Fork-Join
Fork join embodies the design idea of divide and rule
- Divide and rule: divide a big problem into several identical small problems, and there is no correlation between each small problem
Principle:
- When necessary, a large task is fork ed into several small tasks. After each small task is completed, the results of these small tasks are combined and summarized
Sketch Map:
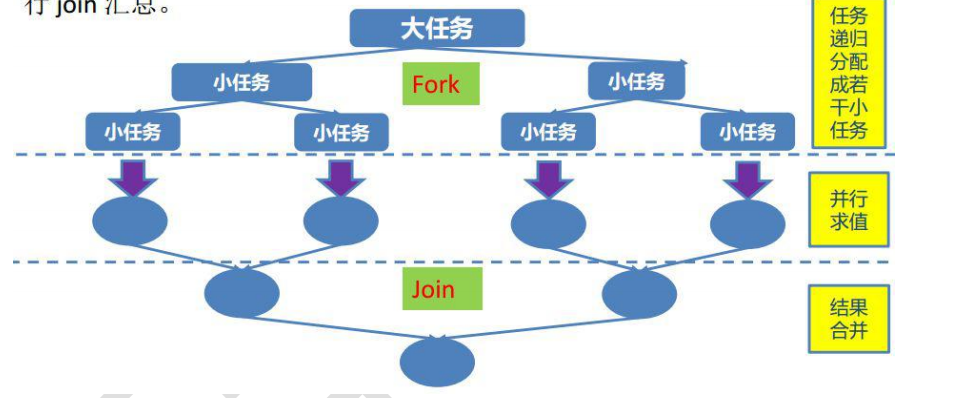
Working secret:
- The so-called work secret, for example: suppose that the current large task is divided into 50 small tasks, but only 5 threads can be used to execute tasks, that is, each thread needs to process 10 tasks. When a thread completes its 10 tasks quickly, It will go to another thread that has not been executed to get the unprocessed task. After processing, it will put the task result back to the corresponding thread
Working diagram
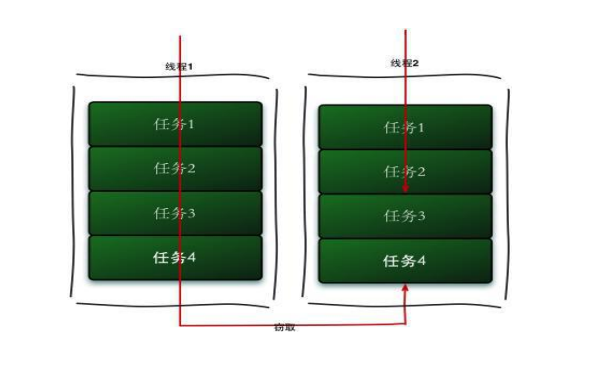
- Working secret can make full use of thread utilization, so as to speed up the execution speed
Fork join standard paradigm
Sketch Map:
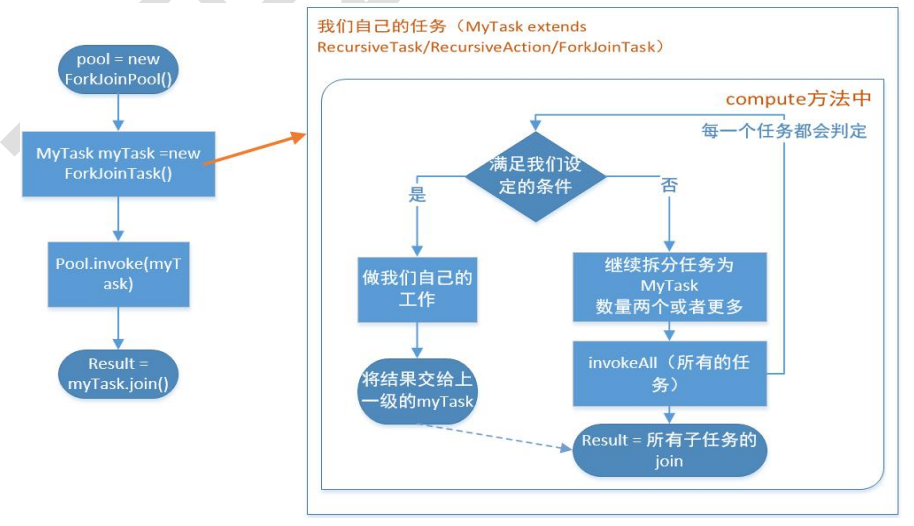
-
If we need to use the fork Join framework, we must first create a fork Join task. It needs to provide a mechanism for executing fork and Join operations in tasks. Generally, we inherit the subclass of ForkJoinTask:
- Recursive task < T >: used for tasks with return values
- RecursiveAction: used for tasks with no return value
-
Task tasks need to be executed through ForkJoinPool and submitted using submit or invoke. The difference between the two is:
- submit: asynchronous execution. After calling, the corresponding thread can continue to execute the following program without waiting for the task to complete
- invoke: synchronous execution. After calling, you need to wait for the task to complete before executing the following program
-
The join and get methods are used to get the results returned after the task is executed
-
In the compute method implemented by ourselves, we first need to judge whether the task is small enough. If it is small enough, we can execute the task directly; If it is judged that the task is not small enough, you must continue to split it into two subtasks. Each subtask will enter the * * compute * * method when calling the * * invokeAll() * * method; Using the * * join * * method will wait for the subtask to finish executing and get its results.
-
When implementing related functions with fork join, the work content is actually divided into two parts:
- Fork, i.e. parsing tasks, filtered to a small enough size for step-by-step execution;
- Join, which is the integration of the results of small tasks. Finally complete the realization of the complete function.
Code example:
/* Use RecursiveTask to calculate a large array and get its final calculated value */
package demo3;
import java.util.Random;
class UserArray {
//Array length
public static final int ARRAY_LENGTH = 4000;
public static int[] makeArray() {
//new a random number generator
Random r = new Random();
int[] result = new int[ARRAY_LENGTH];
for(int i=0;i<ARRAY_LENGTH;i++){
//Fill the array with random numbers
result[i] = r.nextInt(ARRAY_LENGTH*3);
}
return result;
}
}
package demo3;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
class SumArray extends RecursiveTask<Integer> {
public int[] src;
public int fromIndex;
public int toIndex;
public static final int STANDED = UserArray.ARRAY_LENGTH/10;
public SumArray(int[] array, int start, int end) {
src = array;
fromIndex = start;
toIndex = end;
}
@Override
protected Integer compute() {
//First, judge whether the current task is small enough
if ((toIndex - fromIndex) < STANDED) {
//The task is small enough to calculate directly
int result = 0;
for(int i = fromIndex; i < toIndex; i++) {
result += src[i];
}
return result;
} else {
//The task is not small enough and needs to be further split
//The dichotomy is adopted here, and the intermediate value is taken for splitting
int midIndex = (fromIndex + toIndex) / 2;
//Divide the task into two subtasks, that is, create two subtasks
SumArray leftSumTask = new SumArray(src, fromIndex, midIndex);
SumArray rightSumTask = new SumArray(src, (midIndex + 1), toIndex);
//After creating two subtasks, submit the subtasks through invokeAll
invokeAll(leftSumTask, rightSumTask);
//After submitting, obtain the return value of the subtask through the join method
return leftSumTask.join() + rightSumTask.join();
}
}
public static void main(String[] args) {
//Create an array that needs to be calculated
int[] Array = UserArray.makeArray();
//Create ForkJoinPool
ForkJoinPool pool = new ForkJoinPool();
//Create fork join task
SumArray sumTask = new SumArray(Array, 0, Array.length - 1);
//Record the start time
long start = System.currentTimeMillis();
//Submit the created fork join task to ForkJoinPool for execution
pool.invoke(sumTask);
//Obtain the execution result of fork join task through join method
int result = sumTask.join();
//Output results and time spent
System.out.println("sum result = " + result + ", spend time = " + (System.currentTimeMillis() - start));
}
}
/* Use RecursiveTask to sort a large array and get the final sorted array */
class SortArray extends RecursiveTask<int[]> {
public int[] src;
public int fromIndex, toIndex;
public static final int STAND = UserArray.ARRAY_LENGTH/10;
public SortArray(int[] array) {
this.src = array;
fromIndex = 0;
toIndex = src.length - 1;
}
@Override
protected int[] compute() {
//Sort the sub tables
//First, determine the size of the sub table and sort the sub table in fork
if ((toIndex - fromIndex) < STAND) {
int i, j, temp;
for (i = fromIndex; i < toIndex; i++) {
for (j = i+1; j<= toIndex; j++) {
if (src[i] > src[j]) {
temp = src[i];
src[i] = src[j];
src[j] = temp;
}
}
}
return src;
} else {
//The sub table size does not meet the requirements. You need to continue splitting
int midIndex = (fromIndex + toIndex)/2;
SortArray left = new SortArray(Arrays.copyOfRange(src, fromIndex, midIndex));
SortArray right = new SortArray(Arrays.copyOfRange(src, midIndex+1, toIndex));
//The split left and right sub tables are submitted again
SortArray.invokeAll(left, right);
//Get the sorting of each sub table and get the ordered table
int[] resLeft = left.join();
int[] resRight = right.join();
//Merge ordered sub tables
int[] result = new int[resLeft.length + resRight.length];
for(int index = 0, i = 0, j = 0; index < result.length; index++) {
if (i >= resLeft.length) {
//If i is greater than the length of the left sub table, it indicates that the left sub table has been stored, and the right sub table can be stored in order
result[index] = resRight[j++];
} else if (j >= resRight.length) {
//If j is greater than the length of the right sub table, it indicates that the right sub table is stored, and the left sub table can be stored in order
result[index] = resLeft[i++];
} else if (resLeft[i] > resRight[j]) {
//If the value of the left sub table is greater than that of the right sub table, the value of the right sub table is stored in the last result array
result[index] = resRight[j++];
}else if (resLeft[i] <= resRight[j]) {
//If the value of the right sub table is greater than that of the left sub table, the value of the left sub table is stored in the last result array
result[index] = resLeft[i++];
}
}
return result;
}
}
public static void main(String[] args) {
//New sort array
int[] array = UserArray.makeArray();
//Create ForkJoinPool
ForkJoinPool pool = new ForkJoinPool();
//New task
SortArray sortTask = new SortArray(array);
//Put the task into the pool for execution
pool.invoke(sortTask);
//Get the final sorted array
int[] res = sortTask.join();
for (int i = 0; i < res.length; i++) {
System.out.println("array[ " + i + " ] = " + res[i] + "\n");
}
}
}
- If we use a single thread to perform accumulation, we will find that for this example only, the single thread performs faster. The reason is that the fork join framework uses recursion and multithreading. Recursion will involve out of stack and into stack actions, and the existence of multithreading will involve context switching actions, which are time-consuming operations, Therefore, in the scenario where the amount of data is small and the task is not time-consuming, fork join may not run as fast as a single thread, which also shows that using fork join does not mean that it runs a certain fast; However, as long as the task is time-consuming or the scene with a large amount of data, the operation efficiency and speed of fork join can be reflected!
CountDownLatch
CountDownLatch function:
-
CountDownLatch class enables a thread to wait for other threads to finish their work before executing
-
CountDownLatch is essentially implemented through a counter. The initial value of the counter is the number of initial tasks. Every time a task is completed, CountDownLatch can be called Countdown() decrements the counter by one. When the counter is 0, it means that all tasks have been completed. Then wait for CountDownLatch on the lock The thread of await () can resume execution
Execution diagram of CountDownLatch:
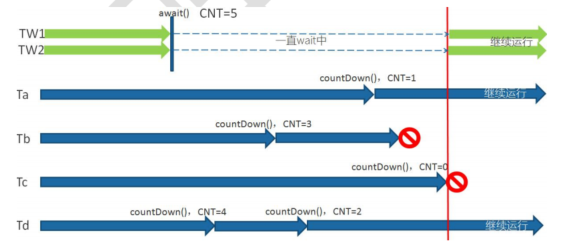
From this picture, we can learn three information:
1. CNT The number of threads and the number of threads may not be equal, CNT The number of threads can be much larger than the number of threads 2. The same thread can execute multiple times`CountDownLatch.countDown()`To decrement the counter 3. It can be called by multiple threads`CountDownLatch.await()`Method to wait
When using CountDownLatch, there is no need to consider thread safety, because AQS is used inside CountDownLatch. For details, see the AQS introduction article later
Code example
public class MyClass {
public static CountDownLatch latch;
static class MyThread implements Runnable {
@Override
public void run() {
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
System.out.println("this Thread:" + Thread.currentThread().getName() + ",latch num = " + latch.getCount());
}
}
public static void main(String[] args) throws InterruptedException {
latch = new CountDownLatch(3);
Thread thread1 = new Thread(new MyThread());
Thread thread2 = new Thread(new MyThread());
thread1.start();
thread2.start();
System.out.println("This is Main Thread, latch count num = " + latch.getCount());
latch.countDown();
latch.await();
System.out.println("main thread end............");
}
}