As a memory based cache system, Redis has always been known for its high performance. Without context switching and lock free operation, even in the case of single thread processing, the read speed can reach 110000 times / s and the write speed can reach 81000 times / s. However, the single thread design also brings some problems to Redis:
-
Only one CPU core can be used;
-
If the deleted key is too large (for example, there are millions of objects in the Set type), the server will be blocked for several seconds;
-
QPS is difficult to improve.
To solve the above problems, Redis introduced Lazy Free and multithreaded IO in versions 4.0 and 6.0, respectively, and gradually transitioned to multithreading, which will be described in detail below.
Single thread principle
It is said that Redis is single threaded, so how does single thread reflect? How to support concurrent requests from clients?
To understand these problems, let's first understand how Redis works.
Redis server is an event driver. The server needs to handle the following two types of events:
-
File event: Redis server communicates with client through socket (or other Redis servers) to connect, and file events are the server's abstraction of socket operations; the communication between the server and the client will generate corresponding file events, and the server will complete a series of network communication operations by listening to and processing these events, such as connection accept, read, write, close, etc;
-
Time event: some operations in Redis server (such as serverCron function) need to be executed at a given time point, and time event is the server's abstraction of such scheduled operations, such as expired key cleaning, service status statistics, etc.
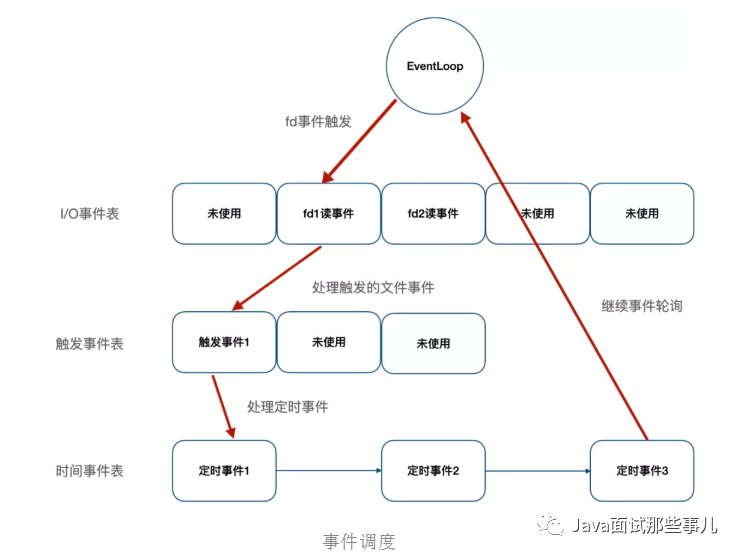
As shown in the figure above, redis abstracts file events and time events. The time rotation trainer will listen to the I/O event table. Once a file event is ready, redis will give priority to file events and then deal with time events. Redis handles all the above events in the form of single thread, so redis is single thread. In addition, as shown in the figure below, redis has developed its own I/O event processor based on Reactor mode, that is, file event processor. Redis adopts I/O multiplexing technology in I/O event processing, listens to multiple sockets at the same time, associates different event processing functions for sockets, and realizes multi client concurrent processing through one thread.
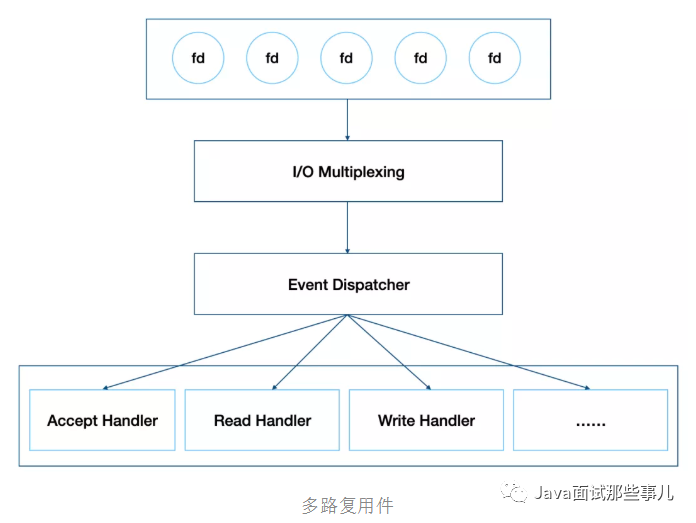
Because of this design, locking operation is avoided in data processing, which not only makes the implementation simple enough, but also ensures its high performance. Of course, Redis single thread only refers to its event processing. In fact, Redis is not single thread. For example, when generating RDB files, it will fork a sub process. Of course, this is not the content to be discussed in this article.
Lazy Free mechanism
As we know above, Redis runs in the form of single thread when processing client commands, and the processing speed is very fast. During this period, it will not respond to other client requests. However, if the client sends a long-time command to Redis, such as deleting a Set key containing millions of objects, or executing flushdb and flushall operations, Redis server needs to reclaim a lot of memory space, It will cause the server to jam for several seconds, which will be a disaster for the cache system with high load. In order to solve this problem, Lazy Free is introduced in Redis version 4.0 to asynchronize slow operations, which is also a step towards multithreading in event processing.
As the author said in his blog, to solve the problem of slow operation, we can adopt progressive processing, that is, add a time event. For example, when deleting a Set key with millions of objects, only part of the data in the big key is deleted each time, and finally the big key is deleted. However, this scheme may cause the recovery speed to catch up with the creation speed, and eventually lead to memory depletion. Therefore, the final implementation of Redis is to asynchronize the deletion of large keys and adopt non blocking deletion (corresponding command UNLINK). The space recovery of large keys is implemented by a separate thread. The main thread only cancels the relationship, can return quickly and continue to process other events to avoid long-term blocking of the server.
Take delete (DEL command) as an example to see how Redis is implemented. The following is the entry of the delete function. lazyfree_lazy_user_del is whether to modify the default behavior of the DEL command. Once enabled, DEL will be executed in the form of UNLINK.
void delCommand(client *c) {
delGenericCommand(c,server.lazyfree_lazy_user_del);
}
/* This command implements DEL and LAZYDEL. */
void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
for (j = 1; j < c->argc; j++) {
expireIfNeeded(c->db,c->argv[j]);
// Determine whether DEL is executed in lazy form according to the configuration
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
if (deleted) {
signalModifiedKey(c,c->db,c->argv[j]);
notifyKeyspaceEvent(NOTIFY_GENERIC,
"del",c->argv[j],c->db->id);
server.dirty++;
numdel++;
}
}
addReplyLongLong(c,numdel);
}
Synchronous deletion is very simple. Just delete the key and value. If there is an inner reference, it will be deleted recursively. It will not be introduced here. Let's take a look at asynchronous deletion. When Redis recycles objects, it will first calculate the recycling revenue. Only when the recycling revenue exceeds a certain value, it will be encapsulated into a Job and added to the asynchronous processing queue. Otherwise, it will be recycled directly synchronously, which is more efficient. The calculation of recovery income is also very simple. For example, for String type, the recovery income value is 1, while for Set type, the recovery income is the number of elements in the Set.
/* Delete a key, value, and associated expiration entry if any, from the DB.
* If there are enough allocations to free the value object may be put into
* a lazy free list instead of being freed synchronously. The lazy free list
* will be reclaimed in a different bio.c thread. */
#define LAZYFREE_THRESHOLD 64
int dbAsyncDelete(redisDb *db, robj *key) {
/* Deleting an entry from the expires dict will not free the sds of
* the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
/* If the value is composed of a few allocations, to free in a lazy way
* is actually just slower... So under a certain limit we just free
* the object synchronously. */
dictEntry *de = dictUnlink(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
// Calculate the recovery income of value
size_t free_effort = lazyfreeGetFreeEffort(val);
/* If releasing the object is too much work, do it in the background
* by adding the object to the lazy free list.
* Note that if the object is shared, to reclaim it now it is not
* possible. This rarely happens, however sometimes the implementation
* of parts of the Redis core may call incrRefCount() to protect
* objects, and then call dbDelete(). In this case we'll fall
* through and reach the dictFreeUnlinkedEntry() call, that will be
* equivalent to just calling decrRefCount(). */
// Asynchronous deletion will be performed only when the recovery income exceeds a certain value, otherwise it will degenerate to synchronous deletion
if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) {
atomicIncr(lazyfree_objects,1);
bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL);
dictSetVal(db->dict,de,NULL);
}
}
/* Release the key-val pair, or just the key if we set the val
* field to NULL in order to lazy free it later. */
if (de) {
dictFreeUnlinkedEntry(db->dict,de);
if (server.cluster_enabled) slotToKeyDel(key->ptr);
return 1;
} else {
return 0;
}
}
By introducing a threaded lazy free, redis realizes Lazy operation for Slow Operation, avoiding server blocking caused by large key deletion, FLUSHALL and FLUSHDB. Of course, when implementing this function, not only the lazy free thread is introduced, but also the redis aggregation type is improved in the storage structure. Redis uses many shared objects internally, such as client output cache. Of course, redis does not use locking to avoid thread conflict. Lock competition will lead to performance degradation. Instead, redis removes the shared object and directly adopts data copy, as shown in 3.3 X and 6 Different implementations of ZSet node value in X.
// 3.2. Version 5 ZSet node implementation, value defines robj *obj
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
// 6.0. The ZSet node of version 10 is implemented, and value is defined as sds ele
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
Removing the shared object not only realizes the lazy free function, but also makes it possible for Redis to stride into multithreading. As the author said:
Now that values of aggregated data types are fully unshared, and client output buffers don't contain shared objects as well, there is a lot to exploit. For example it is finally possible to implement threaded I/O in Redis, so that different clients are served by different threads. This means that we'll have a global lock only when accessing the database, but the clients read/write syscalls and even the parsing of the command the client is sending, can happen in different threads.
Multithreaded I/O and its limitations
Redis introduced Lazy Free in version 4.0. Since then, redis has a Lazy Free thread dedicated to the recovery of large keys. At the same time, it also removes the shared objects of aggregation type, which makes multithreading possible. Redis also lives up to expectations and implements multithreaded I/O in version 6.0.
Implementation principle
As the official reply before, Redis's performance bottleneck is not on the CPU, but on the memory and network. Therefore, the multithreading released in 6.0 does not change the event processing to multithreading, but on I/O. in addition, if the event processing is changed to multithreading, it will not only lead to lock competition, but also frequent context switching, that is, using segmented locks to reduce competition will also make great changes to the Redis kernel, and the performance may not be significantly improved.
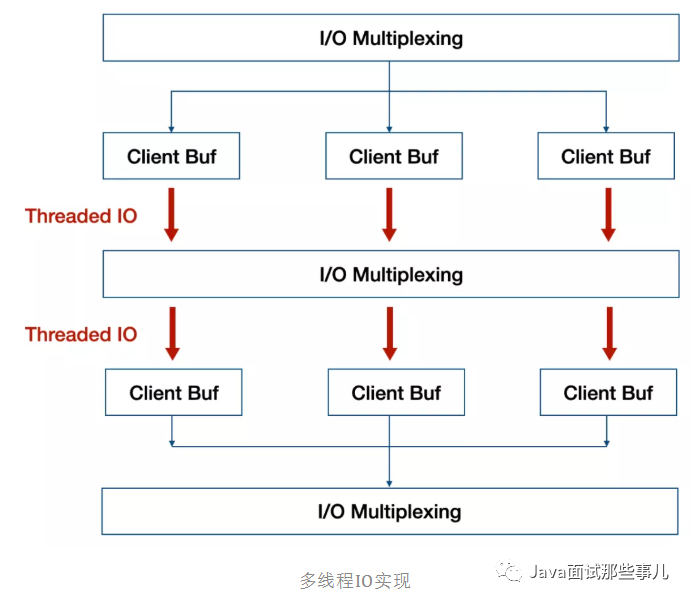
As shown in the figure above, the red part is the multi-threaded part implemented by Redis. Multi cores are used to share the I/O read and write load. Each time the event processing thread obtains a readable event, it will allocate all ready read events to the I/O thread and wait. After all I/O threads complete the read operation, the event processing thread starts to execute task processing. After processing, it will also allocate write events to the I/O thread and wait for all I/O threads to complete the write operation.
Take read event processing as an example to see the task allocation process of event processing thread:
int handleClientsWithPendingReadsUsingThreads(void) {
...
/* Distribute the clients across N different lists. */
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
// Assign clients waiting to be processed to I/O threads
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
...
/* Wait for all the other threads to end their work. */
// Rotate training and wait for all I/O threads to finish processing
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
...
return processed;
}
I/O thread processing flow:
void *IOThreadMain(void *myid) {
...
while(1) {
...
// I/O threads perform read and write operations
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// io_threads_op determines whether to read or write events
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}
limitations
From the above implementation, multithreading in version 6.0 is not complete multithreading. I/O threads can only perform read or write operations at the same time. During this period, the event processing thread has been in a waiting state, not a pipeline model, and there are a lot of rotation waiting overhead.
Implementation principle of Tair multithreading
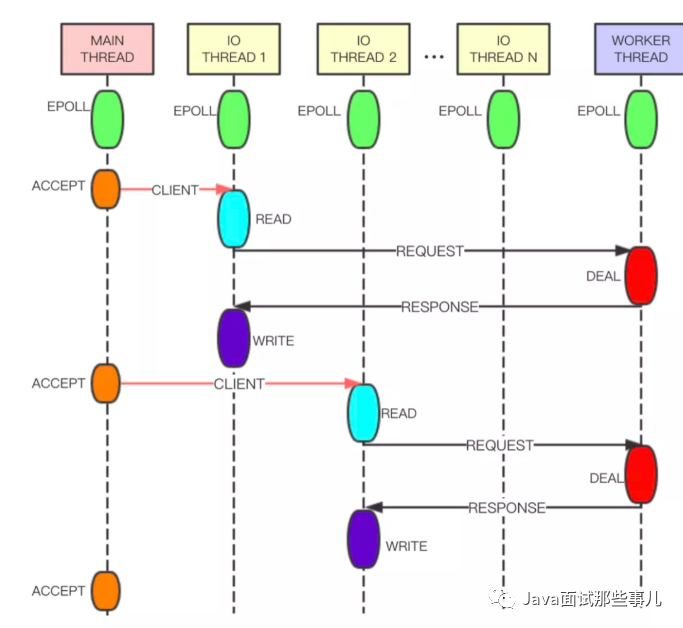
Compared with the 6.0 version of multithreading, Tair's multithreading implementation is more elegant. As shown in the figure below, Tair's Main Thread is responsible for client connection establishment, IO Thread is responsible for request reading, response sending, command parsing, etc., and Worker Thread is specially used for event processing. The IO Thread reads and parses the user's request, and then puts the parsing result in the queue in the form of command and sends it to the Worker Thread for processing. Worker Thread generates a response after processing the command and sends it to IO Thread through another queue. In order to improve the parallelism of threads, lockless queues and pipes are used for data exchange between IO threads and worker threads, and the overall performance will be better.
Summary
Redis 4.0 introduces Lazy Free threads to solve the problem of server blocking caused by large key deletion. In version 6.0, I/O Thread threads are introduced to formally implement multithreading. However, compared with Tair, it is not elegant and the performance improvement is not much. According to the pressure test, the performance of the multithreaded version is twice that of the single threaded version, and that of Tair multithreaded version is three times that of the single threaded version. In the author's opinion, redis multithreading is nothing more than two ideas, I/O threading and Slow commands threading, as the author said in his blog:
I/O threading is not going to happen in Redis AFAIK, because after much consideration I think it's a lot of complexity without a good reason. Many Redis setups are network or memory bound actually. Additionally I really believe in a share-nothing setup, so the way I want to scale Redis is by improving the support for multiple Redis instances to be executed in the same host, especially via Redis Cluster.
What instead I really want a lot is slow operations threading, and with the Redis modules system we already are in the right direction. However in the future (not sure if in Redis 6 or 7) we'll get key-level locking in the module system so that threads can completely acquire control of a key to process slow operations. Now modules can implement commands and can create a reply for the client in a completely separated way, but still to access the shared data set a global lock is needed: this will go away.
Redis authors prefer to use clustering to solve I/O threading, especially in the context of the native Redis Cluster Proxy released in version 6.0, which makes the cluster easier to use. In addition, the author prefers slow operations threading (such as Lazy Free released in version 4.0) to solve the multithreading problem. It is really worth looking forward to whether the subsequent versions will improve the implementation of IO Thread and adopt Module to optimize slow operation.