1. Transaction description
(1) What is a transaction
A transaction is a bundle of things that are bound together and executed sequentially until they are successful, otherwise they are restored to their previous state
Transactions must be subject to ACID principles, which are atomicity, consistency, isolation, and durability, respectively.
Atomicity: When these instructions are operated on, either they are all executed successfully or they are not executed at all.As long as one of the instructions fails, all instructions fail, data is rolled back, back to the data state before the instructions were executed
Consistency: Transaction execution transforms data from one state to another, but remains stable for the integrity of the entire data
Isolation: Any changes to data that occur during the execution of the transaction should only exist in the transaction and have no effect on the outside world. Changes to data made by the transaction will only be displayed after the transaction commits, and the data will not be available to other transactions until the transaction commits
Persistence: When a transaction completes correctly, it is permanent for changes to data
(2) Common errors caused by concurrent transactions
The first type of missing updates: when a transaction is undone, overwrite the update data submitted by other transactions
Dirty Read: One transaction reads uncommitted update data from another transaction
Magic reading is also called virtual reading: a transaction executes two queries, and the second result set contains data that was not found in the first query or that some rows have been deleted, causing two inconsistent results, except that another transaction inserts or deletes data between the two queries
Non-repeatable reading: A transaction reads the data of the same row twice and the result is in a different state. Just in the middle another transaction updates the data. The results are different and cannot be trusted.
The second type of missing updates: is a special case of non-repeatable reading.If both things read the same line, then both write and commit, the changes made by the first thing will be lost
2. redis transaction
The redis transaction is implemented through five commands: MULTI, WATCH, UNWAYCH, EXEC, DISCARD
MUTIL command: To start a transaction, the client can continue to send any number of commands to the server. These commands will not be executed immediately, but will be placed in a queue. When the EXEC command is called, all the commands in the queue will be executed and it will always return OK
WATCH command: Keys are monitored until the user executes the EXEC command. If other clients replace, update or delete any monitored keys first, the transaction will fail and return an error when the user compartment executes the EXEC command (after which the user can choose to retry or abandon the transaction)
UNWATCH command: reset the link after the WATCH command is executed and before the EXEC command is executed
EXEC command: execute transaction command
DISCARD command: Client can cancel WATCH command name and empty all queued commands
3. redis transaction example
The following will illustrate the transaction process with an example of a commodity transaction
(1) Put commodities on the market
a. Use hashes to manage all user information in the market, including user names, money owned by users
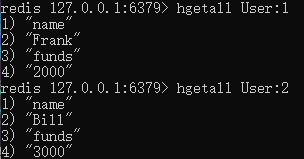
b. Use collections (inventory:) to manage all commodity information for each user, including the name of the commodity
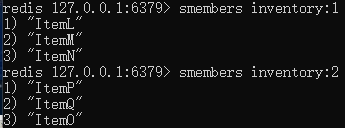
inventory:1 reports for User:1
c. Use ordered collections (market:) to manage goods put on the market
Procedure: Check if the inventory:1 package contains ItemL commodities--->Add ItemL commodities from inventory:1 package to the trading market--->Delete ItemL commodities from inventory:1 package
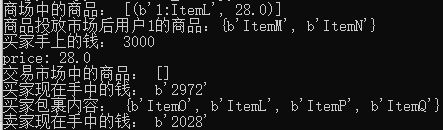
def list_item(conn,userid,goodsname,price): #Use ordered collections (market:) to manage goods put on the market #The key of the item is userid:goodsid inventory = 'inventory:%s' %(userid) user = 'User:%s' %(userid) goodsitem = '%s:%s' %(userid,goodsname) end = time.time() + 5 pipe = conn.pipeline() while time.time() < end: try: pipe.watch(inventory) #Monitor changes to packages if not pipe.sismember(inventory,goodsname): #Check if the user still holds the item that will be put on the market pipe.unwatch() return None pipe.multi() pipe.zadd('market:',{goodsitem:price}) #Put commodities on the market pipe.srem(inventory, goodsname) #Remove the item from the user package pipe.execute() print('Goods in the mall:',conn.zrange('market:', 0, -1,withscores=True)) print('Post-market Users{}Goods:{}'.format(userid, conn.smembers(inventory))) return True except redis.exceptions.WatchError as e: print(e) return False
Testing:

(2) Transaction: User:2 Purchases ItemL commodities in the trading market
Idea: Use watch to monitor the market and the buyer's personal information, then get the amount of money the buyer has and the price of the commodity market, and check if the buyer has enough money to buy the commodity. If the buyer does not have enough money, the program cancels the transaction. If the buyer has enough money, the program first transfers the money paid by the buyer to the seller, and thenRemove the sold goods from the commodity market.
def purchase_item(conn, buyerid, goodsname, sellerid): buyer = 'User:{}'.format(buyerid) #Buyer key seller = 'User:{}'.format(sellerid) #Seller key buy_inventory = 'inventory:{}'.format(buyerid) #Buyer parcel key sell_inverntory = 'inventory:{}'.format(sellerid) #Seller Package key goodsitem = '{}:{}'.format(sellerid,goodsname) #Commodity key in the market end = time.time() + 5 pipe = conn.pipeline() while time.time() < end: try: pipe.watch('market:',buyer) #Monitor the commodity market and buyer's personal information funds = int(pipe.hget(buyer,'funds')) #Get the money the buyer has print('Money in the hands of the buyer:', funds) price = pipe.zscore('market:', goodsitem) #Get the price of the item print('price:',price) if funds < price: pipe.unwatch() return None pipe.multi() pipe.hincrby(buyer, 'funds', int(-price)) #Buyer's money is down pipe.hincrby(seller, 'funds', int(price)) #Seller's Money Increase pipe.sadd(buy_inventory,goodsname) pipe.zrem('market:', goodsitem) pipe.execute() print('Commodities in the trading market:', conn.zrange('market:', 0, -1, withscores=True)) print('The money the buyer has now:',conn.hget(buyer, 'funds')) print('Buyer package contents:', conn.smembers(buy_inventory)) print('The money the seller has now:',conn.hget(seller, 'funds')) return True except redis.exceptions.WatchError as e: print(e) return False
Testing:
if __name__ == '__main__': conn = redis.Redis() #create_users(conn) #create_user_inventory(conn) list_item(conn,1,'ItemL',28) purchase_item(conn, 2, 'ItemL', 1)
4. redis persistence
Redis provides two different persistence methods to store data from memory to hard disk. One is RDB persistence, which is based on the persistence of a database record in redis memory dump to an RDB on disk, and the other is AOF(append only file) persistence, which is based on the replication of the written command executed to disk.
(1) RDB persistence configuration
# Save the DB on disk: # Set the frequency at which sedis mirrors the database. # 900 At least one in seconds (15 minutes) key Value change (then database save)--Persistence). # 300 At least 10 in seconds (5 minutes) key Value change (then database save)--Persistence). # 60 At least 10,000 in seconds (1 minute) key Value change (then database save)--Persistence). save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes # Whether to compress when performing a mirrored backup.yes: compression, but some cpu consumption is required.No: no compression, more disk space is required. rdbcompression yes # One CRC64 The check is placed at the end of the file when stored or loaded rbd There will be a 10 when the file%About this performance degradation, you can turn off this configuration item in order to maximize performance. rdbchecksum yes # File name of snapshot dbfilename dump.rdb # Directory where snapshots are stored dir ./
(2) Ways to create snapshots
A. Clients can create a snapshot by sending besave commands to redis. For platforms that support bgsave commands (basically all platforms support it except the windows platform), redis calls fork to create a child process, which writes the snapshot to disk, and the parent process continues to process command requests
b.Clients can also send save commands to redis to create a snapshot. The redis server that receives the Save command will not respond to any other commands until the snapshot is created. The Save command is not commonly used. We usually use it only when there is not enough memory to support bgsave, or even when waiting for the persistence operation to complete.
c. When redis receives a request to shut down the server through the shutdown command, or when it receives the standard term command, it executes a save command, blocks all clients, stops executing any commands sent by clients, and shuts down the server after the Save command has been executed
d. When a redis server links to another redis server and sends sync synchronization commands to each other to start a replication operation, if the master server is not currently performing the bgsave operation, or if the master server has not just completed the bgsave operation, the master server will perform the bgsave operation
(3) AOF persistence configuration
# Whether to turn on AOF, turn off by default (no) appendonly yes # Specify AOF file name appendfilename appendonly.aof # Redis supports three different brush modes: # appendfsync always #Force a write to disk every time a write command is received, which is the most guaranteed, complete persistence, but also the slowest, and is generally not recommended. appendfsync everysec #Forcing disk writes every second is a recommended way to compromise performance and persistence. # appendfsync no #Completely dependent on OS write, usually about 30 seconds, best performance but least guaranteed persistence, not recommended. #During log rewriting, command appending is not performed, but rather placed in a buffer to avoid conflicts with command appending on DISK IO. #Set to yes means no fsync for new writes during rewrite, temporarily in memory, write after rewrite is complete, default is no, yes is recommended no-appendfsync-on-rewrite yes #The current AOF file size automatically starts a new log rewrite process when it is twice the size of the AOF file from the last log rewrite. auto-aof-rewrite-percentage 100 #The current AOF file initiates a new log rewrite process minimum to avoid frequent rewrites due to smaller file sizes when Reids is just started. auto-aof-rewrite-min-size 64mb
(4) AOF Rewrite Principle
AOF rewrite, like RDB snapshot creation, cleverly utilizes write-time replication:
a. Redis executes fork(), now has both parent and child processes
b. The subprocess begins writing the contents of the new AOF file to the temporary file
c. For all newly executed write commands, the parent process adds these changes to the end of the existing AOF file while accumulating them in a memory cache so that the existing AOF file is safe even if it stops halfway through the override
d. When the child process finishes rewriting, it sends a signal to the parent process, which, upon receiving the signal, appends all the data in the memory cache to the end of the new AOF file
Note: The main process is blocked when appending data from the memory cache to the end of the new AOF file and rename
Origin: https://www.cnblogs.com/xiaobingqianrui/p/10094845.html