1, TICDC
In the previous article, we introduced how to use TICDC to synchronize data to Mysql. From the previous task, we can see that TICDC is much simpler in configuration than tidb binlog, and we also know that the performance of TICDC is also better than tidb binlog. Today, we learn how to use TICDC to synchronize data to downstream Kafka to realize TIDB to ES, MongoDB Synchronization of Redis and other NoSql databases.
Last blog address:
https://blog.csdn.net/qq_43692950/article/details/121731278
Note: to use TiCDC, you need to upgrade the TIDB version to above v4.0.6.
2, TICDC configuration data synchronization Kafka
This article continues with the previous article. Let's take a look at the current cluster status:
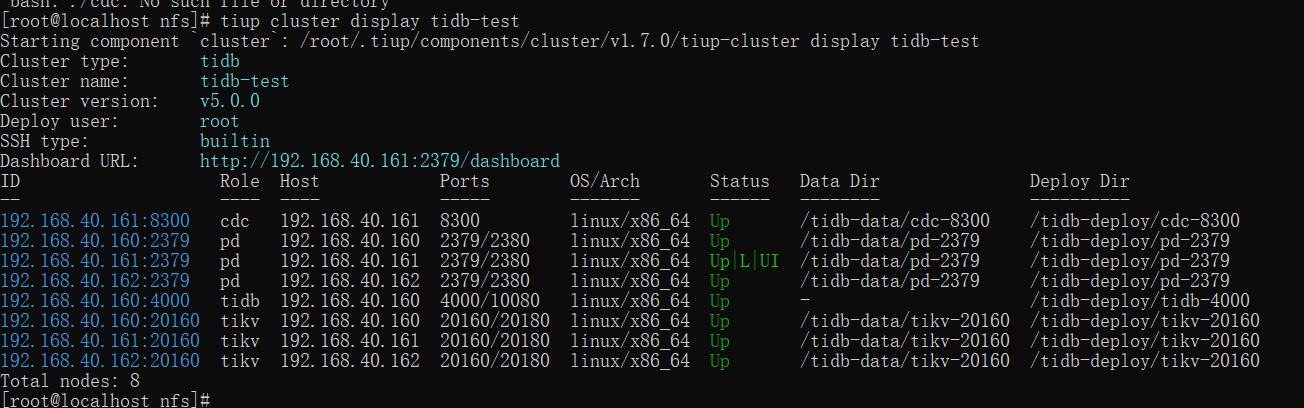
It is also the CDC server we expanded in the previous article.
In the previous article, we created the task of data synchronization from TIDB to mysql. Now we create another task of data synchronization to Kafka:
./cdc cli changefeed create --pd=http://192.168.40.160:2379 --sink-uri='kafka://192.168.40.1:9092/tidb-cdc?kafka-version=2.6.0&partition-num=1&max-message-bytes=67108864&replication-factor=1&protocol=canal-json' --changefeed-id="replication-task-2"
Tidb CDC: indicates topic
Kafka version: downstream Kafka version number (optional, the default value is 2.4.0, and the currently supported minimum version is 0.11.0.2)
Kafka client ID: Specifies the ID of the Kafka client of the synchronization task (optional. The default value is the ID of the TiCDC_sarama_producer_synchronization task)
Partition num: downstream Kafka partition quantity (optional), which cannot be greater than the actual partition quantity. If it is not filled in, the partition quantity will be obtained automatically.
Protocol: indicates the message protocol output to kafka. The optional values are default, canal, avro, maxwell, canal JSON (the default value is default)
Max message bytes: the maximum data amount of messages sent to Kafka broker each time (optional, the default value is 64MB)
Replication factor: the number of copies of kafka messages saved (optional, default 1)
CA: CA certificate file path required to connect downstream Kafka instances (optional)
cert: path to the certificate file required to connect the downstream Kafka instance (optional)
Key: the path of the certificate key file required to connect the downstream Kafka instance (optional)

Created successfully.
All tasks can be seen by using the following command:
./cdc cli changefeed list --pd=http://192.168.40.160:2379
Or view the details of our task:
./cdc cli changefeed query --pd=http://192.168.40.160:2379 --changefeed-id=replication-task-2
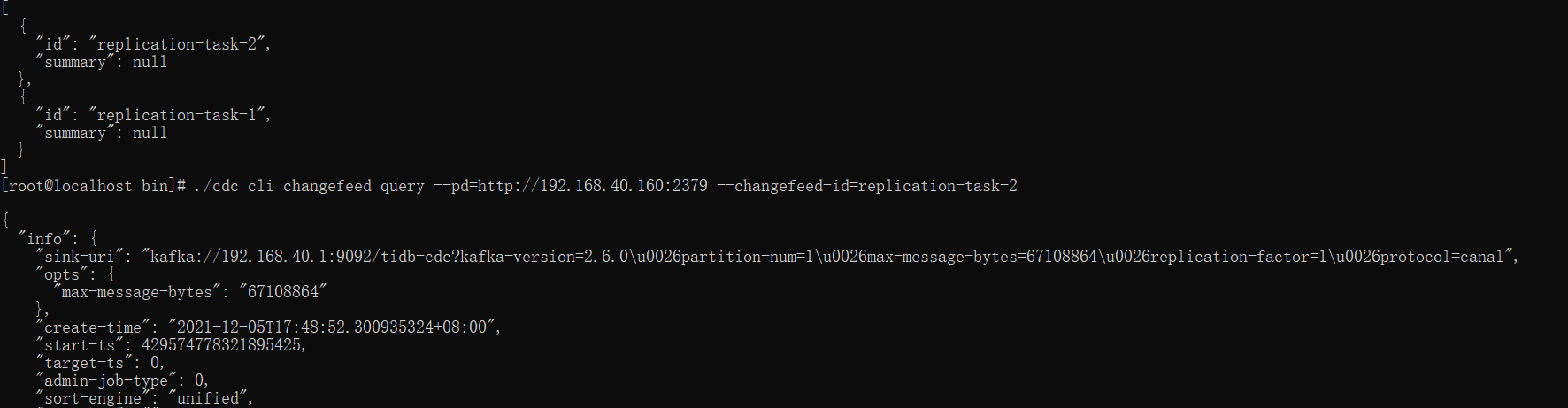
3, SpringBoot Kafka listening
Add POM dependency
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
application
server:
port: 8081
spring:
kafka:
# kafka server address (multiple)
# bootstrap-servers: 192.168.159.128:9092,192.168.159.129:9092,192.168.159.130:9092
bootstrap-servers: 192.168.40.1:9092
consumer:
# Specify a default group name
group-id: kafkaGroup
# Earlist: when there is a committed offset under each partition, the consumption starts from the submitted offset; when there is no committed offset, the consumption starts from the beginning
# latest: when there is a submitted offset under each partition, consumption starts from the submitted offset; when there is no submitted offset, consumption of the newly generated data under the partition
# none:topic when there is a committed offset in each partition, consumption starts after the offset; as long as there is no committed offset in one partition, an exception is thrown
auto-offset-reset: earliest
# Deserialization of key/value
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializer
# value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# Serialization of key/value
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# Batch fetching
batch-size: 65536
# Cache capacity
buffer-memory: 524288
#Failed retries
retries: 3
# server address
# bootstrap-servers: 192.168.159.128:9092,192.168.159.129:9092,192.168.159.130:9092
Consumer monitoring events
@Slf4j
@Component
public class Jms_Consumer {
@KafkaListener(topics = "tidb-cdc")
public void receive4(ConsumerRecord<?, ?> consumer) throws Exception {
System.out.println("tidb tidb-cdc Listener >> ");
JSONObject jsonObject = JSONObject.parseObject(new String(consumer.value()));
String type = jsonObject.getString("type");
String db = jsonObject.getString("database");
String table = jsonObject.getString("table");
String data = jsonObject.getString("data");
log.info("Operation type:{}",type);
log.info("Database:{}",db);
log.info("data sheet:{}",table);
log.info("Updated data:{}",data);
}
}
4, Test data synchronization
Insert data into TIDB:
insert into user(name,age) value('bxc','25');
kafka accept JSON
{
"id": 0,
"database": "testdb",
"table": "user",
"pkNames": ["id"],
"isDdl": false,
"type": "INSERT",
"es": 1638698748819,
"ts": 0,
"sql": "",
"sqlType": {
"age": -5,
"id": -5,
"name": 12
},
"mysqlType": {
"age": "int",
"id": "int",
"name": "varchar"
},
"data": [{
"age": "25",
"id": "242219",
"name": "bxc"
}],
"old": [null]
}

Update data:
update user set age=24 where name = 'bxc';
Kafka accepts JSON
{
"id": 0,
"database": "testdb",
"table": "user",
"pkNames": ["id"],
"isDdl": false,
"type": "UPDATE",
"es": 1638699660093,
"ts": 0,
"sql": "",
"sqlType": {
"age": -5,
"id": -5,
"name": 12
},
"mysqlType": {
"age": "int",
"id": "int",
"name": "varchar"
},
"data": [{
"age": "24",
"id": "242216",
"name": "bxc"
}],
"old": [{
"age": "23",
"id": "242216",
"name": "bxc"
}]
}

Delete data:
delete from user where name = 'bxc';
Kafka accepts JSON
{
"id": 0,
"database": "testdb",
"table": "user",
"pkNames": ["id"],
"isDdl": false,
"type": "DELETE",
"es": 1638699773943,
"ts": 0,
"sql": "",
"sqlType": {
"age": -5,
"id": -5,
"name": 12
},
"mysqlType": {
"age": "int",
"id": "int",
"name": "varchar"
},
"data": [{
"age": "25",
"id": "242218",
"name": "bxc"
}],
"old": [{
"age": "25",
"id": "242218",
"name": "bxc"
}]
}

5, Expand
Stop synchronization task:
./cdc cli changefeed pause --pd=http://192.168.40.160:2379 --changefeed-id replication-task-2
Delete synchronization task
./cdc cli changefeed remove --pd=http://192.168.40.160:2379 --changefeed-id replication-task-2

Love little buddy can pay attention to my personal WeChat official account and get more learning materials.