The contents of this article are as follows. After reading this article, you will find out the following interview questions related to Golang Map
Interview questions
- The underlying implementation principle of map
- Why is traversing a map unordered?
- How to realize orderly traversal of map?
- Why is Go map non thread safe?
- How to implement thread safe map?
- Go sync.map and native map whose performance is good and why?
- Why is the load factor of Go map 6.5?
- What is the map expansion strategy?
Implementation principle
Map in Go is a pointer, occupying 8 bytes, pointing to the hmap structure; Source code Src / Runtime / map You can see the underlying structure of the map in Go
The underlying structure of each map is hmap, which contains several bucket arrays with bmap structure. The bottom layer of each bucket adopts a linked list structure. Next, let's take a detailed look at the structure of the map

hmap structure
// A header for a Go map.
type hmap struct {
count int
// Represents the number of elements in the hash table. When len(map) is called, the field value is returned.
flags uint8
// Status flag. The meanings of four status bits will be explained in the constants below.
B uint8
// Log of buckets_ two
// If B=5, the length of buckets array = 2 ^ 5 = 32, which means there are 32 buckets
noverflow uint16
// Approximate number of spilled barrels
hash0 uint32
// Hash seed
buckets unsafe.Pointer
// Pointer to the buckets array. The array size is 2^B. if the number of elements is 0, it is nil.
oldbuckets unsafe.Pointer
// In case of capacity expansion, oldbuckets is a pointer to the old buckets array, and the size of the old buckets array is 1 / 2 of that of the new buckets; In the non expansion state, it is nil.
nevacuate uintptr
// Indicates the expansion progress. buckets less than this address indicates that the relocation has been completed.
extra *mapextra
// This field is designed to optimize GC scanning. Used when both key and value do not contain pointers and can be inline. extra is a pointer to mapextra type.
}bmap structure
bmap is what we often call a "bucket". A bucket can hold up to 8 keys. The reason why these keys fall into the same bucket is that after hash calculation, the hash result is "one class". We will describe the location of keys in detail in map query and insertion. In the bucket, the position of the key in the bucket will be determined according to the upper 8 bits of the hash value calculated by the key (there are at most 8 positions in a bucket).
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
// Array with len = 8
// Used to quickly locate whether the key is in this bmap
// Slot array of buckets. A bucket can have up to 8 slots. If the slot of the key is in tophash, it means that the key is in this bucket
}
//Underlying defined constants
const (
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Up to 8 positions per barrel
)
But this is only the surface(src/runtime/hashmap.go)A new structure will be created dynamically by adding materials to it during compilation:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
// Overflow bucket
}The bucket memory data structure is visualized as follows:
Note that key and value are put together separately, not key/value/key/value / Such a form. The advantage of this is that in some cases, the padding field can be omitted to save memory space.
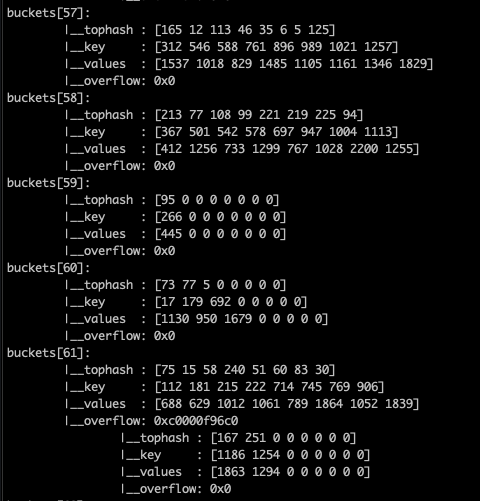
mapextra structure
When the key and value of the map are not pointers and the size is less than 128 bytes, bmap will be marked without pointers, which can avoid scanning the entire hmap during gc. However, we can see that bmap actually has an overflow field of pointer type, which destroys the assumption that bmap does not contain a pointer. At this time, overflow will be moved to the extra field.
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and value do not contain pointers and can be inline (< = 128 bytes)
// Use the extra field of hmap to store overflow buckets, which can avoid GC scanning the entire map
// However, BMAP Overflow is also a pointer. At this time, we can only put these overflow pointers
// All in hmap extra. Overflow and hmap extra. Oldover flow
// overflow contains hmap overflow of buckets
// oldoverflow contains the hmap. When the capacity is expanded overflow bucket of oldbuckets
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
// Pointer to idle overflow bucket
}Main characteristics
reference type
map is a pointer, and the underlying layer points to hmap, so it is a reference type
golang has three commonly used advanced types: slice, map and channel. They are all reference types. When the reference type is used as a function parameter, the original content data may be modified.
There is no reference passing in golang, only value and pointer passing. Therefore, when a map is passed as a function argument, it is essentially a value transfer, but because the underlying data structure of the map points to the actual element storage space through a pointer, modifying the map in the called function is also visible to the caller. Therefore, when a map is passed as a function argument, it shows the effect of reference transfer.
Therefore, when passing a map, if you want to modify the contents of the map instead of the map itself, the function parameters do not need to use pointers
func TestSliceFn(t *testing.T) {
m := map[string]int{}
t.Log(m, len(m))
// map[a:1]
mapAppend(m, "b", 2)
t.Log(m, len(m))
// map[a:1 b:2] 2
}
func mapAppend(m map[string]int, key string, val int) {
m[key] = val
}Shared storage
The underlying data structure of map points to the actual element storage space through pointers. In this case, changes to one map will affect other maps
func TestMapShareMemory(t *testing.T) {
m1 := map[string]int{}
m2 := m1
m1["a"] = 1
t.Log(m1, len(m1))
// map[a:1] 1
t.Log(m2, len(m2))
// map[a:1]
}Ergodic order random
If the map is not modified, the order of the output key s and value s may be different when traversing the map multiple times using range. This is intentional by the designers of Go language. The order of each range is randomized to remind developers that the underlying implementation of Go does not guarantee the stability of map traversal order. Please do not rely on the order of range traversal results.
The map itself is disordered, and the traversal order will be randomized. If you want to traverse the map sequentially, you need to sort the map key s first, and then traverse the map in the order of the keys.
func TestMapRange(t *testing.T) {
m := map[int]string{1: "a", 2: "b", 3: "c"}
t.Log("first range:")
// Default unordered traversal
for i, v := range m {
t.Logf("m[%v]=%v ", i, v)
}
t.Log("\nsecond range:")
for i, v := range m {
t.Logf("m[%v]=%v ", i, v)
}
// Realize orderly traversal
var sl []int
// Take out the key separately and put it in the slice
for k := range m {
sl = append(sl, k)
}
// Sort slice
sort.Ints(sl)
// Traversing the map in the order of the key s in the slice is ordered
for _, k := range sl {
t.Log(k, m[k])
}
}Non thread safe
map is unsafe for concurrency by default for the following reasons:
After a long discussion, Go officials believe that Go map should be more suitable for typical use scenarios (no secure access from multiple goroutine s is required), rather than for a small number of cases (concurrent access), which leads to the locking cost (performance) of most programs, so it is not supported.
Scenario: two coroutines are read and written at the same time, and the following program will have fatal error: fatal error: concurrent map writes
func main() {
m := make(map[int]int)
go func() {
//Open a collaborative process to write a map
for i := 0; i < 10000; i++ {
m[i] = i
}
}()
go func() {
//Open a collaborative process to read map
for i := 0; i < 10000; i++ {
fmt.Println(m[i])
}
}()
//time.Sleep(time.Second * 20)
for {
;
}
}There are two ways to achieve map thread safety:
Method 1: use read / write lock map + sync RWMutex
func BenchmarkMapConcurrencySafeByMutex(b *testing.B) {
var lock sync.Mutex //mutex
m := make(map[int]int, 0)
var wg sync.WaitGroup
for i := 0; i < b.N; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
lock.Lock()
defer lock.Unlock()
m[i] = i
}(i)
}
wg.Wait()
b.Log(len(m), b.N)
}Method 2: use sync. Provided by golang Map
sync.map is realized by separating reading and writing, and its idea is to exchange space for time. Compared with the implementation of map+RWLock, it has made some optimizations: it can access the read map without lock, and will give priority to the operation of the read map. If only the operation of the read map can meet the requirements (addition, deletion, modification, query and traversal), there is no need to operate the write map (its reading and writing must be locked). Therefore, in some specific scenarios, the frequency of lock competition will be much less than that of the implementation of map+RWLock.
func BenchmarkMapConcurrencySafeBySyncMap(b *testing.B) { var m sync.Map var wg sync.WaitGroup for i := 0; i < b.N; i++ { wg.Add(1) go func(i int) { defer wg.Done() m.Store(i, i) }(i) } wg.Wait() b.Log(b.N)}Hash Collisions
map in golang is a kv pair set. The bottom layer uses hash table and linked list to solve conflicts. In case of conflicts, not every key applies for a structure to be linked through the linked list, but is mounted with bmap as the minimum granularity. A bmap can hold 8 kv. In the selection of hash function, check whether the cpu supports aes when the program starts. If yes, use aes hash, otherwise use memhash.
Common operation
establish
map has three initialization modes, which are generally created by making
func TestMapInit(t *testing.T) { // Initialization method 1: directly declare / / var M1 map [string] int / / M1 ["a"] = 1 / / t.log (M1, unsafe. Sizeof (M1)) / / panic: assignment to entry in nil map / / be careful when writing to a map, because writing to an uninitialized map (value Nil) will cause panic, Therefore, when writing to a map, you need to perform empty judgment first. / / initialization method 2: use literal M2: = map [string] int{} M2 ["a"] = 2 t.log (m2, unsafe. Sizeof (M2)) / / map [A: 2] 8 / / initialization method 3: use make to create M3: = make (map [string] int) m3 ["a"] = 3 t.log (M3, unsafe. Sizeof (M3)) / / map [A: 3] 8}When creating a map, you can know by generating assembly code that the underlying function called by make when creating a map is runtime makemap. If the initial capacity of your map is less than or equal to 8, you will find that it is running time Fastrand is because when the capacity is less than 8, multiple buckets do not need to be generated, and the capacity of one bucket can be met
Create process
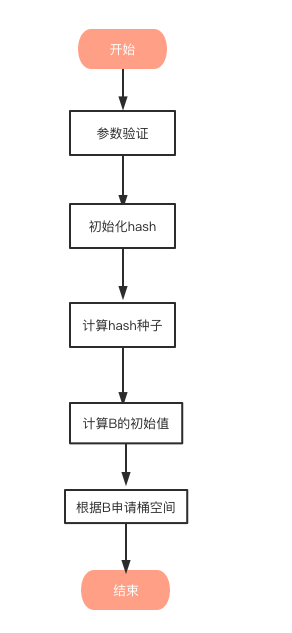
The makemap function creates a random hash seed through fastrand, then calculates the minimum number of buckets required according to the incoming hint, and finally uses makeBucketArray to create an array for storing buckets. This method is actually to allocate a continuous space in memory for storing data according to the number of buckets to be created calculated by the incoming B, In the process of creating buckets, some additional buckets for storing overflow data will be created, and the number is 2^(B-4). The hmap pointer is returned after initialization.
Calculate the initial value of B
Find a B so that the loading factor of the map is within the normal range
B := uint8(0)for overLoadFactor(hint, B) { B++}h.B = B// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.func overLoadFactor(count int, B uint8) bool { return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}lookup
There are two syntax for reading map in Go language: with comma and without comma. When the key to be queried is not in the map, the usage with comma will return a bool variable indicating whether the key is in the map; Statements without comma return a zero value of type value. If value is of type int, it will return 0. If value is of type string, it will return an empty string.
// Without comma usage value = m ["name"] FMT Printf ("value:% s", value) / / with comma usage value, OK: = m ["name"] if ok {FMT. Printf ("value:% s", value)}The search of map can be known by generating assembly code. According to different types of key s, the compiler will replace the search function with a more specific function to optimize efficiency:
| key type | lookup |
|---|---|
| uint32 | mapaccess1_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint32 | mapaccess2_fast32(t maptype, h hmap, key uint32) (unsafe.Pointer, bool) |
| uint64 | mapaccess1_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| uint64 | mapaccess2_fast64(t maptype, h hmap, key uint64) (unsafe.Pointer, bool) |
| string | mapaccess1_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
| string | mapaccess2_faststr(t maptype, h hmap, ky string) (unsafe.Pointer, bool) |
Find process

Write protection monitoring
The function first checks the flag bit flags of the map. If the write flag bit of flags is set to 1 at this time, it indicates that other coprocessors are performing "write" operations, resulting in program panic. This also shows that map is not safe for collaborative processes.
if h.flags&hashWriting != 0 { throw("concurrent map read and map write")}Calculate hash value
hash := t.hasher(noescape(unsafe.Pointer(&ky)), uintptr(h.hash0))
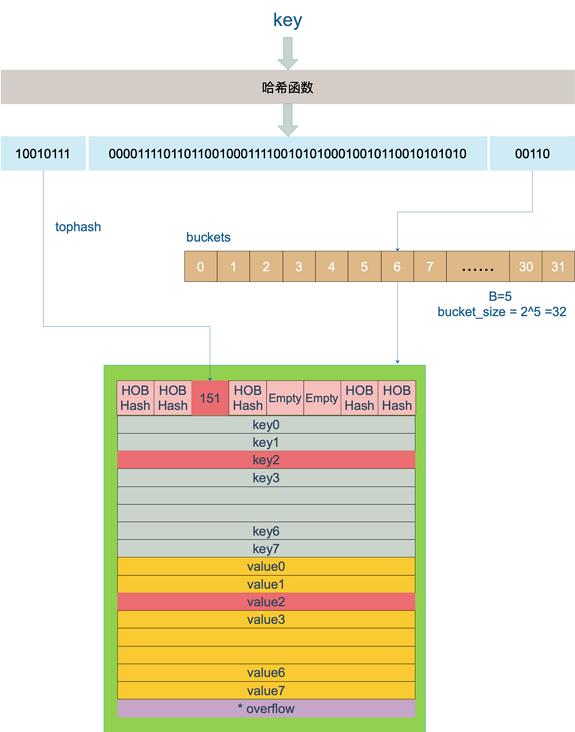
After the key is calculated by the hash function, the hash value obtained is as follows (64 bits in total under the mainstream 64 bit machine):
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
Find the bucket corresponding to the hash
m: Number of barrels
Get the corresponding bucket from buckets through hash & M. if the bucket is expanding and the expansion is not completed, get the corresponding bucket from oldbuckets
m := bucketMask(h.B)b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))// M buckets correspond to B bits if C: = h.oldbuckets; c != Nil {if! H.samesizegrow() {/ / m before capacity expansion is half of the previous m > > = 1} oldB: = (* BMAP) (add (C, (hash & M) * uintptr (t.bucketsize))) if! evacuated(oldb) { B = oldb }}Calculate the bucket number of hash:
Use the last 5 bit s of the hash value in the previous step, that is, 01010, and the value is 10, that is, bucket 10 (the range is bucket 0 ~ 31)
Traversal bucket
Calculate the slot where the hash is located:
top := tophash(hash)func tophash(hash uintptr) uint8 { top := uint8(hash >> (goarch.PtrSize*8 - 8)) if top < minTopHash { top += minTopHash } return top}Use the upper 8 bit s of the hash value in the previous step, that is, 10010111, to convert it into decimal, that is, 151. Look for the slot with the tophash value (HOB hash) of 151 * in bucket 10, that is, the location of the key. Find slot 2, and the whole search process is over.
If it is not found in the bucket and overflow is not empty, continue to search in the overflow bucket until all key slots are found or searched, including all overflow buckets.
Returns the pointer corresponding to the key
The corresponding slot is found above. Here we will analyze in detail how the key/value value is obtained:
// key positioning formula k: = add (unsafe. Pointer (b), dataoffset + I * uintptr (t.keysize)) / / value positioning formula v:= add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) / / offset of BMAP starting address: dataoffset = unsafe Offsetof(struct{ b bmap v int64}{}.v)The starting address of the key in the bucket is unsafe Pointer(b)+dataOffset. The address of the i-th key should span the size of the i-th key on this basis; We also know that the address of value is after all keys, so the address of the ith value needs to add the offset of all keys.
assignment
From the assembly language, you can see that the mapassign function is called when you insert or modify the key into the map.
In fact, the syntax of inserting or modifying keys is the same, except that the keys operated by the former do not exist in the map, while the keys operated by the latter exist in the map.
mapassign has a series of functions. According to different key types, the compiler will optimize them into corresponding "fast functions".
| key type | insert |
|---|---|
| uint32 | mapassign_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint64 | mapassign_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| string | mapassign_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
We only study the most general assignment function mapassign.
Assignment process
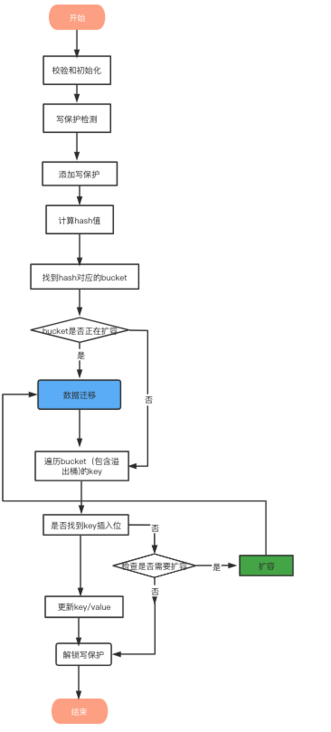
The assignment of map will be accompanied by the expansion and migration of map. The expansion of map only doubles the underlying array without data transfer. The data transfer is carried out step by step after the expansion. In the process of migration, at least one migration will be carried out every assignment (access or delete).
Checksum initialization
1. Judge whether the map is nil
- Judge whether to read and write map concurrently. If so, throw an exception
- Judge whether buckets are nil. If so, call newobject to allocate according to the current bucket size
transfer
For each assignment / deletion operation, as long as oldbuckets= Nil thinks that it is expanding capacity and will do a migration. The migration process will be described in detail below
Find & update
According to the above search process, find the location of the key. If it is found, update it. If it is not found, insert it in an empty space
Capacity expansion
After the previous iterative search action, if the pluggable position is not found, it means that the capacity needs to be expanded for insertion. The capacity expansion process will be described in detail below
delete
As can be seen from the assembly language, the mapdelete function is called after deleting the key from the map
func mapdelete(t \*maptype, h _hmap, key unsafe.Pointer)
The deletion logic is relatively simple. Most functions have been used in assignment operations. The core is to find the specific location of the key. The search process is similar. Search cell by cell in the bucket. After finding the corresponding position, perform the "reset" operation on the key or value, reduce the count value by 1, and set the tophash value of the corresponding position to Empty
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*2*goarch.PtrSize+i*uintptr(t.elemsize))if t.elem.ptrdata != 0 { memclrHasPointers(e, t.elem.size)} else { memclrNoHeapPointers(e, t.elem.size)}b.tophash[i] = emptyOneCapacity expansion
Expansion opportunity
Let's talk about the time to trigger the expansion of map: when inserting a new key into the map, condition detection will be carried out. If the following two conditions are met, the expansion will be triggered:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again }1. Load factor exceeds threshold
The threshold defined in the source code is 6.5 (loadFactorNum/loadFactorDen), which is a reasonable factor taken out after testing
We know that each bucket has 8 empty spaces. When there is no overflow and all buckets are full, the load factor is 8. Therefore, when the load factor exceeds 6.5, it indicates that many buckets are almost full, and the search efficiency and insertion efficiency become lower. It is necessary to expand the capacity at this time.
For condition 1, there are too many elements and too few buckets. It is simple: add B to 1, and the maximum number of buckets (2^B) will directly become twice the number of original buckets. So there are new and old buckets. Note that at this time, the elements are in the old bucket and have not been migrated to the new bucket. The maximum number of new buckets is only twice the original maximum number (2^B * 2).
2. overflow has too many bucket s
When the loading factor is relatively small, the efficiency of map search and insertion is also very low, which can not be recognized in point 1. The surface phenomenon is that the molecules for calculating the loading factor are relatively small, that is, the total number of elements in the map is small, but the number of buckets is large (the number of buckets actually allocated is large, including a large number of overflow bucket s)
It's not hard to imagine the reason for this: constantly inserting and deleting elements. Many elements are inserted first, resulting in the creation of many buckets, but the loading factor does not reach the critical value of point 1. Capacity expansion is not triggered to alleviate this situation. After that, delete elements, reduce the total number of elements, and then insert many elements, resulting in the creation of many overflow buckets, but it will not trigger the provisions of point 1. What can you do with me? The number of overflow buckets is too large, resulting in scattered key s and frightening low search and insertion efficiency. Therefore, point 2 is issued. It's like an empty city. There are many houses, but there are few residents. They are scattered. It's difficult to find people
For condition 2, there are not so many elements, but the number of overflow buckets is very large, indicating that many buckets are not full. The solution is to open up a new bucket space and move the elements in the old bucket to the new bucket, so that the keys in the same bucket are arranged more closely. In this way, the key in the overflow bucket can be moved to the bucket. The result is to save space and improve bucket utilization, which will naturally improve the efficiency of map search and insertion.
Expansion function
func hashGrow(t *maptype, h *hmap) { bigger := uint8(1) if !overLoadFactor(h.count+1, h.B) { bigger = 0 h.flags |= sameSizeGrow } oldbuckets := h.buckets newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil) flags := h.flags &^ (iterator | oldIterator) if h.flags&iterator != 0 { flags |= oldIterator } // commit the grow (atomic wrt gc) h.B += bigger h.flags = flags h.oldbuckets = oldbuckets h.buckets = newbuckets h.nevacuate = 0 h.noverflow = 0 if h.extra != nil && h.extra.overflow != nil { // Promote current overflow buckets to the old generation. if h.extra.oldoverflow != nil { throw("oldoverflow is not nil") } h.extra.oldoverflow = h.extra.overflow h.extra.overflow = nil } if nextOverflow != nil { if h.extra == nil { h.extra = new(mapextra) } h.extra.nextOverflow = nextOverflow } // the actual copying of the hash table data is done incrementally // by growWork() and evacuate().}Because the map expansion requires relocating the original key/value to a new memory address, if a large number of key / values need to be relocated, it will greatly affect the performance. Therefore, the capacity expansion of Go map adopts a "progressive" method. The original keys will not be relocated at one time, and only 2 bucket s will be relocated at most each time.
The hashGrow() function mentioned above does not actually "relocate". It just allocates new buckets and hangs the old buckets in the oldbuckets field. The action of actually moving buckets is in the growWork() function, while the action of calling the growWork() function is in the mapassign and mapdelete functions. That is, when you insert, modify, or delete a key, you will try to move buckets. First check whether the old buckets have been relocated. Specifically, check whether the old buckets are nil.
transfer
Migration timing
If the migration is not completed, the migration will not be performed immediately after the capacity expansion (pre allocated memory) is completed during assignment / deletion. Instead, incremental capacity expansion is adopted. Only when a specific bucket CET is accessed will the migration be carried out gradually (the old bucket will be migrated to the bucket)
if h.growing() { growWork(t, h, bucket)}Transfer function
func growWork(t *maptype, h *hmap, bucket uintptr) { // First move the bucket to evaluate (T, h, Bucket & h.oldbucketmask()) / / then move a bucket if h.growing() {evaluate (T, h, h.nevada)}}Replace indicates the current progress. If the relocation is completed, it should be the same length as 2^B
The implementation of the evaluate method is to transfer the bucket corresponding to this location and the data on its conflict chain to new buckets.
- First, judge whether the current bucket has been transferred. (oldbucket identifies the location of the bucket to be relocated)
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))// Judge if! Evaluated (b) {/ / transfer}The transfer can be judged directly through tophash, and the first hash value in tophash can be judged
func evacuated(b *bmap) bool { h := b.tophash[0] // All the flag s in this interval have been transferred. Return H > emptyone & & H < mintophash / / 1 ~ 5}- If it is not transferred, the data will be migrated. During data migration, you may migrate to buckets of the same size or to buckets twice the size. Here, xy marks the target migration location: x marks the migration to the same location, and y marks the migration to a location twice as large. Let's first look at the determination of the target location:
var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))x.k = add(unsafe.Pointer(x.b), dataOffset)x.v = add(x.k, bucketCnt*uintptr(t.keysize))if !h.sameSizeGrow() { // If it is twice the size, you have to calculate the value of Y once: y = &xy [1] y.b = (* BMAP) (add (h.buckets, (oldbucket + newbit) * uintptr (t.bucketsize))) y.k = add (unsafe. Pointer (y.b), dataoffset) y.v = add (y.k, bucketcnt * uintptr (t.keysize))}- After determining the bucket location, you need to migrate one by kv one.
- If the location of the currently relocated bucket is the same as that of the overall relocated bucket, we need to update the overall progress flag, evacuate
// Newbit is the length of oldbuckets, and it is also the key point of nest function advanceevaluationmark (h * hmap, t * maptype, newbit uintpr) {/ / first update the flag h.nest + + / / view up to 2 ^ 10 buckets stop: = h.nest + 1024 if stop > newbit {stop = newbit} / / if there is no relocation, stop it and wait for the next relocation for h.nest= Stop & & bucketevaluated (T, h, h.nevada) {h.nevada + +} / / if all the old buckets have been relocated successfully, clear the old buckets if h.nevada = = newbit {h.oldbuckets = nil if h.extra! = nil {h.extra. Oldoverflow = nil} h.flags & ^ = samesizegrow}ergodic
The process of traversal is to traverse buckets in order and the key s in buckets in order.
map traversal is unordered. If you want to achieve orderly traversal, you can sort the key s first
Why is traversing a map unordered?
If the key has been migrated, the position of the key has changed significantly. Some keys fly to the high branch, and some keys remain in place. In this way, the results of traversing the map cannot be in the original order.
If you write a dead map, you will not insert or delete it. It is reasonable that each time you traverse such a map, you will return a fixed order key/value sequence. But Go put an end to this practice, because it will bring misunderstanding to novice programmers, thinking that this is bound to happen. In some cases, it may lead to big mistakes.
Go is even better. When we traverse the map, we don't start from bucket 0. Each time we traverse from a bucket with a random number, and we traverse from a cell with a random number of this bucket. In this way, even if you are a dead map and just traverse it, you are unlikely to return a fixed sequence of key/value pairs.
//runtime. Select the function func mapiterinit (t * maptype, h * hmap, it * hiter) {... It. T = t it. H = h it. B = H.B it. Buckets = h.buckets if t.bucket. Kind & kindnopointers! = 0 {h.createoverflow() it. Overflow = h.extra.overflow it. Oldoverflow = h.extra.oldoverflow} R: = uintptr (fastrand()) if H.B > 31 bucketcntbits { r += uintptr(fastrand()) << 31 } it. startBucket = r & bucketMask(h.B) it. offset = uint8(r >> h.B & (bucketCnt - 1)) it. bucket = it. startBucket ... mapiternext(it)}summary
- map is a reference type
- map traversal is unordered
- map is non thread safe
- The hash conflict resolution method of map is linked list method
- The expansion of map does not necessarily add new space, or it may be just memory consolidation
- The migration of map is carried out step by step. At least one migration will be carried out during each assignment
Deleting the key in the map may lead to many empty kv, which will lead to migration. If it can be avoided, try to avoid it
This article is composed of blog one article multi posting platform OpenWrite release!