Tips for simplifying MySQL optimization
- catalogue
- Blogger introduction
- SQL statement execution order
- Set case insensitive
- User and permission management of MySql
- Index optimization
- Mysql index classification
- Index optimization
- Subquery optimization
- Sorting and grouping optimization
catalogue
Blogger introduction
Personal home page: Suzhou program white Individual communities: CSDN programs across the country Introduction to the author: member of China DBA Alliance (ACDU), administrator of CSDN program ape (yuan) gathering places all over the country. Currently engaged in industrial automation software development. Good at C#, Java, machine vision, underlying algorithms and other languages. The July software studio was established in 2019.
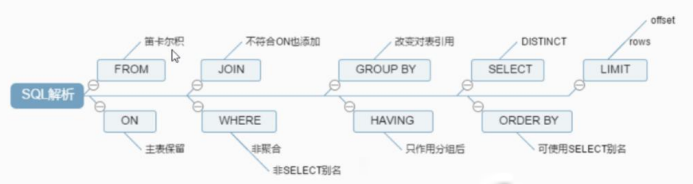
SQL statement execution order
Set case insensitive
- Check case sensitivity: Show variables like '% lower'_ case_ table_ names%'; Windows system is case insensitive by default, but linux system is case sensitive.
- Set case insensitive: in my CNF add lower to the configuration file [mysqld]_ case_ table_ Names = 1, then restart the server.
Property settings | describe |
|---|---|
0 | Case sensitive |
1 | Case insensitive. The created tables and databases are stored on the disk in lowercase. sql statements are converted to lowercase to find the tables and DB |
2 | The created tables and DB are stored according to the statement format, and all searches are converted to lowercase |
Note: before setting the attribute to case insensitive, you need to convert the original database and table to lowercase, otherwise the database name will not be found.
User and permission management of MySql
User management:
-- Create user
create user ahzoo identified by '123456';
-- View information about users and permissions
select host,user,password,select_priv,insert_priv,drop_priv from mysql.user
-- Modify current user password
set password =password('1234');
-- Change other user passwords
update mysql.user set password=password('123456') where user='ouo';
-- All pass user The following commands must be used for table operations to take effect
flush privileges;
-- Modify user name
update mysql.user set user='ahzoo' where user='ouo';
flush privileges;
-- delete user
drop user ouo;
-- Note: when deleting a user, it is not recommended to use the following command to delete it, because the system will retain residual information
delete from user where user='ouo'
flush privileges;Permission management:
Grant permissions
grant Authority 1,Authority 2,...jurisdiction n on Database name.Table name to user name@User address identified by 'password'; -- Grant all tables and permissions under the database grant all privileges on testDB.* to ahzoo@localhost identified by '123456'; -- Grant permission to add, delete, modify and query all databases and tables grant select,insert,delete,drop on *.* to ahzoo@localhost identified by '123456'; -- Authorize network users;@'%' Indicates authorization to non local host users, excluding localhost grant all privileges on *.* to ouo@'%' identified by '123456' -- View permissions show grants;
Cancel permission
revoke [Authority 1,Authority 2,...jurisdiction n] on Library name.Table name from user name@User address; revoke all privileges on testDB.* from ahzoo@localhost;
Index optimization
In addition to data, the database system also maintains data structures that meet specific search algorithms. These data structures reference (point to) data in some way, so that advanced search algorithms can be implemented on these data structures. This data structure is index. The following figure is an example of a possible index method:
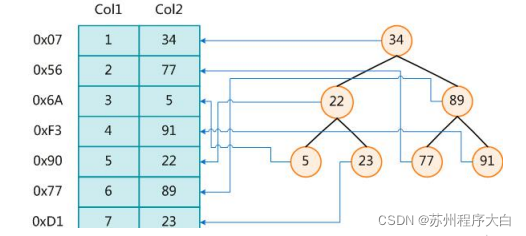
On the left is the data table, which has two columns and seven records. On the far left is the physical address of the data record. In order to speed up the search of Col2, a binary search tree shown on the right can be maintained. Each node contains an index key value and a pointer to the physical address of the corresponding data record, so that the binary search can be used to obtain the corresponding data within a certain complexity, so as to quickly retrieve the qualified records. Generally speaking, the index itself is also large, and it is impossible to store it all in memory. Therefore, the index is often stored on the disk in the form of index file.
Index advantages:
- Improve the efficiency of data retrieval and reduce the IO cost of database.
- Sorting data by index column reduces the cost of data sorting and CPU consumption.
Index disadvantages:
- Although the index greatly improves the query speed, it will reduce the speed of updating the table, such as INSERT, UPDATE and DELETE. When updating a table, MySQL should not only save the data, but also save the index file. Every time the field with index column is updated, the index information after the key value changes caused by the UPDATE will be adjusted.
- In fact, the index is also a table, which saves the primary key and index fields and points to the records of the entity table, so the index column also takes up space.
MySQL index
Btree
MySQL uses Btree index:
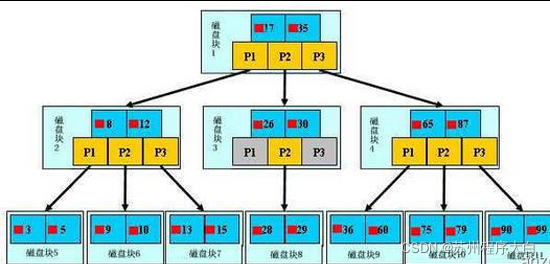
A b-tree, light blue block, we call it a disk block. You can see that each disk block contains several data items (shown in dark blue) and pointers (shown in yellow). For example, disk block 1 contains data items 17 and 35, including pointers P1, P2 and P3. P1 represents a disk block less than 17, P2 represents a disk block between 17 and 35, and P3 represents a disk block greater than 35.
Real data exists in leaf nodes, i.e. 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90 and 99.
Non leaf nodes only store real data, and only store data items that guide the search direction. For example, 17 and 35 do not really exist in the data table.
Discovery process:
If you want to find the data item 29, first load the disk block 1 from the disk into the memory. At this time, an IO occurs. Use the binary search in the memory to determine that the 29 is between 17 and 35, and lock the P2 pointer of disk block 1, Memory time is very short (compared with disk IO), it is negligible. Load disk block 3 from disk to memory through the disk address of P2 pointer of disk block 1, and the second IO occurs. 29 is between 26 and 30. Lock the P2 pointer of disk block 3, load disk block 8 to memory through the pointer, and the third IO occurs. At the same time, do binary search in memory, find 29, and end the query. There are three IOS in total .
The real situation is that the three-tier b + tree can represent millions of data. If millions of data searches only need three IO, the performance improvement will be huge. If there is no index and each data item needs one IO, a total of millions of IO are required. Obviously, the cost is very high.
B+tree

Difference between B+Tree and B-Tree:
1. The keywords and records of B-tree are put together, and the leaf node can be regarded as an external node without any information; In the non leaf node of the B + tree, there are only keywords and indexes pointing to the next node, and records are only placed in the leaf node.
2. In the B-tree, the closer to the root node, the faster the search time of the record. As long as the keyword is found, the existence of the record can be determined; The search time of each record in the B + tree is basically the same. You need to go from the root node to the leaf node, and you need to compare keywords in the leaf node. From this point of view, the performance of B-tree seems to be better than that of B + tree, but in practical application, the performance of B + tree is better. Because the non leaf nodes of the B + tree do not store actual data, each node can accommodate more elements than the B-tree and the tree height is smaller than the B-tree. This brings the advantage of reducing the number of disk accesses. Although the B + tree needs more comparisons to find a record than the B-tree, the time of a disk access is equivalent to hundreds of memory comparisons. Therefore, in practice, the performance of the B + tree may be better, and the leaf nodes of the B + tree are connected together by pointers, It is convenient for sequential traversal (such as viewing all files in a directory, all records in a table, etc.), which is also why many databases and file systems use B + trees.
Why is B + tree more suitable for file index and database index of operating system in practical application than B-tree
- The disk read and write cost of B + tree is lower
The internal node of the B + tree does not have a pointer to the specific information of the keyword. Therefore, its internal nodes are smaller than B-tree. If all the keywords of the same internal node are stored in the same disk block, the disk block can hold more keywords. The more keywords you need to find read into memory at one time. Relatively speaking, the number of IO reads and writes is reduced.
- The query efficiency of B + tree is more stable
Because the non endpoint is not the node that finally points to the file content, but the index of keywords in the leaf node. Therefore, the search of any keyword must go from the root node to the leaf node. The path length of all keyword queries is the same, resulting in the same query efficiency of each data.
Clustered index and non clustered index
Cluster index is not a single index type, but a way of data storage. The term 'cluster' means that data rows and adjacent key values are stored together. As shown in the following figure, the index on the left is a clustered index, because the arrangement of data rows on the disk is consistent with the index sorting.
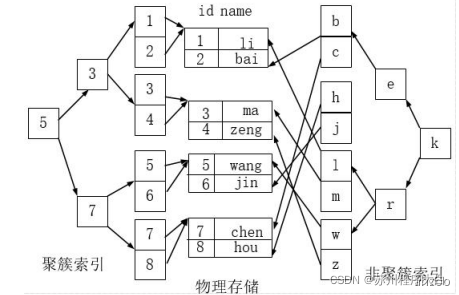
- Benefits of clustered indexing:
According to the order of cluster index, when querying and displaying a certain range of data, because the data are closely connected, the database does not need to extract data from multiple data blocks, so a lot of io operations are saved.
- Restrictions on clustered indexes:
For MySQL database, only innodb data engine supports cluster index, while Myisam does not support cluster index. Because there can only be one sorting method for data physical storage, each MySQL table can only have one clustered index. Generally, it is the primary key of the table. In order to make full use of the clustering characteristics of cluster index, the primary key column of innodb table should use ordered id instead of unordered id, such as uuid
Mysql index classification
-- establish CREATE [UNIQUE] INDEX [indexName] ON table_name(column)) -- delete DROP INDEX [indexName] ON tableName; -- see SHOW INDEX FROM tableName; -- use Alter command: -- This statement adds a primary key, which means that the index value must be unique and cannot be null NULL: ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) -- Add a normal index, and the index value can appear multiple times: ALTER TABLE tbl_name ADD INDEX index_name (column_list) --The statement specifies that the index is FULLTEXT ,For full-text indexing: ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)
Single valued index
That is, an index contains only a single column, and a table can have multiple single column indexes.
-- Create indexes directly when creating tables CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); -- Create index separately: CREATE INDEX idx_customer_name ON customer(customer_name);
unique index
Index column values must be unique, but null values are allowed.
-- Create with table: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); -- Create a unique index separately: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no
primary key
When set as the primary key, the database will automatically establish an index, and innodb is a clustered index.
-- Create with table CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); -- Create a separate primary key index: ALTER TABLE customer add PRIMARY KEY customer(customer_no) -- Delete primary key index: ALTER TABLE customer drop PRIMARY
Composite index
That is, an index contains multiple columns.
-- Index with table: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); -- Index separately: CREATE INDEX idx_no_name ON customer(customer_no,customer_name);
Index optimization
- Optimal left prefix rule
When using a composite index, it is necessary to follow the leftmost prefix rule (the query starts from the leftmost front row of the index and does not skip the columns in the index). That is, the filter conditions must be met in turn according to the order in which the index is established. Once a field is skipped, the words behind the index cannot be used.
- Do not do any calculations on index columns
When [calculation, function, (automatic / manual) type conversion] is performed on the index column, the index will become invalid and turn to full table scanning.
- Cannot have range query on index column
When executing the mysql command, you should put the index order of the fields that may be queried in the range last.
- Use overlay indexes whenever possible
Overlay index: SQL can return the data required for query only through the index, instead of querying the data after finding the primary key through the secondary index. That is, when querying columns and index columns, do not use select *... But select a,b,c.
1. When not equal to (! = or < >), sometimes the index cannot be used, resulting in full table scanning.
2. The is null of the field can use the index, while is not null will not use the index.
3. Prefix cannot be used for fuzzy matching:
... like '%a%' √... like '%a' √... like 'a%' ×
Use union all or union instead of or example:
Suppose abc is the index
-- Index used: where a = 3; where a = 3 and b = 5; where a = 3 and b = 5 and c = 4; -- Index not used: where a <> 3; where abs(a) =3; where b = 3; where b = 3 and c = 4; where c = 4; -- Use to a Index, but not used b,c Indexes where a = 3 and c = 5; where a = 3 and b > 4 and c = 5; where a is null and b is not null;
Subquery optimization
When judging the range, try not to use not in and not exists, and use left join on xxx i.
Sorting and grouping optimization
- No filtering, no indexing
where and limt are equivalent to filtering conditions, so the upper index can be used.
- If the order is wrong, it must be sorted
The order of columns on both sides of where can be changed with the same effect, but the order by column cannot be changed arbitrarily.
- In the opposite direction, sorting is required
If the fields that can be indexed are in positive or reverse order, it will have no effect, just changing the order of the result set.
-- Both sorting methods are desc: select * from mytest where name='ahzoo' order by deptid desc, name desc
If the order of the sorted fields is different, you need to reverse the order of the different parts once, so you still need to sort manually.
-- The two sorting methods are opposite, one is in descending order and the other is in ascending order select * from mytest where name='ahzoo' order by deptid desc, name asc