There is a certain relationship between Java code and system call. Java is an interpretive language (Java is not valuable, but jvm is valuable). The Java code we write is finally compiled into bytecode, and then system call. In this paper, we still learn and understand io from a simple server program.
BIO
No matter which language, as long as it is a server-side program, it must have the following operations
- Call socket to get the file descriptor (representing the socket)
- bind binding port, such as 8090
- listen listening status
- accept receive client connections
Continue to use the test demo of the previous article. Connect the server through a client. From the following picture, you can see that the main thread has reached a poll (multiplexing, described later) state and is blocked in this place
public class ServerSocketTest {
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(8090);
System.out.println("step1:new ServerSocket(8090)");
while (true){
Socket client = server.accept();
System.out.println("step2:client\t"+client.getPort());
new Thread(() ->{
try {
InputStream in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true){
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}

Then we connect to the server through a client; You can see that it was still blocked just now (above figure). Now there are events connected. After they come in, they start to accept and receive, and a new file descriptor 6 (that is, the client) is generated


Further down, I found a clone. What's this? You must have guessed that the new Thread(()) above creates a new thread every time a client receives it. Thread id:16872

We can verify whether there is an additional 16872 thread. As shown in the figure below, there is indeed an additional 16872 thread
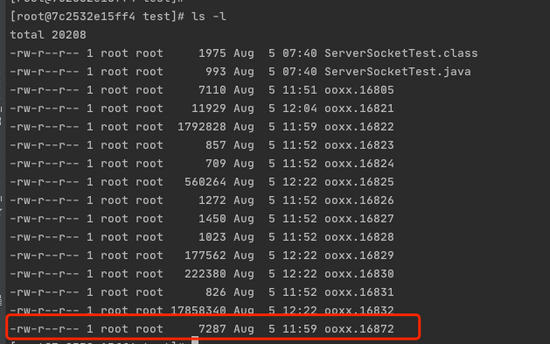
We look at the newly created thread and find that the thread is blocked in recvfrom(6), which is combined with the theory. The thread has been blocked until the client data arrives

Next, we give an input to the client, and then look at the response of the server

It is found that the content is read from the 6 descriptor, and then write1 (as we said earlier, 1 is standard output), and we see the content input by the client on the server
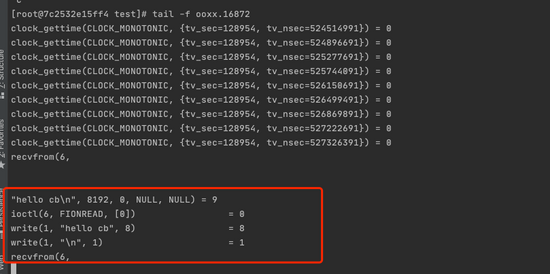

Here we can clearly see the io blocking point. The above example is to process the requests of multiple clients through multiple threads (each client corresponds to one thread), and the kernel must participate in this process (whether the jvm's own functions or lib, the final system call)
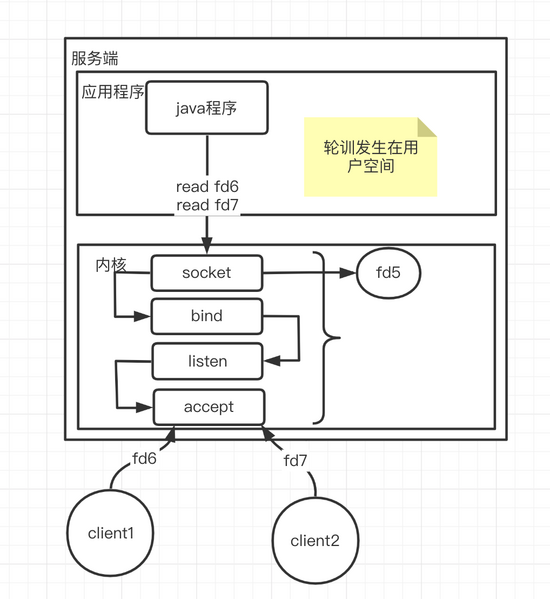
For the above operation, let's make a picture to describe it

In fact, this is BIO, a typical BIO. What's the problem
There are too many threads, and threads are also resources. Creating threads will take the system call (clone described above), so soft interrupts are bound to occur; We know that the memory of the thread stack is independent, so it will consume memory resources and waste cpu switching. In fact, these are superficial problems, and the fundamental problem is IO blocking
So how to make it not blocked? Let's look at the description of socket system call through the command man socket; The following figure shows that a socket can be made non blocking in the kernel (socket Linux 2.6.27 kernel supports non blocking mode.)

NIO
Adding a parameter when calling can make the socket non blocking. At this time, read fd is non blocking. If there is data, it will be read directly, and if there is no data, it will be returned directly. This is the so-called NIO. In fact, NIO has the following two statements
- From the perspective of App lib, N means new. It is a new io system with new components such as channel and buffer
- From the perspective of the operating system kernel, N means no blocking
Compared with the previous BIO, this model solves the problem of opening up many threads; It seems more awesome than before, so what's the problem with doing so?
I don't know if you have ever heard of C10K. For example, if there are 1w client s, you will call the system kernel 1w times each time to see if there is data. That is to say, there will be an O(n) complexity sys call process each time, but maybe only a few of the 1w times have data or are ready, that is, the vast majority of system calls are busy in vain, This is a bit of a waste of resources!
How to solve this problem? Whether the complexity of O(n) can be degraded depends on how the kernel is optimized. We can look at the select command. The following description is "allow a program to listen to multiple file descriptors and wait for one or more file descriptors to become available"
SYNOPSIS
/* According to POSIX.1-2001, POSIX.1-2008 */
#include <sys/select.h>
/* According to earlier standards */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
--
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
#include <sys/select.h>
int pselect(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, const struct timespec *timeout,
const sigset_t *sigmask);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
pselect(): _POSIX_C_SOURCE >= 200112L
DESCRIPTION
select() and pselect() allow a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation (e.g., input pos-
sible). A file descriptor is considered ready if it is possible to perform a corresponding I/O operation (e.g., read(2) without blocking, or a sufficiently small write(2)).
select() can monitor only file descriptors numbers that are less than FD_SETSIZE; poll(2) does not have this limitation. See BUGS.
The operation of select() and pselect() is identical, other than these three differences:
(i) select() uses a timeout that is a struct timeval (with seconds and microseconds), while pselect() uses a struct timespec (with seconds and nanoseconds).
(ii) select() may update the timeout argument to indicate how much time was left. pselect() does not change this argument.
It is easy to understand from the following figure. The program first calls a system call called select, and then passes it into fds (if there are 1w file descriptors, send these 1w file descriptors to the kernel in this system call), and the kernel will return several available file descriptors, The final read data is read by accessing the kernel based on the file descriptors of several available states. The complexity of the system can be understood as O(m), followed by nio (each client asks whether it is ready), and now all client connections are thrown into a tool select (multiplexer); Therefore, many client connections reuse a system call, return the ready connection, and then the program reads and writes by itself
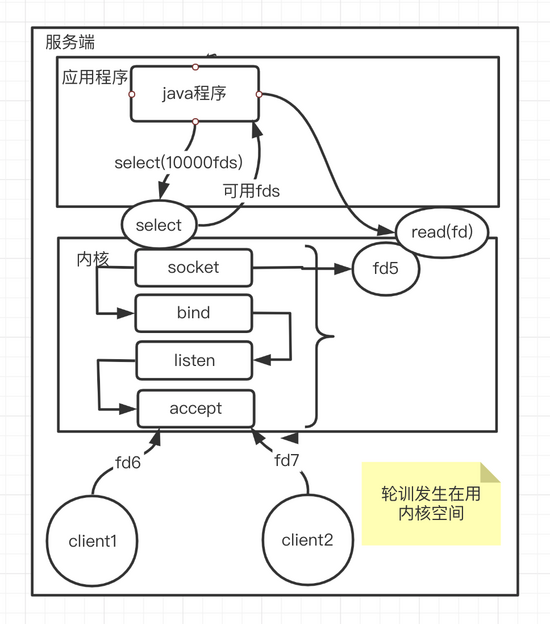
Compared with the above nio system complexity O(n), this multiplexing model reduces the number of system calls and becomes o(m). However, the active traversal of O(n) needs to be completed in the kernel, so there are still the following two problems
- select needs to pass values every time (10w fds)
- The kernel actively traverses which fd are readable and writable
Is there any way to solve this problem? Yes, there must be. Let's continue to look at ha
epoll multiplexing
If a space can be opened up in the kernel, the program will save the file descriptor of the connection to the kernel every time it receives a connection, and there is no need to repeat the transmission next time, reducing the transmission process, how to know which of these fd are readable / writable? The former method was active traversal. If there were 1w, it would traverse 1w times. How to optimize this active traversal method to make it faster; In fact, there is an event driven approach, and epoll is needed at this time. You can view the epoll document through the man epoll command
The epoll API performs a similar task to poll(2): monitoring multiple file descriptors to see if I/O is possible on any of them. The epoll API can be used either as an edge-triggered or a
level-triggered interface and scales well to large numbers of watched file descriptors. The following system calls are provided to create and manage an epoll instance:
* epoll_create(2) creates a new epoll instance and returns a file descriptor referring to that instance. (The more recent epoll_create1(2) extends the functionality of epoll_create(2).)
* Interest in particular file descriptors is then registered via epoll_ctl(2). The set of file descriptors currently registered on an epoll instance is sometimes called an epoll set.
* epoll_wait(2) waits for I/O events, blocking the calling thread if no events are currently available.
You can see that epoll has three main commands_ create,epoll_ctl,epoll_wait
epoll_create
epoll_create: the kernel will generate an epoll instance data structure and return a file descriptor epfd, which actually describes a space opened up in the kernel described above
DESCRIPTION
epoll_create() creates a new epoll(7) instance. Since Linux 2.6.8, the size argument is ignored, but must be greater than zero; see NOTES below.
epoll_create() returns a file descriptor referring to the new epoll instance. This file descriptor is used for all the subsequent calls to the epoll interface. When no longer required, the
file descriptor returned by epoll_create() should be closed by using close(2). When all file descriptors referring to an epoll instance have been closed, the kernel destroys the instance and
releases the associated resources for reuse.
epoll_create1()
If flags is 0, then, other than the fact that the obsolete size argument is dropped, epoll_create1() is the same as epoll_create(). The following value can be included in flags to obtain
different behavior:
EPOLL_CLOEXEC
Set the close-on-exec (FD_CLOEXEC) flag on the new file descriptor. See the description of the O_CLOEXEC flag in open(2) for reasons why this may be useful.
RETURN VALUE
On success, these system calls return a nonnegative file descriptor. On error, -1 is returned, and errno is set to indicate the error.
epoll_ctl
Epoll for file descriptor fd and its listening event_ Event to register, delete, or modify its listening event epoll_event
DESCRIPTION
This system call performs control operations on the epoll(7) instance referred to by the file descriptor epfd. It requests that the operation op be performed for the target file descriptor,
fd.
Valid values for the op argument are:
EPOLL_CTL_ADD
Register the target file descriptor fd on the epoll instance referred to by the file descriptor epfd and associate the event event with the internal file linked to fd.
EPOLL_CTL_MOD
Change the event event associated with the target file descriptor fd.
EPOLL_CTL_DEL
Remove (deregister) the target file descriptor fd from the epoll instance referred to by epfd. The event is ignored and can be NULL (but see BUGS below).
epoll_wait
Block the occurrence of events waiting for registration, return the number of events, and write the triggered available events to epoll_events array.
SYNOPSIS
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
int epoll_pwait(int epfd, struct epoll_event *events,
int maxevents, int timeout,
const sigset_t *sigmask);
DESCRIPTION
The epoll_wait() system call waits for events on the epoll(7) instance referred to by the file descriptor epfd. The memory area pointed to by events will contain the events that will be
available for the caller. Up to maxevents are returned by epoll_wait(). The maxevents argument must be greater than zero.
The timeout argument specifies the number of milliseconds that epoll_wait() will block. Time is measured against the CLOCK_MONOTONIC clock. The call will block until either:
* a file descriptor delivers an event;
* the call is interrupted by a signal handler; or
* the timeout expires.
The whole running process of the program
socket fd5 establish socket wait until fd5 bind 8090 Binding 8090 listen fd5 monitor fd5 epoll_create fd8 Create an area in the kernel fd8 epoll_ctl(fd8,add fd5,accept) stay fd8 In this area fd5 Put it in epoll_wait(fd8) Let the program wait for the file descriptor to reach the ready state accept fd5 -> fd6 The new file descriptor is fd6 Client for epoll_ctl(fd8,fd6) hold fd6 put to fd8 If there are many clients, fd8 There will be many in the kernel area fd

How to implement event driven? We need to introduce the concept of interrupt in detail here (I hope to introduce it separately in an article later): for example, when the client sends data to the network card of the server, the network card will interrupt to the cpu after receiving the data, the cpu will call back, and the kernel will know which fd it is through DMA (direct memory access), Then, the ready fd is transferred from area a to area b in the figure; The client directly obtains the ready fd to read and write
summary
To sum up, epoll actually gives full play to the hardware and does not waste cpu; From bio - > NiO - > epoll multiplexing, it is to solve the problems existing in the existing model, so as to derive a new model, not only technology, but also all things