Background: kafka client's producer API sends messages and simple source code analysis
Starting from Kafka 0.11, Kafka producer supports two modes: idempotent producer and transaction producer. Idempotent producers strengthen Kafka's delivery semantics, from at least one delivery to precise one delivery. In particular, the retry of the producer will no longer introduce duplication. Transactional producers allow applications to send messages atomically to multiple partitions (and topics).
Idempotency
Kafka introduced a major feature in version 0.11, idempotency. The so-called idempotency means that no matter how many times the Producer sends duplicate data to the Server, the Server side will only persist one.
Take http as an example. For one or more requests, the response is consistent (except for network timeout). In other words, the impact of performing multiple operations is the same as that of performing one operation.
If a system is not idempotent, it may cause adverse effects if users repeatedly submit a form. For example, as like as two peas, the user clicks on multiple submit order buttons on the browser, and generates many identical orders in the background.
Basic principle of idempotency
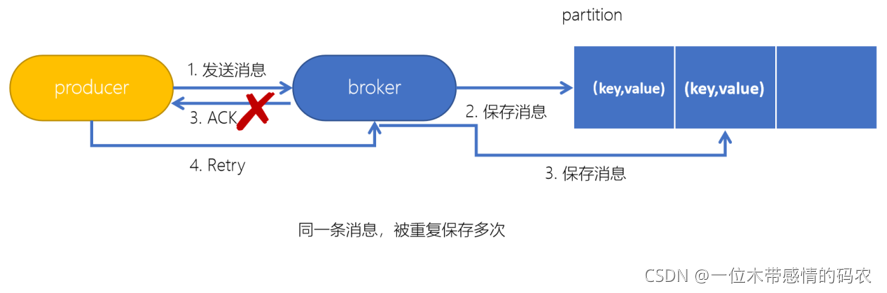
For Kafka, the idempotent problem that the producer sends messages needs to be solved. As like as two peas are generated, the message is sent to the retry when the producer produces the message. If Kafka is not idempotent, it will be possible to save many identical messages in partition.
In order to realize the idempotency of Producer ID and number, the concept of Kafka sequence is introduced.
- PID: Each Producer will assign a unique PID during initialization. This PID is transparent to the user
- Sequence Number: the message sent to the specified topic partition by each producer (corresponding PID) corresponds to a Sequence Number increasing from 0. The Server side judges whether the data is repeated according to this value
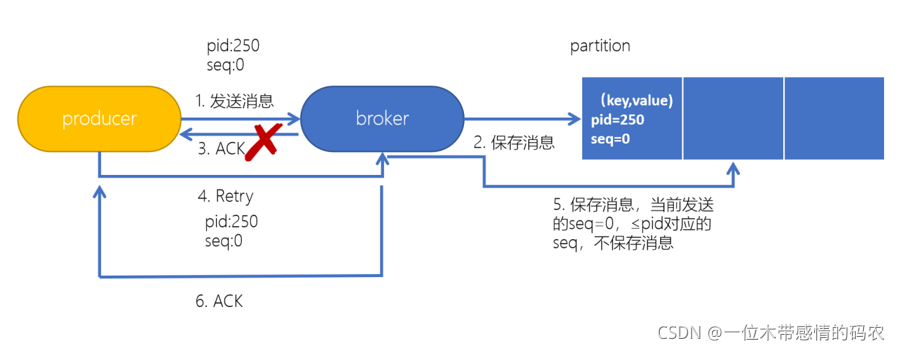
During the initialization of producer, a PID will be generated by the server side, and then each message sent will contain the PID and sequence number. On the server side, a sequence numbers information is stored according to the partition, and whether the data is repeated or omitted will be determined by judging the difference between the sequence number sent by the client and the number+1 of the server side.
When the Producer sends a message to the Broker, the Broker receives the message and appends it to the message flow. At this time, when the Broker returns the Ack signal to the Producer, an exception occurs, causing the Producer to fail to receive the Ack signal. For Producer, the retry mechanism will be triggered to send the message again. However, due to the introduction of idempotency, PID (Producer ID) and Sequence Number are attached to each message. If the same PID and Sequence Number are sent to the Broker, and the Broker has cached the same message sent before, there will be only one message in the message flow and there will be no repeated sending.
Process of generating PID
//When creating a transaction
Producer<String, String> producer = new KafkaProducer<String, String>(props);
//A Sender will be created and the thread will be started, and the following run method will be executed
Sender{
void run(long now) {
if (transactionManager != null) {
try {
........
if (!transactionManager.isTransactional()) {
// Generate a producer id for idempotent producer
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
Why MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION less than or equal to 5
Usually, in order to ensure the data order, we can use MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1 to ensure that this is only for a single instance. In kafka2 In version 0 +, as long as idempotency is enabled, the order of sending data can be guaranteed without setting this parameter.
In fact, here, Max is required_ IN_ FLIGHT_ REQUESTS_ PER_ The main reason why connection is less than or equal to 5 is that the ProducerStateManager instance on the Server side will cache the last five batch data sent by each PID on each topic partition (this 5 is written dead, and the reason why it is 5 may be related to experience. When idempotency is not set, when this is set to 5, the performance is relatively high, and the community has a relevant test document). If it exceeds 5, the producer statemanager will clear the oldest batch data.
Suppose the application will be MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION is set to 6. Suppose the order of requests sent is 1, 2, 3, 4, 5 and 6. At this time, the server can only cache the batch data corresponding to requests 2, 3, 4, 5 and 6. At this time, suppose that request 1 fails to be sent and needs to be retried. When the retried request is sent, first check whether it is a duplicate batch, and then check whether the check result is correct, After that, it will start checking its sequence number value. At this time, only one OutOfOrderSequenceException exception will be returned. After receiving this exception, the client will retry again until the maximum number of retries or timeout is exceeded. This will not only affect the performance of the Producer, but also put pressure on the server (equivalent to the client sending out error requests).
Considerations for idempotency
- Idempotency Producer can only guarantee the idempotency of a single partition: that is, it can only ensure that there are no duplicate messages on one partition on a topic, and it cannot realize the idempotency of multiple partitions
- Idempotency Producer can only achieve idempotency on a single session, but cannot achieve idempotency across sessions
Session: a run of the Producer process. If the Producer process is restarted, the idempotency guarantee will be lost
Configuration idempotency
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);
To enable idempotence, you must set enable The identotence configuration is set to true. If set, the retries configuration defaults to integer MAX_ Value, acks configuration will default to all. If acks is explicitly set to 0, - 1, an error will be reported.
In addition, if send (producer record) returns an error even if it retries indefinitely (for example, the message expires in the buffer before sending), it is recommended to shut down the producer and check the content of the last generated message to ensure that it is not repeated. Finally, the producer can only guarantee the idempotency of messages sent in a single session.
Exactly Once semantics
Setting the ACK level of the Server to - 1 ensures that no data will be lost between the Producer and the Server, that is, At Least Once semantics. In contrast, setting the Server ack level to 0 can ensure that each message of the Producer will be sent only once, that is, At Most Once semantics.
At Least Once can ensure that the data is not lost, but it cannot guarantee that the data is not repeated; In contrast, At Most Once can ensure that the data is not repeated, but it cannot guarantee that the data is not lost. However, for some very important information, such as transaction data, downstream data consumers require that the data be neither repeated nor lost, that is, the semantics of Exactly Once. In Kafka before version 0.11, there is nothing we can do about it. We can only ensure that the data is not lost, and then do global de duplication for the data in the downstream consumers. In the case of multiple downstream applications, each needs to do global de duplication separately, which has a great impact on the performance.
Version 0.11 of Kafka introduces a major feature: idempotency. Idempotency combined with At Least Once semantics constitutes Kafka's Exactly Once semantics. Namely:
At Least Once + idempotent = Exactly Once
Kafka's idempotency implementation actually replays what the downstream needs to do in the upstream of the data.
affair
Idempotency does not work across multiple partitions, and transactions can make up for this defect. Kafka transaction is a new feature introduced by Kafka 0.11 in 2017. A transaction similar to a database. Kafka transaction refers to the fact that production and consumption can cross partitions and sessions on the basis of Exactly Once semantics. The producer can produce messages and the consumer can submit offset s in an atomic operation, either successful or failed. Especially when producers and consumers coexist, the protection of affairs is particularly important. (consumer transform producer mode)
Scenario where the consumer submits an offset that causes repeated consumption messages: the consumer hangs up before the consumer completes submitting the offset o2 (assuming that the offset it recently submitted is o1). At this time, when rebalancing is performed, other consumers will repeat consumption messages (information between o1 and o2).
Application of transaction
An atomic operation can be divided into three situations according to the operation types:
- Only Producer production messages;
- Consumption messages and production messages coexist. This is the most common case in transaction scenarios, which is often referred to as the "consume transform produce" mode
- Only consumer consumption messages
The first two cases are the scenarios of transaction introduction, and the last case has no use value (the same effect as using manual submission).
Related attribute configuration
Some considerations when using kafka's transaction API:
- The automatic mode of the consumer needs to be set to false, and the child can no longer execute consumer#commitSync or consumer#commitAsyc manually
- Producer configuration transaction ID attribute
- The producer does not need to configure enable Idempotent, because if transaction. Is configured ID, then enable Idempotent will be set to true
- Consumer needs to configure isolation level. When using transactions in consume trnasform produce mode, it must be set to READ_COMMITTED.
Producer transaction
In order to realize cross partition and cross session transactions, it is necessary to introduce a globally unique Transaction ID and bind the PID obtained by the Producer with the Transaction ID. In this way, when the Producer is restarted, the original PID can be obtained through the ongoing Transaction ID.
To manage transactions, Kafka introduces a new component Transaction Coordinator. Producer obtains the task status corresponding to the Transaction ID by interacting with the Transaction Coordinator. The Transaction Coordinator is also responsible for writing the Transaction information into an internal Topic of Kafka. In this way, even if the whole service is restarted, the Transaction status in progress can be restored because the Transaction status is saved, so as to continue.
To use the transaction producer and attendant API s, you must set transactional id. If transactional is set ID, idempotency will be automatically enabled together with the producer configuration on which idempotency depends. In addition, topics included in transactions should be configured for durability. In particular, replication The factor should be at least 3, and the min.insync of these topics Replicas should be set to 2. Finally, in order to achieve end-to-end transactional assurance, consumers must also be configured to read only submitted messages.
transactional. The purpose of ID is to realize transaction recovery between multiple sessions of a single producer instance. It is usually derived from partition identifiers in partitioned, stateful applications. Therefore, it should be unique for each producer instance running in a partitioned application.
All new transactional API s are blocked and throw exceptions when they fail.
Definition of transaction related methods in Producer interface
//Transaction methods provided by producer
/**
* Initialize the transaction. It should be noted that:
* 1,premise
* Transition needs to be guaranteed The ID attribute is configured.
* 2,The execution logic of this method is:
* (1)Ensures any transactions initiated by previous instances of the producer with the same
* transactional.id are completed. If the previous instance had failed with a transaction in
* progress, it will be aborted. If the last transaction had begun completion,
* but not yet finished, this method awaits its completion.
* (2)Gets the internal producer id and epoch, used in all future transactional
* messages issued by the producer.
*
*/
public void initTransactions();
/**
* Open transaction
*/
public void beginTransaction() throws ProducerFencedException ;
/**
* The action provided to the consumer to commit an offset within a transaction
*/
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException ;
/**
* Commit transaction
*/
public void commitTransaction() throws ProducerFencedException;
/**
* Abandoning a transaction is similar to rolling back a transaction
*/
public void abortTransaction() throws ProducerFencedException ;
Create producer
Configure transactional ID attribute
public static Producer<String, String> createProducer() {
Properties properties = new Properties();
//The variables in the configuration file are of static final type and have default values
//host/port used to establish connection with kafka cluster
//The inherited hashtable ensures thread safety
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"IP:9092");
/**
* producer Attempts will be made to batch message logging to reduce the number of requests. This will improve the performance between client and server. This configuration controls the default number of message bytes for batch processing.
* No attempt will be made to process message bytes larger than this number. The request sent to brokers will contain multiple batch processes, including one request for each partition.
* Smaller batch processing values are less used and may reduce throughput (0 will only use batch processing). Larger batch processing values will waste more memory space, which requires special allocation
* Memory size for batch processing values
**/
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384");
/**
* producer The group will summarize any messages that arrive between the request and the sending, and record a single batch of requests. Generally speaking, this is only possible when the recording generation speed is greater than the transmission speed
* Can happen. However, under certain conditions, the client will want to reduce the number of requests, even to a moderate load. This will be done through a small delay, that is, not immediately
* After sending a record, producer will wait for a given delay time to allow other message records to be sent. These message records can be processed in batch. This can be considered as the calculation of TCP Nagle
* The method is similar. This setting sets a higher delay boundary for batch processing: once we get the batch of a partition Size, he will send it immediately regardless of this setting,
* However, if we get a much smaller number of message bytes than this setting, we need a "linker" specific time to get more messages. This setting defaults to 0, that is, there is no delay. set up
* Fixed linker Ms = 5, for example, will reduce the number of requests, but will increase the delay of 5ms at the same time
**/
properties.put(ProducerConfig.LINGER_MS_CONFIG,"1");
/**
* producer The amount of memory that can be used to cache data. If the data generation speed is faster than that sent to the broker, the cache space will be exhausted
* It will block or throw an exception, which is indicated by "block.on.buffer.full". This setting will be related to the total memory that producer can use, but not a single one
* Hard limit, because not all memory used by producer is used for caching. Some extra memory will be used for compression (if compression mechanism is introduced), and there are also some
* Used to maintain requests. When the cache space is exhausted, other sending calls will be blocked. The threshold of blocking time passes max.block After MS is set, it will throw a TimeoutException.
**/
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432");
/**
* This configuration controls kafkaproducer's send(), partitionsfor(), inittransaction(), sendoffsetstotransaction(), committransaction()“
* The and abortTransaction() methods will block. For send(), this timeout limits the total wait time for getting metadata and allocating buffers“
**/
properties.put(ProducerConfig.MAX_BLOCK_MS_CONFIG,"5000");
//Sending messages to kafka server definitely requires serialization. The messages sent here are of string type, so the serialization class of string is used
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//Set the transaction ID if transactional is configured ID attribute, then enable Idempotent will be set to true
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"my-transactional-id");
return new KafkaProducer<>(properties);
}
Create consumer
- Turn off the auto commit attribute (auto.commit) in the configuration
- Moreover, manual submission of commitSync() or commitAsync() cannot be used in the code
- Set isolation level
/**
* need:
* 1,Turn off auto commit enable auto. commit
* 2,isolation.level Is read_committed
* @return
*/
public static Consumer createConsumer() {
Properties properties = new Properties();
// bootstrap.servers is the IP address of the Kafka cluster. Use commas to separate multiple
properties.put("bootstrap.servers", "IP:9092");
// Consumer group
properties.put("group.id", "groupxt");
// Set isolation level
properties.put("isolation.level","read_committed");
// Turn off auto submit
properties.put("enable.auto.commit", "false");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(properties);
}
Only Producer production messages
/*
Producer Asynchronous sending with callback function (transaction) has only production message operation in a transaction
*/
public static void onlyProduceInTransaction(){
Producer<String,String> producer = ProducerTransaction.createProducer();
// 1. Initialize transaction
producer.initTransactions();
try {
// 2. Start transaction
producer.beginTransaction();
// 3.kafka write operation set
// 3.1 do business logic
// 3.2 sending messages
// Message object - ProducerRecoder
for(int i=0;i<10;i++){
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,"key-"+i,"value-"+i);
//Is to pass in one more callback instance
/**
* The user can implement a callback interface to allow the code to execute when the request is completed. This callback is usually executed in the background I/O thread, so it should be fast.
**/
producer.send(record, new Callback() {
/**
* The callback method provided by the user can complete the processing of the request asynchronously. This method is called when the record sent to the server is confirmed. When the exception in the callback is not empty, the metadata will contain the special-1 values of all fields except topicPartition, which will be valid.
* Parametric shape:
* metadata – Metadata (i.e. partition and offset) of the record sent. If an error occurs, metadata with all fields of - 1 except topicPartition will be returned,
* exception – Exception thrown during processing of this record. Null if no error occurred.
* Possible exceptions thrown include: non retryable exception (fatal, never send message):
* InvalidTopicException OffsetMetadataTooLargeException RecordBatchTooLargeException RecordTooLargeException UnknownServerException UnknownProducerIdException InvalidProducerEpochException
* Retryable exception (can be overwritten by adding retries): CorruptRecordException InvalidMetadataException NotEnoughReplicasAfterAppendException NotEnoughOutReplicasException Offset
**/
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println(
"partition : "+recordMetadata.partition()+" , offset : "+recordMetadata.offset());
}
});
}
// 3.3 do other business logic, you can also send messages of other topic s.
// 4. Transaction submission
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 5. Abandonment of business
producer.abortTransaction();
}finally{
// All channels need to be closed when they are opened. The close method will set the cache queue status to closed, wake up the io thread and send the data in memory to the broker, so as to prevent the process of this program from suddenly hanging up and then the messages in memory are lost. Therefore, when this method ends, all the message data will be sent out
producer.close();
}
}
Only consumer consumption messages
/**
* There are only message operations in a transaction
*/
public static void onlyConsumeInTransaction() {
// 1. Build a producer
Producer<String,String> producer = ProducerTransaction.createProducer();
// 2. Initialize transaction (generate productId). For a producer, only one initialization transaction operation can be performed
producer.initTransactions();
// 3. Build consumer and subscription themes
Consumer consumer = createConsumer();
consumer.subscribe(Arrays.asList("xt"));
while (true) {
// 4. Start transaction
producer.beginTransaction();
// 5.1 receiving messages
Duration duration = Duration.ofMillis(500);
ConsumerRecords<String, String> records = consumer.poll(duration);
try {
// 5.2 do business logic;
System.out.println("customer Message---");
Map<TopicPartition, OffsetAndMetadata> commits = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
// 5.2.1 print the offset,key and value for the consumer records
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// 5.2.2 record submission offset
commits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()));
}
// 6. Submit offset
producer.sendOffsetsToTransaction(commits, "groupxt");
// 7. Transaction submission
producer.commitTransaction();
}catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 8. Abandonment of business
System.out.println(e.getMessage());
producer.abortTransaction();
}finally{
producer.flush();
}
}
}
Consumption transform produce
In a transaction, there are both production message operations and consumption message operations, which is often referred to as the consumption tansform production mode. The following example code
/**
* Within a transaction, there are both production and consumption messages
*/
public static void consumeTransferProduce() {
// 1. Build a producer
Producer<String,String> producer = ProducerTransaction.createProducer();
// 2. Initialize transaction (generate productId). For a producer, only one initialization transaction operation can be performed
producer.initTransactions();
// 3. Build consumer and subscription themes
Consumer consumer = createConsumer();
consumer.subscribe(Arrays.asList("xt"));
while (true) {
// 4. Start transaction
producer.beginTransaction();
// 5.1 receiving messages
Duration duration = Duration.ofMillis(5000);
ConsumerRecords<String, String> records = consumer.poll(duration);
System.out.println(records.count());
try {
// 5.2 do business logic;
System.out.println("customer Message---");
Map<TopicPartition, OffsetAndMetadata> commits = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
// 5.2.1 read and process messages. print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// 5.2.2 offset of record submission
commits.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()));
// 6. Produce new news. For example, for the message of takeout order status, if the order is successful, you need to send a carry forward message with the merchant or a commission message from the dispatcher
producer.send(new ProducerRecord<String, String>("xt", "data"));
}
// 7. Submit offset
producer.sendOffsetsToTransaction(commits, "groupxt");
// 8. Transaction submission
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 7. Abandonment of business
producer.abortTransaction();
}finally{
producer.flush();
}
}
}
Consumer transaction
The above transaction mechanism is mainly considered from the aspect of Producer. For consumers, the guarantee of transaction will be relatively weak, especially the accurate consumption of Commit information can not be guaranteed. This is because the Consumer can access any information through offset, and the life cycles of different segment files are different. Messages of the same transaction may be deleted after restart.
Related profile fields
Broker configs
| Configuration item | describe |
|---|---|
| transactional.id.timeout.ms | The transaction coordinator does not receive any waiting time for transaction status updates from the producer. After the time has passed, the producer will actively update the transaction status. Transaction id expiration defaults to 604800000 (7 days). This allows producers to work regularly every week to maintain their IDs |
| max.transaction.timeout.ms | The maximum timeout allowed for a transaction. If the transaction time requested by the client exceeds this value, the broker will return an InvalidTransactionTimeout error in InitPidRequest. This prevents the client from timeout too long, which will cause the client to pause when reading the Topic contained in the transaction. The default is 900000 (15 minutes). This is a conservative upper limit on the time it takes to send a transaction message. |
| transaction.state.log.replication.factor | Number of copies of the transaction status topic. The default is 3 |
| transaction.state.log.num.partitions | The number of partitions for the transaction status topic. The default is 50 |
| transaction.state.log.min.isr | Each partition of the transaction status topic needs to consider the minimum number of insync replicas online. The default is 2 |
| transaction.state.log.segment.bytes | Segment size of the transaction status topic. Default: 104857600 bytes. |
Producer configs
| Configuration item | describe |
|---|---|
| enable.idempotence | Whether idempotent is enabled (false by default). If disabled, the producer will not set the PID field in the production request and the current producer delivery semantics. Note that in order to use transactions, idempotency must be enabled. When we turn on idempotency, and we turn on. Max. flies = 1 requests. per. connection=1. If these configurations do not have these values, we cannot guarantee idempotency. If these settings are not explicitly overridden by the application, when the idempotent function is enabled, the producer will set acks = all, retries = integer MAX_ VALUE, max.inflight. requests. per. connection=1 |
| transaction.timeout.ms | The maximum time for the transaction coordinator to wait for the transaction status update before actively aborting the ongoing transaction. This configuration value will be sent to the transaction coordinator together with InitPidRequest. If the value is greater than max.transaction.set in the proxy timeout. MS, the request will fail with an InvalidTransactionTimeout error. The default is 60000ms. This allows transactions not to block downstream consumption for more than one minute, which is usually allowed in real-time applications. |
| transactional.id | TransactionalId for transaction delivery. This supports reliability semantics across multiple producer sessions because it allows clients to ensure that transactions using the same TransactionalId have completed before starting any new transactions. If no TransactionalId is provided, the producer will be restricted to idempotent delivery. If transactional is configured ID attribute, then enable Idempotent will be set to true |
Consumer configs
| Configuration item | describe |
|---|---|
| isolation.level | (default is read_uncommitted) read_uncommitted: use submitted and uncommitted messages in offset order. read_committed: use only non transactional messages or transactional messages submitted in offset order. To maintain the offset order, this setting means that we must buffer messages in the consumer until we see all messages in a given transaction. |
Relationship between idempotency and transaction
The precondition for the implementation of transaction attribute is idempotency, that is, when configuring the transaction attribute transaction id, idempotency must also be configured; However, idempotency can be used independently without relying on transaction attributes.
- Idempotency introduces Porducer ID
- The Transaction Id attribute is introduced into the transaction attribute
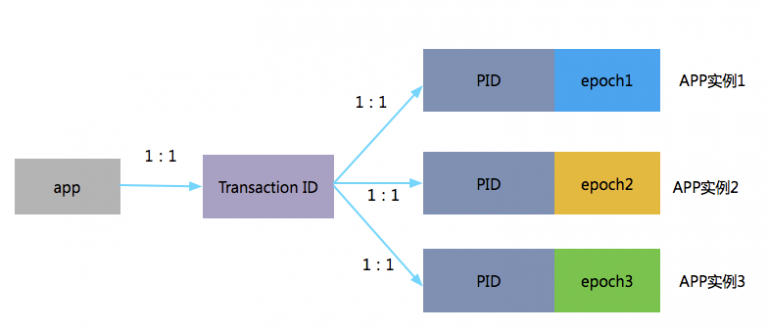
transactionalId, producerId and producepoch

An app has a tid. The PID of different instances of the same application is the same, but the value of epoch is different.
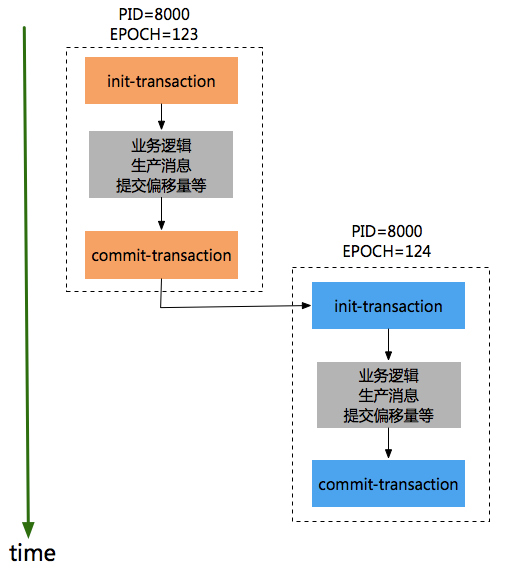
For the same transaction ID, first ensure that the producer with small epoch executes init transaction and commit transaction, and then the producer with large epoch can start executing init transaction and commit transaction, in the following order:
With transactionId, Kafka can guarantee:
Data idempotent transmission across sessions. When a new producer instance with the same Transaction ID is created and working, the old producer with the same Transaction ID will no longer work. kafka ensures that all producers associated with the same transaction (an application has multiple instances) must initialize, and commit transactions in order, otherwise there will be problems, which ensures that the messages in the same Transaction ID are orderly (different instances have to create and submit transactions in order).
Transaction settings for spring Kafka
Kafka is a data idempotent transmission across sessions, that is, if an application deploys multiple instances, it will often encounter "org.apache.kafka.common.errors.producerfencedexception: producer attempted an operation with an old epoch. Either there is a new producer with the same transactionalid, or the producer's transaction has been expired by the broker.", It is necessary to ensure that the commit transaction order of these instance generators is consistent with the creation order, otherwise they will not succeed. In fact, in practice, we focus more on how to realize the transaction of application single instance. You can learn from the spring kafaka implementation idea, that is, each time the creator sets a different transactionId value, as shown in the following code:
====================================
Class name: ProducerFactoryUtils
====================================
/**
* Obtain a Producer that is synchronized with the current transaction, if any.
* @param producerFactory the ConnectionFactory to obtain a Channel for
* @param <K> the key type.
* @param <V> the value type.
* @return the resource holder.
*/
public static <K, V> KafkaResourceHolder<K, V> getTransactionalResourceHolder(
final ProducerFactory<K, V> producerFactory) {
Assert.notNull(producerFactory, "ProducerFactory must not be null");
// 1. For each thread, a unique key will be generated, and then the resourceHolder will be found according to the key
@SuppressWarnings("unchecked")
KafkaResourceHolder<K, V> resourceHolder = (KafkaResourceHolder<K, V>) TransactionSynchronizationManager
.getResource(producerFactory);
if (resourceHolder == null) {
// 2. Create a consumer
Producer<K, V> producer = producerFactory.createProducer();
// 3. Start transaction
producer.beginTransaction();
resourceHolder = new KafkaResourceHolder<K, V>(producer);
bindResourceToTransaction(resourceHolder, producerFactory);
}
return resourceHolder;
}
In spring Kafka, a producer is created for a thread. After the transaction is committed, the producer will be closed and cleared. When the transaction is re executed by the same thread or a new thread, the producer will be re created.
Create consumer code
====================================
Class name: DefaultKafkaProducerFactory
====================================
protected Producer<K, V> createTransactionalProducer() {
Producer<K, V> producer = this.cache.poll();
if (producer == null) {
Map<String, Object> configs = new HashMap<>(this.configs);
// Each time a producer is generated, a different transactionId is set
configs.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,
this.transactionIdPrefix + this.transactionIdSuffix.getAndIncrement());
producer = new KafkaProducer<K, V>(configs, this.keySerializer, this.valueSerializer);
// 1. Initialize session transactions.
producer.initTransactions();
return new CloseSafeProducer<K, V>(producer, this.cache);
}
else {
return producer;
}
}
Flow chart of consumption transform produce
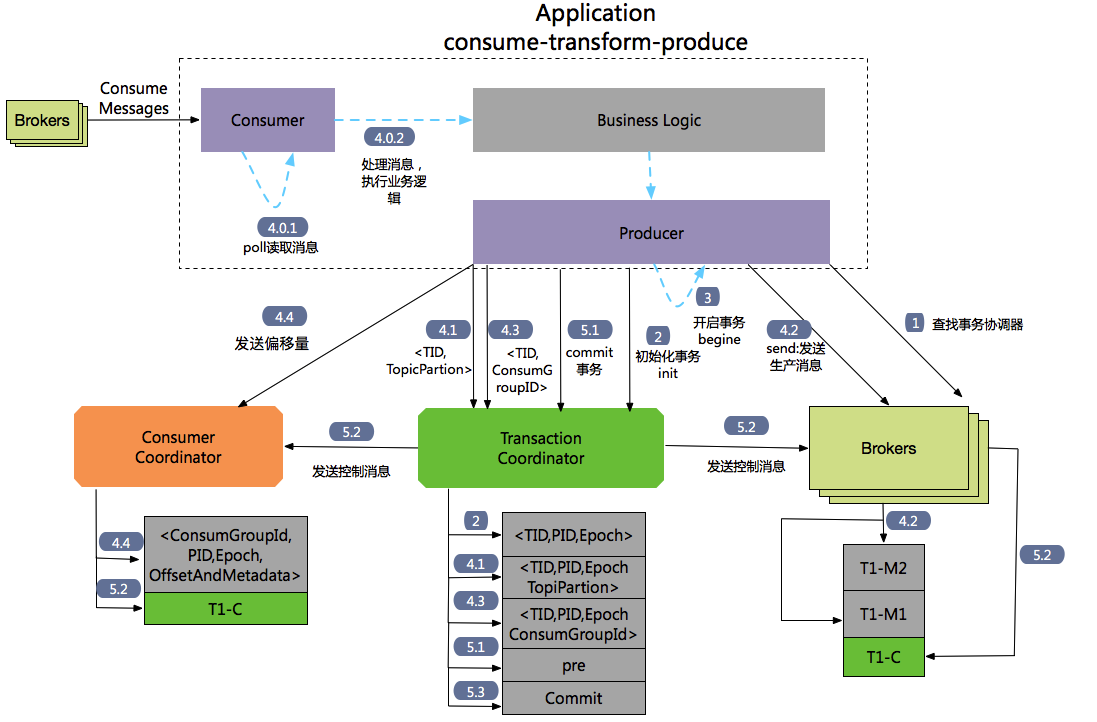
Process 1: find the transaction coordinator.
The Producer sends a findcoordinator request to any broker to obtain the address of the Transaction Coordinator.
Process 2: initialize transaction initTransaction
The Producer sends InitpidRequest to the transaction coordinator to obtain a PID. The processing of InitpidRequest is synchronously blocked. Once the call returns correctly, Producer can start a new transaction. TranactionalId is sent to the tranciton coordinator through InitpidRequest, and then the mapping relationship of < tranacionaldid, PID > is recorded in the Tranaciton Log. In addition to returning PID, it also has the following functions:
Increment the epoch corresponding to the PID to ensure that the PIDs corresponding to different instances of the same app are the same, but the epoch is different.
Roll back the unfinished transactions (if any) of the previous Producer.
Process 3: begin transaction
Execute the begin transaction () of the Producer, which is used to record the status of the transaction locally as the start status.
Note: this operation does not notify the Transaction Coordinator.
Process 4: consume transform produce loop
Process 4.0: consume messages through the consumer and process business logic
Process 4.1: producer sends AddPartitionsToTxnRequest to transactioncordiantro
When the producer executes the send operation, if it is the first time to send data to < topic, part >, it will send an AddPartitionsToTxnRequest request to the transaction coordinator, who will record the mapping relationship between the transaction ID and < topic, part > in the transaction log and change the status to begin. The data structure of AddPartionsToTxnRequest is as follows:
AddPartitionsToTxnRequest => TransactionalId PID Epoch [Topic [Partition]] TransactionalId => string PID => int64 Epoch => int16 Topic => string Partition => int32
Process 4.2: producer#send send ProduceRequst
The producer sends data. Although the commit or absrot has not been executed, the message has been saved to kafka at this time. Even if abort is executed later, the message will not be deleted, but the status field is changed to identify the message as abort status.
Process 4.3: AddOffsetCommitsToTxnRequest
Producer through kafkaproducer Sendoffsetstotransaction sends an AddOffesetCommitsToTxnRequests to the transaction coordinator:
AddOffsetsToTxnRequest => TransactionalId PID Epoch ConsumerGroupID TransactionalId => string PID => int64 Epoch => int16 ConsumerGroupID => string
When executing transaction submission, it can be inferred from ConsumerGroupID_ customer_offsets the corresponding topicparticles information in the topic. So in
Process 4.4: TxnOffsetCommitRequest
Producer through kafkaproducer Sendoffsetstotransaction also sends a TxnOffsetCommitRequest to the consumer coordinator, the consumer coordinator, in the subject_ consumer_ The offset information of the consumer is saved in offsets.
TxnOffsetCommitRequest => ConsumerGroupID
PID
Epoch
RetentionTime
OffsetAndMetadata
ConsumerGroupID => string
PID => int64
Epoch => int32
RetentionTime => int64
OffsetAndMetadata => [TopicName [Partition Offset Metadata]]
TopicName => string
Partition => int32
Offset => int64
Metadata => string
Process 5: transaction commit and transaction termination (abandon transaction)
Submit and terminate transactions through the producer's commitTransaction or abortTransaction methods. Both operations will send an EndTxnRequest to the Transaction Coordinator.
Process 5.1: EndTxnRequest. The Producer sends an EndTxnRequest to the Transaction Coordinator, and then performs the following operations:
- The Transaction Coordinator will PREPARE_COMMIT or PREPARE_ABORT
The message is written to the transaction log - Implementation process 5.2
- Implementation process 5.3
Process 5.2: WriteTxnMarkerRequest
WriteTxnMarkersRequest => [CoorinadorEpoch PID Epoch Marker [Topic [Partition]]] CoordinatorEpoch => int32 PID => int64 Epoch => int16 Marker => boolean (false(0) means ABORT, true(1) means COMMIT) Topic => string Partition => int32
- Messages for Producer production. The transaction coordinator will send WriteTxnMarkerRequest to each < topic, part > leader involved in the current transaction. After receiving the request, the leader will write a COMMIT(PID) or ABORT(PID) control information to the data log
- For consumer offset information, if it is included in this transaction_ Consumer offsets topic. Tranaction
The Coordinator will send WriteTxnMarkerRequest to the transaction Coordinator. After receiving the request, the transaction Coordinator will write a COMMIT(PID) or ABORT(PID) control information to the data log.
Process 5.3: the Transaction Coordinator will complete the final_ Commit or complete_ The abort message is written into the Transaction Log to indicate the end of the transaction.
- Only the PID and timstamp corresponding to this transaction will be retained. Then delete other relevant messages of the current transaction, including the mapping relationship between PID and tranactionId.
References:
- https://blog.csdn.net/weixin_44758876/article/details/120195566
- https://www.cnblogs.com/fnlingnzb-learner/p/13646390.html
- https://www.orchome.com/303
- https://blog.csdn.net/looo000ngname/article/details/107183144
- http://www.heartthinkdo.com/?p=2040#4
(the main source of the blog is the author's own knowledge and criticism. However, most of the blog's main sources are not easy to sort out and share. Thank you for your own knowledge and practice.)