preface
I have been thinking about the complexity of dfs for a few days, but I don't understand it now.
The storage methods of graphs are chained forward stars or adjacency matrices. This paper mainly expounds the calculation method of dfs time complexity through several classic topics.
$n $is the number of nodes in the graph, $e $is the number of edges in the graph.
Depth first traverses every node of the graph
Time complexity: chained forward Star: $o \ left (n + e \ right) $; Adjacency matrix: $o \ left (n \ right)$
Given a graph (chained forward star storage), we traverse each node in the graph by depth first traversal.
First, each node in the graph can be traversed at most once. This is because when a node is traversed, it will be marked. When the node is searched again next time, it will not be searched from this node. Therefore, each node can call the dfs function at most once, so the time complexity is $o \ left (n \ right) $. The essence of ergodic graph is to traverse the adjacent nodes of each node, that is, when you start from one node to traverse other nodes, you should traverse the adjacent nodes of the node once. Therefore, for each node, the time complexity of traversing its adjacent nodes is $o \ left (e_{i} \ right) $, where $E_ {i} $refers to the number of edges connected between the $I $node and its adjacent nodes. Therefore, the time complexity of traversing the whole graph is to add up the time complexity of depth first traversal of each node, that is, $o \ left (n + e \ right) $, that is, the number of all nodes and edges.
If the graph is stored with adjacency matrix, the time complexity is $o \ left (n ^ {2} \ right) $. This is because each node has to scan its adjacent nodes, that is, traverse a row of the matrix, that is, $o \ left (n \ right) $. Because there are $n $nodes, the time complexity is $o \ left (n ^ {2} \ right) $.
Here is an example of depth first traversal.
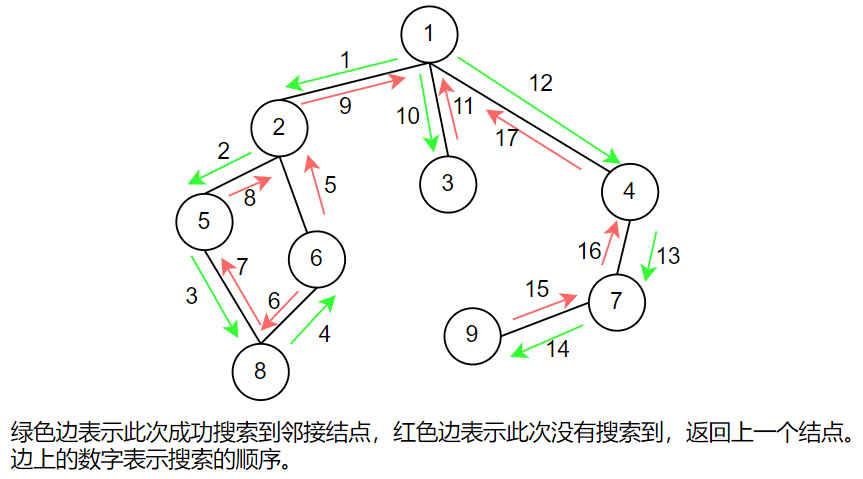
Depth first traversal Code:
1 #include <cstdio> 2 #include <cstring> 3 #include <algorithm> 4 using namespace std; 5 6 const int N = 1e5 + 10; 7 8 int head[N], e[N], ne[N], idx; 9 bool vis[N]; 10 11 void add(int v, int w) { 12 e[idx] = w, ne[idx] = head[v], head[v] = idx++; 13 } 14 15 void dfs(int src) { 16 vis[src] = true; 17 printf("%d ", src); 18 for (int i = head[src]; i != -1; i = ne[i]) { 19 if (!vis[e[i]]) dfs(e[i]); 20 } 21 } 22 23 int main() { 24 int n, m; 25 scanf("%d %d", &n, &m); 26 memset(head, -1, sizeof(head)); 27 28 // Input edge and create drawing 29 for (int i = 0; i < m; i++) { 30 int v, w; 31 scanf("%d %d", &v, &w); 32 add(v, w), add(v, w); 33 } 34 35 // Depth first traversal, search from node 1 36 dfs(1); 37 38 return 0; 39 }
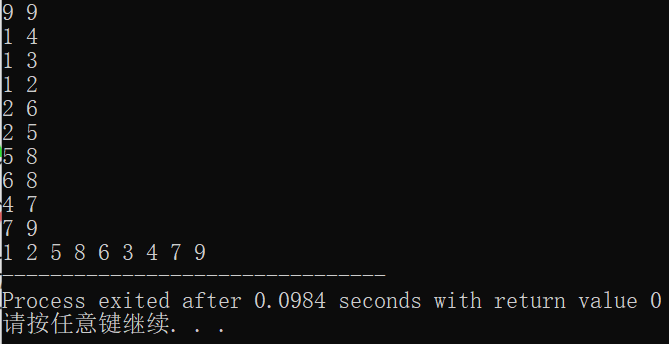
Taking the above figure as an example, the operation results are given here:
Digital permutation problem
The time complexity is $o \ left ({n \ cdot n!}) \right)$
Given a number $n $, find a total permutation of all $1 \sim n $.
For example, to find a complete arrangement of $3 $, here is a picture understanding (the line drawing part is drawn by hand, make do with it...).
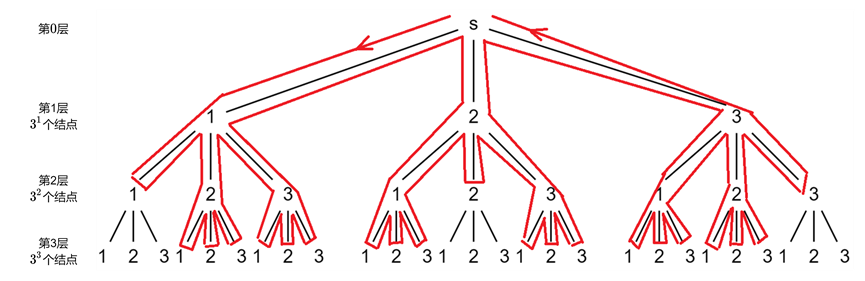
Starting from $s $, layer $1 $can select $3 $different nodes, and each node corresponds to a branch. Let's first look at the leftmost branch of $s $, that is, the branch corresponding to the number $1 $. Select the node "$1 $" in the $1 $layer, and then traverse $3 $adjacent nodes, corresponding to $3 $edges. Since $1 $has been traversed, it will only be traversed from "$2 $" and "$3 $", and these two nodes should traverse their adjacent nodes to determine which number to choose for the last number in the arrangement. The analysis of the nodes "$2 $" and "$3 $" in layer $1 $is the same as above.
It can be found that the number of adjacent nodes of each node is $3 $, so the loop needs to execute $3 $times to scan the $3 $adjacent nodes. And as the depth of the tree increases, the number of nodes that can be selected in each layer will also decrease. That is, for every $1 increase in depth, the number of nodes that can be selected in this layer will decrease by $1 $(because a number has been determined in the previous layer, there will be one fewer selection for each layer traversed).
So let's deduce a more general law, assuming a total permutation of $n $. The corresponding search tree looks like this:
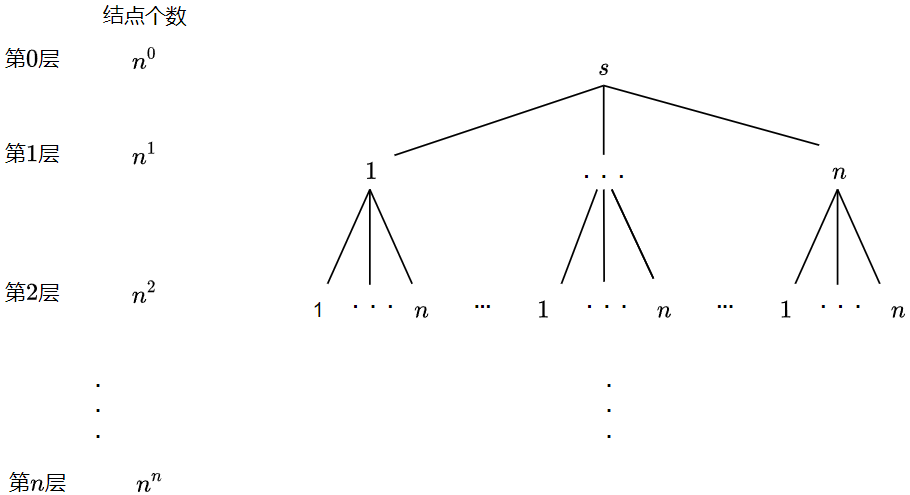
There are $n $nodes that can be selected in the $1 $layer. Then, for the $2 $layer, because the upper layer (the $1 $layer) has $n $selectable nodes, and although each node has $n $adjacent nodes, because a number has been determined in the upper layer, in fact, only $n - 1 $nodes can be selected in the next layer (the $2 $layer). Because there are $n $nodes in the upper layer, the number of nodes that can be selected in the $2 $layer is $n \ cdot \ left (n - 1 \ right) $(mainly to emphasize that although each adjacent node will be traversed, not all adjacent nodes can be selected for DFs in the next layer). Similarly, in the $3 $layer, the upper layer has $n \ cdot \ left (n - 1 \ right) $selectable nodes, and the actual selectable adjacent nodes of each node are only $n - 2 $, so the number of selectable nodes in the $3 $layer is $n \ cdot \ left (n - 1 \ right) \ cdot \ left (n - 2 \ right) $. By analogy, to the $n - 1 $layer, the number of nodes that can be selected is $n \ cdot \ left ({n - 1} \ right) \ cdot \ left ({n - 2} \ right) \ cdot ~ \ cdots ~ \ cdot 2 = n! $. The last layer is not considered, because the leaf node has no adjacent nodes, and the operation of traversing adjacent nodes will not be carried out.
Therefore, time complexity is the number of times that all selectable nodes traverse their adjacent nodes. Set the number of selectable nodes of layer $I $as $s_{i} $, each node has $n $adjacent nodes, so the number of times that all selectable nodes traverse its adjacent nodes is $$o \ left ({n \ cdot {\ sum \ limits {I = 0} ^ {n - 1} s {I}} = n \ cdot \ left ({1 + N + n \ cdot \ left ({n - 1} \ right) + \ cdots + n!} \right)} \right) = O\left( {n \cdot n!} \right)$$
Code of full permutation problem:
1 #include <cstdio> 2 #include <algorithm> 3 using namespace std; 4 5 const int N = 20; 6 7 int a[N]; 8 bool vis[N]; 9 10 void dfs(int u, int n) { 11 if (u == n) { 12 for (int i = 1; i <= n; i++) { 13 printf("%d ", a[i]); 14 } 15 printf("\n"); 16 17 return; 18 } 19 20 for (int i = 1; i <= n; i++) { 21 if (!vis[i]) { 22 vis[i] = true; 23 a[u + 1] = i; 24 dfs(u + 1, n); 25 vis[i] = false; 26 } 27 } 28 } 29 30 int main() { 31 int n; 32 scanf("%d", &n); 33 34 // Search from level 0 35 dfs(0, n); 36 37 return 0; 38 }
For example, find a full permutation of $4 $and the operation results are as follows:
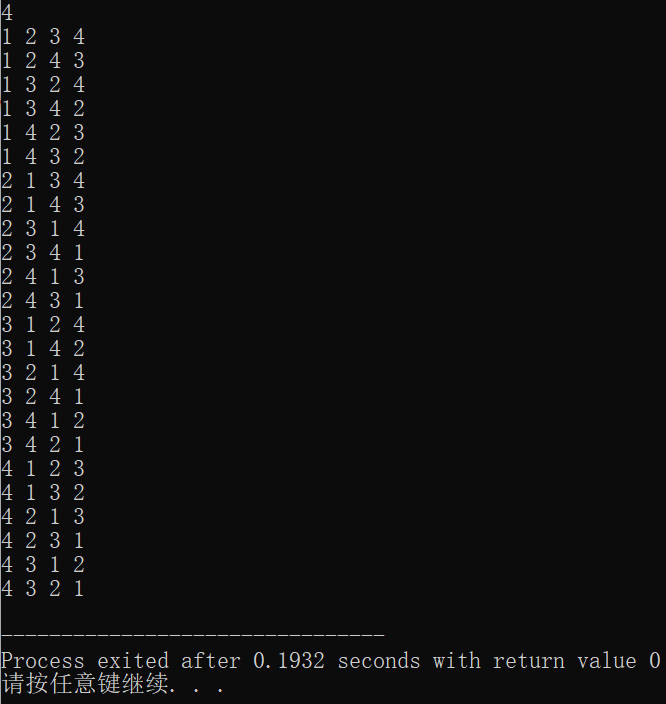
Due to the high time complexity, in order to calculate the result within $1s $, the value of $n $will not exceed $8 $.
n-queen problem
The $n $queen problem refers to placing $n $queens on the chess board of $n \times n $so that queens cannot attack each other, that is, any two queens cannot be in the same row, column or slash. Now, given the integer $n $, find all the pieces that meet the conditions.
Method 1
Time complexity is $o \ left (2 ^ {n ^ {2}} \ right)$
The purest dfs is to consider whether to put chess pieces in each grid or not.
First post the general appearance of the search tree:
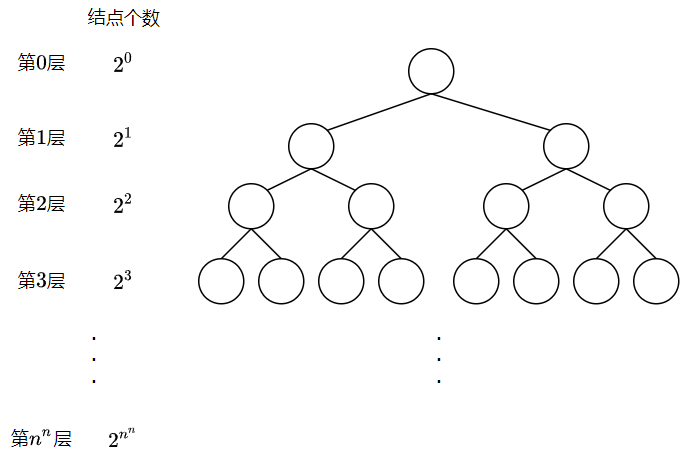
Because there are $n^{n} $grids, all search trees have $n^{n} $layers (excluding the $0 $layer), and each grid corresponds to the layer in the search tree. When the $n^{n} $layer is searched, it means that we choose to put or not put pieces for each grid, that is, we determine a scheme (the scheme does not necessarily meet the requirements of the solution). The node of each layer corresponds to the grid at this position. For example, the node of the $1 $layer corresponds to the $1 $grid, the node of the $n $layer corresponds to the $n $grid, and so on. Because each grid has two choices of putting or not putting chess pieces, each node has two adjacent nodes.
We now calculate the number of times to traverse the adjacent nodes of each node (regardless of pruning, which is the worst case). Because the nodes of the last layer, that is, $n^{n} $layer, are leaf nodes and have no adjacent nodes, only the nodes of $0 \sim n^{n} - 1 $layer are considered. Then, since each node has two adjacent nodes, let the $I $layer have $s_{i} $nodes, so the nodes of layer $I $will traverse $2 \ cdot s in total_ {i} $secondary adjacency node. Therefore, the number of times all nodes traverse adjacent nodes is $$o \ left ({2 \ cdot {\ sum \ limits {I = 0} ^ {n} - 1} {s {I}} = 2 \ cdot {\ sum \ limits {I = 0} ^ {n} - 1} ^ {I}} = 2 \ cdot \ frac{1 - 2 ^ {n}}} {1 - 2} = 2 \ cdot 2 ^ {n}} - 2} \ right) = O \ left (2 ^ {n ^ {2} \ right)$$
Of course, in fact, we will filter out the situation that there is no solution through pruning, and we will not continue to search from this place. The above analysis is the time complexity in the worst case, so the actual operation efficiency will be better than the time complexity analyzed above.
The code of method 1 of the $n $queen problem is as follows:
1 #include <cstdio> 2 #include <algorithm> 3 using namespace std; 4 5 const int N = 20; 6 7 char graph[N][N]; 8 bool row[N], col[N], dg[N], udg[N]; 9 10 void dfs(int x, int y, int cnt, int n) { 11 if (cnt == n) { 12 for (int i = 0; i < n; i++) { 13 printf("%s\n", graph[i]); 14 } 15 printf("\n"); 16 17 return; 18 } 19 20 if (y == n) { 21 y = 0, x++; 22 if (x == n) return; 23 } 24 25 dfs(x, y + 1, cnt, n); 26 27 if (!row[x] && !col[y] && !dg[y - x + n] && !udg[y + x]) { 28 row[x] = col[y] = dg[y - x + n] = udg[y + x] = true; 29 graph[x][y] = 'Q'; 30 dfs(x, y + 1, cnt + 1, n); 31 row[x] = col[y] = dg[y - x + n] = udg[y + x] = false; 32 graph[x][y] = '.'; 33 } 34 } 35 36 int main() { 37 int n; 38 scanf("%d", &n); 39 40 for (int i = 0; i < n; i++) { 41 for (int j = 0; j < n; j++) { 42 graph[i][j] = '.'; 43 } 44 } 45 46 // from(0, 0)The grid at this location starts the search 47 dfs(0, 0, 0, n); 48 49 return 0; 50 }
Here is the solution of $4 $Queens:
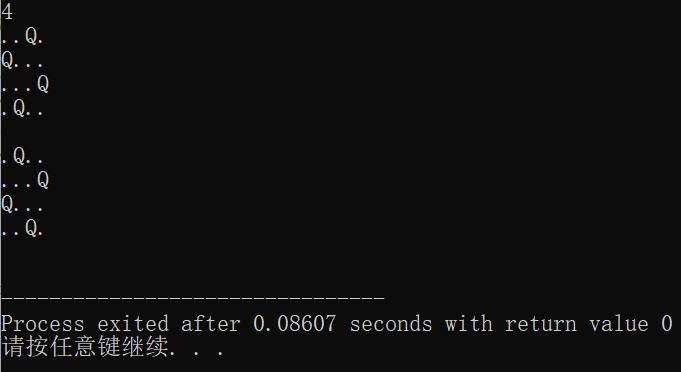
Due to the high time complexity, in order to calculate the result within $1s $, the value of $n $will not exceed $9 $.
Method 2
The time complexity is $o \ left ({n \ cdot n!}) \right)$
At this time, we need to further optimize the above method. We can find that according to the meaning of the title, there will only be one queen in each line, so we can enumerate each line. And each column has only one queen. Therefore, after selecting a queen in each row, record the column number of the queen. In the remaining rows, the queen of each row cannot be placed on the previously marked column number. In other words, after selecting one of the columns to place the queen in each enumerated row, the number of columns that can place the queen in the next row will be reduced by $1 $, that is, the position of the queen will be reduced by $1 $.
Is it similar to the previous full permutation analysis? We give a rough search tree:
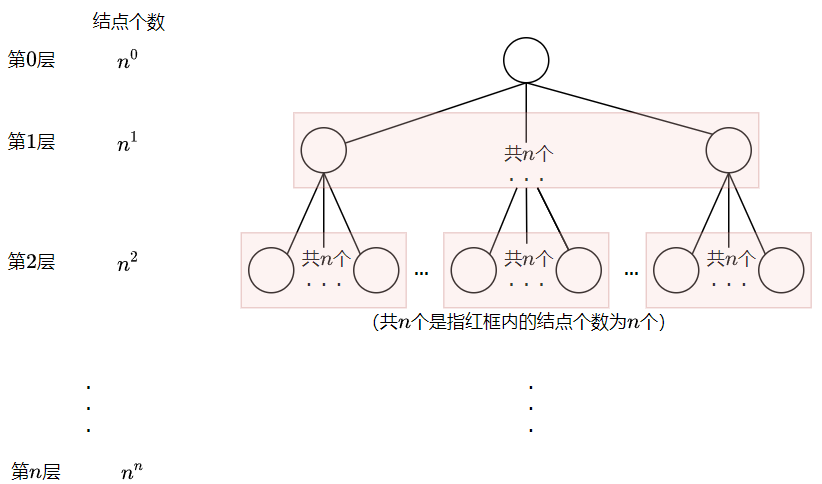
Yes, it is almost the same as the fully arranged search tree j above.
The $i $represents the $i $row of the chessboard. In the subtree with each node as the root, the $n $adjacent nodes of the root node represent $n $column numbers. According to the above analysis, each time you go down one layer, the number of selectable adjacent nodes will be reduced by one.
This is the same as the full permutation analysis, so the time complexity is $o \ left ({n \ cdot n!} \right)$.
The code of method 2 of the $n $queen problem is as follows:
1 #include <cstdio> 2 #include <algorithm> 3 using namespace std; 4 5 const int N = 20; 6 7 char graph[N][N]; 8 bool row[N], col[N], dg[N], udg[N]; 9 10 void dfs(int x, int n) { 11 if (x == n) { 12 for (int i = 0; i < n; i++) { 13 printf("%s\n", graph[i]); 14 } 15 printf("\n"); 16 17 return; 18 } 19 20 for (int i = 0; i < n; i++) { 21 if (!col[i] && !dg[i - x + n] && !udg[i + x]) { 22 col[i] = dg[i - x + n] = udg[i + x] = true; 23 graph[x][i] = 'Q'; 24 dfs(x + 1, n); 25 col[i] = dg[i - x + n] = udg[i + x] = false; 26 graph[x][i] = '.'; 27 } 28 } 29 } 30 31 int main() { 32 int n; 33 scanf("%d", &n); 34 35 for (int i = 0; i < n; i++) { 36 for (int j = 0; j < n; j++) { 37 graph[i][j] = '.'; 38 } 39 } 40 41 // Search from line 0 42 dfs(0, n); 43 44 return 0; 45 }
Compared with method 1, $n $value will increase. In order to calculate the result within $1s $, $n $can get $13 $.
Memory search
The time complexity is $o \ left (n \ right)$
Here is an example to analyze.
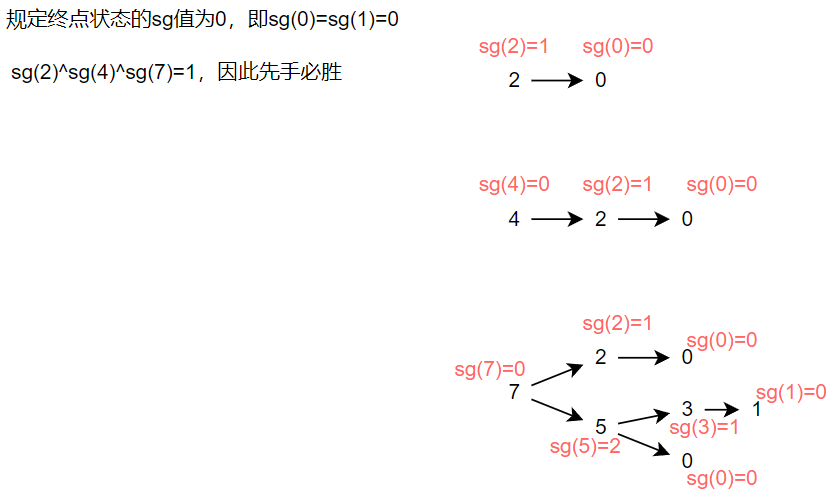
In the set Nim game, we need to find the sg value of each number, and a number may appear many times in the search process. Because the sg value of each number is the same in the same game, if we directly perform dfs to find the sg value of each number in the search process, it will repeat the search and waste time. Therefore, we can open an array to record the sg value of a number obtained each time. If you find that the sg of a number has been obtained in the process of search, you can get the result directly from the array without dfs from this number.
In this way, the sg value of each number will only be searched once. If $n $different numbers appear in the game, the time complexity is $o \ left (n \ right) $.
In fact, it is very similar to the depth first traversal in this figure, that is, it does not allow the same number (node) to be traversed repeatedly to ensure that it is traversed at most once.
Based on the test example of the topic, we draw the graph for finding sg value:
The AC code of the title is as follows:
1 #include <cstdio> 2 #include <cstring> 3 #include <unordered_set> 4 #include <algorithm> 5 using namespace std; 6 7 const int N = 110, M = 1e4 + 10; 8 9 int n, m; 10 int s[N], sg[M]; 11 12 int getSG(int val) { 13 if (sg[val] != -1) return sg[val]; 14 15 unordered_set<int> st; 16 for (int i = 0; i < n; i++) { 17 if (val - s[i] >= 0) st.insert(getSG(val - s[i])); 18 } 19 20 for (int i = 0; ; i++) { 21 if (st.count(i) == 0) return sg[val] = i; 22 } 23 } 24 25 int main() { 26 memset(sg, -1, sizeof(sg)); 27 28 scanf("%d", &n); 29 for (int i = 0; i < n; i++) { 30 scanf("%d", s + i); 31 } 32 scanf("%d", &m); 33 34 int ret = 0; 35 while (m--) { 36 int val; 37 scanf("%d", &val); 38 ret ^= getSG(val); 39 } 40 41 printf("%s", ret ? "Yes" : "No"); 42 43 return 0; 44 }
reference material
Acwing: https://www.acwing.com/
Finally, today is February 1, 2022. I wish you a happy Spring Festival!