) { if (rw_ahead) { unlock_buffer(bh); return; } sleep_on(&wait_for_request); goto repeat; } /* fill up the request-info, and add it to the queue */ req->dev = bh->b_dev; req->cmd = rw; req->errors=0; req->sector = bh->b_blocknr<<1; req->nr_sectors = 2; req->buffer = bh->b_data; req->waiting = NULL; req->bh = bh; req->next = NULL; add_request(major+blk_dev,req); }
###4.3 Linux elevator scheduling algorithm add Ou request
When the device does not request an operation, it directly calls the request function. For the hard disk, it is do? HD? Request. Otherwise, traverse the request list and insert the current req. Here, the elevator scheduling algorithm is used.
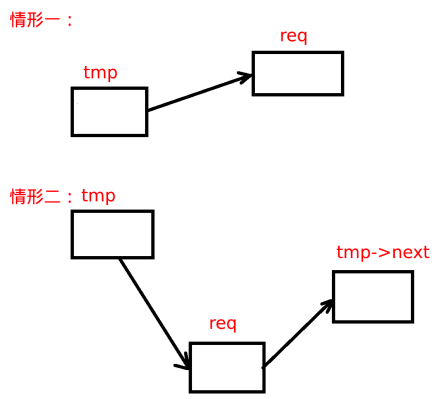
Note: req cannot be inserted at the beginning because the beginning item is in operation. The main idea here is to consider that the time consumption of the disk's arm moving is large, either from inside to outside, or from outside to inside, processing requests in a certain direction. If req is just on the top of the head moving, you can process it first, which can save IO time.
/* * add-request adds a request to the linked list. * It disables interrupts so that it can muck with the * request-lists in peace. */ static void add_request(struct blk_dev_struct * dev, struct request * req) { struct request * tmp; req->next = NULL; cli(); if (req->bh) req->bh->b_dirt = 0; if (!(tmp = dev->current_request)) { dev->current_request = req; sti(); (dev->request_fn)(); return; } for ( ; tmp->next ; tmp=tmp->next) if ((IN_ORDER(tmp,req) || !IN_ORDER(tmp,tmp->next)) && IN_ORDER(req,tmp->next)) break; req->next=tmp->next; tmp->next=req; sti(); }
Where IN_ORDER is in kernel/blk_drv/blk.h (p134, line 35)
/* * This is used in the elevator algorithm: Note that * reads always go before writes. This is natural: reads * are much more time-critical than writes. */ #define IN_ORDER(s1,s2) \ ((s1)->cmd<(s2)->cmd || ((s1)->cmd==(s2)->cmd && \ ((s1)->dev < (s2)->dev || ((s1)->dev == (s2)->dev && \ (s1)->sector < (s2)->sector))))
The meaning of this macro is that the read request is in front of the write request; for the same request, the lower device number is in front, that is, the lower partition is in front; or for the same device number, that is, the same partition, the lower sector number is in front.
###4.4 correlation function
Here's a look at the file blk.h:
#ifndef _BLK_H #define _BLK_H #define NR_BLK_DEV 7 /* * NR_REQUEST is the number of entries in the request-queue. * NOTE that writes may use only the low 2/3 of these: reads take precedence. * 32 seems to be a reasonable number: enough to get some benefit from the elevator-mechanism, but not so much as to lock a lot of buffers when they are in the queue. 64 seems to be too many (easily long pauses in reading when heavy writing/syncing is going on) */ #define NR_REQUEST 32 /* Ok, this is an expanded form so that we can use the same request for paging requests when that is implemented. In paging, 'bh' is NULL, and 'waiting' is used to wait for read/write completion. */ struct request { int dev; /* -1 if no request */ int cmd; /* READ or WRITE */ int errors; unsigned long sector; unsigned long nr_sectors; char * buffer; struct task_struct * waiting; struct buffer_head * bh; struct request * next; }; /* * This is used in the elevator algorithm: Note that * reads always go before writes. This is natural: reads * are much more time-critical than writes. */ #define IN_ORDER(s1,s2) \ ((s1)->cmd<(s2)->cmd || ((s1)->cmd==(s2)->cmd && \ ((s1)->dev < (s2)->dev || ((s1)->dev == (s2)->dev && \ (s1)->sector < (s2)->sector)))) struct blk_dev_struct { void (*request_fn)(void); struct request * current_request; }; extern struct blk_dev_struct blk_dev[NR_BLK_DEV]; extern struct request request[NR_REQUEST]; extern struct task_struct * wait_for_request; #ifdef MAJOR_NR /* * Add entries as needed. Currently the only block devices * supported are hard-disks and floppies. */ #if (MAJOR_NR == 1) /* ram disk */ #define DEVICE_NAME "ramdisk" #define DEVICE_REQUEST do_rd_request #define DEVICE_NR(device) ((device) & 7) #define DEVICE_ON(device) #define DEVICE_OFF(device) #elif (MAJOR_NR == 2) /* floppy */ #define DEVICE_NAME "floppy" #define DEVICE_INTR do_floppy #define DEVICE_REQUEST do_fd_request #define DEVICE_NR(device) ((device) & 3) #define DEVICE_ON(device) floppy_on(DEVICE_NR(device)) #define DEVICE_OFF(device) floppy_off(DEVICE_NR(device)) #elif (MAJOR_NR == 3) /* harddisk */ #define DEVICE_NAME "harddisk" #define DEVICE_INTR do_hd #define DEVICE_REQUEST do_hd_request #define DEVICE_NR(device) (MINOR(device)/5) #define DEVICE_ON(device) #define DEVICE_OFF(device) #elif 1 /* unknown blk device */ #error "unknown blk device" #endif #define CURRENT (blk_dev[MAJOR_NR].current_request) #define CURRENT_DEV DEVICE_NR(CURRENT->dev) #ifdef DEVICE_INTR void (*DEVICE_INTR)(void) = NULL; #endif static void (DEVICE_REQUEST)(void); static inline void unlock_buffer(struct buffer_head * bh) { if (!bh->b_lock) printk(DEVICE_NAME ": free buffer being unlocked\n"); bh->b_lock=0; wake_up(&bh->b_wait); } static inline void end_request(int uptodate) { DEVICE_OFF(CURRENT->dev); if (CURRENT->bh) { CURRENT->bh->b_uptodate = uptodate; unlock_buffer(CURRENT->bh); } if (!uptodate) { printk(DEVICE_NAME " I/O error\n\r"); printk("dev %04x, block %d\n\r",CURRENT->dev, CURRENT->bh->b_blocknr); } wake_up(&CURRENT->waiting); wake_up(&wait_for_request); CURRENT->dev = -1; CURRENT = CURRENT->next; } #define INIT_REQUEST \ repeat: \ if (!CURRENT) \ return; \ if (MAJOR(CURRENT->dev) != MAJOR_NR) \ panic(DEVICE_NAME ": request list destroyed"); \ if (CURRENT->bh) { \ if (!CURRENT->bh->b_lock) \ panic(DEVICE_NAME ": block not locked"); \ } #endif #endif
This file defines the structure of BLK? Dev, that is, the request function of the device (initialized in the init function of each device, and do? HD? Request for the hard disk), and the header of the corresponding request list (NULL at the beginning, defined in ll? RW? BLK. C). There are 7 items in total. The request is defined with 32 items in total. When the attribute dev = -1, it means that the request is not used. Three request functions for block devices are defined. Obviously, this file is to be included, and the macro major? NR, the main device number, must be defined before this file to indicate which device to use. CURRENT represents the request header, and CURRENT dev represents the secondary device number. End ﹣ request is also defined here, that is, after the interruption, move the request list to the next item, release the processed request, dev = -1, and wake up wait ﹣ for ﹣ request, indicating that there is a request available. The most important thing is to unlock and wake up the process waiting for the buffer block.
##5, Hard disk driver
In add request, if the current header dev - > current request is empty, call directly (dev - > request fn()). This function is the key function to start reading and writing. There is a request FN function for each device. Here's a hard disk.
###5.1 do HD request
Do HD request in kernel / BLK DRV / HD. C (p145, line 294)
void do_hd_request(void) { int i,r = 0; unsigned int block,dev; unsigned int sec,head,cyl; unsigned int nsect; INIT_REQUEST; dev = MINOR(CURRENT->dev); block = CURRENT->sector; if (dev >= 5*NR_HD || block+2 > hd[dev].nr_sects) { end_request(0); goto repeat; } block += hd[dev].start_sect; dev /= 5; __asm__("divl %4":"=a" (block),"=d" (sec):"0" (block),"1" (0), "r" (hd_info[dev].sect)); __asm__("divl %4":"=a" (cyl),"=d" (head):"0" (block),"1" (0), "r" (hd_info[dev].head)); sec++; nsect = CURRENT->nr_sectors; if (reset) { reset = 0; recalibrate = 1; reset_hd(CURRENT_DEV); return; } if (recalibrate) { recalibrate = 0; hd_out(dev,hd_info[CURRENT_DEV].sect,0,0,0, WIN_RESTORE,&recal_intr); return; } if (CURRENT->cmd == WRITE) { hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr); for(i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++) /* nothing */ ; if (!r) { bad_rw_intr(); goto repeat; } port_write(HD_DATA,CURRENT->buffer,256); } else if (CURRENT->cmd == READ) { hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr); } else panic("unknown hd-command"); }
Do HD request first checks whether the header of the hard disk device is empty. If it is empty, it returns directly. Otherwise, obtain the secondary device number of the header request item, convert the starting sector number to the absolute sector number (LBA), and then convert the absolute sector number to the sector number, head number and cylinder number. For writing hard disk, first pass the specific hard disk (the first or second block), the number of written sectors, sector code, head number, cylinder number, write command, and the corresponding write interrupt function pointer to the HD UUT function, so as to write the relevant parameters to the corresponding registers of the hard disk, and then wait for a while, and then write the data of a sector to the hard disk. For the read hard disk, only the relevant parameters are passed to HD ﹐ out.
5.2 fill in HD ﹣ out
This function mainly writes the relevant parameters to the corresponding registers of the hard disk, and sets the global interrupt handle do? HD, which indicates the function of the next interrupt call on the hard disk. For read, do? HD = read? Intr, and for write, do? HD = write? Intr.
static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect, unsigned int head,unsigned int cyl,unsigned int cmd, void (*intr_addr)(void)) { register int port asm("dx"); if (drive>1 || head>15) panic("Trying to write bad sector"); if (!controller_ready()) panic("HD controller not ready"); do_hd = intr_addr; outb_p(hd_info[drive].ctl,HD_CMD); port=HD_DATA; outb_p(hd_info[drive].wpcom>>2,++port); outb_p(nsect,++port); outb_p(sect,++port); outb_p(cyl,++port); outb_p(cyl>>8,++port); outb_p(0xA0|(drive<<4)|head,++port); outb(cmd,++port); }
###5.3 hard disk drive
Why does the hard disk call do? HD? This can be learned from the handle of the hard disk interrupt:
void hd_init(void) { blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST; set_intr_gate(0x2E,&hd_interrupt); outb_p(inb_p(0x21)&0xfb,0x21); outb(inb_p(0xA1)&0xbf,0xA1); }
Obviously, the entry function of hard disk interrupt is set as hd_interrupt. This function is located in kernel / system call. S (p89, line 221):
hd_interrupt: pushl %eax pushl %ecx pushl %edx push %ds push %es push %fs movl $0x10,%eax mov %ax,%ds mov %ax,%es movl $0x17,%eax mov %ax,%fs movb $0x20,%al outb %al,$0xA0 # EOI to interrupt controller #1 jmp 1f # give port chance to breathe 1: jmp 1f 1: xorl %edx,%edx xchgl do_hd,%edx testl %edx,%edx jne 1f movl $unexpected_hd_interrupt,%edx 1: outb %al,$0x20 call *%edx # "interesting" way of handling intr. pop %fs pop %es pop %ds popl %edx popl %ecx popl %eax iret
This code is mainly to interrupt the end command word to 8259A, and then judge whether do? HD is empty. If it is not empty, then do? HD will be called.
Let's take a look at read? Intr and write? Intr:
static void read_intr(void) { if (win_result()) { bad_rw_intr(); do_hd_request(); return; } port_read(HD_DATA,CURRENT->buffer,256); CURRENT->errors = 0; CURRENT->buffer += 512; CURRENT->sector++; if (--CURRENT->nr_sectors) { do_hd = &read_intr; return; } end_request(1); do_hd_request(); } static void write_intr(void) { if (win_result()) { bad_rw_intr(); do_hd_request(); return; } if (--CURRENT->nr_sectors) { CURRENT->sector++; CURRENT->buffer += 512; do_hd = &write_intr; port_write(HD_DATA,CURRENT->buffer,256); return; } end_request(1); do_hd_request(); }
These two functions are to reduce the number of sectors before operation, then increase the requested starting sector, and add the starting address of the buffer block to the length of one sector. As long as the number of sectors of the operation is not zero, the current request item is processed continuously. For read requests, read the data from the hard disk to the buffer, and use port read; for write requests, write the data in the buffer to the hard disk buffer, and use port write. The command is no longer sent to the register because the command requesting data from two sectors has already been sent. Only when the current request item is processed will the end "request be processed, and the next item will be processed. It's kind of like a linked list.

