Reference link: https://blog.csdn.net/qyhaill/article/details/103043637
Call example:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
initial_lr = 5
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1),verbose = True)
print("Initialized learning rate:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
optimizer_1.zero_grad()
optimizer_1.step()
print("The first%d individual epoch Learning rate:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
method:
1.torch.optim.lr_scheduler.LambdaLR
The initial learning rate is multiplied by the coefficient. Since each multiplication coefficient is multiplied by the initial learning rate, the coefficient is often a function of epoch.
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
Calculation formula:
lr_lambda = f(epoch) new_lr = lr_lambda * init_lr
Parameters:
- optimizer (Optimizer) – the optimizer that needs to be optimized
- lr_lambda: mathematical functions about epoch, or a list of such functions, such as lambda: epoch*2. In each epoch.
- last_epoch: the index of the last epoch. The default value is - 1.
- verbose: if set to True, print new for each epoch_ lr.
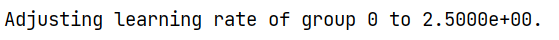
example:
lambda1 = lambda epoch: 0.95 ** epoch scheduler = LambdaLR(optimizer, lr_lambda=lambda1, verbose = True) for epoch in range(100): train(...) validate(...) scheduler.step()
2.torch.optim.lr_scheduler.MultiplicativeLR
Unlike LambdaLR, this method multiplies the previous learning rate by lr_lambda, so usually lr_lambda functions do not need to be associated with epoch.
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
Calculation formula:
new_lr = lr_lambda*old_lr
- Optimizer: the optimizer that needs to be optimized
- lr_lambda: multiplier, function, or list of such functions.
- last_epoch: the index of the last epoch. The default value is - 1.
- verbose: if set to True, print new for each epoch_ lr.
example:
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
3.torch.optim.lr_scheduler.StepLR
Every step_size an epoch and make an update
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
Calculation formula:
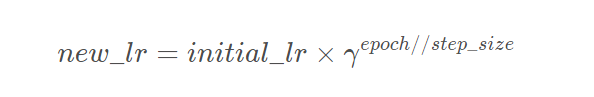
- Optimizer: the optimizer to optimize
- step_size: every training step_size epoch s, update parameters once
- gamma: update the multiplication factor of lr
example:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
4.torch.optim.lr_scheduler.MultiStepLR
Different from the method of specifying how many epochs to go through, this method is used to update when a specific epoch is encountered, that is, update every epoch in the milestones
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
- Optimizer: the optimizer to optimize
- milestones: the index list of epoch, in which the elements must be incremented.
- gamma: update the multiplier factor of lr
example:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
5.torch.optim.lr_scheduler.ConstantLR
Attenuate the learning rate of each parameter group by a small constant factor until the number of epoch s reaches the predefined milestone. This attenuation may occur simultaneously with other changes to the learning rate outside this scheduler.
torch.optim.lr_scheduler.ConstantLR(Optimizer, factor= 0.3333333333333333,total_iters = 5,last_epoch = - 1,detailed= False)
Formula:
[base_lr * (self.factor + (self.last_epoch >= self.total_iters) * (1 - self.factor))
- Factor: multiplier factor, multiplied by the learning rate until the epoch of milestone
- total_iter: the number of steps in which the scheduler attenuates the learning rate, that is, when the iter is reached, the learning rate changes.
example:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.025 if epoch == 0
# lr = 0.025 if epoch == 1
# lr = 0.025 if epoch == 2
# lr = 0.025 if epoch == 3
# lr = 0.05 if epoch >= 4
scheduler = ConstantLR(self.opt, factor=0.5, total_iters=4)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
6.torch.optim.lr_scheduler.LinearLR
The learning rate of each parameter group is attenuated by linearly changing the small multiplication factor until the number of epoch s reaches the predefined milestone
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3333333333333333, end_factor=1.0, total_iters=5, last_epoch=- 1, verbose=False)
Formula:
base_lr * (self.start_factor + (self.end_factor - self.start_factor) * min(self.total_iters, self.last_epoch) / self.total_iters
- start_factor: the number multiplied by the learning rate in the first epoch. In the following period, the multiplication factor increases to end_factor changes.
- end_factor: the number multiplied by the learning rate at the end of the linear change process.
- total_iters: the number of iterations when the multiplication factor reaches 1.
Example: (the official website feels that the output is wrong)
>>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.025 if epoch == 0 >>> # lr = 0.03125 if epoch == 1 >>> # lr = 0.0375 if epoch == 2 >>> # lr = 0.04375 if epoch == 3 >>> # lr = 0.005 if epoch >= 4 >>> scheduler = LinearLR(self.opt, start_factor=0.5, total_iters=4) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
7.torch.optim.lr_scheduler.ExponentialLR
Similar to multiplicative LR, but this uses the multiplier factor directly
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)