preface
Thesis address: arxiv
Code address: github
Receiver: NeurIPS 2021
Series articles
Transformer backbone - PVT_V1 nanny level resolution
Transformer backbone - PVT_V2 level parsing
Transformer backbone network -- T2T-ViT nanny level analysis
Transformer backbone network -- TNT nanny level analysis
Continuous update!
motivation
The author's starting point is also the deficiency of ViT's patch embedded (the pit left by ViT really leaves an opportunity for future generations to send papers...). The author compares a picture to an article. An article is composed of sentences and a sentence is composed of words. In the past, attention only modeled the relationship between sentences. The author believes that the relationship between words in sentences can not be ignored.
- Based on the above motivation, the author designs the structure of transformer in transformer, which is equivalent to transformer nesting. The inner transformer is used to model the attention between words in sentences, and the outer transformer is used to model the attention between sentences.
- Because the TNT nested transformer structure is introduced, the author designs the location coding for TNT.
network analysis
First, let's take a look at the complete structural diagram, which is derived from the author's paper:
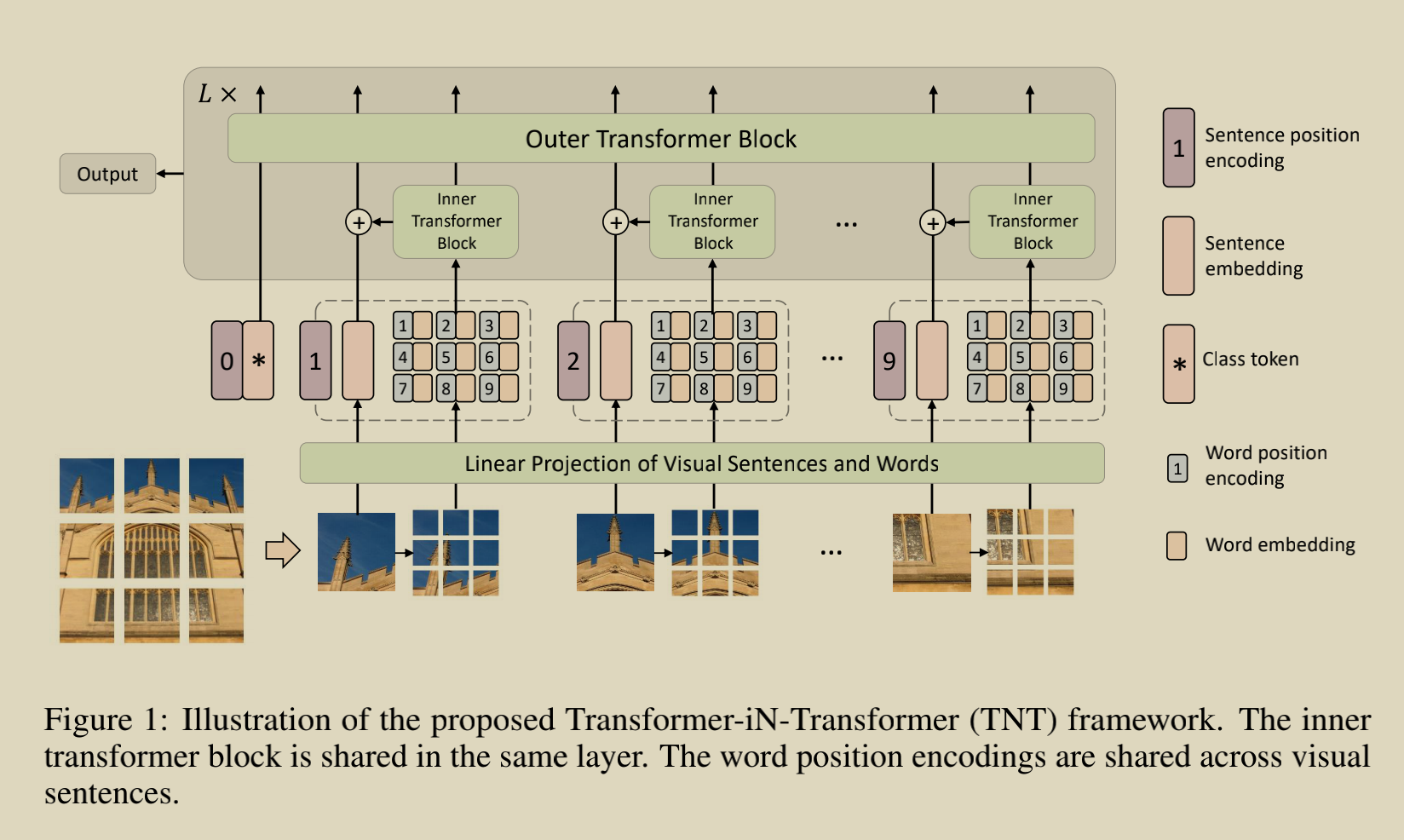
For the convenience of analysis, the data size input to the network in this paper is (1,322424)
1,For input 224 * 224 The author first executed the image nn.Unfold Operation: self.unfold = nn.Unfold(kernel_size=patch_size=16, stride=patch_size=16) # input_shape (1,3,224,224) x = self.unfold(x) # output_shape (1,768,196) Here 196=14*14,196 Indicates 16*16 of patch You can traverse 224*224 Times (224)/16 * 224/16) Then 768=16*16*3,The first two 16 are one patch The length and width of 3 are three channels of color. Equivalent to each patch of pixel Number. This step Unfold The "volume" process equivalent to convolution takes out all blocks with a sliding window.
Then corresponding to the image is the first step to divide the original image into many patch es:

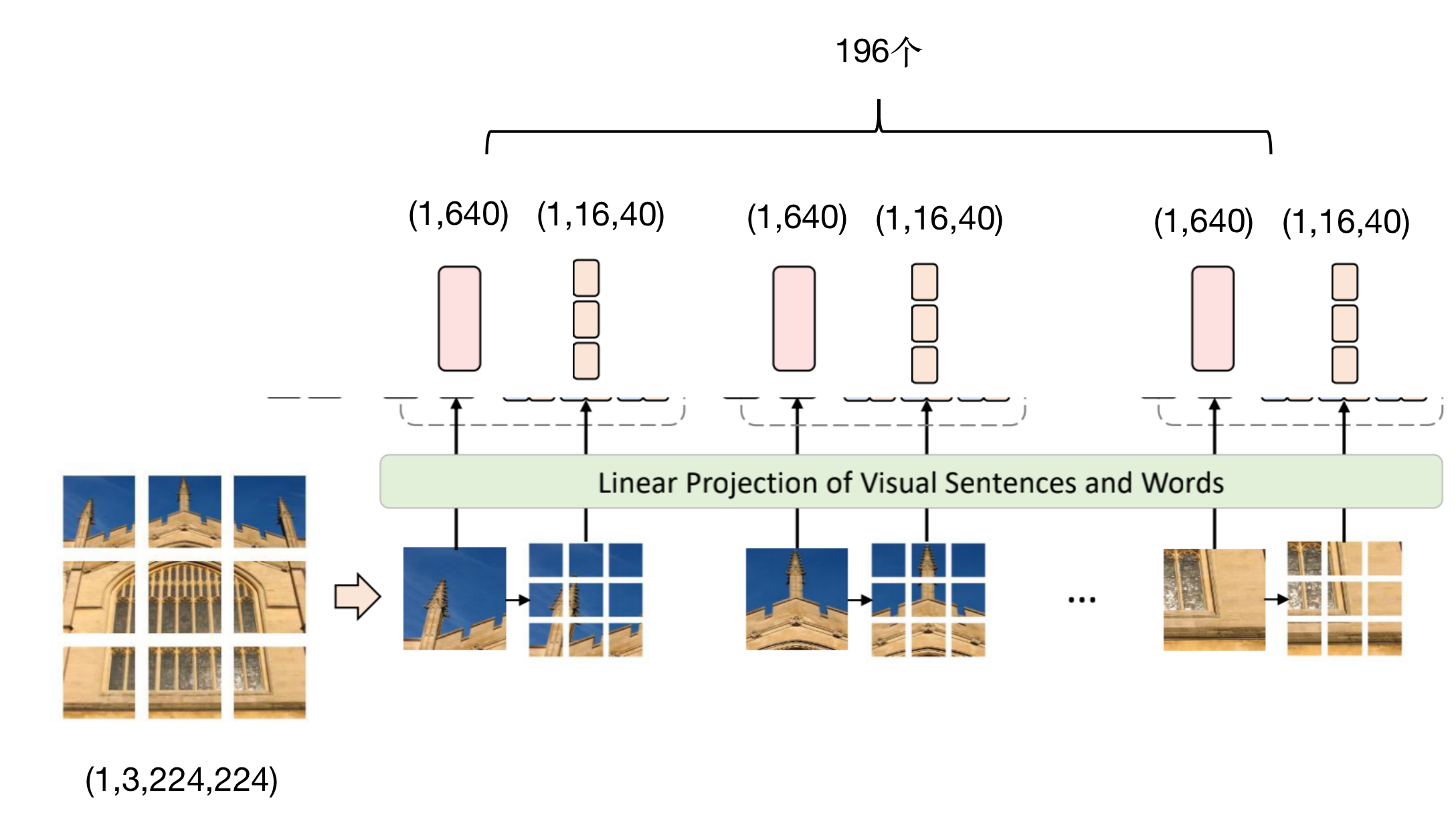
2,Picture to word level tokens: self.proj = nn.Conv2d(in_chans, inner_dim, kernel_size=7, padding=3, stride=inner_stride) # input_shape (1,196,768) x = x.transpose(1, 2).reshape(B * self.num_patches, C, *self.patch_size) # shape (196,3,16,16) x = self.proj(x) # shape (196,40,4,4) x = x.reshape(B * self.num_patches, self.inner_dim, -1).transpose(1, 2) # output_shape (196,16,40) (196,3,16,16) This is easy to understand. This is 196 patch,each patch It's colored, so it's 3 channels, and the length and width are 16 (196,40,4,4)This is the result of convolution (196,16,40)It is a deformed structure. It can be understood that a picture has 196 sentence levels tokens,Of each sentence level token There are 16 word levels tokens,Per word level token of dim It's 40.
The above operations get word level tokens, corresponding to all the circled parts in the figure:
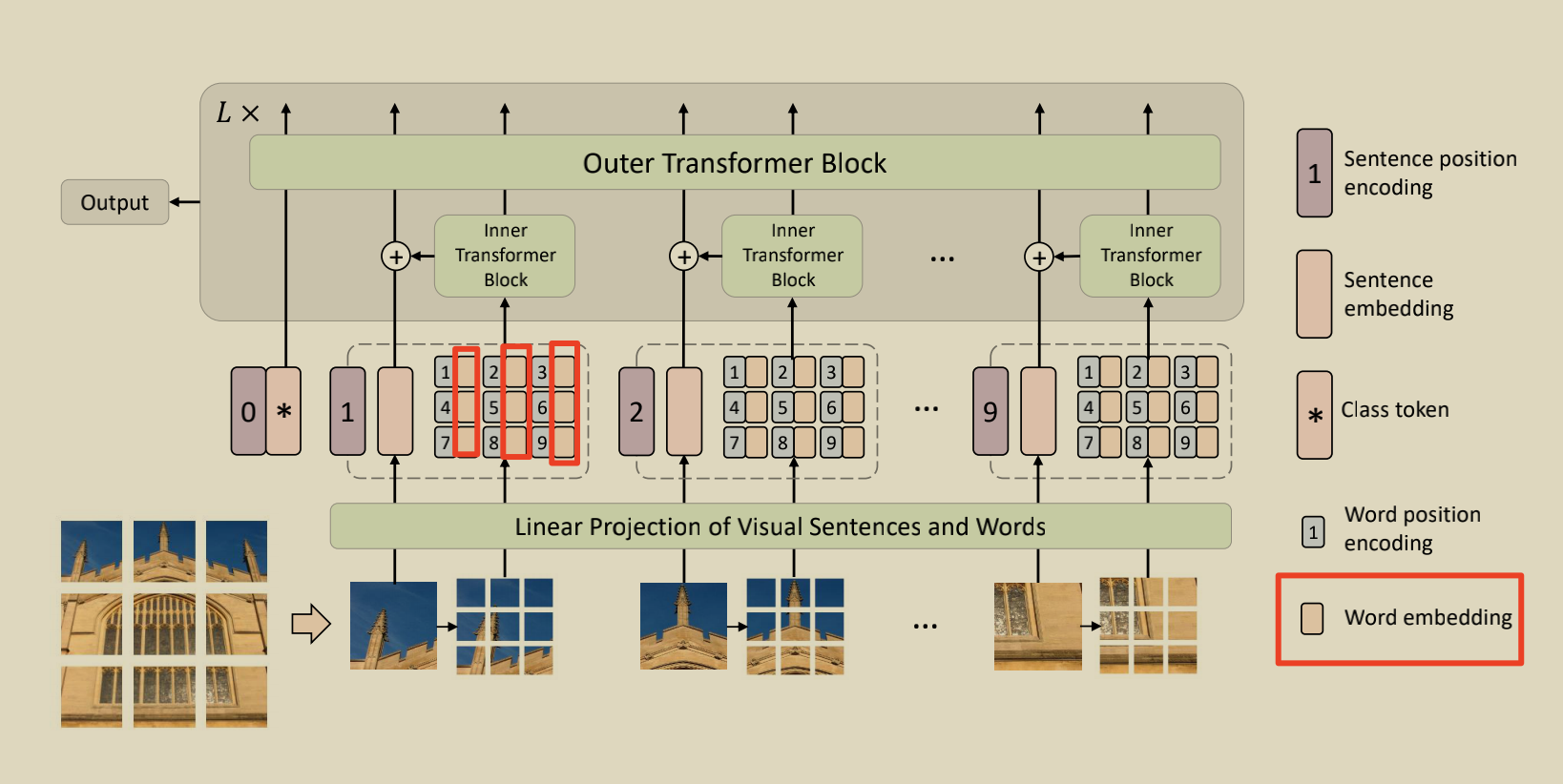
3,Word level tokens Matrix plus location code: inner_tokens = self.patch_embed(x) + self.inner_pos Bitwise addition shape unchanged! this inner_pos and ViT The same, hard training a location code.
4,Picture to sentence level tokens: Because there are word level tokens So sentence level tokens Can be directly determined by word level tokens form: self.proj_norm1 = norm_layer(num_words * inner_dim) self.proj = nn.Linear(num_words * inner_dim, outer_dim) self.proj_norm2 = norm_layer(outer_dim) # input_shape (196, 16, 40) outer_tokens = self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, self.num_patches, -1)))) # output_shape (1, 196, 640) (1, 196, 640)It's a picture of 196 sentence levels tokens Composition, each tokens of dim It's 640
Then the above completes the most important part of this paper, which consists of sentence level tokens and word level tokens! Corresponding figure:
5,Sentence level tokens Splice heads are used for classification: # input_shape (1,196,640) outer_tokens = torch.cat((self.cls_token.expand(B, -1, -1), outer_tokens), dim=1) # output_shape (1,197,640)

6,Sentence level tokens Matrix plus location code: outer_tokens = outer_tokens + self.outer_pos Bitwise addition shape unchanged! this outer_pos and ViT The same, hard training a location code. outer_tokens = self.pos_drop(outer_tokens) plus drop path
7,The next step is to word tokens and sentence tokens Delivered together block In, this block and ViT of block The same, but because there are two kinds of output here tokens, So there are some changes. Look at the picture! whole block The return is the two parts circled in red!
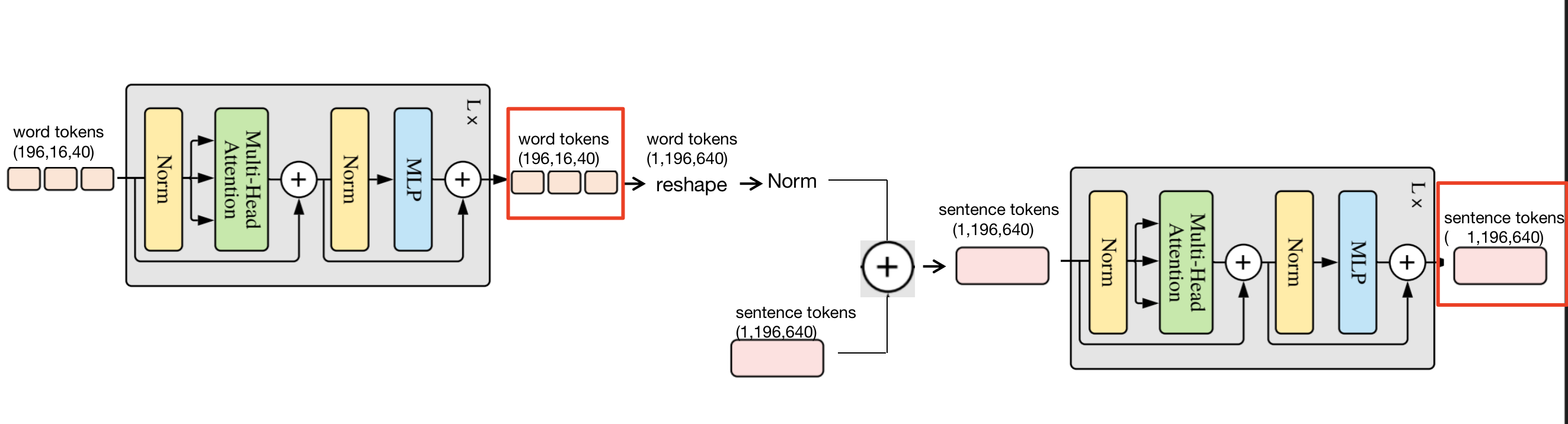
Sprinkle flowers at the end~
No matter how good the model is, it has to stand the test of business. The experimental results on its own data set will be updated later
Complete test code
# 2021.06.15-Changed for implementation of TNT model
# Huawei Technologies Co., Ltd. <foss@huawei.com>
""" Vision Transformer (ViT) in PyTorch
A PyTorch implement of Vision Transformers as described in
'An Image Is Worth 16 x 16 Words: Transformers for Image Recognition at Scale' - https://arxiv.org/abs/2010.11929
The official jax code is released and available at https://github.com/google-research/vision_transformer
Status/TODO:
* Models updated to be compatible with official impl. Args added to support backward compat for old PyTorch weights.
* Weights ported from official jax impl for 384x384 base and small models, 16x16 and 32x32 patches.
* Trained (supervised on ImageNet-1k) my custom 'small' patch model to 77.9, 'base' to 79.4 top-1 with this code.
* Hopefully find time and GPUs for SSL or unsupervised pretraining on OpenImages w/ ImageNet fine-tune in future.
Acknowledgments:
* The paper authors for releasing code and weights, thanks!
* I fixed my class token impl based on Phil Wang's https://github.com/lucidrains/vit-pytorch ... check it out
for some einops/einsum fun
* Simple transformer style inspired by Andrej Karpathy's https://github.com/karpathy/minGPT
* Bert reference code checks against Huggingface Transformers and Tensorflow Bert
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
import torch.nn as nn
from functools import partial
import math
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'tnt_s_patch16_224': _cfg(
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'tnt_b_patch16_224': _cfg(
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
}
def make_divisible(v, divisor=8, min_value=None):
min_value = min_value or divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class SE(nn.Module):
def __init__(self, dim, hidden_ratio=None):
super().__init__()
hidden_ratio = hidden_ratio or 1
self.dim = dim
hidden_dim = int(dim * hidden_ratio)
self.fc = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, dim),
nn.Tanh()
)
def forward(self, x):
a = x.mean(dim=1, keepdim=True) # B, 1, C
a = self.fc(a)
x = a * x
return x
class Attention(nn.Module):
def __init__(self, dim, hidden_dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
def forward(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape(B, N, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k = qk[0], qk[1] # make torchscript happy (cannot use tensor as tuple)
v = self.v(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
""" TNT Block
"""
def __init__(self, outer_dim, inner_dim, outer_num_heads, inner_num_heads, num_words, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, se=0):
super().__init__()
self.has_inner = inner_dim > 0
if self.has_inner:
# Inner
self.inner_norm1 = norm_layer(inner_dim)
self.inner_attn = Attention(
inner_dim, inner_dim, num_heads=inner_num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.inner_norm2 = norm_layer(inner_dim)
self.inner_mlp = Mlp(in_features=inner_dim, hidden_features=int(inner_dim * mlp_ratio),
out_features=inner_dim, act_layer=act_layer, drop=drop)
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim, bias=False)
self.proj_norm2 = norm_layer(outer_dim)
# Outer
self.outer_norm1 = norm_layer(outer_dim)
self.outer_attn = Attention(
outer_dim, outer_dim, num_heads=outer_num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.outer_norm2 = norm_layer(outer_dim)
self.outer_mlp = Mlp(in_features=outer_dim, hidden_features=int(outer_dim * mlp_ratio),
out_features=outer_dim, act_layer=act_layer, drop=drop)
# SE
self.se = se
self.se_layer = None
if self.se > 0:
self.se_layer = SE(outer_dim, 0.25)
def forward(self, inner_tokens, outer_tokens):
if self.has_inner:
print(inner_tokens.shape)
inner_tokens = inner_tokens + self.drop_path(self.inner_attn(self.inner_norm1(inner_tokens))) # B*N, k*k, c
print(inner_tokens.shape)
inner_tokens = inner_tokens + self.drop_path(self.inner_mlp(self.inner_norm2(inner_tokens))) # B*N, k*k, c
print(inner_tokens.shape)
B, N, C = outer_tokens.size()
print(inner_tokens.reshape(B, N - 1, -1).shape)
outer_tokens[:, 1:] = outer_tokens[:, 1:] + self.proj_norm2(
self.proj(self.proj_norm1(inner_tokens.reshape(B, N - 1, -1)))) # B, N, C
if self.se > 0:
outer_tokens = outer_tokens + self.drop_path(self.outer_attn(self.outer_norm1(outer_tokens)))
tmp_ = self.outer_mlp(self.outer_norm2(outer_tokens))
outer_tokens = outer_tokens + self.drop_path(tmp_ + self.se_layer(tmp_))
else:
outer_tokens = outer_tokens + self.drop_path(self.outer_attn(self.outer_norm1(outer_tokens)))
outer_tokens = outer_tokens + self.drop_path(self.outer_mlp(self.outer_norm2(outer_tokens)))
return inner_tokens, outer_tokens
class PatchEmbed(nn.Module):
""" Image to Visual Word Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, outer_dim=768, inner_dim=24, inner_stride=4):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.inner_dim = inner_dim
self.num_words = math.ceil(patch_size[0] / inner_stride) * math.ceil(patch_size[1] / inner_stride)
self.unfold = nn.Unfold(kernel_size=patch_size, stride=patch_size)
self.proj = nn.Conv2d(in_chans, inner_dim, kernel_size=7, padding=3, stride=inner_stride)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
print(x.shape)
x = self.unfold(x) # B, Ck2, N
print(x.shape)
x = x.transpose(1, 2).reshape(B * self.num_patches, C, *self.patch_size) # B*N, C, 16, 16
print(x.shape)
x = self.proj(x) # B*N, C, 8, 8
print(x.shape)
x = x.reshape(B * self.num_patches, self.inner_dim, -1).transpose(1, 2) # B*N, 8*8, C
print(x.shape)
return x
class TNT(nn.Module):
""" TNT (Transformer in Transformer) for computer vision
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, outer_dim=768, inner_dim=48,
depth=12, outer_num_heads=12, inner_num_heads=4, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm, inner_stride=4, se=0):
super().__init__()
self.num_classes = num_classes
self.num_features = self.outer_dim = outer_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, outer_dim=outer_dim,
inner_dim=inner_dim, inner_stride=inner_stride)
self.num_patches = num_patches = self.patch_embed.num_patches
num_words = self.patch_embed.num_words
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim)
self.proj_norm2 = norm_layer(outer_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, outer_dim))
self.outer_tokens = nn.Parameter(torch.zeros(1, num_patches, outer_dim), requires_grad=False)
self.outer_pos = nn.Parameter(torch.zeros(1, num_patches + 1, outer_dim))
self.inner_pos = nn.Parameter(torch.zeros(1, num_words, inner_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
vanilla_idxs = []
blocks = []
for i in range(depth):
if i in vanilla_idxs:
blocks.append(Block(
outer_dim=outer_dim, inner_dim=-1, outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, se=se))
else:
blocks.append(Block(
outer_dim=outer_dim, inner_dim=inner_dim, outer_num_heads=outer_num_heads,
inner_num_heads=inner_num_heads,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, se=se))
self.blocks = nn.ModuleList(blocks)
self.norm = norm_layer(outer_dim)
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
# self.repr = nn.Linear(outer_dim, representation_size)
# self.repr_act = nn.Tanh()
# Classifier head
self.head = nn.Linear(outer_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
trunc_normal_(self.outer_pos, std=.02)
trunc_normal_(self.inner_pos, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'outer_pos', 'inner_pos', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.outer_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
inner_tokens = self.patch_embed(x) + self.inner_pos # B*N, 8*8, C
outer_tokens = self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, self.num_patches, -1))))
outer_tokens = torch.cat((self.cls_token.expand(B, -1, -1), outer_tokens), dim=1)
outer_tokens = outer_tokens + self.outer_pos
outer_tokens = self.pos_drop(outer_tokens)
for blk in self.blocks:
inner_tokens, outer_tokens = blk(inner_tokens, outer_tokens)
outer_tokens = self.norm(outer_tokens)
return outer_tokens[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def tnt_s_patch16_224(pretrained=False, **kwargs):
patch_size = 16
inner_stride = 4
outer_dim = 384
inner_dim = 24
outer_num_heads = 6
inner_num_heads = 4
outer_dim = make_divisible(outer_dim, outer_num_heads)
inner_dim = make_divisible(inner_dim, inner_num_heads)
model = TNT(img_size=224, patch_size=patch_size, outer_dim=outer_dim, inner_dim=inner_dim, depth=12,
outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads, qkv_bias=False,
inner_stride=inner_stride, **kwargs)
model.default_cfg = default_cfgs['tnt_s_patch16_224']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def tnt_b_patch16_224(pretrained=False, **kwargs):
patch_size = 16
inner_stride = 4
outer_dim = 640
inner_dim = 40
outer_num_heads = 10
inner_num_heads = 4
outer_dim = make_divisible(outer_dim, outer_num_heads)
inner_dim = make_divisible(inner_dim, inner_num_heads)
model = TNT(img_size=224, patch_size=patch_size, outer_dim=outer_dim, inner_dim=inner_dim, depth=12,
outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads, qkv_bias=False,
inner_stride=inner_stride, **kwargs)
model.default_cfg = default_cfgs['tnt_b_patch16_224']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
if __name__ == '__main__':
model = tnt_b_patch16_224(pretrained=False)
input = torch.randn((1,3,224,224))
output = model(input)
print(output.shape)