Typora + various blogs (Wordpress/Hexo/Typecho) have been used to take notes and write before. Later, I contacted and fell in love with YuQue, mainly because the mapping is too convenient. (when using typora, it will be combined with PicGo + cloud storage, but sometimes redundant pictures are pasted or when you want to replace existing pictures, you don't bother to open the cloud storage for deletion, which will be forgotten over time, resulting in a certain waste of space.) At the beginning, I read it specially. You can export articles in md format. But recently, when I want to export the knowledge base in batches, I found that I can only choose PDF or YuQue specific format, and I don't feel relieved that the data is not in my own hands. So I got a script, exported all the articles through the official API of YuQue, and began to look for locally stored note taking software. After screening according to personal situation, it is found that Obisidian It's more suitable, but it won't be used at the beginning. It won't deal with the problem of image path. The language bird does not have the concept of directory, so the exported articles are put together, and then the pictures and other resources are also put in a directory in the article directory. If I classified articles by creating multi-level folders in Obsidian, the links of all image resources would have to be changed and almost abandoned. Fortunately, I watched the video about ob in station B and learned to manage it by indexing.
Let's start with a picture of Obisidian
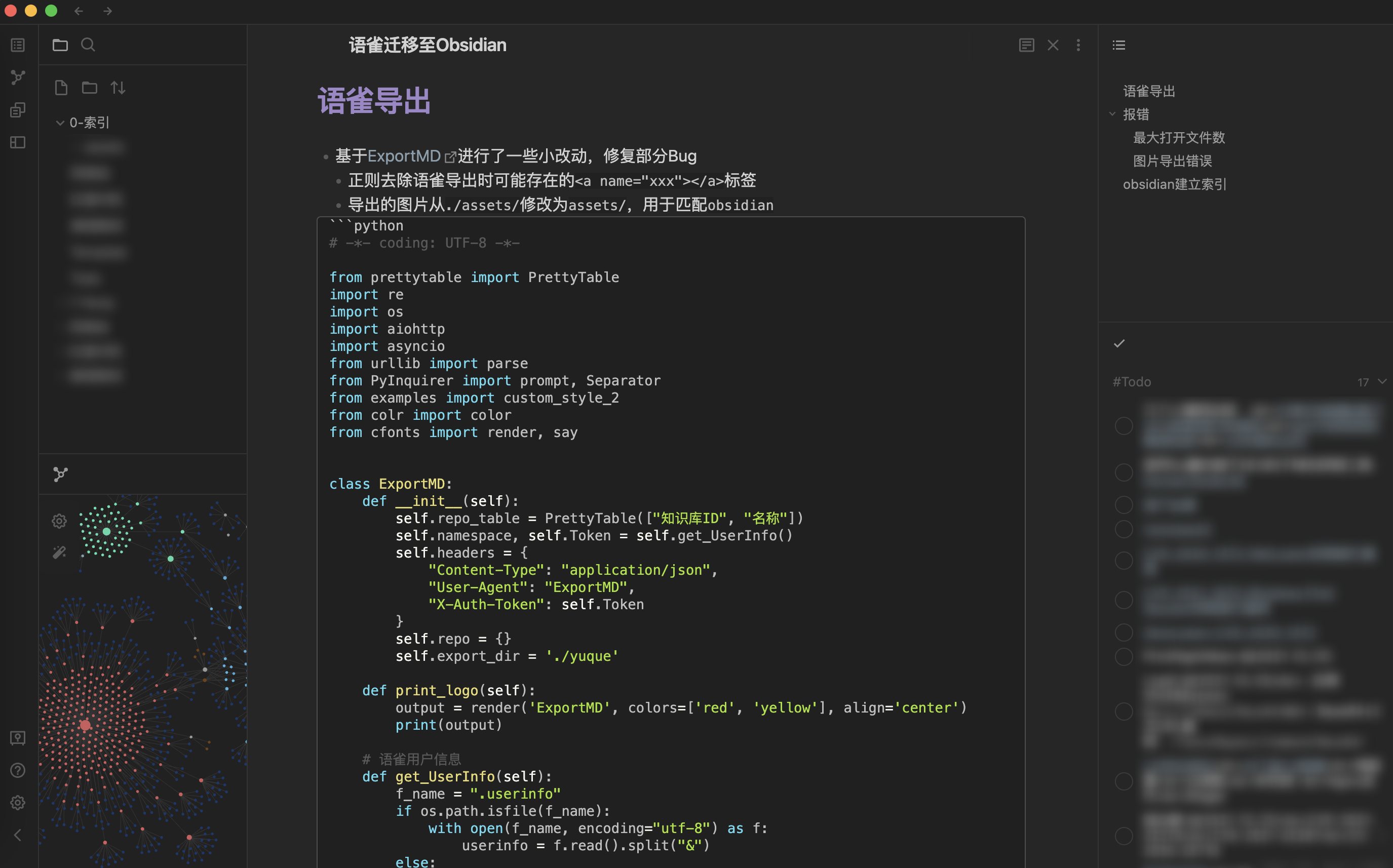
Language bird export
- be based on ExportMD Some optimizations have been made to fix some bugs and adapt Obsidian
- Regular remove tags that may exist when exporting
- Export pictures from/ Assets / is changed to assets /, which is used to match Obsidian
- usage method:
- NameSpace: visit the YuQue personal home page https://www.yuque.com/ Part xxx in < xxx >
- Token: access YuQue Token To create a new, you only need to give read permission.
$ python3 ExportMD.py > Please enter a word namespace: xxx > Please enter a word Token: xxx
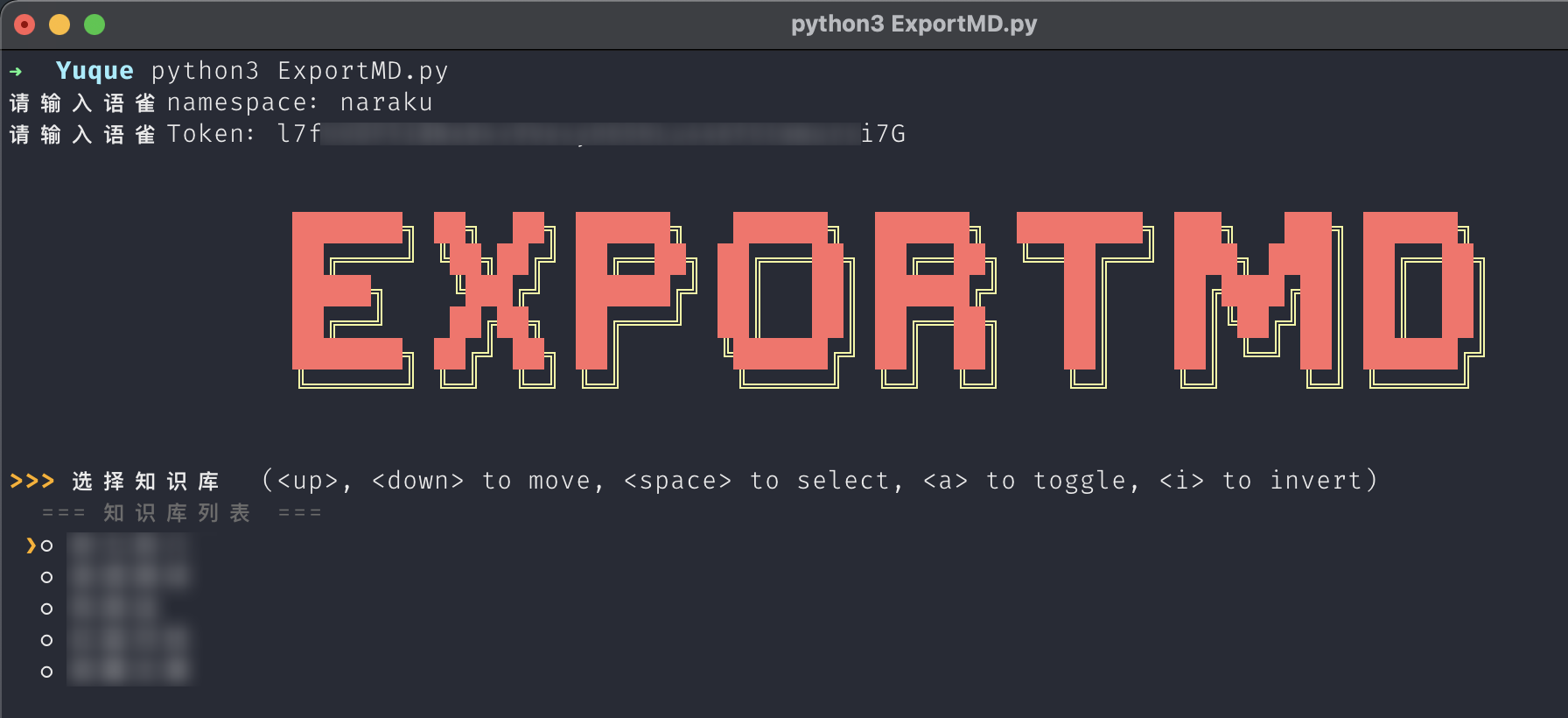
- ExportMD.py complete code:
# -*- coding: UTF-8 -*-
from prettytable import PrettyTable
import re
import os
import aiohttp
import asyncio
from urllib import parse
from PyInquirer import prompt, Separator
from examples import custom_style_2
from colr import color
from cfonts import render, say
class ExportMD:
def __init__(self):
self.repo_table = PrettyTable(["knowledge base ID", "name"])
self.namespace, self.Token = self.get_UserInfo()
self.headers = {
"Content-Type": "application/json",
"User-Agent": "ExportMD",
"X-Auth-Token": self.Token
}
self.repo = {}
self.export_dir = './yuque'
def print_logo(self):
output = render('ExportMD', colors=['red', 'yellow'], align='center')
print(output)
# YuQue user information
def get_UserInfo(self):
f_name = ".userinfo"
if os.path.isfile(f_name):
with open(f_name, encoding="utf-8") as f:
userinfo = f.read().split("&")
else:
namespace = input("Please enter a word namespace: ")
Token = input("Please enter a word Token: ")
userinfo = [namespace, Token]
with open(f_name, "w") as f:
f.write(namespace + "&" + Token)
return userinfo
# Send request
async def req(self, session, api):
url = "https://www.yuque.com/api/v2" + api
# print(url)
async with session.get(url, headers=self.headers) as resp:
result = await resp.json()
return result
# Get all knowledge bases
async def getRepo(self):
api = "/users/%s/repos" % self.namespace
async with aiohttp.ClientSession() as session:
result = await self.req(session, api)
for repo in result.get('data'):
repo_id = str(repo['id'])
repo_name = repo['name']
self.repo[repo_name] = repo_id
self.repo_table.add_row([repo_id, repo_name])
# Get the document list of a knowledge base
async def get_docs(self, repo_id):
api = "/repos/%s/docs" % repo_id
async with aiohttp.ClientSession() as session:
result = await self.req(session, api)
docs = {}
for doc in result.get('data'):
title = doc['title']
slug = doc['slug']
docs[slug] = title
return docs
# Get body Markdown source code
async def get_body(self, repo_id, slug):
api = "/repos/%s/docs/%s" % (repo_id, slug)
async with aiohttp.ClientSession() as session:
result = await self.req(session, api)
body = result['data']['body']
body = re.sub("<a name=\".*\"></a>","", body) # Regular removal of < a > tags derived from finches
return body
# Select knowledge base
def selectRepo(self):
choices = [{"name": repo_name} for repo_name, _ in self.repo.items()]
choices.insert(0, Separator('=== Knowledge base list ==='))
questions = [
{
'type': 'checkbox',
'qmark': '>>>',
'message': 'Select knowledge base',
'name': 'repo',
'choices': choices
}
]
repo_name_list = prompt(questions, style=custom_style_2)
return repo_name_list["repo"]
# create folder
def mkDir(self, dir):
isExists = os.path.exists(dir)
if not isExists:
os.makedirs(dir)
# Get the article and save it
async def download_md(self, repo_id, slug, repo_name, title):
"""
:param repo_id: knowledge base id
:param slug: article id
:param repo_name: Knowledge base name
:param title: Article name
:return: none
"""
body = await self.get_body(repo_id, slug)
new_body, image_list = await self.to_local_image_src(body)
if image_list:
# Picture save location: yuque/<repo_ name>/assets/<filename>
save_dir = os.path.join(self.export_dir, repo_name, "assets")
self.mkDir(save_dir)
async with aiohttp.ClientSession() as session:
await asyncio.gather(
*(self.download_image(session, image_info, save_dir) for image_info in image_list)
)
self.save(repo_name, title, new_body)
print("%s Export succeeded!" % color(title, fore='green', style='bright'))
# Replace the picture address in md with the local picture address
async def to_local_image_src(self, body):
pattern = r"!\[(?P<img_name>.*?)\]" \
r"\((?P<img_src>https:\/\/cdn\.nlark\.com\/yuque.*\/(?P<slug>\d+)\/(?P<filename>.*?\.[a-zA-z]+)).*\)"
# repl = r""
repl = r"" # modify
images = [_.groupdict() for _ in re.finditer(pattern, body)]
new_body = re.sub(pattern, repl, body)
# new_body = body
return new_body, images
# Download pictures
async def download_image(self, session, image_info: dict, save_dir: str):
img_src = image_info['img_src']
filename = image_info["filename"]
async with session.get(img_src) as resp:
with open(os.path.join(save_dir, filename), 'wb') as f:
f.write(await resp.read())
# Save article
def save(self, repo_name, title, body):
# Encodes characters that cannot be used as file names
def check_safe_path(path: str):
for char in r'/\<>?:"|*':
path = path.replace(char, parse.quote_plus(char))
return path
repo_name = check_safe_path(repo_name)
title = check_safe_path(title)
save_path = "./yuque/%s/%s.md" % (repo_name, title)
with open(save_path, "w", encoding="utf-8") as f:
f.write(body)
async def run(self):
self.print_logo()
await self.getRepo()
repo_name_list = self.selectRepo()
self.mkDir(self.export_dir) # Create a folder for storing knowledge base articles
# Traverse the selected knowledge base
for repo_name in repo_name_list:
dir_path = self.export_dir + "/" + repo_name.replace("/", "%2F")
dir_path.replace("//", "/")
self.mkDir(dir_path)
repo_id = self.repo[repo_name]
docs = await self.get_docs(repo_id)
await asyncio.gather(
*(self.download_md(repo_id, slug, repo_name, title) for slug, title in docs.items())
)
print("\n" + color('Export complete!', fore='green', style='bright'))
print("Exported to:" + color(os.path.realpath(self.export_dir), fore='green', style='bright'))
if __name__ == '__main__':
export = ExportMD()
loop = asyncio.get_event_loop()
loop.run_until_complete(export.run())Possible error reports
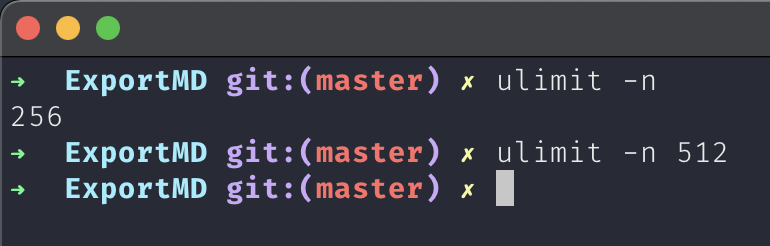
- The following error occurred while running the script:

- The reason is that the default maximum number of open files is not enough. Repair method:
$ ulimit -n # View the current maximum number of open files $ ulimit -n 512 # More settings
Picture export
A small Bug is found during export: when exporting a document through the above script, if there are two connected pictures in the document, such as pic_a and pic_b. The pic will be exported twice_ a. And rename the second picture pic_b. It should be the problem of bad regular matching.
When the above bugs exist in a large number of documents, the solution is as follows:
- First, in the AAA / directory, use the previous exportmd Py script to download all documents
- Then go to BBB / directory and note exportmd Py and open 140 lines
# new_body = re.sub(pattern, repl, body) # Comment this line new_body = body # Open this row
- And use the script to download the document again. After downloading, the document directory structure is as follows:
└── AAA/
└── yuque/
└── assets/ # Picture folder
└── ... # MarkDown document
└── BBB/
└── yuque/
└── assets/ # Picture folder
└── ... # MarkDown document- Finally, manually delete the AAA/assets / picture folder and move the BBB/assets / picture folder to AAA /
Explain: The link format in the document downloaded in AAA / directory for the first time is: assets / xxx Png, some pictures here have the above-mentioned Bug; The link format in the document downloaded in BBB / directory for the second time is: https://cdn.nlark.com/yuque/xxx.png , the picture link here has not been modified by regular matching. It is the original link of the picture in the language bird document; So here, first download the documents in the two link formats, then download the images from the native links through the script, and replace the images in the Bug part.
- Download_Yuque_imgs.py complete code:
# python3 Download_ Yuque_ imgs. Py < markdown file path >
# -*- coding: utf-8 -*-
import os
import re
import sys
from urllib.request import urlretrieve
# Read all picture URL s in markdown file
def get_urls(file_path):
print(f"[+] obtain {file_path} All picture links ... ")
imgs = []
with open(file_path, encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
img = re.findall(r"!\[image.png\]\((.*?\.png)", line, re.S)
if img:
imgs.append(img[0])
return imgs
# Traverse the URL, download and store it in the picture directory
def save_imgs(imgs):
index = 1
for img_url in imgs:
try:
img_name = re.findall(r"520228\/(.*?\.png)", img_url)[0]
urlretrieve(img_url, f'./{img_name}')
print(f"[+] <{index}/{len(imgs)}> {img_name}")
index += 1
except Exception as e:
print(f"!!! [-] <{index}/{len(imgs)}> {img_name} !!!")
continue
if __name__ == '__main__':
path = sys.argv[1]
files = list(filter(lambda x: x[-3:]==".md", os.listdir(path)))
for file in files:
file_path = os.path.join(path, file)
imgs = get_urls(file_path)
if(imgs):
save_imgs(imgs)
print(f"====== Execution complete: {file} ======")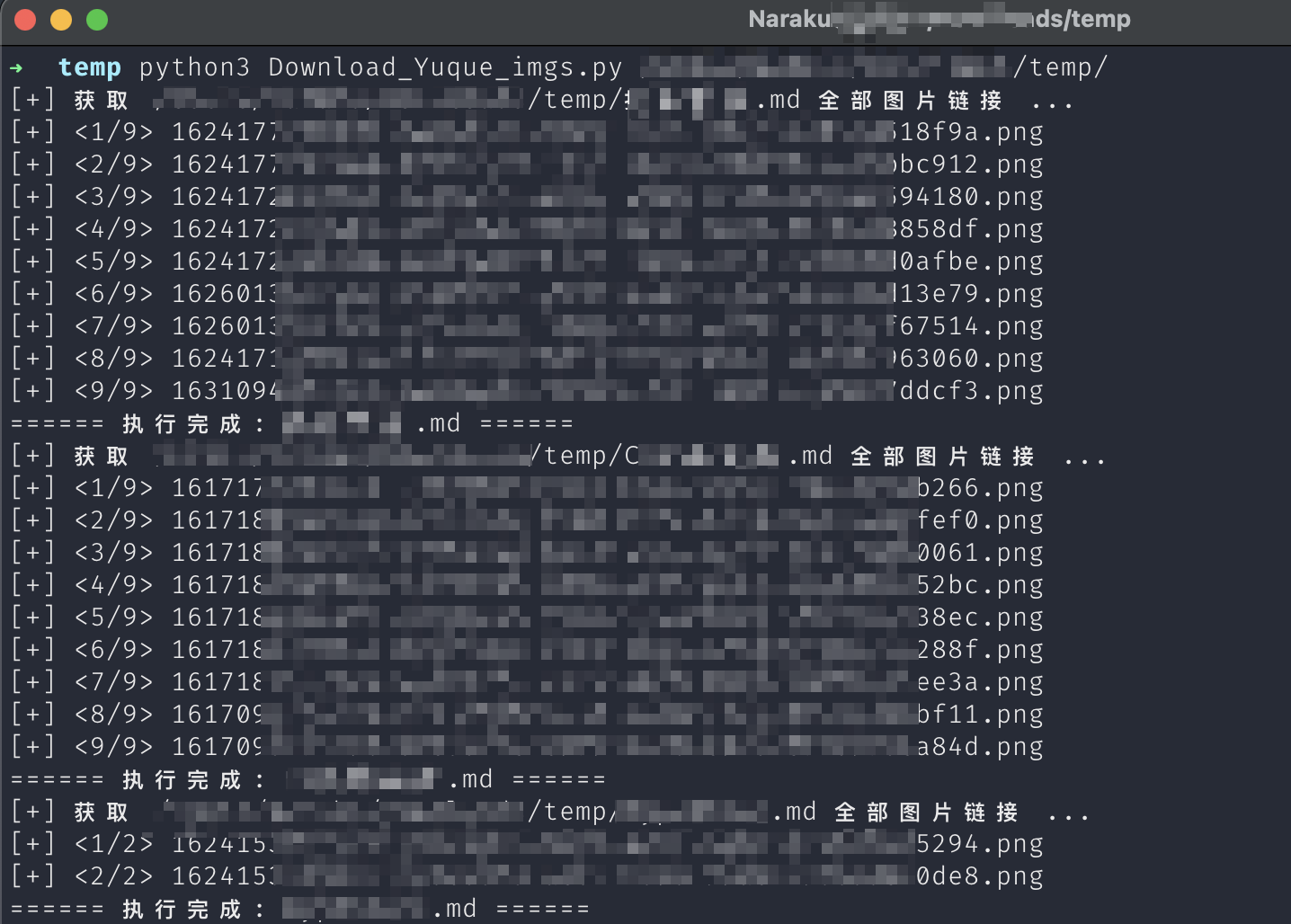
Indexing
Here, take the language bird directory as the content, and batch add the internal chain format [[xxx]] of obsidian to establish the index
- First copy the titles of all documents, then use the following script to batch add the inner chain format, and finally manually adjust it according to the situation.
file = "list.txt"
new_file = "list2.txt"
datas = []
with open(file, "r") as f:
lines = f.readlines()
for line in lines:
data = "[[" + line.strip() + "]]"
datas.append(data)
with open(new_file, "w") as f2:
for line in datas:
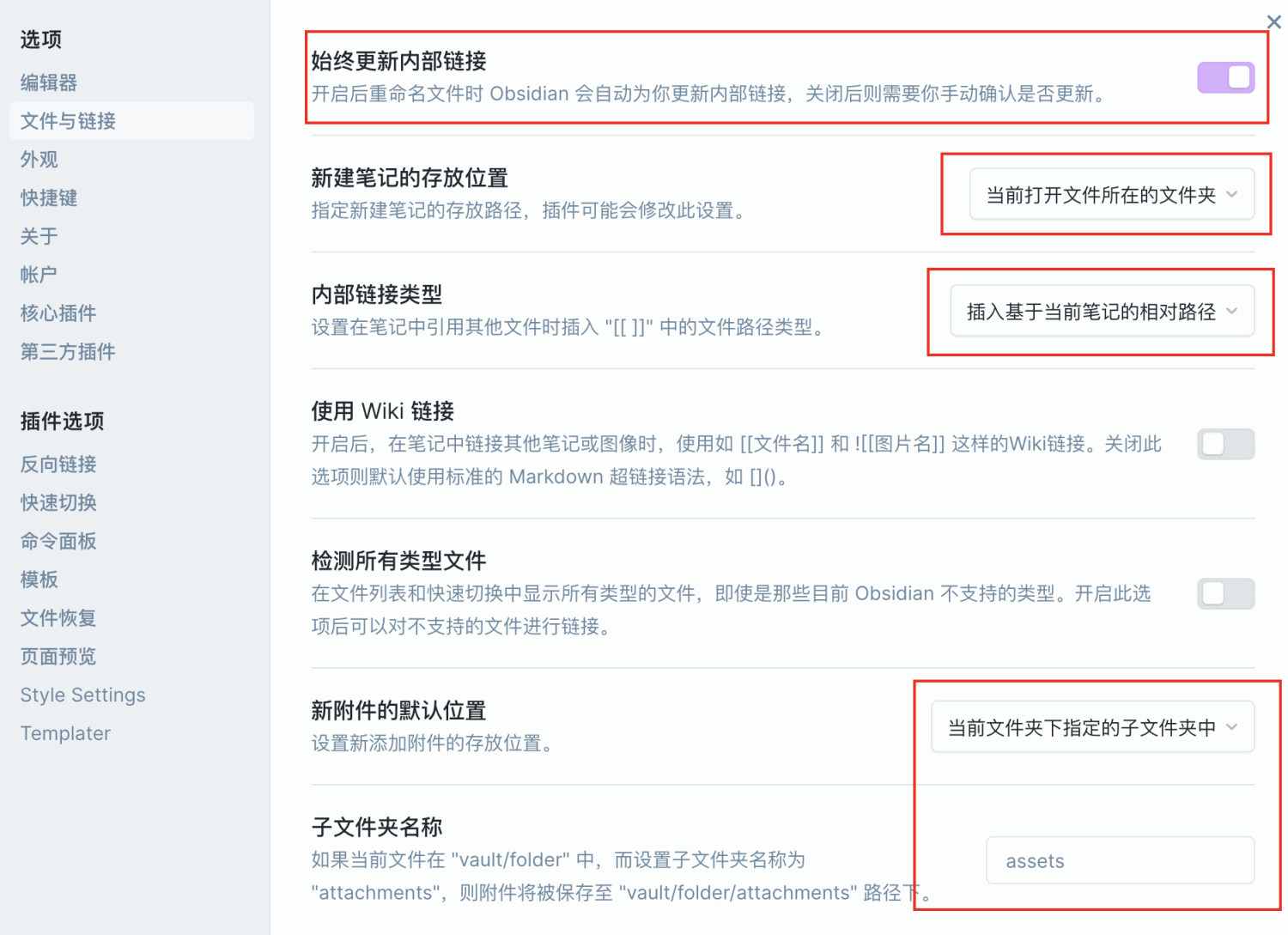
f2.writelines(line + "\n")- Some configurations of obsidian
Copyright: Naraku Link to this article: https://www.naraku.cn/posts/109.html All original articles on this site adopt Creative Commons Attribution - non commercial - no deduction 4.0 international license . If you need to reprint, please be sure to indicate the source and keep the original link, thank you~