Tornado is widely used in Zhihu. When you open the web version of Zhihu with Chrome and use the developer tool to carefully observe the requests in the Network, you will find that there is a special request with a status code of 101. It uses the browser's websocket technology to establish a long connection with the back-end server to receive the notification messages actively pushed by the server. The backend server here uses the tornado server. Apart from providing websocket services, tornado server can also provide long connection services, HTTP short link services, UDP services, etc. Tornado server is open source by facebook and is widely used in the back end of handheld reading.
How to use such a powerful tornado framework? This article will lead readers to gradually and deeply learn how to use tornado as the basis of web server.
Hello, World
This is the official Hello, world instance, which executes Python hello Py, open the browser to access http://localhost:8888/ You can see the normal output of the server Hello, world.
An ordinary tornado web server usually consists of four components.
- The ioloop instance, which is a global tornado event loop, is the core engine of the server. In the example, tornado ioloop. IOLoop. Current () is the default tornado ioloop instance.
- App instance, which represents a completed back-end app. It will be connected to a server socket port to provide services. There can be multiple app instances in an ioloop instance. There is only one app instance in the example. In fact, multiple app instances can be allowed, but they are rarely used.
- handler class, which represents business logic. When we develop the server, we write a pile of handlers to serve client requests.
- Routing table, which connects the specified url rule with the handler to form a routing mapping table. When the request arrives, query the routing mapping table according to the requested access url to find the corresponding service handler.
The relationship between these four components is that an ioloop contains multiple apps (managing multiple service ports), an app contains a routing table, and a routing table contains multiple handlers. Ioloop is the core of the service engine. It is the engine, which is responsible for receiving and responding to client requests, driving the operation of business handlers, and executing scheduled tasks within the server.
When a request arrives, ioloop reads the request and unpacks it into an http request object, finds the routing table of the corresponding app on the socket, queries the handler attached in the routing table through the url of the request object, and then executes the handler. After the handler method is executed, it will generally return an object. Ioloop is responsible for packaging the object into an http response object and serializing it to the client.
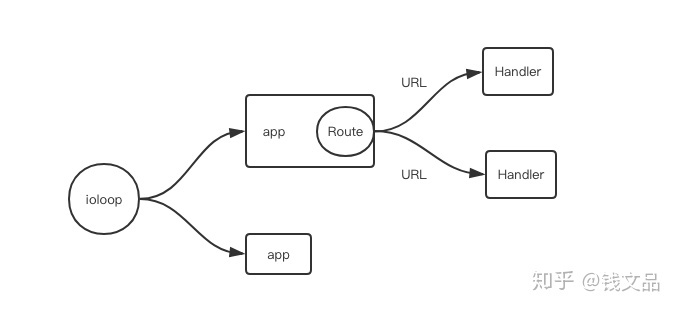
The same ioloop instance runs in a single threaded environment.
Factorial service
Let's write a normal web server that will provide factorial services. That is to help us calculate n! Value of. The server will provide factorial cache, and the calculated ones will be saved. There is no need to recalculate next time. The advantage of using Python is that we don't have to be careful that the calculation result of factorial will overflow. Python integers can be infinite.
Execute Python fact Py, open the browser and type http://localhost:8888/fact?n=50 , you can see the browser output
6082818640342675608722521633212953768875528313792102400000000. If we do not provide the n parameter, visit http://localhost:8888/fact , you can see that the browser outputs 400: Bad Request, which tells you that the request is wrong, that is, one parameter is missing.
Using Redis
--
The above example is to store the cache in the local memory. If you change a port and a factorial service to access it through this new port, it needs to be recalculated for each n, because the local memory cannot be shared across processes and machines.
Therefore, in this example, we will use Redis to cache the calculation results, so as to completely avoid repeated calculation. In addition, instead of returning plain text, we will return a json, and add a field name in the response to say whether this calculation comes from the cache or the fact. In addition, we provide default parameters. If the client does not provide N, it defaults to n=1.
When we visit again http://localhost:8888/fact?n=50 , you can see the browser output as follows
{"cached": false, "fact": 608281864034267560872252163321295376887552831379210240000000000, "n": 50}
, refresh again. The browser outputs {"cached": true, "fact": 6082818640342675608722521633212953768875528313792102400000000, "n": 50}. You can see that the cached field is programmed from true to false, indicating that the cache has indeed saved the calculation results. Let's restart the process,
Visit the connection again and observe the browser output. You can find that the cached result is still equal to true. This indicates that the cache result is no longer stored in local memory.
PI calculation service
--
Next, we will add a service to calculate the PI. There are many formulas for calculating the PI. We use it as the simplest one.
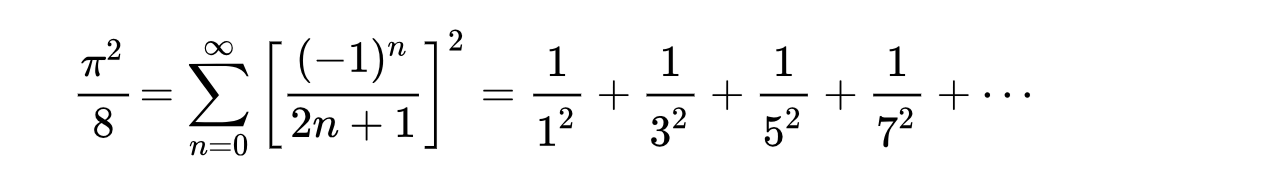
We provide a parameter n in the service as the accuracy index of PI. The larger n is, the more accurate the PI calculation is. Similarly, we also cache the calculation results in Redis server to avoid repeated calculation.
Because both handlers need redis, we extract redis separately and pass it in through parameters. In addition, the Handler can pass parameters through the initialize function. When registering the route, it can pass any parameters by providing a dictionary. The key of the dictionary should correspond to the parameter name. We run Python PI Py, open the browser to access http://localhost:8888/pi?n=200 , you can see the browser output {"cached": false, "pi": 3.1412743276, "n": 1000}, which is very close to the PI.
More Python videos, source codes and materials are available for free
Reprinted to: https://zhuanlan.zhihu.com/p/37382503