Hello, guys, long time no see... (really * long time no see =.)
I haven't written a blog for a long time. To apologize, I spent the whole day on the big guys today ~ that's the theme I'm going to talk about this time - Luwu~
So, what is Luwu? It's a spicy chicken open source project written by bencai chicken

What's the use of this spicy chicken open source project?
Keke, Luwu, or Lu Wu, aims to provide a code free or low code in-depth learning tool (the original intention of development is just to facilitate yourself to be lazy... Even simple in-depth learning tasks, there are often a lot of repetitive and cumbersome work, and these low-cost tasks should not waste our precious time. Automation, yyds!)
Luwu's appeal can be summarized into two points:
- So that developers without deep learning background can easily complete the development of simple deep learning tasks
- Enable deep learning developers to complete general deep learning tasks faster and easier
As of June 14, 2021, the supported task types are (the current version number of Luwu is 0.32):
- image classification
- object detection
- Text classification
- Text sequence annotation (named entity recognition)
More functions of the spicy chicken project are still being iterated by the spicy chicken author
Luwu is still in the early stage of the project, many places are not perfect, and the project is not very mature, so the interface / use mode may be adjusted in the subsequent process. I beg your pardon~
However, it's better to find a star for the spicy chicken project. If you like the big guys, welcome the star ~ and if you are willing to contribute code, you're welcome at any time~

Project address:
https://github.com/AaronJny/luwu
For more information, please refer to the readme documentation of the project.
Well, if you don't give it to star, it's just for your convenience at first

Well, without much gossip, start the whole work~
Please indicate the source of Reprint: https://blog.csdn.net/aaronjny/article/details/117917378
1, Install Luwu
First of all, let's talk about the bad news. The installation and use of Luwu have certain requirements for the network environment. During installation and use, files may be downloaded from GitHub and Google (such as TensorFlow Object Detection API, BERT pre training weight, accessing kaggle, etc.), so please ensure that your network can access Google normally or use agents, otherwise Luwu may not be able to use normally due to network reasons.
If you can't access Google normally, you can set the proxy in the command line as follows (you need to prepare the proxy yourself):
If your proxy address and port are as follows:
| type | address | port |
|---|---|---|
| http | http://127.0.0.1 | 7890 |
| https | http://127.0.0.1 | 7890 |
| socks5 | socks5://127.0.0.1 | 7891 |
Then open the terminal, enter the following command and press enter (note that after the agent setting is completed, it is only valid in the current window, and it needs to be reset to open a new window):
export https_proxy=http://127.0.0.1:7890 http_proxy=http://127.0.0.1:7890 all_proxy=socks5://127.0.0.1:7891
In addition, the project does not provide Windows support at present, and only has conducted compatibility test under Linux / Mac. Bigwigs who use Windows can consider using Docker. Luwu provides a built Docker image (both CPU version and GPU version). For details, please refer to Luwu's project description document.
Luwu supports pip installation, which is very simple. Open the terminal and enter the following instructions:
pip install luwu -v
Installation succeeded:
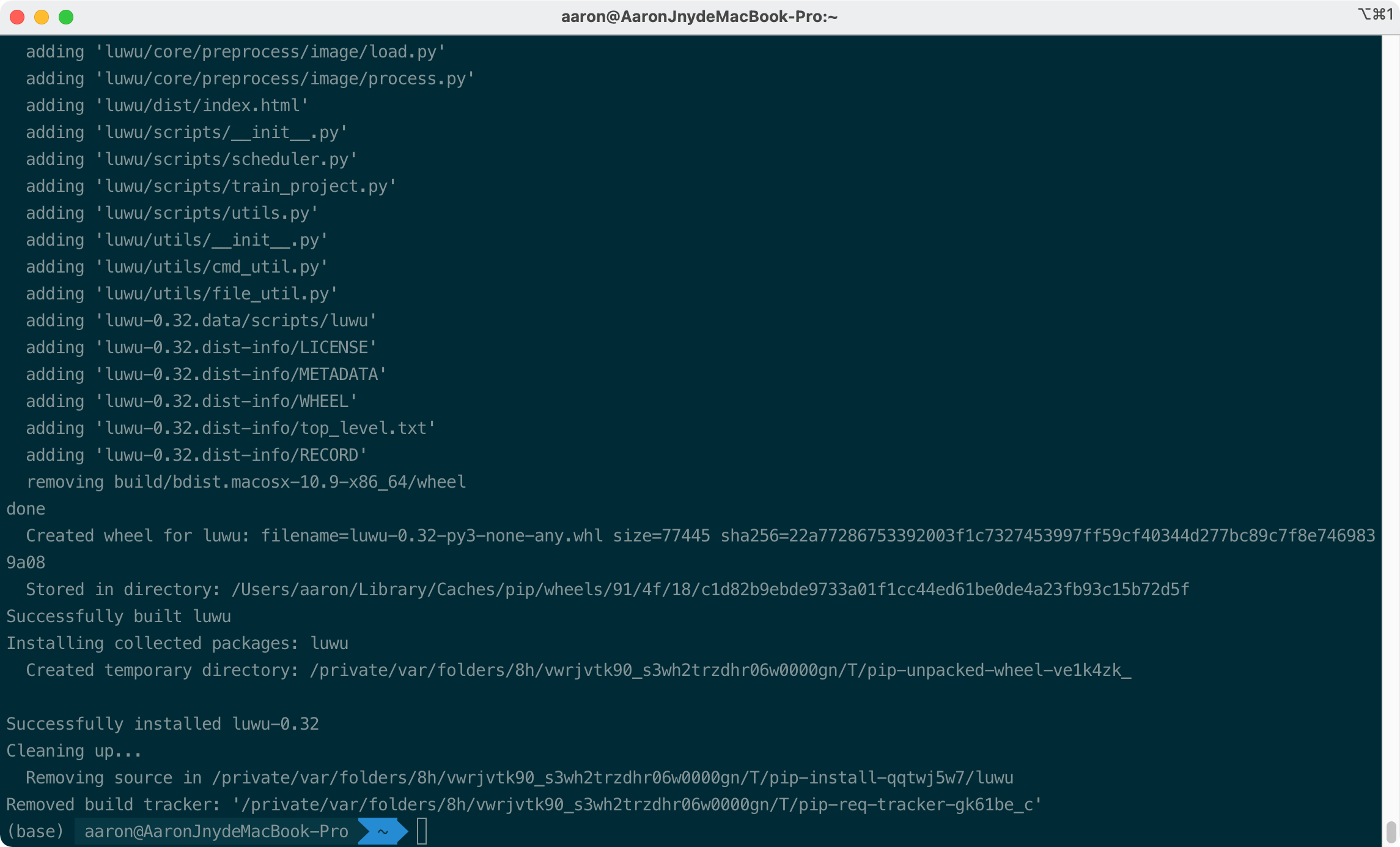
Note that Luwu will install relevant dependencies through scripts, which may take some time (1 minute or more). Use - v to better prompt the installation progress and avoid waiting anxiety ==

2, Training an image classifier using Luwu
Luwu supports two ways of using Web UI services and command-line tools, but at present, the development of Web UI services has been shelved because - I find that command-line tools seem to be better and more practical.
PS: the Web UI service now only supports the image classification function, and the command line tool supports all functions.
Here I will use Luwu's command line tool for demonstration.
After we install Luwu, we can call Luwu's command line tool at the terminal. Open the terminal and enter luwu -v to view the version number of the currently installed Luwu:

Enter luwu -h to view the basic usage of Luwu command line tool.
The output is as follows:
usage: luwu [-h] [--version] [--luwu_version LUWU_VERSION]
{web-server,detection,classification,text_classification,text_sequence_labeling}
...
Luwu Command line tool. You can complete the development of deep learning tasks without writing any code. LuWu command tool. You can complete the
development of deep learning tasks without writing any code.
optional arguments:
-h, --help show this help message and exit
--version, -v View current luwu Version number
--luwu_version LUWU_VERSION
kaggle Used on Luwu Version. If it is not specified, the latest official version will be used by default
cmd:
Command parameters to specify Luwu Action to be performed
{web-server,detection,classification,text_classification,text_sequence_labeling}
web-server with web Start as a service Luwu,So as to complete the development of deep learning task through graphical interface.
detection Target detection task training is carried out through the command line.
classification The image classification task is trained through the command line.
text_classification
Text classification task training through the command line.
text_sequence_labeling
Train the text sequence annotation task through the command line.
What we need to do now is the image classification task, that is, the above classification task. We can enter luwu classification -h to view the usage of this task. The output is as follows:
usage: luwu classification [-h] [--origin_dataset_path ORIGIN_DATASET_PATH]
[--validation_dataset_path VALIDATION_DATASET_PATH]
[--test_dataset_path TEST_DATASET_PATH]
[--tfrecord_dataset_path TFRECORD_DATASET_PATH]
[--model_save_path MODEL_SAVE_PATH]
[--validation_split VALIDATION_SPLIT]
[--test_split TEST_SPLIT]
[--do_fine_tune DO_FINE_TUNE]
[--freeze_epochs_ratio FREEZE_EPOCHS_RATIO]
[--batch_size BATCH_SIZE] [--epochs EPOCHS]
[--learning_rate LEARNING_RATE]
[--optimizer OPTIMIZER] [--project_id PROJECT_ID]
[--image_augmentation_random_flip_horizontal IMAGE_AUGMENTATION_RANDOM_FLIP_HORIZONTAL]
[--image_augmentation_random_flip_vertival IMAGE_AUGMENTATION_RANDOM_FLIP_VERTIVAL]
[--image_augmentation_random_crop IMAGE_AUGMENTATION_RANDOM_CROP]
[--image_augmentation_random_brightness IMAGE_AUGMENTATION_RANDOM_BRIGHTNESS]
[--image_augmentation_random_hue IMAGE_AUGMENTATION_RANDOM_HUE]
[--run_with_kaggle RUN_WITH_KAGGLE]
[--kaggle_accelerator KAGGLE_ACCELERATOR]
network_name
positional arguments:
network_name Classifier name. Supported classifiers are:[LuwuDenseNet121ImageClassifier, LuwuDen
seNet169ImageClassifier,LuwuDenseNet201ImageClassifier
, LuwuVGG16ImageClassifier,LuwuVGG19ImageClassifier,Lu
wuMobileNetImageClassifier, LuwuMobileNetV2ImageClassi
fier,LuwuInceptionResNetV2ImageClassifier, LuwuIncepti
onV3ImageClassifier,LuwuNASNetMobileImageClassifier, L
uwuNASNetLargeImageClassifier,LuwuResNet50ImageClassif
ier, LuwuResNet50V2ImageClassifier,LuwuResNet101ImageC
lassifier, LuwuResNet101V2ImageClassifier,LuwuResNet15
2ImageClassifier, LuwuResNet152V2ImageClassifier,LuwuM
obileNetV3SmallImageClassifier, LuwuMobileNetV3LargeIm
ageClassifier,LuwuXceptionImageClassifier, LuwuEfficie
ntNetB0ImageClassifier,LuwuEfficientNetB1ImageClassifi
er, LuwuEfficientNetB2ImageClassifier,LuwuEfficientNet
B3ImageClassifier, LuwuEfficientNetB4ImageClassifier,L
uwuEfficientNetB5ImageClassifier, LuwuEfficientNetB6Im
ageClassifier,LuwuEfficientNetB7ImageClassifier]
optional arguments:
-h, --help show this help message and exit
--origin_dataset_path ORIGIN_DATASET_PATH
Data set path before processing
--validation_dataset_path VALIDATION_DATASET_PATH
Validate dataset path. If not specified, from origin_dataset_path Cut in.
--test_dataset_path TEST_DATASET_PATH
Test dataset path. If not specified, from origin_dataset_path Cut in.
--tfrecord_dataset_path TFRECORD_DATASET_PATH
Treated tfrecord Dataset path
--model_save_path MODEL_SAVE_PATH
Model save path
--validation_split VALIDATION_SPLIT
Verify the cut scale of the set. Default 0.1
--test_split TEST_SPLIT
Test set cut scale. Default 0.1
--do_fine_tune DO_FINE_TUNE
Yes fine tune,Or retrain. default False
--freeze_epochs_ratio FREEZE_EPOCHS_RATIO
When carried fine_tune The pre training model will be frozen for training epochs,Thaw all parameters and train them for a certain time epochs,
This parameter indicates that training is frozen epochs Account for all epochs Scale of this parameter only do_fine_tune = True
Valid when). Default 0.1(When total epochs>1 As long as the proportion is set, at least one will be trained epoch)
--batch_size BATCH_SIZE
mini batch size. Default 32.
--epochs EPOCHS train epoch Count. Default 30.
--learning_rate LEARNING_RATE, -lr LEARNING_RATE
Learning rate. Default 0.001.
--optimizer OPTIMIZER
Optimizer type during training,Optional parameters are [Adam, Adamax, Adagrad, Nadam,
Adadelta, SGD, RMSprop]. Silent use Adam.
--project_id PROJECT_ID
Item No. Defaults to 0.
--image_augmentation_random_flip_horizontal IMAGE_AUGMENTATION_RANDOM_FLIP_HORIZONTAL
Data enhancement option, whether to do random left and right mirroring. default False.
--image_augmentation_random_flip_vertival IMAGE_AUGMENTATION_RANDOM_FLIP_VERTIVAL
Data enhancement option, whether to do random up and down mirror. default False.
--image_augmentation_random_crop IMAGE_AUGMENTATION_RANDOM_CROP
Data enhancement option, whether to make random clipping, and the clipping size is 0 of the original scale.9. default False.
--image_augmentation_random_brightness IMAGE_AUGMENTATION_RANDOM_BRIGHTNESS
Data enhancement option, whether to make random saturation adjustment. default False.
--image_augmentation_random_hue IMAGE_AUGMENTATION_RANDOM_HUE
Data enhancement option, whether to make random tone adjustment. default False.
--run_with_kaggle RUN_WITH_KAGGLE
Whether to use kaggle Environment operation. You must first install and configure kaggle
api,To use this option. Default to False,I.e. local operation
--kaggle_accelerator KAGGLE_ACCELERATOR
Whether to use kaggle GPU Accelerate (note that only if run_with_kaggle by True
This option is only valid when). Not used by default (i.e. used) CPU)
So many parameters??? Is there any mistake???

Don't worry. You don't need to use most of the parameters here. It just provides a possibility. Generally, you only need to configure a few parameters.
Now let's officially start - we now use Luwu to train a cat and dog image classifier.
First, in the first step, we need to obtain the image data set of cats and dogs.
1. Download data set
Datasets can be downloaded here: https://www.floydhub.com/fastai/datasets/cats-vs-dogs
After downloading, unzip it.
Because it is just a demonstration, we will not use the complete dataset, but only the train part of the dataset.
2. Create a project folder
We need to create a folder as the working directory.
Open the terminal and enter MKDIR cats vs dogs to create a working directory.
Enter CD cats VS DOGS & & MKDIR data to create a data directory for storing the original data set.

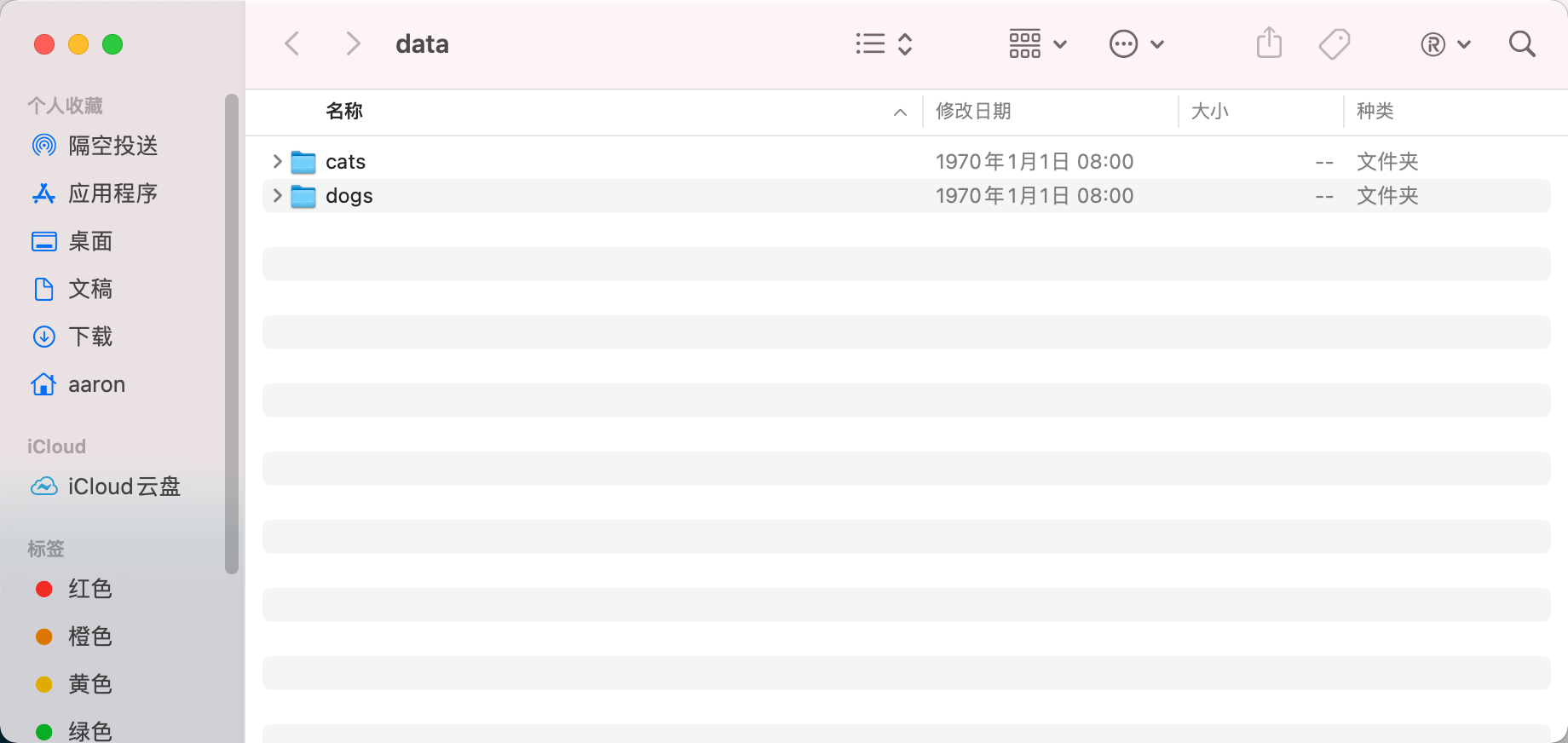
3. Copy / move the dataset to the project folder
Next, open the cats vs dogs / data folder and copy the subfolders under the train folder in the downloaded dataset to the cats vs dogs / data folder.
4. Train the image classifier through luwu's command line tool
Open the terminal, switch the current directory to cats vs dogs, and then enter the command:
luwu classification --origin_dataset_path "./data" --tfrecord_dataset_path "./dataset" --model_save_path "." --epochs 4 --validation_split 0.05 --do_fine_tune True LuwuDenseNet121ImageClassifier
Here we explain the parameters in the command:
- Luwu: Luwu command line tool entry
- Classification: train an image classification task
- –origin_dataset_path: the path of the original dataset. There are requirements for the organization of data sets. It is necessary to take the category as the folder name and put the pictures under the corresponding folder. For example, the origin here_ dataset_ Path is/ data,./ There are two folders under data. Cats and dogs represent two categories respectively. All pictures of cats are placed under cats and all pictures of dogs are placed under dogs.
- –tfrecord_dataset_path: before model training, the data set is first converted into a file in TFRecord format. This directory represents the storage location of the generated TFRecord file. For example, TFRecord here_ dataset_ Path is/ Dataset, the generated files will be placed in this directory (if the directory does not exist, it will be created automatically).
- –model_save_path: indicates the directory where files such as the trained model and generated call code are stored. Model here_ save_ Path is, Indicates that it is stored in the current directory.
- – epochs: indicates how many complete iterations are performed on the data set. Here, epochs is 4, indicating that the complete data set is traversed 4 times.
- –validation_split: during training, the data set will be divided into training set and verification set. This parameter indicates the proportion of dividing verification set. Validation here_ Split is 0.05, which means that about 5% of the data is used for model verification.
- –do_fine_tune: indicates whether to freeze the pre training model for fine tune during training When this parameter is True, by default, 0.1*epochs are trained by freezing the weight of the pre training model (rounded up) (the specific proportion can be adjusted through the free_epochs_ratio parameter), and then unfreeze all parameters to train the remaining epochs. Otherwise, thaw all parameters and train all epochs. Do here_ fine_ Tune is True, epichs is 4, free_ epochs_ Ratio is the default value of 0.1, which means to freeze 1 epochs for training first, and then unfreeze 3 epochs for training.
- LuwuDenseNet121ImageClassifier: the name of the classifier model. This is one of the models supported by luwu. More models can be viewed by executing luwu classification -h on the command line. (how to choose so many models? Please explain later)
Note that the parameters related to the path will be more appropriate to the absolute path, which can reduce the problem of artificially introduced path errors. However, for the convenience of demonstration, I use relative path here.
More configurable parameters can also be viewed by executing luwu classification -h on the command line.
To get back to business, after inputting the above command, luwu will start training an image classifier, and the general output is as follows:
Namespace(batch_size=8, cmd='classification', do_fine_tune=True, epochs=4, freeze_epochs_ratio=0.1, image_augmentation_random_brightness=False, image_augmentation_random_crop=False, image_augmentation_random_flip_horizontal=False, image_augmentation_random_flip_vertival=False, image_augmentation_random_hue=False, kaggle_accelerator=False, learning_rate=0.001, luwu_version='', model_save_path='.', network_name='LuwuDenseNet121ImageClassifier', optimizer='Adam', origin_dataset_path='./data', project_id=0, run_with_kaggle=False, test_dataset_path='', test_split=0.1, tfrecord_dataset_path='./dataset', validation_dataset_path='', validation_split=0.05) 2021-06-15 00:42:55.613 | INFO | luwu.core.models.classifier:run:319 - Preprocessing dataset... 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 19672/19672 [00:06<00:00, 3216.37it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 1150/1150 [00:00<00:00, 2846.68it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 2300/2300 [00:00<00:00, 2991.18it/s] 2021-06-15 00:43:06.926540: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set 2021-06-15 00:43:06.929492: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-06-15 00:43:07.167322: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2) 2021-06-15 00:43:20.214 | INFO | luwu.core.models.classifier:run:322 - Building model... 2021-06-15 00:43:23.919 | INFO | luwu.core.models.classifier:run:325 - Start training... 2021-06-15 00:43:23.919 | INFO | luwu.core.models.classifier.preset.pre_trained:train:50 - Training in two steps, freeze training 1 epochs,Thaw training 3 epochs... 2021-06-15 00:43:23.919 | INFO | luwu.core.models.classifier.preset.pre_trained:train:54 - frozen pre-trained Model, start pre training ... 2459/2459 [==============================] - 1464s 593ms/step - loss: 0.5017 - accuracy: 0.9508 - val_loss: 0.2045 - val_accuracy: 0.9770 2021-06-15 01:07:48.171 | INFO | luwu.core.models.classifier.preset.pre_trained:train:67 - thaw pre-trained Model, continue training ... Epoch 2/4 2459/2459 [==============================] - 1460s 594ms/step - loss: 0.1425 - accuracy: 0.9806 - val_loss: 0.1068 - val_accuracy: 0.9765 Epoch 3/4 2459/2459 [==============================] - 1439s 585ms/step - loss: 0.0842 - accuracy: 0.9816 - val_loss: 0.0752 - val_accuracy: 0.9791 Epoch 4/4 2459/2459 [==============================] - 1455s 592ms/step - loss: 0.0630 - accuracy: 0.9819 - val_loss: 0.0628 - val_accuracy: 0.9796 2021-06-15 02:20:24.311 | INFO | luwu.core.models.classifier.preset.pre_trained:train:80 - Validate on test set... 288/288 [==============================] - 153s 533ms/step - loss: 0.0628 - accuracy: 0.9796 2021-06-15 02:22:57.761 | INFO | luwu.core.models.classifier.preset.pre_trained:train:84 - [0.06279316544532776, 0.9795652031898499] 2021-06-15 02:22:57.761 | INFO | luwu.core.models.classifier:run:328 - Export code... 2021-06-15 02:22:57.767 | INFO | luwu.core.models.classifier:run:330 - Done.
The machine demonstrated has no GPU environment, so the training will be slow, but it will not affect the demonstration.
This classification problem is also relatively simple. It can be found that training the first epochs already has good results. After training the first epochs, the acc of the verification set is 0.977, after training four epochs, and finally the acc of the test set is 0.9796.
After training, open the cats vs dogs folder:
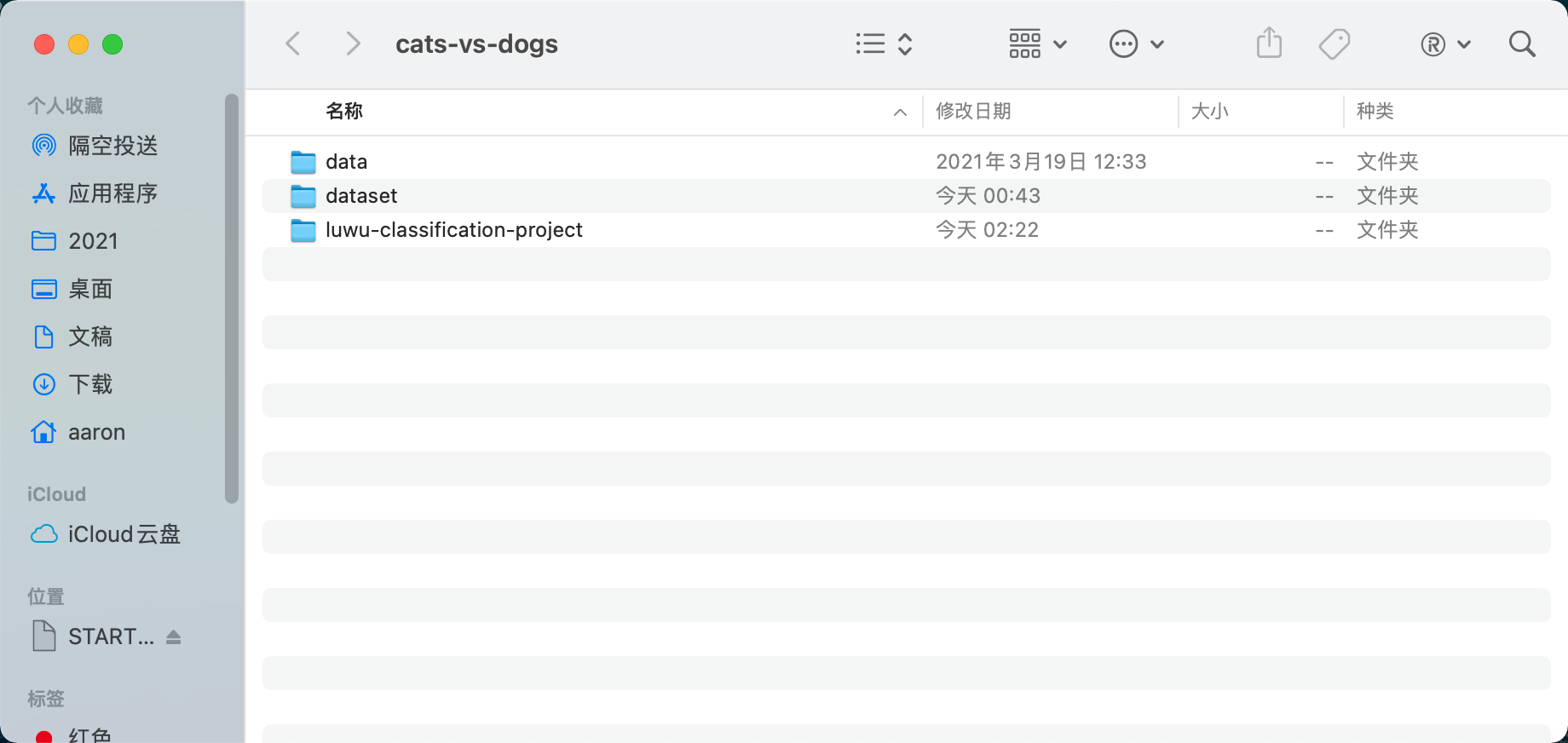
Luwu classification project is the directory where we save the model. Open it. There are trained models and call scripts for reference:
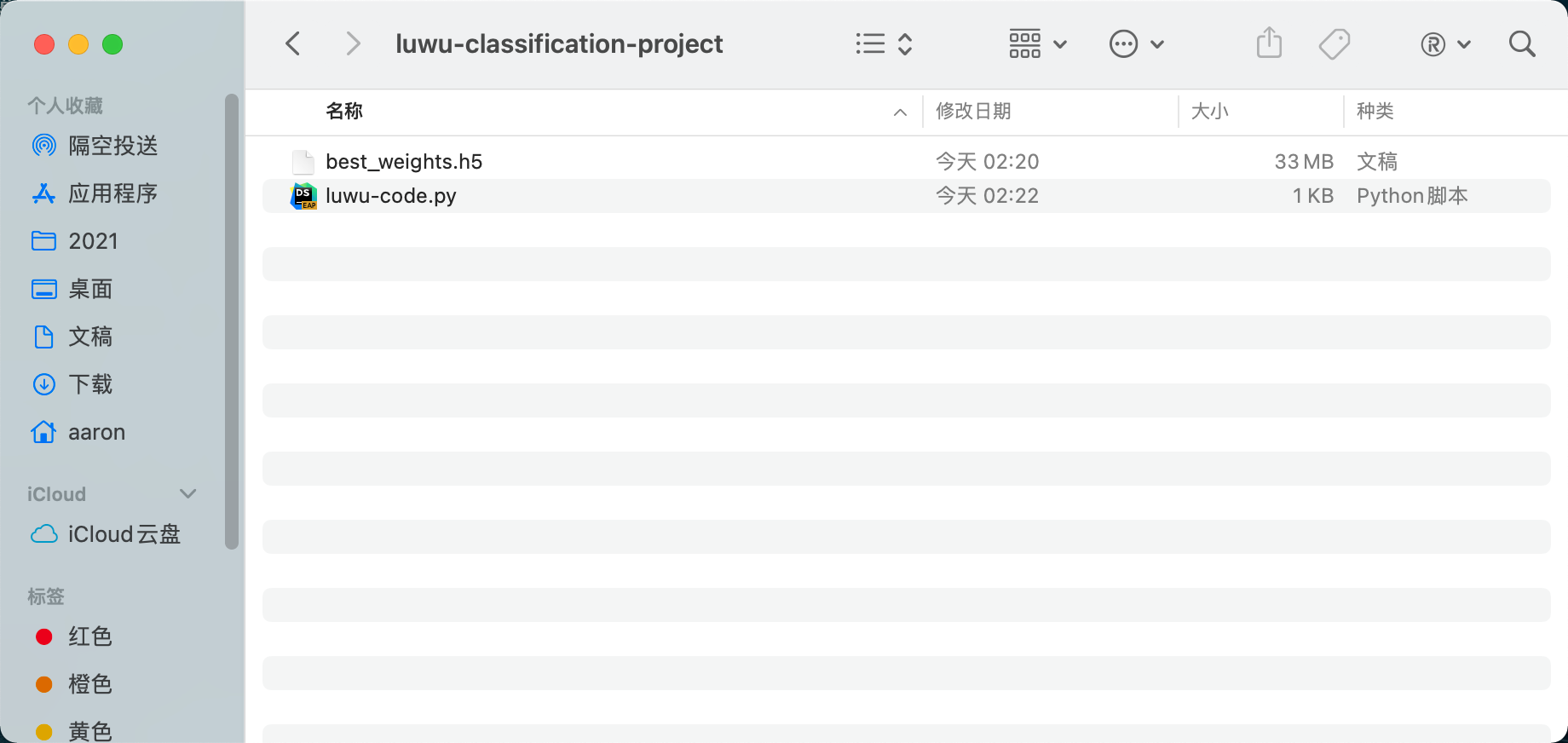
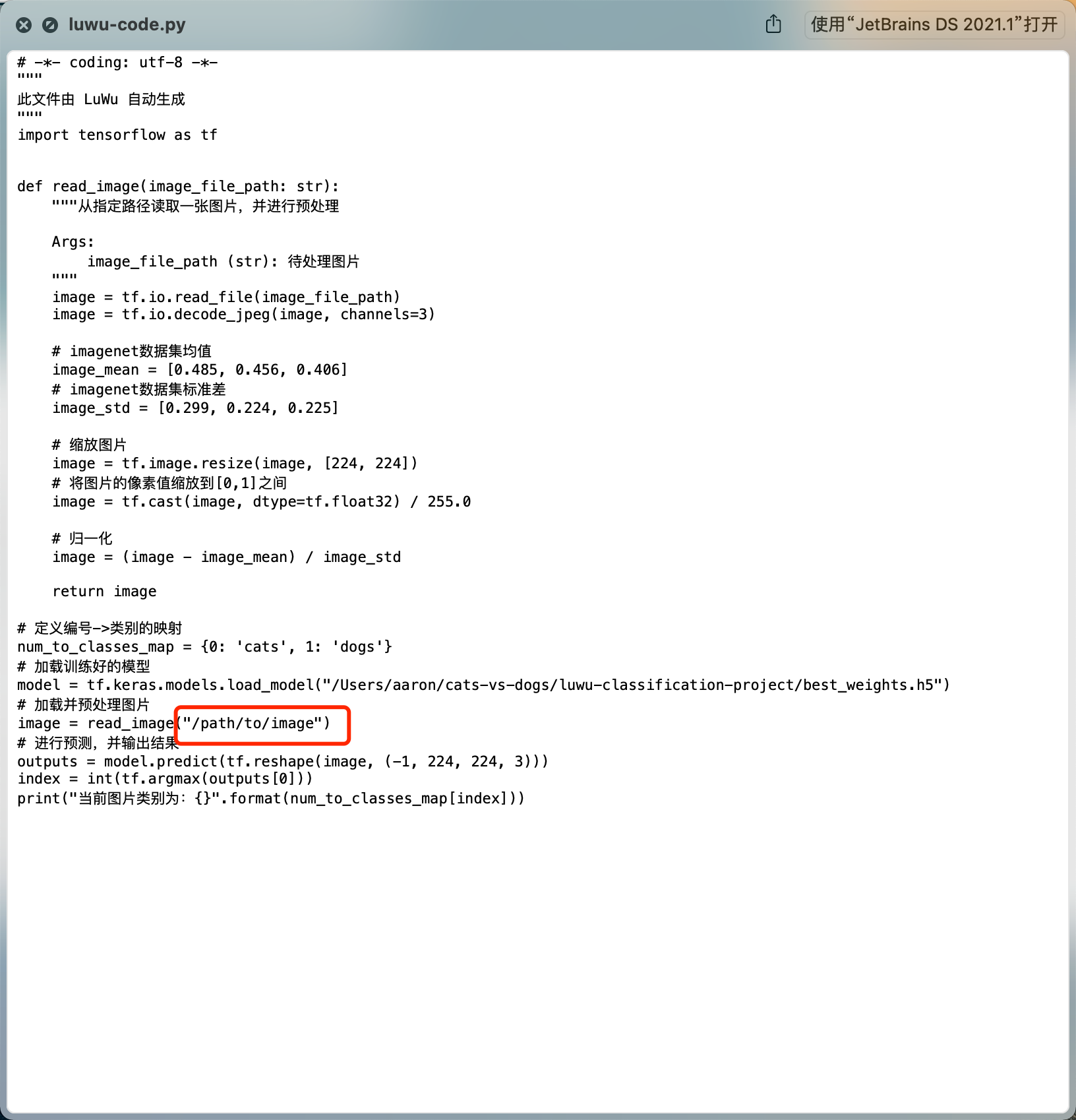
Change the image path in the script to call the model to classify the specified images ~ let's try with the following image:

(base) aaron@AaronJnydeMacBook-Pro > ~/cats-vs-dogs/luwu-classification-project > python luwu-code.py 2021-06-15 05:27:55.020102: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set 2021-06-15 05:27:55.020308: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-06-15 05:27:57.890260: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2) The current picture category is: dogs
Successfully identified, the result is a dog.
3, Conclusion
Spicy chicken author, spicy chicken project, a pile of bug s, forgive me~
If you encounter any problems or have any good suggestions, you can also launch an issue on GitHub.
If you like this project, please give a star~
If you like this article, you can see it here. You can pay attention to it, watch it and like it~
Thank you, boss~
About me
A technology enthusiast with Python as the main language, ACM-ICPC broken iron player.
A batch of weak chickens who like sharing and cooking, and who like to engage in crawlers and algorithms.
An unknown and growing technology blogger.
CSDN: https://blog.csdn.net/aaronjny
GitHub: https://github.com/AaronJny
WeChat official account: technical diary
Come on, encourage each other!