background
SMP(Symmetric Multi-Processor)
Symmetric multiprocessor architecture is a widely used parallel technology compared with asymmetric multiprocessing technology.
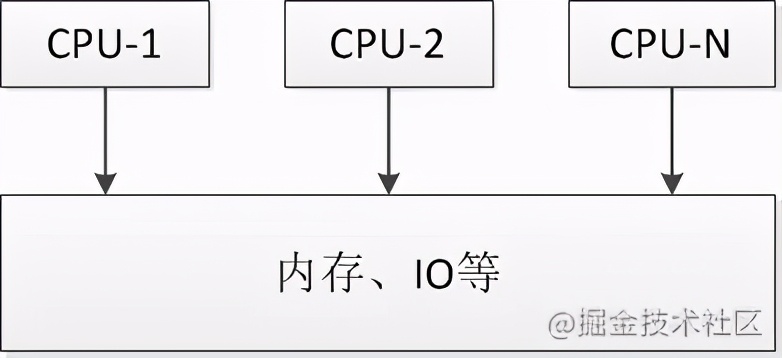
- In this architecture, a computer is composed of multiple CPUs and shares memory and other resources. All CPUs can access memory, I/O and external interrupts equally.
- Although multiple CPU s are used at the same time, they behave like a single machine from a management point of view.
- The operating system symmetrically distributes the task queue on multiple CPU s, which greatly improves the data processing capacity of the whole system.
- However, with the increase of the number of CPUs, each CPU has to access the same memory resources. Shared resources may become a system bottleneck, resulting in a waste of CPU resources.
NUMA(Non-Uniform Memory Access)
Non consistent storage access divides the CPU into CPU modules. Each CPU module is composed of multiple CPUs, and has independent local memory, I/O slot, etc. the modules can access each other through interconnected modules.
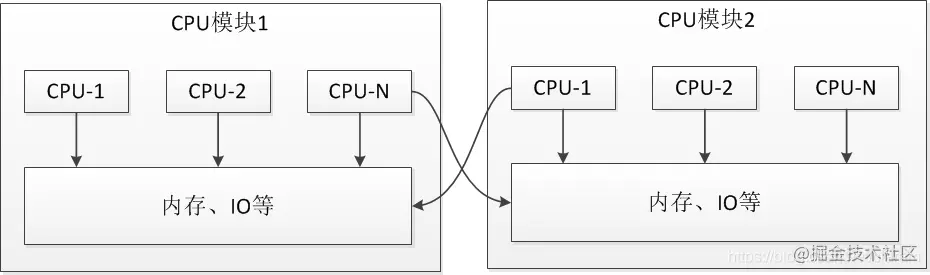
- The speed of accessing local memory (the memory of this CPU module) will be much higher than that of accessing remote memory (the memory of other CPU modules), which is also the origin of inconsistent storage access.
- NUMA can better solve the problem of SMP expansion. When the number of CPU s increases, the system performance cannot increase linearly because the delay of accessing remote memory far exceeds that of local memory.
CLH lock
CLH is a high-performance and fair spin lock based on one-way linked list. The thread applying for locking spins through the variables of the precursor node. After the front node is unlocked, the current node will end the spin and lock.
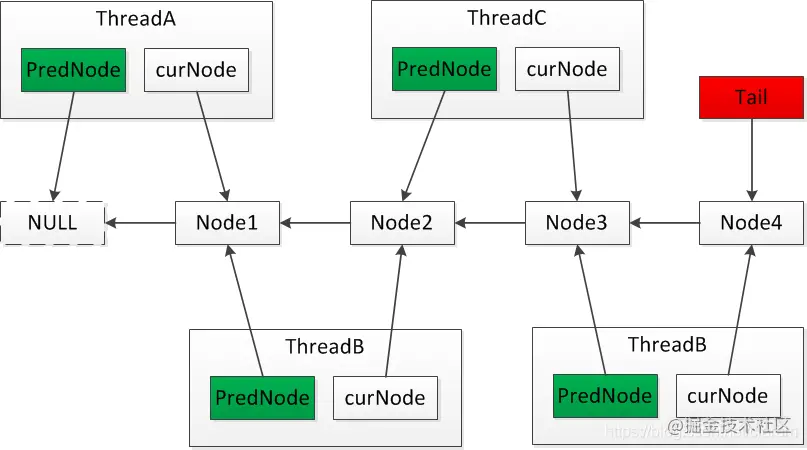
- Under SMP architecture, CLH has more advantages.
- In NUMA architecture, if the current node and the predecessor node are not in the same CPU module, the cross CPU module will bring additional system overhead, and MCS lock is more suitable for NUMA architecture.
Lock logic
- Get the lock node of the current thread. If it is empty, initialize it;
- The synchronization method obtains the tail node of the linked list and sets the current node as the tail node. At this time, the original tail node is the front node of the current node.
- If the tail node is empty, it means that the current node is the first node, and the direct locking is successful.
- If the tail node is not empty, spin based on the lock value of the front node (locked==true) until the lock value of the front node becomes false.
Unlock logic
- Obtain the lock node corresponding to the current thread. If the node is empty or the lock value is false, it does not need to be unlocked and returns directly;
- The synchronization method assigns a null value to the tail node. Unsuccessful assignment means that the current node is not the tail node, so you need to unlock the node with locked=false of the current node. If the current node is a tail node, you do not need to set a for that node.
public class CLHLock {
private final AtomicReference<Node> tail;
private final ThreadLocal<Node> myNode;
private final ThreadLocal<Node> myPred;
public CLHLock() {
tail = new AtomicReference<>(new Node());
myNode = ThreadLocal.withInitial(() -> new Node());
myPred = ThreadLocal.withInitial(() -> null);
}
public void lock(){
Node node = myNode.get();
node.locked = true;
Node pred = tail.getAndSet(node);
myPred.set(pred);
while (pred.locked){}
}
public void unLock(){
Node node = myNode.get();
node.locked=false;
myNode.set(myPred.get());
}
static class Node {
volatile boolean locked = false;
}
}
Copy codeMCS lock
The biggest difference between MSC and CLH is not whether the linked list is displayed or implicit, but the rules of thread spin: CLH spins and waits on the locked domain of the leading node, while MCS spins and waits on the locked domain of its own node. Because of this, it solves the problem that CLH has too much memory to obtain the locked domain state in NUMA system architecture.
Specific implementation rules of MCS lock:
- a. There is no node during queue initialization, tail=null
- b. Thread A wants to obtain the lock and put itself at the end of the queue. Because it is the first node, its locked field is false
- c. Threads B and C join the queue successively. A - > next = B, B - > next = C. B and C do not acquire the lock and are in the waiting state. Therefore, the locked field is true, and the tail pointer points to the node corresponding to thread C
- d. After thread A releases the lock, it finds thread B along its next pointer and sets the locked field of B to false. This action will trigger thread B to obtain the lock.
public class MCSLock {
private final AtomicReference<Node> tail;
private final ThreadLocal<Node> myNode;
public MCSLock() {
tail = new AtomicReference<>();
myNode = ThreadLocal.withInitial(() -> new Node());
}
public void lock() {
Node node = myNode.get();
Node pred = tail.getAndSet(node);
if (pred != null) {
node.locked = true;
pred.next = node;
while (node.locked) {
}
}
}
public void unLock() {
Node node = myNode.get();
if (node.next == null) {
if (tail.compareAndSet(node, null)) {
return;
}
while (node.next == null) {
}
}
node.next.locked = false;
node.next = null;
}
class Node {
volatile boolean locked = false;
Node next = null;
}
public static void main(String[] args) {
MCSLock lock = new MCSLock();
Runnable task = new Runnable() {
private int a;
@Override
public void run() {
lock.lock();
for (int i = 0; i < 10; i++) {
a++;
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(a);
lock.unLock();
}
};
new Thread(task).start();
new Thread(task).start();
new Thread(task).start();
new Thread(task).start();
}
}