Welcome to my Personal blog Learn more
transform
Function: convert the South data (source data) into the required data
Common functions
map
The map operator is similar to the map in python. In python, the data is converted into the data in lambda expression, while the map in flink is more extensive. Through a new Mapfunction, the user-defined map() method specifies the conversion process to convert one data type (input) to another data type (output)
The format is as follows
dataStream.map(new Mapfunction<input,output>(){
@Override
map(input){xxx};
})
It can be better understood by drawing

The rectangle becomes an ellipse, but the color does not change (logic does not change)
flatMap
flatmap flattening operator: convert input type into output type. Unlike map, flatmap outputs multiple output types
Take an example
String "hello,word"
Output in Tuple2("hello", 1) and Tuple2("word", 1)
inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(",");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
});
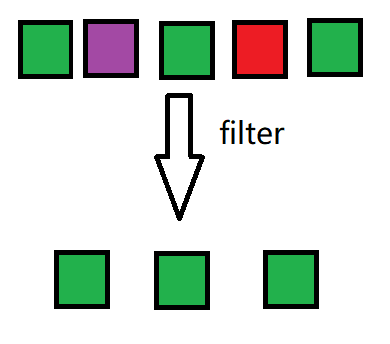
filter
The filter operator filters out input data of type input. Stay for true and filter out false
The illustration is as follows
keyby (Group)
DataStream → KeyedStream: logically split a stream into disjoint partitions. Each partition contains elements with the same key and is implemented internally in the form of hash.
use
dataStream.keyby(param)
param: data field subscripts start from 0 by default
You can also enter the field of id, which will be shunted according to the id
rolling Aggregation
- sum: sum
- max: select the maximum value for each flow
- min: select the minimum value of each flow
- minby: select the minimum value for a field data in keyedStream
- maxby: select the maximum value for a field data in keyedStream
reduce (complex aggregation)
KeyedStream → DataStream: merge the current element and the results of the last aggregation to generate a new value. The returned stream contains the results of each aggregation, rather than only the final results of the last aggregation.
Case: compare the temperature of the last time stamp according to the data transmitted from the sensor id, and select the time stamp data of the maximum temperature
import com.chengyuyang.apitest.SensorReading;
import com.chengyuyang.apitest.SourceFromCustom;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Transform_keyed_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// The data source is custom generated sensor data
DataStreamSource<SensorReading> inputDataStream = env.addSource(new SourceFromCustom.CustomSource());
//According to the data transmitted from the sensor id, compare the temperature of the last timestamp and select the timestamp data of the maximum temperature
SingleOutputStreamOperator<SensorReading> resultDataStream = inputDataStream.keyBy("id")
.reduce(new CustomReduceFunction());
resultDataStream.print();
env.execute();
}
public static class CustomReduceFunction implements ReduceFunction<SensorReading> {
@Override
public SensorReading reduce(SensorReading sensorReading, SensorReading input) throws Exception {
String id = sensorReading.getId();
Long timestamp = input.getTimestamp();
//Select the maximum temperature according to the time stamp
double temperature = Math.max(sensorReading.getTemperature(), input.getTemperature());
return new SensorReading(id, timestamp, temperature);
}
}
}
split and select
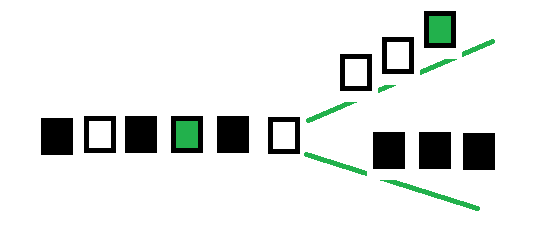
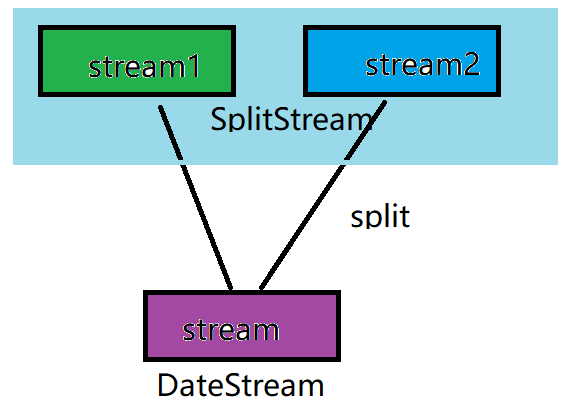
split
DataStream → SplitStream: split a DataStream into two or more datastreams according to some characteristics
The illustration is as follows
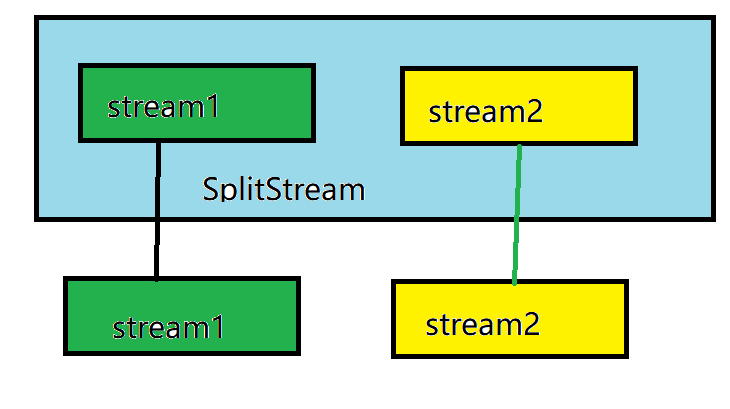
select
SplitStream → DataStream: obtain one or more datastreams from a SplitStream
The illustration is as follows
case
According to the temperature of the sensor, take 60 degrees as the standard, greater than or equal to 60 degrees is high flow, and others are low flow
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.chengyuyang.apitest.SensorReading;
import com.chengyuyang.apitest.SourceFromCustom;
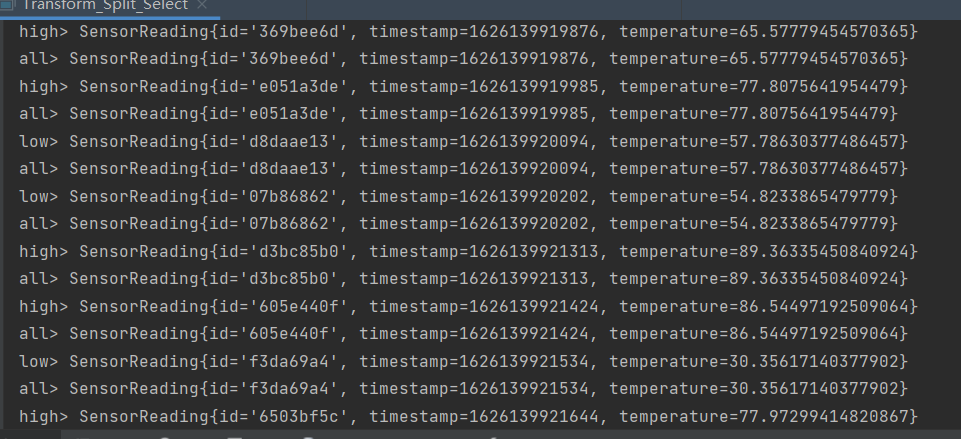
public class Transform_Split_Select {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<SensorReading> inputDatStream = env.addSource(new SourceFromCustom.CustomSource());
// split according to the temperature 60 standard is actually a select operation
SplitStream<SensorReading> splitStream = inputDatStream.split(new OutputSelector<SensorReading>() {
@Override
public Iterable<String> select(SensorReading sensorReading) {
Double temperature = sensorReading.getTemperature();
if (temperature >= 60) {
return Lists.newArrayList("high");
} else {
return Lists.newArrayList("low");
}
}
});
//SplitStream → DataStream operation the select variable can be multiple. The above two split s can be selected into three DataStream streams
DataStream<SensorReading> high = splitStream.select("high");
DataStream<SensorReading> low = splitStream.select("low");
DataStream<SensorReading> all = splitStream.select("high", "low");
high.print("high").setParallelism(1);
low.print("low").setParallelism(1);
all.print("all").setParallelism(1);
env.execute();
}
}
give the result as follows
connect and comap
connect (one country, two systems)
DataStream,DataStream → ConnectedStreams: connect two streams as ConnectedStreams, but keep their various data types unchanged. The internal two streams are independent of each other, and the input data types can be the same or different
The illustration is as follows

comap coflatmap
The functions of ConnectedStreams → DataStream are the same as those of map and flatMap, but because the data types of the two streams of connect class are different, map and flatMap should be processed for the streams inside, and the final results can be the same or different
case
According to the split and select cases, the high temperature is added with the warning tag, and the normal temperature data is output
Partial code
ConnectedStreams<Tuple2<String, Double>, SensorReading> connectDataStream = highDataStream.connect(lowDataStream);
SingleOutputStreamOperator<Object> resultDataStream = connectDataStream.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> input) throws Exception {
// Processing high temperature data
return new Tuple3<>(input.f0, input.f1, "warnning");
}
@Override
public Object map2(SensorReading input) throws Exception {
// Process normal temperature data
return new Tuple3<>(input.getId(), input.getTimestamp(), input.getTemperature());
}
});
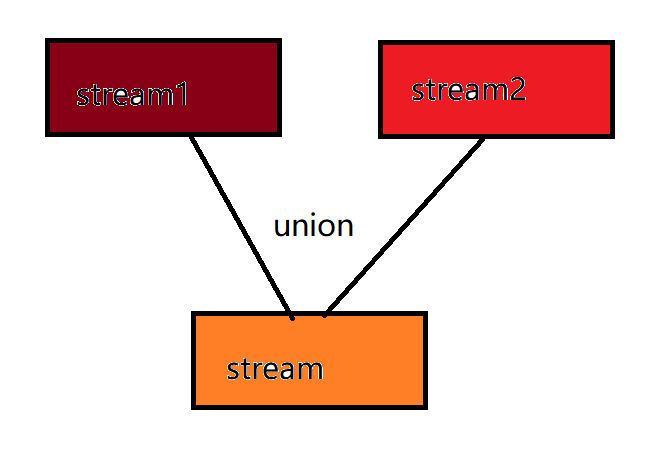
union
DataStream → DataStream performs union operation on two or more datastreams to generate a new DataStream containing all DataStream elements. Note: if you union a DataStream with itself, you will see that each element appears twice in the new DataStream
The illustration is as follows
What is the difference between Connect and Union
- Before Union, the types of the two streams must be the same, and Connect can be different
- Connect can be adjusted to be the same or different in the subsequent coMap
- Connect can only operate two streams, and Union can operate multiple streams
case
Conduct union according to the split and select cases, add warning label to the high temperature, and output the normal temperature data
Partial code
DataStream<SensorReading> unionDataStream = high.union(low);
SingleOutputStreamOperator<Tuple3<String, Long, Object>> resultDataStream = unionDataStream.map(new MapFunction<SensorReading, Tuple3<String, Long, Object>>() {
@Override
public Tuple3<String, Long, Object> map(SensorReading input) throws Exception {
if (input.getTemperature() >= 60) {
return new Tuple3<String, Long, Object>(input.getId(), input.getTimestamp(), "warnning");
} else {
return new Tuple3<String, Long, Object>(input.getId(), input.getTimestamp(), input.getTemperature());
}
}
});
This article is reproduced in my personal blog transform operator of Flink stream processing api
follow CC 4.0 BY-SA Copyright agreement