PyTorch chapter of Transformer source code interpretation
chapter
Insert picture description here
Transformer is essentially an Encoder. Taking the translation task as an example, the original data set is composed of one line in two languages. In application, it should be the Encoder to input the source language sequence, and the Decoder to input the language sequence to be converted (during training). A text is often composed of many sequences. The common operation is to preprocess the sequence (such as word segmentation) into a list. The elements of a sequence list are usually the smallest words that cannot be segmented in the vocabulary. The whole text is a large list, and the elements are a list composed of sequences. For example, a sequence becomes ["am", "##ro", "##zi", "captured", "his", "father"] after segmentation, and then it is converted according to their corresponding indexes in the thesaurus. The hypothetical results are as follows [23, 94, 13, 41, 27, 96]. If there are 100 sentences in the whole text, then there are 100 lists as its elements. Because the length of each sequence is different, the maximum length needs to be set. Here, it might as well be set to 128. After converting the whole text into an array, the shape is 100 x 128, which corresponds to batch_size and seq_length.
After input, word embedding is followed by word embedding. Word embedding is to map each word with a pre trained vector. The parameters are the size of the word list and the dimension of the mapped vector. Generally speaking, it is how many numbers are in the vector. Note that the first parameter is the size of the word list. If you currently have four words, fill in 4. If you enter words different from these four words later, you need to remap. In order to unify, you also need to remap at the beginning. Therefore, the total size of the word list here. If we plan to map to 512 dimensions (num_features or embedded_dim), the shape of the whole text becomes 100 x 128 x 512. Let's take a small example to explain: suppose our vocabulary has 10 words in total, there are 2 sentences in the text, and each sentence has 4 words. We want to map each word to an 8-dimensional vector. Thus, 2, 4 and 8 correspond to batch_size, seq_length, embed_dim (if batch is in the first dimension).
In addition, general deep learning tasks only change num_features, so the dimension is generally aimed at the dimension of the last feature.
Import of all required packages:
import torch import torch.nn as nn from torch.nn.parameter import Parameter from torch.nn.init import xavier_uniform_ from torch.nn.init import constant_ from torch.nn.init import xavier_normal_ import torch.nn.functional as F from typing import Optional, Tuple, Any from typing import List, Optional, Tuple import math import warnings
X = torch.zeros((2,4),dtype=torch.long) embed = nn.Embedding(10,8) print(embed(X).shape) # torch.Size([2, 4, 8])
Word embedding is followed by position coding, which is used to distinguish the relationship between different words and different features of the same word. Note in the code: X_ It is only an initialized matrix, which is not input; After the location coding is completed, a dropout will be added. In addition, the position code is added last, so the input and output shape remains unchanged.
Tensor = torch.Tensor
def positional_encoding(X, num_features, dropout_p=0.1, max_len=512) -> Tensor:
r'''
Add location code to input
Parameters:
- num_features: Input dimension
- dropout_p: dropout The probability of execution when it is non-zero dropout
- max_len: The maximum length of a sentence, 512 by default
Shape:
- Input: [batch_size, seq_length, num_features]
- Output: [batch_size, seq_length, num_features]
example:
>>> X = torch.randn((2,4,10))
>>> X = positional_encoding(X, 10)
>>> print(X.shape)
>>> torch.Size([2, 4, 10])
'''
dropout = nn.Dropout(dropout_p)
P = torch.zeros((1,max_len,num_features))
X_ = torch.arange(max_len,dtype=torch.float32).reshape(-1,1) / torch.pow(
10000,
torch.arange(0,num_features,2,dtype=torch.float32) /num_features)
P[:,:,0::2] = torch.sin(X_)
P[:,:,1::2] = torch.cos(X_)
X = X + P[:,:X.shape[1],:].to(X.device)
return dropout(X)
Bull attention is roughly divided into three parts: parameter initialization, where Q, K and V come from, occlusion mechanism and dot product attention
- Initialization parameters
query, key and value are obtained by multiplying the source language sequence (src in this paper) by the corresponding matrix. Then, where do those matrices come from (note that most codes are extracted from the source code, so they often have self and so on. Finally, the well composed ones will be presented, but the whole structure will not be presented in the writing process):
if self._qkv_same_embed_dim is False:
# The shape remains unchanged before and after initialization
# (seq_length x embed_dim) x (embed_dim x embed_dim) ==> (seq_length x embed_dim)
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
# Later, the attention of all heads will be spliced together, and then multiplied by the weight matrix output
# out_proj is for later preparation
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
torch.empty is to form the corresponding tensor according to the given shape. It is characterized by the fact that the filled value has not been initialized. It is similar to torch Randn (standard normal distribution), which is a way of initialization. In PyTorch, if the variable type is tensor, the value cannot be modified, while the Parameter() function can be regarded as a type conversion function to convert the non modifiable tensor into a trainable and modifiable model parameter, that is, the same as model Parameters are bound together, register_parameter means whether to put this parameter into model Parameters, None means there is no such parameter.
Here is an if judgment to judge whether the last dimension of Q, K and V is consistent. If it is consistent, a large weight matrix will be multiplied and divided. If not, each initialization will not change the original shape (e.g q = q W q + b q q=qW_q+b_q q=qWq + bq, see note).
You can find the last one_ reset_parameters() function, which is used to initialize parameter values. xavier_uniform means from Continuous uniform distribution The value is randomly sampled as the initialization value, xavier_normal_ The distribution of samples is normal. Because the initialization value is very important in training neural network, these two functions are needed.
constant_ It means to fill the input vector with the given value.
In addition, in the source code of PyTorch, it seems that projection represents a linear transformation, in_proj_bias means the offset of the linear transformation at the beginning
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
The above is the parameter initialization process, followed by the assignment of query,key and value
- q. Where does K, V come from?
For NN functional. Linear function is actually a linear transformation, and NN Unlike linear, the former can provide weight matrix and offset to perform y = x W T + b y=xW^T+b y=xWT+b, the latter is the dimension that can freely determine the output, because the linear function is called in multiple layers and has little meaning, which is omitted here.
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
r"""
Linear transformation with a large weight parameter matrix
parameter:
q, k, v: For self attention, all three are src;about seq2seq Model, k and v Is consistent tensor.
But their last dimension(num_features Or called embed_dim)Must be consistent.
w: Large matrix for linear transformation, according to q,k,v The order is pressed in one tensor Inside.
b: Offset for linear transformation, according to q,k,v The order is pressed in one tensor Inside.
shape:
input:
- q: shape:`(..., E)`,E Is the dimension of word embedding (shown below) E All for this purpose).
- k: shape:`(..., E)`
- v: shape:`(..., E)`
- w: shape:`(E * 3, E)`
- b: shape:`E * 3`
output:
- Output list :`[q', k', v']`,q,k,v The shape is consistent before and after linear transformation.
"""
E = q.size(-1)
# If it is self attention, then q = k = v = src, so their reference variables are src
# That is, the results of k is v and q is k are True
# If it is seq2seq, k = v, so the result of k is v is True
if k is v:
if q is k:
return F.linear(q, w, b).chunk(3, dim=-1)
else:
# seq2seq model
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
return (F.linear(q, w_q, b_q),) + F.linear(k, w_kv, b_kv).chunk(2, dim=-1)
else:
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return F.linear(q, w_q, b_q), F.linear(k, w_k, b_k), F.linear(v, w_v, b_v)
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
- Occlusion mechanism
For Attn_ For mask, if it is 2D, the shape is (L, S). L and S represent the length of target language and source language sequence respectively. If it is 3D, the shape is (N * num_heads, L, S), and N represents batch_size,num_ Heads stands for the number of attention heads. If it is ByteTensor, positions other than 0 will be ignored and no attention will be paid; If it is BoolTensor, the position corresponding to True will be ignored; If it is a numerical value, it will be directly added to attn_weights.
When the decoder decodes, it can only look at the position and the position before it. If it looks at the back, it will be a foul, so Attn is required_ Mask.
The following function directly copies PyTorch, which means to ensure that the mask shapes of different dimensions are correct and different types of transformations
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
# Shape judgment of different dimensions
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
And Attn_ The difference between mask and key_padding_mask is used to mask the value in the key. In detail, it should be < pad >. The ignored case is the same as attn_mask is consistent.
# Will key_ padding_ Change mask value to Boolean value
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
First introduce two small functions, logical_or, enter two tensors and perform logical or operation on the values in the two tensors. It is False only when both values are 0, True at other times, and masked_fill, the input is a mask, and the value to fill in. The mask consists of 1 and 0. The position value of 0 remains unchanged, and the position of 1 is filled with new values.
a = torch.tensor([0,1,10,0],dtype=torch.int8) b = torch.tensor([4,0,1,0],dtype=torch.int8) print(torch.logical_or(a,b)) # tensor([ True, True, True, False])
r = torch.tensor([[0,0,0,0],[0,0,0,0]]) mask = torch.tensor([[1,1,1,1],[0,0,0,0]]) print(r.masked_fill(mask,1)) # tensor([[1, 1, 1, 1], # [0, 0, 0, 0]])
Actually, attn_mask and key_ padding_ Sometimes the objects of the mask are the same, so sometimes they can be viewed together- The value of inf after softmax is 0, which is ignored.
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
# If attn_mask is empty. Use key directly_ padding_ mask
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# If Attn_ If the mask value is Boolean, the mask is converted to float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
- Dot product attention
from typing import Optional, Tuple, Any
def scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
r'''
stay query, key, value Calculate the dot product attention on the. If there is attention masking, use it, and apply a probability of dropout_p of dropout
Parameters:
- q: shape:`(B, Nt, E)` B representative batch size, Nt Is the length of the target language sequence, E Is the embedded feature dimension
- key: shape:`(B, Ns, E)` Ns Is the length of the source language sequence
- value: shape:`(B, Ns, E)`And key Same shape
- attn_mask: Or three D of tensor,Shape is:`(B, Nt, Ns)`Or 2 D of tensor,Shape such as:`(Nt, Ns)`
- Output: attention values: shape:`(B, Nt, E)`,And q Consistent shape;attention weights: shape:`(B, Nt, Ns)`
example:
>>> q = torch.randn((2,3,6))
>>> k = torch.randn((2,4,6))
>>> v = torch.randn((2,4,6))
>>> out = scaled_dot_product_attention(q, k, v)
>>> out[0].shape, out[1].shape
>>> torch.Size([2, 3, 6]) torch.Size([2, 3, 4])
'''
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2,-1))
if attn_mask is not None:
attn += attn_mask
# attn means that each word of the target sequence pays attention to the source language sequence
attn = F.softmax(attn, dim=-1)
if dropout_p:
attn = F.dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output, attn
Next, connect the three parts:
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
num_heads: int,
in_proj_weight: Tensor,
in_proj_bias: Optional[Tensor],
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_seperate_proj_weight = None,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
) -> Tuple[Tensor, Optional[Tensor]]:
r'''
Shape:
Input:
- query: `(L, N, E)`
- key: `(S, N, E)`
- value: `(S, N, E)`
- key_padding_mask: `(N, S)`
- attn_mask: `(L, S)` or `(N * num_heads, L, S)`
Output:
- attn_output:`(L, N, E)`
- attn_output_weights:`(N, L, S)`
'''
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
head_dim = embed_dim // num_heads
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
# reshape q,k,v place the Batch in the first dimension to fit the dot product
# At the same time, it is a multi head mechanism, which puts different heads together to form a layer
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
k = k.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
v = v.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# If Attn_ If the mask value is Boolean, the mask is converted to float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
# dropout is applied only when training is True
if not training:
dropout_p = 0.0
attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
if need_weights:
# average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
return attn_output, attn_output_weights.sum(dim=1) / num_heads
else:
return attn_output, None
Next, build the MultiheadAttention class
class MultiheadAttention(nn.Module):
r'''
Parameters:
embed_dim: Dimension of word embedding
num_heads: Number of parallel heads
batch_first: if`True`,Then(batch, seq, feture),if it is`False`,Then(seq, batch, feature)
example:
>>> multihead_attn = MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
'''
def __init__(self, embed_dim, num_heads, dropout=0., bias=True,
kdim=None, vdim=None, batch_first=False) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
if self._qkv_same_embed_dim is False:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:
xavier_normal_(self.bias_k)
if self.bias_v is not None:
xavier_normal_(self.bias_v)
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None) -> Tuple[Tensor, Optional[Tensor]]:
if self.batch_first:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
if not self._qkv_same_embed_dim:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
if self.batch_first:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
Next, you can practice it and add up the position coding. It can be found that the shape before and after adding position coding and multi head attention will not change
# Because batch_first is False, so src shape: ` (SEQ, batch, embedded_dim)` src = torch.randn((2,4,100)) src = positional_encoding(src,100,0.1) print(src.shape) multihead_attn = MultiheadAttention(100, 4, 0.1) attn_output, attn_output_weights = multihead_attn(src,src,src) print(attn_output.shape, attn_output_weights.shape) # torch.Size([2, 4, 100]) # torch.Size([2, 4, 100]) torch.Size([4, 2, 2])
- Encoder Layer
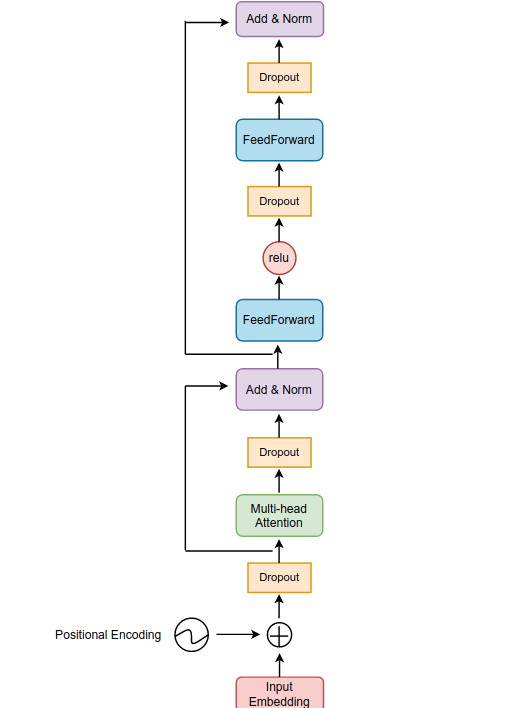
class TransformerEncoderLayer(nn.Module):
r'''
Parameters:
d_model: Dimension of word embedding (required)
nhead: Number of parallel heads in long attention (required)
dim_feedforward: The number of neurons in the whole connection layer, also known as the dimension input through this layer( Default = 2048)
dropout: dropout Probability of( Default = 0.1)
activation: Activation function between two linear layers, default relu or gelu
lay_norm_eps: layer normalization To prevent the denominator from being 0( Default = 1e-5)
batch_first: if`True`,Then(batch, seq, feture),if it is`False`,Then(seq, batch, feature)(Default: False)
example:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> src = torch.randn((32, 10, 512))
>>> out = encoder_layer(src)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = activation
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout(src2)
src = self.norm2(src)
return src
Take a look at it with a small example
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8) src = torch.randn((32, 10, 512)) out = encoder_layer(src) print(out.shape) # torch.Size([32, 10, 512])
- Encoder
class TransformerEncoder(nn.Module):
r'''
Parameters:
encoder_layer((mandatory)
num_layers: encoder_layer Number of layers (required)
norm: Selection of normalization (optional)
example:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.randn((10, 32, 512))
>>> out = transformer_encoder(src)
'''
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layer = encoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = positional_encoding(src, src.shape[-1])
for _ in range(self.num_layers):
output = self.layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
Take a look at it with a small example
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8) transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6) src = torch.randn((10, 32, 512)) out = transformer_encoder(src) print(out.shape) # torch.Size([10, 32, 512])
- Decoder Layer:
class TransformerDecoderLayer(nn.Module):
r'''
Parameters:
d_model: Dimension of word embedding (required)
nhead: Number of parallel heads in long attention (required)
dim_feedforward: The number of neurons passing through this dimension is also known as the number of neurons passing through this dimension( Default = 2048)
dropout: dropout Probability of( Default = 0.1)
activation: Activation function between two linear layers, default relu or gelu
lay_norm_eps: layer normalization To prevent the denominator from being 0( Default = 1e-5)
batch_first: if`True`,Then(batch, seq, feture),if it is`False`,Then(seq, batch, feature)(Default: False)
example:
>>> decoder_layer = TransformerDecoderLayer(d_model=512, nhead=8)
>>> memory = torch.randn((10, 32, 512))
>>> tgt = torch.randn((20, 32, 512))
>>> out = decoder_layer(tgt, memory)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm3 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = activation
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
Parameters:
tgt: Target language sequence (required)
memory: From the last encoder_layer Running sentences (required)
tgt_mask: Target language sequence mask((optional)
memory_mask((optional)
tgt_key_padding_mask((optional)
memory_key_padding_mask((optional)
'''
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
Take a look at it with a small example
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8) memory = torch.randn((10, 32, 512)) tgt = torch.randn((20, 32, 512)) out = decoder_layer(tgt, memory) print(out.shape) # torch.Size([20, 32, 512])
- Decoder
class TransformerDecoder(nn.Module):
r'''
Parameters:
decoder_layer((mandatory)
num_layers: decoder_layer Number of layers (required)
norm: Normalized selection
example:
>>> decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
>>> transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = transformer_decoder(tgt, memory)
'''
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
self.layer = decoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = tgt
for _ in range(self.num_layers):
output = self.layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
Take a look at it with a small example
decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8) transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6) memory = torch.rand(10, 32, 512) tgt = torch.rand(20, 32, 512) out = transformer_decoder(tgt, memory) print(out.shape) # torch.Size([20, 32, 512])
To sum up, after position coding, the shapes of Encoder Layer and Decoder Layer will not change, while the shapes of Encoder and Decoder are consistent with src and tgt respectively
- Transformer
class Transformer(nn.Module):
r'''
Parameters:
d_model: Dimension of word embedding (required)( Default=512)
nhead: Number of parallel heads in long attention (required)( Default=8)
num_encoder_layers:Number of coding layers( Default=8)
num_decoder_layers:Number of decoding layers( Default=8)
dim_feedforward: The number of neurons in the whole connection layer, also known as the dimension input through this layer( Default = 2048)
dropout: dropout Probability of( Default = 0.1)
activation: Activation function between two linear layers, default relu or gelu
custom_encoder: custom encoder(Default=None)
custom_decoder: custom decoder(Default=None)
lay_norm_eps: layer normalization To prevent the denominator from being 0( Default = 1e-5)
batch_first: if`True`,Then(batch, seq, feture),if it is`False`,Then(seq, batch, feature)(Default: False)
example:
>>> transformer_model = Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
'''
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation = F.relu, custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False) -> None:
super(Transformer, self).__init__()
if custom_encoder is not None:
self.encoder = custom_encoder
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
encoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers)
if custom_decoder is not None:
self.decoder = custom_decoder
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
decoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
Parameters:
src: Source language sequence (input) Encoder)((mandatory)
tgt: Target language sequence Decoder)((mandatory)
src_mask: (Optional)
tgt_mask: ((optional)
memory_mask: ((optional)
src_key_padding_mask: ((optional)
tgt_key_padding_mask: ((optional)
memory_key_padding_mask: ((optional)
Shape:
- src: shape:`(S, N, E)`, `(N, S, E)` if batch_first.
- tgt: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
- src_mask: shape:`(S, S)`.
- tgt_mask: shape:`(T, T)`.
- memory_mask: shape:`(T, S)`.
- src_key_padding_mask: shape:`(N, S)`.
- tgt_key_padding_mask: shape:`(N, T)`.
- memory_key_padding_mask: shape:`(N, S)`.
[src/tgt/memory]_mask Make sure that some positions are not seen, such as decode When, you can only see the position and its previous, not the back.
if it is ByteTensor,Non-zero positions will be ignored and no attention will be paid; if it is BoolTensor,True The corresponding position will be ignored;
If it is a numerical value, it will be added directly attn_weights
[src/tgt/memory]_key_padding_mask bring key Some elements inside are not involved attention Calculation, the three cases are the same as above
- output: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
be careful:
src and tgt The last dimension of needs to be equal to d_model,batch The dimension of needs to be equal
example:
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
'''
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, sz: int) -> Tensor:
r'''Generate information about the sequence mask,Shaded area assignment`-inf`,The uncovered area is assigned as`0`'''
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def _reset_parameters(self):
r'''Initialize parameters with normal distribution'''
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
Try it out with a small example
transformer_model = Transformer(nhead=16, num_encoder_layers=12) src = torch.rand((10, 32, 512)) tgt = torch.rand((20, 32, 512)) out = transformer_model(src, tgt) print(out.shape) # torch.Size([20, 32, 512])
So far, I have fully implemented the Transformer Library of PyTorch. Compared with the official version, I have fewer judgment statements written by myself, so please make sure you read my tutorial and understand the basic input and output. Some unnecessary calls and packaging have been omitted, and some unnecessary functions have been rewritten and written by yourself.
In addition, all codes have been tested. If there is a problem, it must be your problem, Full version code.
These articles are copied from my github. You can go to star directly. There are many tutorials and resources that beginners can understand.
https://github.com/sherlcok314159/ML