Author: Xiao Ming
Sometimes some data have a certain correspondence, but there is a lack of connection fields. It is necessary to manually find the matching data to establish a relationship. Here, I show several ideas of fuzzy matching to deal with different levels of data.
Of course, sort based fuzzy matching (similar to the fuzzy matching mode of Excel VLOOKUP function) also belongs to the category of fuzzy matching, but it is too simple and not the category discussed in this paper.
This paper mainly discusses the fuzzy matching of strings based on company name or address.
Fuzzy matching using edit distance algorithm
The basic idea of fuzzy matching is to calculate the similarity between each string and the target string, and take the string with the highest similarity as the fuzzy matching result with the target string.
For calculating the similarity between strings, the most common idea is to use the edit distance algorithm.
We have 28 names below. We need to find the most similar names from the database (390 data):
import pandas as pd
excel = pd.ExcelFile("All customers.xlsx")
data = excel.parse(0)
find = excel.parse(1)
display(data.head())
print(data.shape)
display(find.head())
print(find.shape)

Editing distance algorithm refers to the minimum number of editing operations required to convert one string to another between two strings. Allowed editing operations include replacing one character with another, inserting a character, and deleting a character.
Generally speaking, the smaller the editing distance, the less the number of operations, and the greater the similarity between the two strings.
Create a function to calculate the edit distance:
def minDistance(word1: str, word2: str):
'Edit distance calculation function'
n = len(word1)
m = len(word2)
# A string is empty
if n * m == 0:
return n + m
# DP array
D = [[0] * (m + 1) for _ in range(n + 1)]
# Boundary state initialization
for i in range(n + 1):
D[i][0] = i
for j in range(m + 1):
D[0][j] = j
# Calculate all DP values
for i in range(1, n + 1):
for j in range(1, m + 1):
left = D[i - 1][j] + 1
down = D[i][j - 1] + 1
left_down = D[i - 1][j - 1]
if word1[i - 1] != word2[j - 1]:
left_down += 1
D[i][j] = min(left, down, left_down)
return D[n][m]
For the analysis of the above code, please refer to the solution to the question of force buckle: https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
Traverse each searched name, calculate its editing distance from all customer names in the database, and take the customer name with the smallest editing distance:
result = []
for name in find.name.values:
a = data.user.apply(lambda user: minDistance(user, name))
user = data.user[a.argmin()]
result.append(user)
find["result"] = result
find
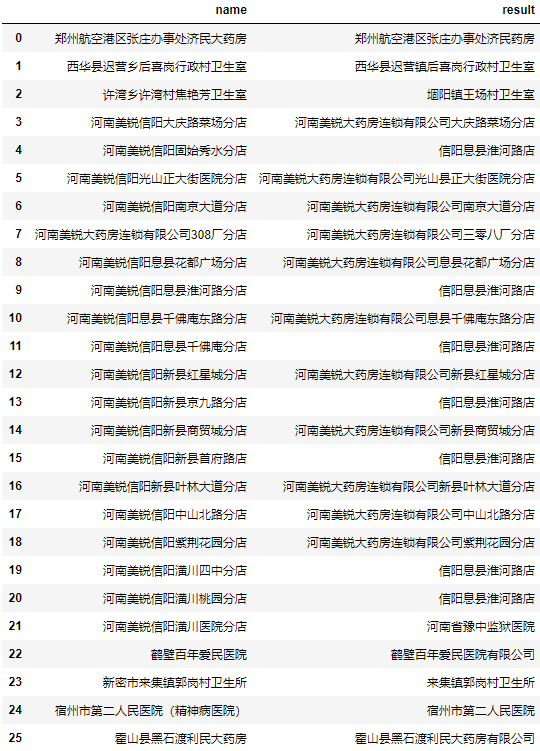
After the test, it is found that the effect of some addresses is poor.
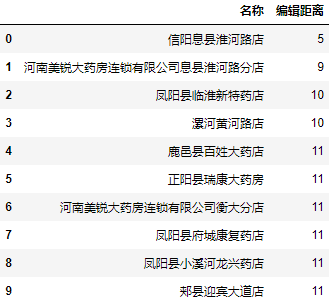
Let's take any two results as the address of Huaihe Road store in Xi county, Xinyang and look at the top 10 addresses with the smallest editing distance and editing distance:
a = data.user.apply(lambda user: minDistance(user, 'Henan Meirui Xinyang Xixian Huaihe Road Branch')) a = a.nsmallest(10).reset_index() a.columns = ["name", "Edit distance"] a.name = data.user[a.name].values a
a = data.user.apply(lambda user: minDistance(user, 'Henan Meirui Xinyang Huangchuan No. 4 middle school branch')) a = a.nsmallest(10).reset_index() a.columns = ["name", "Edit distance"] a.name = data.user[a.name].values a
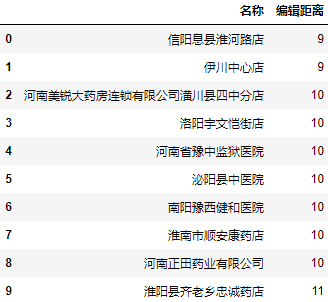
We can see that the results we want still exist in the names with the lowest editing distance in the first ten.
Batch fuzzy matching using fuzzy wuzzy
Through the above code, we have basically understood the basic principle of batch fuzzy matching through editing distance algorithm. However, it is complicated to write the code of editing distance algorithm by yourself, and it is troublesome to convert it into similarity analysis. If there are ready-made wheels, you don't have to write them by yourself.
The fuzzywuzzy library is developed based on the edit distance algorithm, and quantifying the value into the similarity score will be much better than the algorithm we wrote without targeted optimization. It can be installed through pip install FuzzyWuzzy.
The fuzzy wuzzy library mainly includes fuzzy module and process module. The fuzzy module is used to calculate the similarity between two strings, which is equivalent to encapsulating and optimizing the above code. The process module can directly extract the required results.
Fuzzy module
from fuzzywuzzy import fuzz
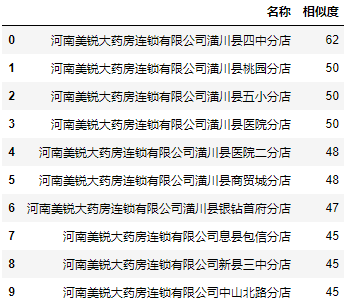
Simple match (Ratio):
a = data.user.apply(lambda user: fuzz.ratio(user, 'Henan Meirui Xinyang Huangchuan No. 4 middle school branch')) a = a.nlargest(10).reset_index() a.columns = ["name", "Similarity"] a.name = data.user[a.name].values a
Partial Ratio:
a = data.user.apply(lambda user: fuzz.partial_ratio(user, 'Henan Meirui Xinyang Huangchuan No. 4 middle school branch')) a = a.nlargest(10).reset_index() a.columns = ["name", "Similarity"] a.name = data.user[a.name].values a

Obviously, the ratio() function of the fuzzywuzzy library is much more accurate than the editing distance algorithm written by myself.
process module
The process module is further encapsulated, which can directly obtain the value and similarity with the highest similarity:
from fuzzywuzzy import process
extract extracts multiple pieces of data:
users = data.user.to_list()
a = process.extract('Henan Meirui Xinyang Huangchuan No. 4 middle school branch', users, limit=10)
a = pd.DataFrame(a, columns=["name", "Similarity"])
a
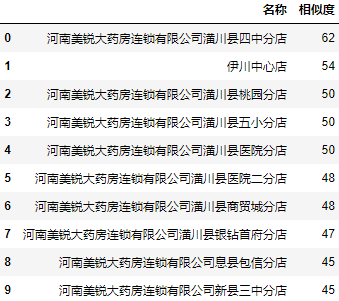
From the results, the process module seems to integrate the results of simple Ratio and Partial Ratio of fuzz y module at the same time.
When we only need to return one piece of data, it is more convenient to use extractOne:
users = data.user.to_list() find["result"] = find.name.apply(lambda x: process.extractOne(x, users)[0]) find
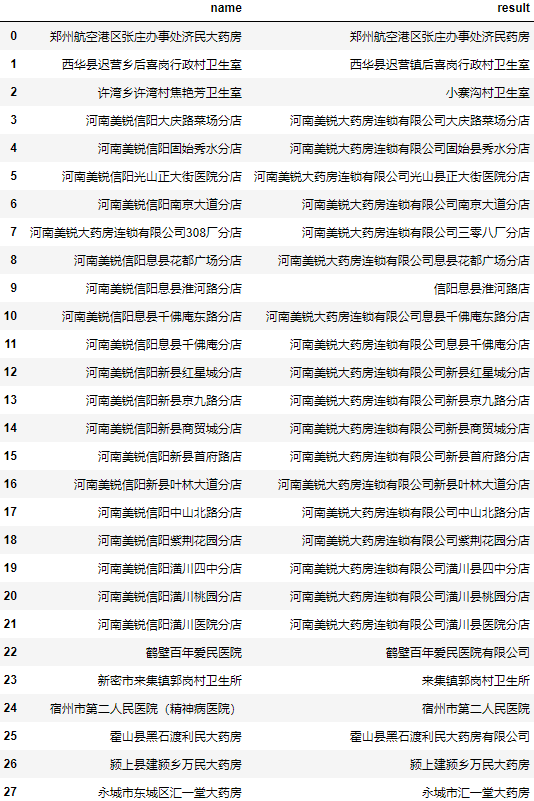
It can be seen that the accuracy has been greatly improved compared with the previous self written editing distance algorithm, but the matching results of individual names are still poor.
View these two addresses that do not match accurately:
process.extract('Jiao Yanfang clinic, xuwan village, xuwan Township', users)
[('Xiaozhaigou village clinic', 51),
('Zhoukou urban-rural integration Jiao Yanfang integrated clinic', 50),
('Louchen village clinic, Piying Township, Xihua county', 42),
('The second clinic of duyang village, Dengli Township, Ye County', 40),
('East clinic of Longhu village, Wagang Township, Tangyin County', 40)]
process.extract('Henan Meirui Xinyang Xixian Huaihe Road Branch', users)
[('Xinyang Xixian Huaihe Road store', 79),
('Henan Meirui pharmacy chain Co., Ltd. Xixian Huaihe Road Branch', 67),
('Henan Meirui pharmacy chain Co., Ltd. Xi county Dahe Wenjin branch', 53),
('Henan Meirui pharmacy chain Co., Ltd. Xixian qianfo'an East Road Branch', 51),
('Henan Meirui pharmacy chain Co., Ltd. Xixian Baoxin branch', 50)]
I don't have a perfect solution to this problem. I suggest adding the n names with the highest similarity to the result list, and then manually screening later:
result = find.name.apply(lambda x: next(zip(*process.extract(x, users, limit=3)))).apply(pd.Series)
result.rename(columns=lambda i: f"matching{i+1}", inplace=True)
result = pd.concat([find.drop(columns="result"), result], axis=1)
result
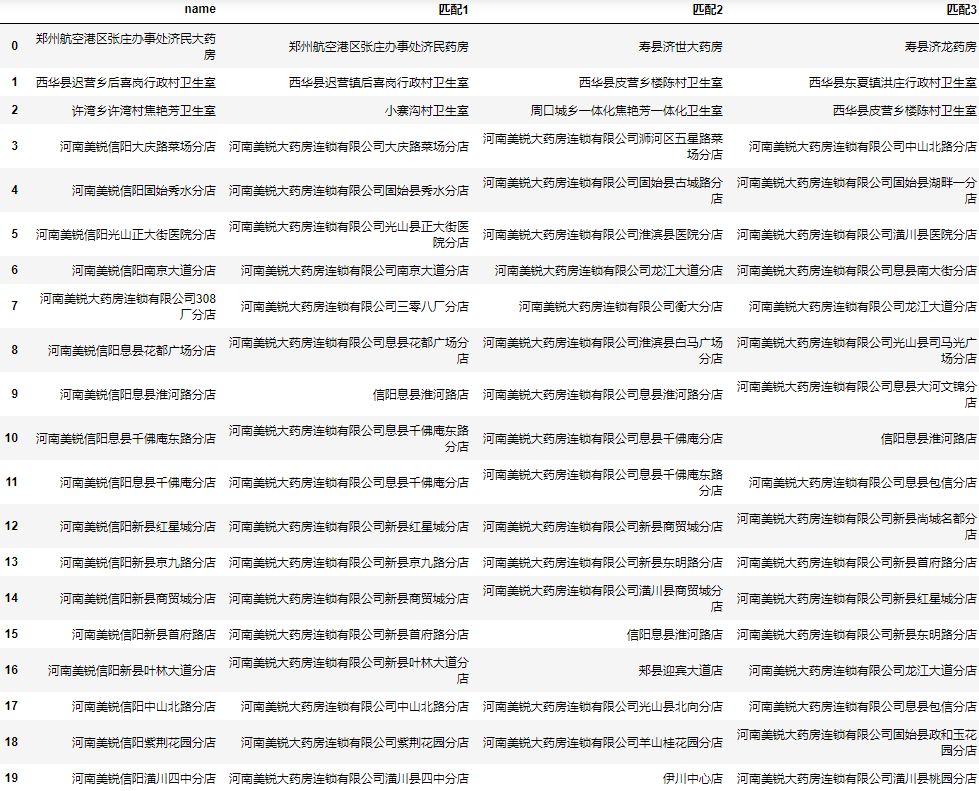
Although there may be individual correct results, none of these five are true, it saves a lot of time for manual screening as a whole.
Overall code
from fuzzywuzzy import process
import pandas as pd
excel = pd.ExcelFile("All customers.xlsx")
data = excel.parse(0)
find = excel.parse(1)
users = data.user.to_list()
result = find.name.apply(lambda x: next(
zip(*process.extract(x, users, limit=3)))).apply(pd.Series)
result.rename(columns=lambda i: f"matching{i+1}", inplace=True)
result = pd.concat([find, result], axis=1)
result
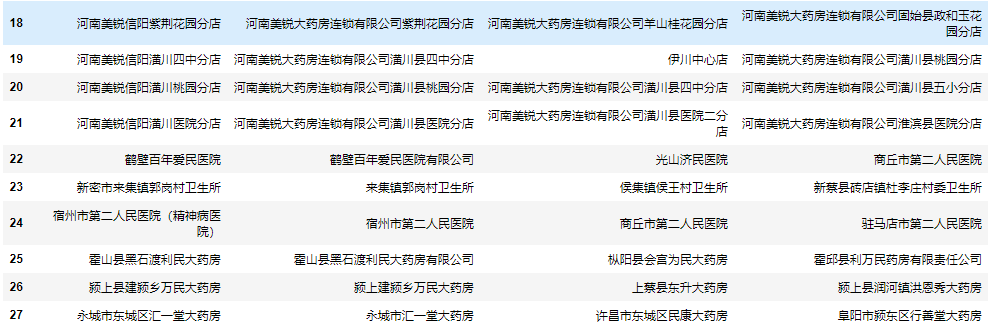
Batch fuzzy matching using Gensim
Gensim introduction
Gensim supports a variety of topic model algorithms including TF-IDF, LSA, LDA and word2vec, supports flow training, and provides API interfaces for some common tasks such as similarity calculation and information retrieval.
Basic concepts:
- Corpus: a set of original texts used to unsupervised train the hidden layer structure of text topics. Additional information that does not need manual annotation in the corpus. In Gensim, corpus is usually an iteratable object (such as a list). Each iteration returns a sparse vector that can be used to express text objects.
- Vector: a list of text features. Is the internal expression of a text in Gensim.
- Sparse vector: redundant 0 elements in the vector can be omitted. At this point, each element in the vector is a tuple of (key, value)
- Model: an abstract term. The transformation of two vector spaces is defined (that is, from one vector expression of text to another vector expression).
Installation: pip install gensim
Official website: https://radimrehurek.com/gensim/
Under what circumstances does NLP need to be used for batch fuzzy matching? That is, when the database data is too large, for example, it reaches tens of thousands of levels:
import pandas as pd
data = pd.read_csv("All customers.csv", encoding="gbk")
find = pd.read_csv("Found customers.csv", encoding="gbk")
display(data.head())
print(data.shape)
display(find.head())
print(find.shape)

At this time, if the editing distance or fuzzy wuzzy violence traversal is still used for calculation, it is estimated that the result cannot be calculated in 1 hour, but it only takes a few seconds to calculate the result using NLP artifact Gensim.
The word bag model is used for batch similarity matching directly
First, we need to segment the original text to get the feature list of each name:
import jieba data_split_word = data.user.apply(jieba.lcut) data_split_word.head(10)
0 [Zhuhai, Guangyao, Kang Ming, medicine, limited company] 1 [Shenzhen City, Bao'an District, Central Hospital] 2 [Zhongshan, torch, area for development, Bankang, Pharmacy] 3 [zhongshan , Tongfang, medicine, limited company] 4 [Guangzhou City, Tianhe District, Yuan Gangjin, Jianmin, medicine, store] 5 [Guangzhou City, Tianhe District, Yuan Gangju, Jiantang, Pharmacy] 6 [Guangzhou City, Tianhe District, Yuangang runbai, Pharmacy] 7 [Guangzhou City, Tianhe District, Yuangang, be of one mind, Pharmacy] 8 [Guangzhou City, Tianhe District, Yuangang, Xinyi, Pharmacy] 9 [Guangzhou City, Tianhe District, Yuangang Yongheng Hall, Pharmacy] Name: user, dtype: object
Next, the index Dictionary of corpus features is established, and the original expression of text features is transformed into the expression of sparse vector corresponding to word bag model:
from gensim import corpora dictionary = corpora.Dictionary(data_split_word.values) data_corpus = data_split_word.apply(dictionary.doc2bow) data_corpus.head()
0 [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)] 1 [(5, 1), (6, 1), (7, 1)] 2 [(8, 1), (9, 1), (10, 1), (11, 1), (12, 1)] 3 [(0, 1), (3, 1), (13, 1), (14, 1)] 4 [(0, 1), (15, 1), (16, 1), (17, 1), (18, 1), (... Name: user, dtype: object
In this way, we get the sparse vector corresponding to each name (here is the bow vector). Each element of the vector represents the number of times a word appears in the name.
At this point, we can build the similarity matrix:
from gensim import similarities index = similarities.SparseMatrixSimilarity(data_corpus.values, num_features=len(dictionary))
Then do the same processing for the searched name to carry out similarity batch matching:
find_corpus = find.name.apply(jieba.lcut).apply(dictionary.doc2bow) sim = index[find_corpus] find["result"] = data.user[sim.argmax(axis=1)].values find.head(30)
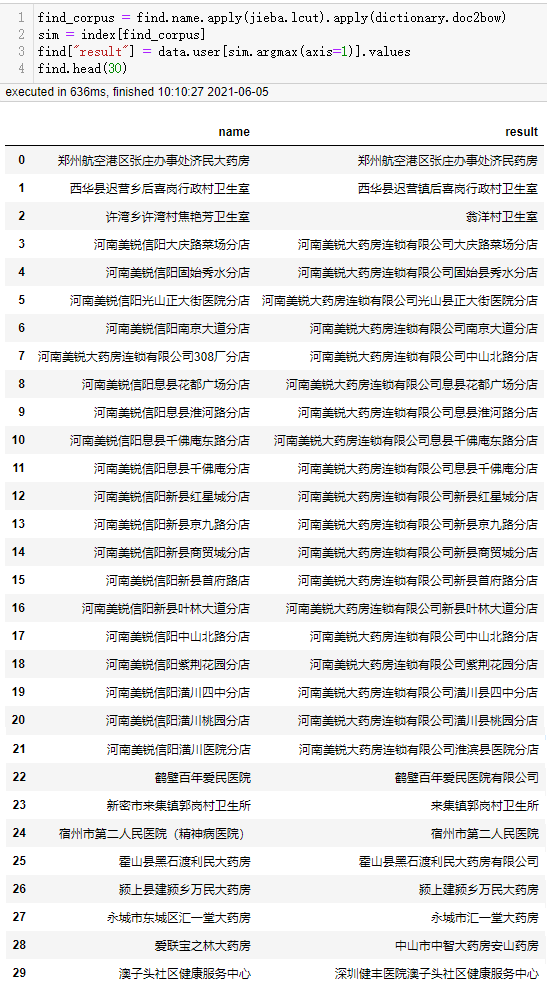
It can be seen that the calculation speed of the model is very fast, and the accuracy seems to be higher than that of fuzzy wuzzy on the whole, but the matching result of fuzzy wuzzy to the 308 branch of Henan Meirui pharmacy chain Co., Ltd. is correct.
The TF-IDF topic vector is used for batch similarity matching
The Corpus we used before was a sparse matrix of word frequency vector. Now we convert it into TF-IDF model and then build the similarity matrix:
from gensim import models
tfidf = models.TfidfModel(data_corpus.to_list())
index = similarities.SparseMatrixSimilarity(
tfidf[data_corpus], num_features=len(dictionary))
The searched name is also handled in the same way:
sim = index[tfidf[find_corpus]] find["result"] = data.user[sim.argmax(axis=1)].values find.head(30)

It can be seen that Jiao Yanfang's clinic in xuwan village, xuwan township is matched correctly, but the Huaihe Road branch in Xinyang County, Henan Meirui is matched incorrectly again. This is because Meirui has been reduced in many pieces of data in the TF-IDF model.
If only TF-IDF conversion is made to the database, and the searched name only uses word frequency vector, how about the matching effect?
from gensim import models
tfidf = models.TfidfModel(data_corpus.to_list())
index = similarities.SparseMatrixSimilarity(
tfidf[data_corpus], num_features=len(dictionary))
sim = index[find_corpus]
find["result"] = data.user[sim.argmax(axis=1)].values
find.head(30)

It can be seen that the matching of 308 branch of Henan Meirui pharmacy chain Co., Ltd. is incorrect, except that the database does not contain the correct name of ailianbao Zhilin pharmacy. This is because we can't recognize that the semantics of 308 is equal to 308. If there are many such data, we can convert the searched data from lowercase numbers to uppercase numbers (keep consistent with the database) before word segmentation:
trantab = str.maketrans("0123456789", "zero one two three four five six seven eight nine")
find_corpus = find.name.apply(lambda x: dictionary.doc2bow(jieba.lcut(x.translate(trantab))))
sim = index[find_corpus]
find["result"] = data.user[sim.argmax(axis=1)].values
find.head(30)
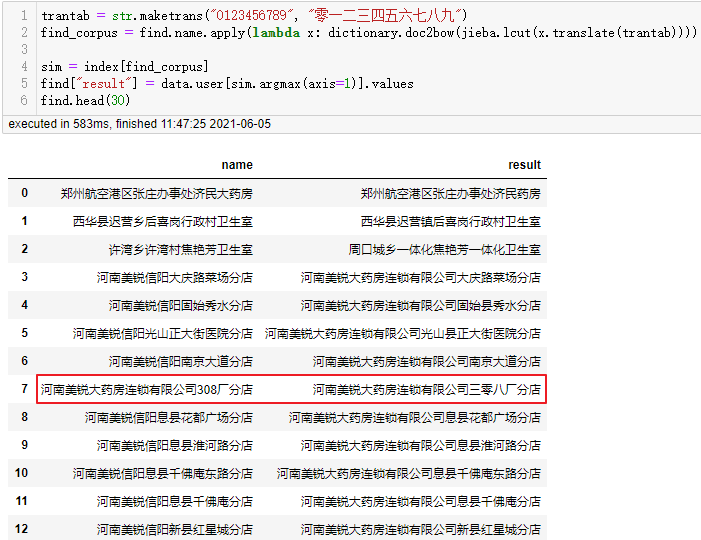
After this treatment, the branch of plant 308 has also been correctly matched, and other similar problems can be converted with this idea.
Although through the above processing, the matching accuracy rate is almost 100%, it does not mean that other types of data will have such a high accuracy rate, and the conversion needs to be analyzed according to the specific situation of the data. There is no perfect way to deal with batch fuzzy matching. For such problems, we can't fully trust the results of program matching. We need manual secondary inspection unless we can accept a certain error rate.
For the convenience of manual screening, we can save the first N data with the highest similarity to the results. Here we take three as examples:
Get the maximum 3 results at the same time
Next, we add the three values with the highest similarity to the results:
result = []
for corpus in find_corpus.values:
sim = pd.Series(index[corpus])
result.append(data.user[sim.nlargest(3).index].values)
result = pd.DataFrame(result)
result.rename(columns=lambda i: f"matching{i+1}", inplace=True)
result = pd.concat([find.drop(columns="result"), result], axis=1)
result.head(30)
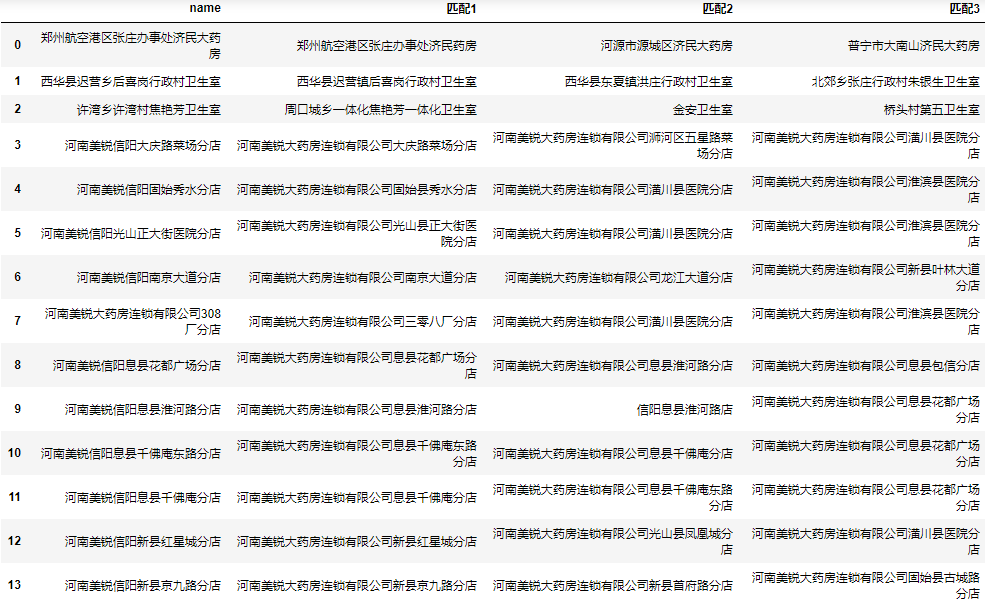
Complete code
from gensim import corpora, similarities, models
import jieba
import pandas as pd
data = pd.read_csv("All customers.csv", encoding="gbk")
find = pd.read_csv("Found customers.csv", encoding="gbk")
data_split_word = data.user.apply(jieba.lcut)
dictionary = corpora.Dictionary(data_split_word.values)
data_corpus = data_split_word.apply(dictionary.doc2bow)
trantab = str.maketrans("0123456789", "zero one two three four five six seven eight nine")
find_corpus = find.name.apply(
lambda x: dictionary.doc2bow(jieba.lcut(x.translate(trantab))))
tfidf = models.TfidfModel(data_corpus.to_list())
index = similarities.SparseMatrixSimilarity(
tfidf[data_corpus], num_features=len(dictionary))
result = []
for corpus in find_corpus.values:
sim = pd.Series(index[corpus])
result.append(data.user[sim.nlargest(3).index].values)
result = pd.DataFrame(result)
result.rename(columns=lambda i: f"matching{i+1}", inplace=True)
result = pd.concat([find, result], axis=1)
result.head(30)
summary
Firstly, this paper shares the concept of editing distance and how to use editing distance for similarity fuzzy matching. Then the wheel fuzzy based on this algorithm is introduced. It is well encapsulated and easy to use. However, when the database level reaches more than 10000, the efficiency is extremely reduced, especially when the data volume reaches more than 100000, it can't get results all day. Therefore, Gensim calculates the corresponding TF IDF vector after word segmentation to calculate the similarity. The calculation time is reduced from a few hours to a few seconds, and the accuracy has been greatly improved, which can deal with most batch similarity fuzzy matching problems.
I'm Xiao Ming. Please leave a comment below to express your views.