AskTUG.com # technology Q & a website is believed to be familiar to everyone, but in addition to the familiar front-end pages, there is an unknown story behind the database supporting its operation. This paper is written by asktug Wang Xingzong, one of the authors of www.Discourse.com, shared the secret with asktug, which was born in Discourse COM, the wonderful story of migrating from PostgreSQL to MySQL and finally running stably in TiDB.
One ad:
AskTUG.com is the gathering place of TiDB users, contributors and partners, where you can find the answers to all TiDB related questions. Welcome to register and experience ~
Link: https://asktug.com/
background
"Through one platform, we will be able to find satisfactory answers to all the questions of TiDB."
Because of this desire, users, contributors and partners in TiDB ecology have established asktug Com technical Q & a website, which was officially launched in August 2019. As a "gathering place" for TUG members to learn and share, TiDB users can ask and answer questions, exchange and discuss with each other here, and gather the collective wisdom of TiDB users. Since its launch, asktug Com has gradually attracted the attention of more and more users. By the end of June 2021, asktug Com has 7000 + registered users and precipitated 1.6w + problems and 300 + technical articles.
Many friends have found that asktug The back-end program of COM is a discover program. About discover is a new open source forum project launched by Jeff Atwood, co-founder of Stack Overflow. Its purpose is to change the forum software that has not changed for ten years. At asktug At the beginning of the establishment of COM, discover was determined to be used from the following perspectives:
- Powerful: Discover has rich features and strong customizability. It is the WordPress in the forum industry. Compared with other traditional forums, discover simplifies the classification of traditional forums and replaces them with hot posts, which is a bit like Q & A. It can avoid the confusion that users can't find directions after entering the traditional forum. This feature starts from asktug Com page:
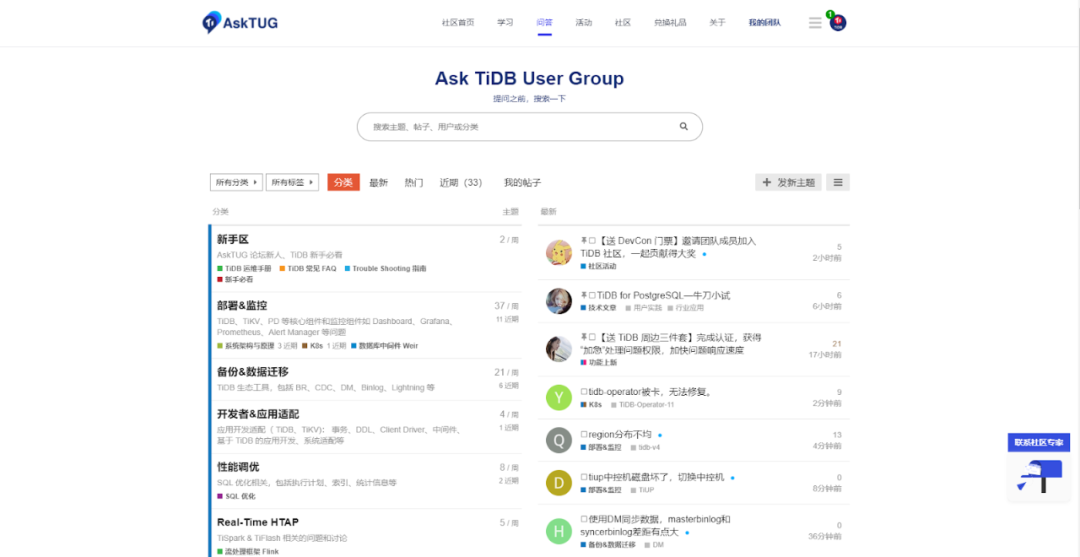
-
Audience breadth: most popular open source projects choose to use discover to build their own communities, including:
-
Docker:https://forums.docker.com/
-
Github Atom:https://discuss.atom.io/
-
Mozilla:https://discourse.mozilla.org/
-
TiDB:https://asktug.com/
-
Discourse:https://meta.discourse.org/
-
Rust:https://users.rust-lang.org/
-

-
- more: https://discourse.org/customers
-
Easy to use: Discover posts are displayed in the form of bubbles. All Ajax loads are available in computer and mobile versions. The forum adopts the design of waterfall flow to automatically load the next page without turning the page manually. In short, this is a great system.
Why migrate
So far, Everything is Good, except for one thing: discovery officially only supports PostgreSQL.
As an open source database manufacturer, we have great enthusiasm and good reasons for asktug Com runs on its own database TiDB. When it first came to this idea, of course, it was to find out whether there was a scheme to port discovery to MySQL. As a result, many people asked, but no action.
So we decided to do the transformation of discover database by ourselves. There are two reasons:
-
Eat your own dog food to verify the compatibility of TiDB.
-
**Discover is a typical HTAP application. Its management background has very complex report queries. With the increase of forum data, stand-alone PostgreSQL and MySQL are prone to performance bottlenecks** The TiFlash MPP computing model introduced by TiDB 5.0 just meets the needs of this application scenario. By introducing TiFlash node, some complex statistical analysis queries are processed in parallel to achieve the effect of acceleration. And there is no need to change SQL and complex ETL processes.
Migration practice
Earlier, we talked about the reasons for the asktug & discover database transformation project. Next, we will talk in detail about the "pit" of migrating from PostgreSQL to MySQL / TiDB. If you have friends migrating from PG to MySQL, you can refer to it.
TiDB is compatible with MySQL protocol and ecology, with convenient migration and extremely low operation and maintenance cost. Therefore, the migration of discover from PG to TiDB is roughly divided into two steps:
Step 1: migrate discover to MySQL;
Step 2: adapt TiDB.
Migrate to MySQL 5.7
🌟mini_sql
minisql is a lightweight SQL wrapper, which is convenient for making queries that ORM is not good at, and can prevent SQL injection. Previously, only PG and sqlite were supported. The code of discover relies on minisql in many places, and the workload of rewriting is huge, such as patch mini_sql to support MySQL is an important step to complete migration: https://github.com/discourse/mini_sql/pull/5
🌟 schema migration
The schema migration of Rails is used to maintain DDL and reflects the change process of database schema. In fact, it increases the workload for migration. The solution is to create a final schema RB file, modify the final result and generate a new migration file. Delete the migration file generated in the intermediate process.
🌟 character set utf8mb4
database.yml
development: prepared_statements: false encoding: utf8mb4 socket: /tmp/mysql.sock adapter: mysql2
/etc/mysql/my.cnf
[client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci
🌟 MySQL can index only the first N chars of a BLOB or TEXT column
All types of PG can be indexed. MySQL cannot index text. The solution is to specify the length when indexing:
t.index ["error"], name: "index_incoming_emails_on_error", length: 100
However, the case of combined index is more complex. You can only ignore the text type. Fortunately, the index does not affect the function.
🌟 data migration
Pg2mysql can convert the insert statement from pgdump into a form compatible with MySQL syntax, but it is only limited to simple forms. Some formats with array and json will be messy, but this part is handled correctly in Ruby and is divided into two parts. First, pg2mysql handles and eliminates some tables with conversion errors, such as user_options,site_settings, etc.:
PGPASSWORD=yourpass pg_dump discourse_development -h localhost --quote-all-identifiers --quote-all-identifiers --inserts --disable-dollar-quoting --column-inserts --exclude-table-data user_options --exclude-table-data user_api_keys --exclude-table-data reviewable_histories --exclude-table-data reviewables --exclude-table-data notifications --exclude-table-data site_settings --exclude-table-data reviewables --no-acl --no-owner --format p --data-only -f pgfile.sql
The rest of the data uses seed_dump to migrate:
bundle exec rake db:seed:dump
MODELS=UserApiKey,UserOption,ReviewableHistory,
Reviewable,Notification,SiteSetting
EXCLUDE=[] IMPORT=true
🌟 distinct on
PG has a distinct on usage, which is equivalent to mysqlonly_ FULL_ GROUP_ The effect when the by parameter is turned off, but since MySQL 5.7, this parameter has been turned on by default. So one solution is to turn off ONLY_FULL_GROUP_BY parameter, the other is simulated by group and aggregate function:
# postgresql
SELECT DISTINCT ON (pr.user_id) pr.user_id, pr.post_id, pr.created_at granted_at
FROM post_revisions pr
JOIN badge_posts p on p.id = pr.post_id
WHERE p.wiki
AND NOT pr.hidden
AND (:backfill OR p.id IN (:post_ids))
# mysql
SELECT pr.user_id, MIN(pr.post_id) AS post_id, MIN(pr.created_at) AS granted_at
FROM post_revisions pr
JOIN badge_posts p on p.id = pr.post_id
WHERE p.wiki
AND NOT pr.hidden
AND (:backfill OR p.id IN (:post_ids))
GROUP BY pr.user_id
🌟 returning
PG's UPDATE, DELETE and INSERT statements can all carry a returning keyword to return the results after modification / insertion. For UPDATE and DELETE statements, MySQL is easy to change. It only needs to be split into two steps. First find out the primary key, and then UPDATE or DELETE it:
update users set updated_at = now() where id = 801 returning id,updated_at ; id | updated_at -----+--------------------------- 801 | 2019-12-30 15:43:35.81969
MySQL version:
update users set updated_at = now() where id = 801; select id, updated_at from users where id = 801; +-----+---------------------+ | id | updated_at | +-----+---------------------+ | 801 | 2019-12-30 15:45:46 | +-----+---------------------+
For a single INSERT, you need to use last_insert_id() function:
PG version:
insert into category_users(user_id, category_id, notification_level) values(100,100,1) returning id, user_id, category_id; id | user_id | category_id ----+---------+------------- 59 | 100 | 100
Change to MySQL version:
insert into category_users(user_id, category_id, notification_level) values(100,100,1); select id, category_id, user_id from category_users where id = last_insert_id(); +----+-------------+---------+ | id | category_id | user_id | +----+-------------+---------+ | 48 | 100 | 100 | +----+-------------+---------+
For batch inserts, you need to change to a single INSERT and then use last_insert_id() function, because MySQL does not provide last_insert_id() function:
ub_ids = records.map do |ub|
DB.exec(
"INSERT IGNORE INTO user_badges(badge_id, user_id, granted_at, granted_by_id, post_id)
VALUES (:badge_id, :user_id, :granted_at, :granted_by_id, :post_id)",
badge_id: badge.id,
user_id: ub.user_id,
granted_at: ub.granted_at,
granted_by_id: -1,
post_id: ub.post_id
)
DB.raw_connection.last_id
end
DB.query("SELECT id, user_id, granted_at FROM user_badges WHERE id IN (:ub_ids)", ub_ids: ub_ids)
🌟 insert into on conflict do nothing
PG 9.5 supports upsert, and MySQL has the same function, but the writing method is inconsistent:
# postgresql DB.exec(<<~SQL, args) INSERT INTO post_timings (topic_id, user_id, post_number, msecs) SELECT :topic_id, :user_id, :post_number, :msecs ON CONFLICT DO NOTHING SQL # MySQL DB.exec(<<~SQL, args) INSERT IGNORE INTO post_timings (topic_id, user_id, post_number, msecs) SELECT :topic_id, :user_id, :post_number, :msecs SQL
🌟 select without from
PG allows such syntax: select 1 where 1=2;
However, this is illegal in MySQL because there is no FROM clause. The solution is to trick. Manually create a table with only one data to be compatible with this syntax.
execute("create table one_row_table (id int)")
execute("insert into one_row_table values (1)")
MySQL usage:
# MySQL select 1 from one_row_table where 1=2;
🌟 full outer join
MySQL does not support full outer join. You need to use LEFT JOIN + RIGHT JOIN + UNION to simulate:
# MySQL SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id UNION SELECT * FROM t1 RIGHT JOIN t2 ON t1.id = t2.id
🌟 recursive cte
Before MySQL 8.0, CTE/Recursive CTE is not supported. CTE with simple structure can be directly changed into sub query, which has no functional impact except poor readability. Recursive CTE can be simulated with user defined variables. There is a query with nested replies in discover:
WITH RECURSIVE breadcrumb(id, level) AS (
SELECT 8543, 0
UNION
SELECT reply_id, level + 1
FROM post_replies AS r
JOIN breadcrumb AS b ON (r.post_id = b.id)
WHERE r.post_id <> r.reply_id
AND b.level < 1000
), breadcrumb_with_count AS (
SELECT
id,
level,
COUNT(*) AS count
FROM post_replies AS r
JOIN breadcrumb AS b ON (r.reply_id = b.id)
WHERE r.reply_id <> r.post_id
GROUP BY id, level
)
SELECT id, level
FROM breadcrumb_with_count
ORDER BY id
Use MySQL 5.7 for compatibility:
# MySQL
SELECT id, level FROM (
SELECT id, level, count(*) as count FROM (
SELECT reply_id AS id, length(@pv) - length((replace(@pv, ',', ''))) AS level
FROM (
SELECT * FROM post_replies ORDER BY post_id, reply_id) pr,
(SELECT @pv := 8543) init
WHERE find_in_set(post_id, @pv)
AND length(@pv := concat(@pv, ',', reply_id))
) tmp GROUP BY id, level
) tmp1
WHERE (count = 1)
ORDER BY id
CTEs of PG can be nested. For example, the query in discover, note WITH period_actions are nested in flag_ In count:
WITH mods AS (
SELECT
id AS user_id,
username_lower AS username,
uploaded_avatar_id
FROM users u
WHERE u.moderator = 'true'
AND u.id > 0
),
time_read AS (
SELECT SUM(uv.time_read) AS time_read,
uv.user_id
FROM mods m
JOIN user_visits uv
ON m.user_id = uv.user_id
WHERE uv.visited_at >= '#{report.start_date}'
AND uv.visited_at <= '#{report.end_date}'
GROUP BY uv.user_id
),
flag_count AS (
WITH period_actions AS (
SELECT agreed_by_id,
disagreed_by_id
FROM post_actions
WHERE post_action_type_id IN (#{PostActionType.flag_types_without_custom.values.join(',')})
AND created_at >= '#{report.start_date}'
AND created_at <= '#{report.end_date}'
),
agreed_flags AS (
SELECT pa.agreed_by_id AS user_id,
COUNT(*) AS flag_count
FROM mods m
JOIN period_actions pa
ON pa.agreed_by_id = m.user_id
GROUP BY agreed_by_id
),
disagreed_flags AS (
SELECT pa.disagreed_by_id AS user_id,
COUNT(*) AS flag_count
FROM mods m
JOIN period_actions pa
ON pa.disagreed_by_id = m.user_id
GROUP BY disagreed_by_id
)
This sub query is very complex to simulate and can be compatible WITH temporary tables. The query part does not need any modification, but only needs to replace the WITH part WITH temporary tables according to the dependency order:
DB.exec(<<~SQL)
CREATE TEMPORARY TABLE IF NOT EXISTS mods AS (
SELECT
id AS user_id,
username_lower AS username,
uploaded_avatar_id
FROM users u
WHERE u.moderator = true
AND u.id > 0
)
SQL
DB.exec(<<~SQL)
CREATE TEMPORARY TABLE IF NOT EXISTS time_read AS (
SELECT SUM(uv.time_read) AS time_read,
uv.user_id
FROM mods m
JOIN user_visits uv
ON m.user_id = uv.user_id
WHERE uv.visited_at >= '#{report.start_date.to_s(:db)}'
AND uv.visited_at <= '#{report.end_date.to_s(:db)}'
GROUP BY uv.user_id
)
SQL
🌟 delete & update
The update/delete statements of PG and MySQL are written differently. They will be processed automatically by using ORM, but a large amount of code in discover uses mini_sql handwritten SQL needs to be replaced one by one.
PG update statement:
# postgresql UPDATE employees SET department_name = departments.name FROM departments WHERE employees.department_id = departments.id
MySQL update statement:
# MySQL UPDATE employees LEFT JOIN departments ON employees.department_id = departments.id SET department_name = departments.name
The delete statement is similar.
🌟 You can't specify target table xx for update in FROM clause
After moving from PG to MySQL, many statements will report such an error: You can't specify target table 'users' for update in from claim.
# MySQL update users set updated_at = now() where id in ( select id from users where id < 10 ); # You can't specify target table 'users' for update in FROM clause
The solution is to use derived table in the sub query:
# MySQL update users set updated_at = now() where id in ( select id from (select * from users) u where id < 10 );
🌟 MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
Take the above query as an example. If the sub query has a LIMIT:
# MySQL update users set updated_at = now() where id in ( select id from (select * from users) u where id < 10 limit 10 ); # MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
The simplest solution is derived again:
# MySQL
update users set updated_at = now() where id in (
select id from (
select id from (select * from users) u where id < 10 limit 10
) u1
);
🌟 window function
There is no window function before MySQL 8.0. You can use user defined variables instead:
# postgresql
WITH ranked_requests AS (
SELECT row_number() OVER (ORDER BY count DESC) as row_number, id
FROM web_crawler_requests
WHERE date = '#{1.day.ago.strftime("%Y-%m-%d")}'
)
DELETE FROM web_crawler_requests
WHERE id IN (
SELECT ranked_requests.id
FROM ranked_requests
WHERE row_number > 10
)
# MySQL
DELETE FROM web_crawler_requests
WHERE id IN (
SELECT ranked_requests.id
FROM (
SELECT @r := @r + 1 as row_number, id
FROM web_crawler_requests, (SELECT @r := 0) t
WHERE date = '#{1.day.ago.strftime("%Y-%m-%d")}'
ORDER BY count DESC
) ranked_requests
WHERE row_number > 10
)
🌟 swap columns
When MySQL and PG process the update statement, the column reference behavior is inconsistent. PG refers to the original value, while MySQL refers to the updated value, for example:
# postgresql create table tmp (id integer primary key, c1 varchar(10), c2 varchar(10)); insert into tmp values (1,2,3); insert into tmp values (2,4,5); select * from tmp; id | c1 | c2 ----+----+---- 1 | 3 | 2 2 | 5 | 4 update tmp set c1=c2,c2=c1; select * from tmp; id | c1 | c2 ----+----+---- 1 | 3 | 2 2 | 5 | 4 # MySQL create table tmp (id integer primary key, c1 varchar(10), c2 varchar(10)); insert into tmp values (1,2,3); insert into tmp values (2,4,5); select * from tmp; +----+------+------+ | id | c1 | c2 | +----+------+------+ | 1 | 2 | 3 | | 2 | 4 | 5 | +----+------+------+ update tmp set c1=c2,c2=c1; select * from tmp; +----+------+------+ | id | c1 | c2 | +----+------+------+ | 1 | 3 | 3 | | 2 | 5 | 5 | +----+------+------+
🌟 function
Some built-in function names and behaviors of PG and MySQL are inconsistent:
-
regexp_replace -> replace
-
pg_sleep -> sleep
-
ilike -> lower + like
-
~* -> regexp
-
|| -> concat
-
set local statementtimeout -> set session statementtimeout
-
offset a limit b -> limit a offset b
-
@ -> ABS
-
interval -> date_ Add or datediff
-
extract epoch from -> unix_timestimp
-
unnest -> union all
-
json syntax: json - > > 'username' to json - > > '$ username’
-
position in -> locate
-
generate_series -> union
-
greatest & least -> greatest/least + coalesce
🌟 type & casting
MySQL uses the cast function, and PG also supports the same syntax, but four points are more commonly used::, such as SELECT 1::varchar. The conversion types of MySQL can only be the following five: CHAR[(N)], DATE, DATETIME, DECIMAL, SIGNED and TIME.
select cast('1' as signed);
In Rails, PG is mapped to varchar and MySQL is mapped to varchar(255). In fact, PG's varchar can store more than 255. Some data using string in discover will exceed 255 and will be truncated after being converted to MySQL. The solution is to use text type for these columns.
🌟 keywords
The keywords lists of MySQL and PG are not exactly the same. For example, read is a keyword in MySQL but not in PG. The SQL produced by ORM has been handled. Some handwritten SQL needs to be quote d by themselves. PG uses "" and MySQL uses `.
🌟 expression index
PG supports expression index:
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));
Some functions in discover will add unique constraints to the expression index. MySQL has no direct correspondence, but you can use Stored Generated Column to simulate. First, redundant a Stored Generated Column, and then add unique constraints to achieve the same effect.
Rails also supports:
t.virtual "virtual_parent_category_id", type: :string, as: "COALESCE(parent_category_id, '-1')", stored: true t.index "virtual_parent_category_id, name", name: "unique_index_categories_on_name", unique: true
🌟 array && json
PG supports ARRAY and JSON types. MySQL 5.7 already has JSON. In discover, the usage scenarios of ARRAY and JSON are relatively single, and they are used for storage. There is no advanced retrieval requirement. Using JSON directly can replace PG's ARRAY and JSON. However, neither JSON nor text in MySQL supports default value, which can only be set in the application layer. You can use: https://github.com/FooBarWidget/default_value_for
Adaptive TiDB
TiDB supports MySQL transport protocol and most of its syntax, but some features cannot be well implemented in a distributed environment, so the performance of some features is still different from that of MySQL. See the document for details https://pingcap.com/docs-cn/stable/reference/mysql-compatibility/ Next, let's mainly look at some small problems involved in this migration.
🌟 TiDB reserved keyword
TiDB supports Window Function in the new version (v3.0.7 is used in this migration) and introduces {group, rank and row_number and other functions, but the special thing is that the above function names will be treated as keywords by TiDB. Therefore, when opening the Window Function, we need to modify the SQL named similar to the Window Function name and wrap the relevant keywords in backquotes.
TiDB reserved keywords: https://pingcap.com/docs-cn/stable/reference/sql/language-structure/keywords-and-reserved-words/
TiDB window function: https://pingcap.com/docs-cn/stable/reference/sql/functions-and-operators/window-functions/
🌟 Incompatible Insert into select syntax
TiDB does not support this syntax temporarily. You can use insert into select from dual to bypass:
invalid: insert into t1 (i) select 1; valid: insert into t1 (i) select 1 from dual;
🌟 Nested transaction & savepoint
TiDB does not support nested transactions, nor does it support savepoints. However, when the database is MySQL or PostgreSQL, Rails ActiveRecord uses savepoint to simulate nested transactions and uses {requirements_ New option to control the document: https://api.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html .
Therefore, after the database is migrated to TiDB, we need to adjust the business code, adjust the original logic involving "nested transactions" to single-layer transactions, roll back uniformly in case of exceptions, and cancel the use of "requirements" in discover_ New option.
TiDB's powerful compatibility
TiDB is 100% compatible with MySQL 5.7 protocol. In addition, it also supports the common functions and syntax of MySQL 5.7. The system tools (PHPMyAdmin, Navicat, MySQL Workbench, mysqldump, Mydumper/Myloader) and clients in MySQL 5.7 ecosystem are applicable to TiDB. At the same time, after TiDB 5.0, many new features will be released successively, such as expression index, CTE, temporary table, etc. the compatibility of the new version of TiDB is getting better and better, and it will become easier and easier to migrate from MySQL or PostgreSQL to TiDB.
summary
The project has been 100% completed and is currently on the AskTUG website( https://asktug.com )It has been running smoothly on TiDB (current version: tidb-v5.0.x) for more than a year. Yes, without changing the experience, no one found that the database had quietly changed ~ it proved the feasibility of migrating the business running on PG to TiDB.
The address of the project is: https://github.com/tidb-incubator/discourse/tree/my-2.3.3 , you can participate in the improvement and pay attention to the progress of the project through fork & PR. you are also very welcome to feel the goodwill of TiDB community from the partners of ruby community, Ruby On Rails community and discover community.