This article has been included in a Zhuang's personal website: https://jonssonyan.com , welcome to comment and forward.
Hi, everyone. I'm Zhuang, a compassionate programmer.
ID is the unique identification of data. The traditional method is to use UUID and self incrementing ID of database. In Internet enterprises, most companies use MySQL and usually use Innodb storage engine because they need transaction support. UUID is too long and disordered, so it is not suitable to use Innodb as the primary key. Self incrementing ID is more suitable, but with the development of the company's business, The amount of data will be larger and larger, so it is necessary to divide the data into tables. After dividing the tables, the data in each table will increase automatically according to its own rhythm, and there is likely to be ID conflict. At this time, a separate mechanism is needed to generate a unique ID. the generated ID can also be called distributed ID or global ID.
Why does the database primary key use an incremental sequence?
Sequential IDS occupy less space than random IDs.
The reason is that the database primary key and index are stored in the data structure of B + tree. The sequential ID data is stored in the last position of the last node, and the data of the previous node is full. When storing random IDS, there may be node splitting, resulting in more nodes, but the amount of data of each node is less. When storing in the file system, no matter whether the data in the node is full or not, it will occupy one page of space. Therefore, it takes up a large amount of space.
Why is UUID not suitable for primary key?
The UUID value is determined by the local Mac address, timestamp and other factors. The repetition probability of UUID is very negligible.
If the requirement is only to ensure uniqueness, UUID can also be used. However, according to the requirements of distributed id above, UUID can not be made into distributed id for the following reasons:
- First of all, distributed IDS are generally used as primary keys, but mysql officially recommends that primary keys should be as short as possible. Each UUID is very long, so it is not recommended
- Since the distributed id is the primary key, then the primary key contains the index, and then the mysql index is implemented through the b + tree, every time a new UUID data is inserted, the b + tree at the bottom of the index will be modified for query optimization. Because the UUID data is disordered, every UUID data insertion will greatly modify the b + tree in the primary key dungeon, This is very bad
- Information insecurity: the algorithm of generating UUID based on MAC address may cause MAC address disclosure. This vulnerability has been used to find the location of the creator of Melissa virus.
Java implementation UUID
package com.one.util;
import java.util.UUID;
public class Test {
public static void main(String[] args) {
String uuid= UUID.randomUUID().toString().replace("-", "").toLowerCase();
System.out.println("UUID The value of is:"+uuid);
}
}
Requirements as primary key
- order
- only
- Can be short is short, reduce space occupation
Self increasing ID S can meet most business scenarios, but they are not suitable in some special scenarios. Just give some examples
- In distributed system
- Database design of sub database and sub table
- There are some security problems. For some sensitive information, such as the amount of data, it is easy to speculate.
Comparison of common ID solutions
| describe | advantage | shortcoming | shortcoming |
|---|---|---|---|
| UUID | UUID is the abbreviation of universal unique identification code. Its purpose is that all elements in the distributed system have unique identification information, and there is no need to specify the unique identification through the central controller. | 1. Reduce the pressure on global nodes and make the generation of primary keys faster; 2. The generated primary key is globally unique; 3. It is convenient to merge data across servers | 1. UUID takes up 16 characters and takes up a lot of space; 2. It is not a number that increases in order. The randomness of data writing IO is great, and the index efficiency is reduced |
| Database primary key auto increment | MySQL database sets the primary key and the primary key grows automatically | 1. INT and BIGINT types occupy less space; 2. The primary key grows automatically, and IO writing continuity is good; 3. The query speed of digital type is better than that of string | 1. The concurrency performance is not high, which is limited by the database performance; 2. Sub warehouse and sub table, which needs transformation and is complex; 3. Self increment: data leakage |
| Redis self increment | Redis counter, atomic self incrementing | Using memory, good concurrency performance | 1. Data loss; 2. Self increasing: data leakage |
| Snow flake algorithm | The famous snowflake algorithm is the classic solution of distributed ID | 1. Independent of external components; 2. Good performance | 1. Clock callback; 2. Trend increase is not absolute increase; 3. Multiple distributed ID services cannot be deployed on one server; |
Popular distributed ID solutions
Snow flake algorithm
Snowflake algorithm is composed of symbol bit + timestamp + working machine id + serial number
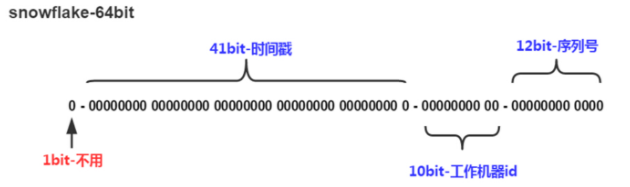
explain
-
The sign bit is 0, 0 represents a positive number, and the ID is a positive number.
-
Needless to say, the time stamp bit is used to store the time stamp. The unit is ms.
-
The working machine id bit is used to store the machine id, which is usually divided into 5 area bits + 5 server identification bits.
Java implementation of Snowflake algorithm on Twitter
public class SnowflakeIdWorker {
private static SnowflakeIdWorker instance = new SnowflakeIdWorker(0,0);
/**
* Start date (January 1, 2015)
*/
private final long twepoch = 1420041600000L;
/**
* Number of digits occupied by machine id
*/
private final long workerIdBits = 5L;
/**
* Number of bits occupied by data id
*/
private final long datacenterIdBits = 5L;
/**
* The maximum machine id supported is 31 (this shift algorithm can quickly calculate the maximum decimal number represented by several binary numbers)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* The maximum data id supported is 31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* The number of bits the sequence occupies in the id
*/
private final long sequenceBits = 12L;
/**
* The machine ID shifts 12 bits to the left
*/
private final long workerIdShift = sequenceBits;
/**
* Data id shifts 17 bits to the left (12 + 5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* Shift the time cut to the left by 22 bits (5 + 5 + 12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* The mask of the generated sequence is 4095 (0b111111 = 0xfff = 4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* Working machine ID(0~31)
*/
private long workerId;
/**
* Data center ID(0~31)
*/
private long datacenterId;
/**
* Sequence in milliseconds (0 ~ 4095)
*/
private long sequence = 0L;
/**
* Last generated ID
*/
private long lastTimestamp = -1L;
/**
* Constructor
* @param workerId Job ID (0~31)
* @param datacenterId Data center ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* Get the next ID (this method is thread safe)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
// If the current time is less than the timestamp generated by the last ID, it indicates that the system clock has fallback, and an exception should be thrown at this time
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
// If it is generated at the same time, the sequence within milliseconds is performed
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
// Sequence overflow in milliseconds
if (sequence == 0) {
//Block to the next millisecond and get a new timestamp
timestamp = tilNextMillis(lastTimestamp);
}
}
// The timestamp changes and the sequence resets in milliseconds
else {
sequence = 0L;
}
// Last generated ID
lastTimestamp = timestamp;
// Shift and put together by or operation to form a 64 bit ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* Block to the next millisecond until a new timestamp is obtained
* @param lastTimestamp Last generated ID
* @return Current timestamp
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* Returns the current time in milliseconds
* @return Current time (MS)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
public static SnowflakeIdWorker getInstance(){
return instance;
}
public static void main(String[] args) throws InterruptedException {
SnowflakeIdWorker idWorker = SnowflakeIdWorker.getInstance();
for (int i = 0; i < 10; i++) {
long id = idWorker.nextId();
Thread.sleep(1);
System.out.println(id);
}
}
}
Segment mode
The number segment mode can be understood as obtaining self incrementing IDs from the database in batches. One number segment range is taken out from the database each time. For example, (11000] represents 1000 IDs. The specific business service generates 1 ~ 1000 self incrementing IDs from this number segment and loads them into memory. The table structure is as follows:
CREATE TABLE id_generator ( id int(10) NOT NULL, max_id bigint(20) NOT NULL COMMENT 'Current maximum id', step int(20) NOT NULL COMMENT 'Cloth length of section', biz_type int(20) NOT NULL COMMENT 'Business type', version int(20) NOT NULL COMMENT 'Version number', PRIMARY KEY (`id`) )
-
biz_type: represents different business types
-
max_id: the current maximum available id
-
step: represents the length of the number segment
-
Version: it is an optimistic lock. It updates version every time to ensure the correctness of data during concurrency
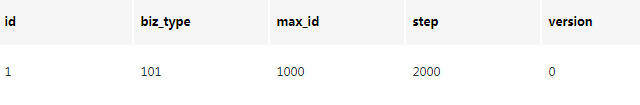
When the ID of this batch number segment is used up, apply for a new batch number segment from the database again, right_ Update the ID field once, update max_id= max_id + step, if the update is successful, the new number segment is successful. The range of the new number segment is (max_id, max_id + step].
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
Since multiple business terminals may operate at the same time, the version number version optimistic locking method is adopted for updating. This distributed ID generation method does not rely strongly on the database, does not frequently access the database, and has much less pressure on the database.
Other solutions
- TinyID Github address: https://github.com/didi/tinyid
- Baidu GitHub address: https://github.com/baidu/uid-generator
- Leaf GitHub address: https://github.com/Meituan-Dianping/Leaf
I'm a Zhuang, wechat search: Tech cat, pay attention to this caring programmer. I'll see you next time