Last TVM's "hello world" basic process I Based on a basic case, this paper introduces the definition of calculation and the construction of schedule in TVM. This article follows the case in the previous article and continues to introduce the next key part, which is compilation.
With the previously built schedule, you need to compile and generate the object code. This work is mainly by TVM Build () and relay Build () two functions to complete. Their difference lies in the scope of application targets. The former is used for a single operator and the latter is used for the whole network. Since the network can be regarded as composed of operators, the latter will call the former. This example is for a single operator, so the former is used here:
tgt = tvm.target.Target(target="llvm", host="llvm") fadd = tvm.build(s, [A, B, C], tgt, name="vecadd")
The main build() function is defined in driver/build_module.py file. This function constructs a callable objective function based on the given parameters. According to the official introduction, it mainly does two jobs:
- Lowing: convert the loop nesting structure of high-level into the IR of the final low-level.
- Codegen: generate target machine code from low level IR.
The first parameter of the function is the previously built schedule, the second parameter is the parameter list of the function, and the third parameter is target. It provides the target platform information required for lowering and codegen. The corresponding target object in the code is defined in target* File. Its constructor has two parameters, of which the first parameter target indicates the configuration of the target platform. The configuration items include:
- Kind: platform type, which basically determines the processor on which the generated code runs. See target kind for details of registered target kind_ kind. CC, including llvm, c, cuda, nvptx, romc, opencl, metal, vulkan, hexagon, etc.
- keys: if kind is opencl, the key can be mali, opencl, gpu.
- Device: corresponding to the actual running device, it will be added after keys.
- libs: external libraries, such as cblas, cudnn, cublas and MKL.
- ...
In addition, the parameter host is similar to target, but it is used to indicate the host platform. For example, if the taret platform is cuda, after all, the GPU can not run completely away from the CPU, so the host code is also needed as glue, such as memory allocation and kernel startup. The default is llvm.
The lowing process can be used separately with TVM The lower() function is completed, such as:
m = tvm.lower(s, [A, B, C], name="vecadd") rt_mod = tvm.build(m, target="llvm")
You can also use TVM The build () function is complete (because it calls the lower () function as soon as it goes in). Main process related codes of lower() function:
lower(sch, args, name="main", ...) // driver/build_module.py
// Handle add_lower_pass, if any.
lower_phases0 = ...
...
// According to the given schedule, form a function (in IRModule).
mod = form_irmodule(sch, args, ...) // build_module.py
sch.normalize()
Schedule::normalize() // schedule_dataflow_rewrite.cc
InjectInline()
RebaseNonZeroMinLoop()
LegalizeInvalidAttach()
bounds = schedule.InferBound(sch)
InferBound() // bound.cc
stmt = schedule.ScheduleOps(sch, bounds)
ScheduleOps() // schedule_ops.cc
body = Stmt()
// scan init and scan updates
...
for each stage in schedule: // in reverse order
body = MakePipeline(stage, dom_map, body, ...)
SchedulePostProc post_proc
post_proc.Init(sch)
return post_proc(body)
compact = schedule.VerifyCompactBuffer(stmt)
binds, arg_list = get_binds(args, compact, binds)
stmt = schedule.SchedulePostProcRewriteForTensorCore(stmt, sch, ...)
// func type: PrimFunc
func = schedule.SchedulePostProcToPrimFunc(arg_list, stmt, ...) // schedule_postproc_to_primfunc.cc
// Prepare parameters
...
return tie::PrimFunc(params, body, ...)
// name: vecadd
func = func.with_attr("global_symbol", name)
// Set functions
return tvm.IRModule({name: func})
// Phase 0: InjectPrefetch, StorageFlatten, BF16Legalize, NarrowDataType, Simplify
pass_list = lower_phase0
// Phase 1: LoopPartition, VectorizeLoop, InjectVirtualThread, InjectDoubleBuffer, StorageRewrite, UnrollLoop
pass_list += lower_phase1
// Phase 3: Simplify, RemoveNoOp, RewriteUnsafeSelect, HoistIfThenElse
pass_list += lower_phase2
// Apply the above passes.
optimize = tvm.transform.Sequential(pass_list)
mod = optimize(mod)
// mod type: tvm.ir.module.IRModule
return mod
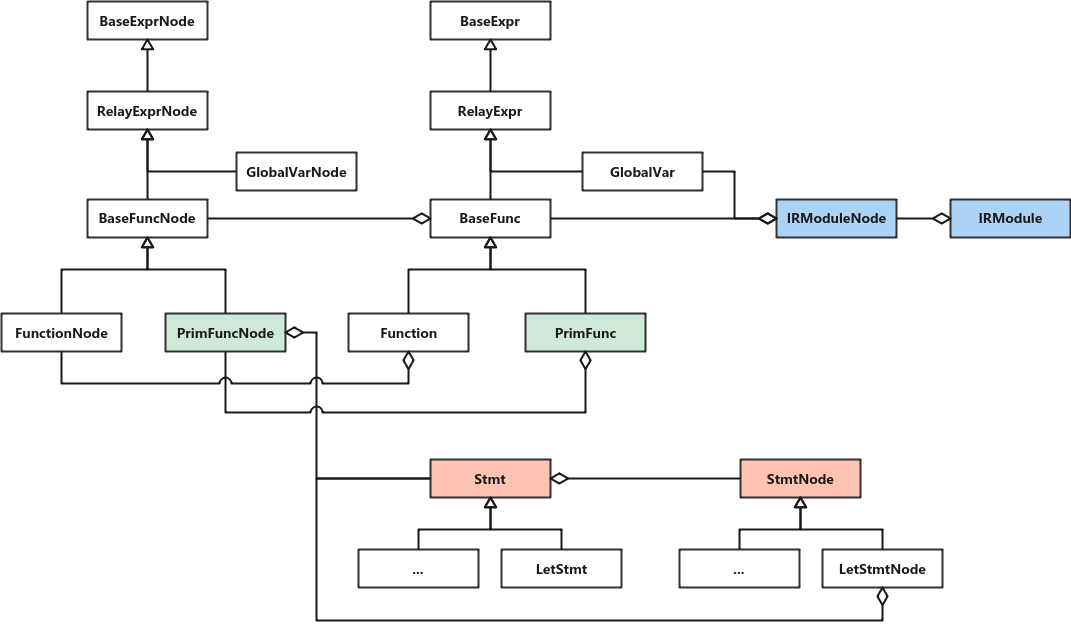
It mainly generates corresponding IRModule objects (defined in ir/module.h) according to the schedule and parameters given by the parameters. IRModule is the basic unit of all IR transformations in the software stack. It maintains function and type definitions. Various pass es here are performed on IRModule and spit out IRModule.
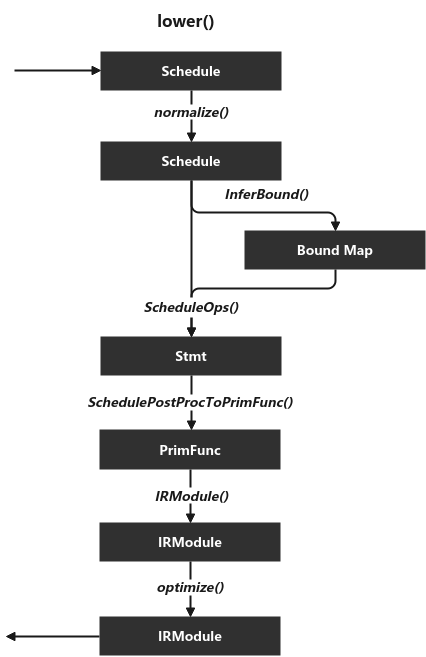
The main data structure relationships are as follows:
There are four stages in the lower() function. In the first stage, form is passed_ The IRModule () function generates an IRModule object according to the given schedule, and then applies four rounds of passes on the IRModule object. These passes are mainly divided into several stages:
- Phase 0: user defined pass.
- Phase 1: user defined pass. And:
- InjectPrefetch
- StorageFlatten
- BF16Legalize
- NarrowDataType
- Simplify
- Phase 2: user defined pass. And:
- LoopPartition
- VectorizeLoop
- InjectVirtualThread
- InjectDoubleBuffer
- StorageRewrite
- UnrollLoop
- Phase 3: user defined pass. And:
- Simplify
- RemoveNoOp
- RewriteUnsafeSelect
- HoistIfThenElse
- InstrumentBoundCheckers
This pass is actually one of the essences of compiling and constructing. But limited to space (actually I don't know all about it myself), I'll discuss it further in the future.
The last of the lower() function returns the IRModule object after the above rounds of pass optimization. Where form_irmodule() function is a relatively complex part. It is mainly responsible for generating the initial IRModule object. Several key steps are as follows:
- The Schedule::normalize() function normalizes the given schedule. It is mainly implemented in schedule_dataflow_rewrite.cc file. It calls the following three functions. This example is simple, so they don't really work...
- The InjectInline() function handles operator inlining. Use the scheduling primitive compute_inline will be used.
- The RebaseNonZeroMinLoop() function sets the minimum bound of the loop iteration to 0. It feels a little canonicalization.
- The legalizeinvalidatach() function handles the use of the scheduling primitive compute_at and the target iteration is legalized in the case of split or fuse.
- The InferBound() function, as its name implies, is used to derive the loop boundary. More specifically, it determines the Range of each IterVar and returns the mapping from IterVar to Range, that is, the Range of each loop variable. This information is used to determine the Range of the for loop in the MakeLoopNest() function, And setting the size of the buffer in the BuildRealize() function. See official documents for details InferBound Pass.
- The ScheduleOps() function generates an stmt object based on the previously processed schedule object and the derived loop boundary. It represents an initial loop nesting structure. Stmt in the C + + layer is the container for all statements. Its subclasses include LetStmt, AttrStmt, AssertStmt, Store, Allocate, SeqStmt, IfThenElse, Evaluate, for, While, etc. this function will handle the dependency of schedule, and the core part is to traverse the stage in schedule backward (in the above example, Compute Op is followed by two placeholder OPS). For each stage (except Placeholder Op), call the corresponding logic according to its attach type.
- For the above example, Compute Op does not have an attach in other calculations, so the attach type of its corresponding Stage is kGroupRoot. Therefore, the MakePipeline() function is called here to generate Stmt. This step is critical and complex, which will be carried out later.
- Then, the previously generated Stmt is post processed through the SchedulePostProc object (inherited from stmtexrmutator).
- get_ The bindings() function is used to bind the buffer. It assigns a buffer to each parameter tensor. For example, for the three tensors a, B and C in the above example, TVM tir. decl_ Buffer () creates a buffer and binds it to the tensor.
- The SchedulePostProcToPrimFunc() function creates a PrimFunc object based on the Stmt generated by ScheduleOps(), which can be used for TIR optimization. PrimFunc represents the primitive function containing TIR statement, which is the code representation of low-level.
- Create an IRModule object. Encapsulate the object generated above into an IRModule object and return it. An IRModule can have multiple functions, one in a relatively simple case.
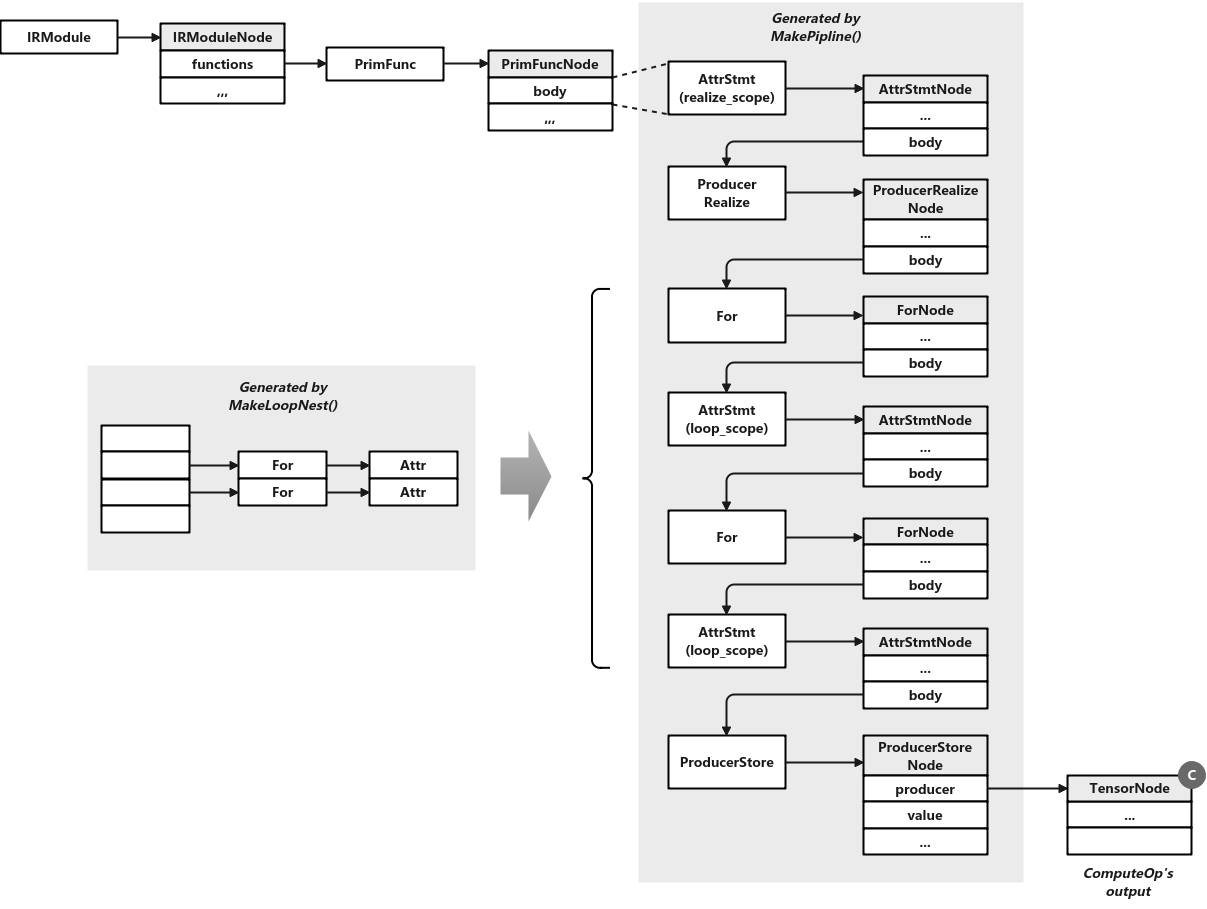
In the ScheduleOps() function above, the MakePipeline() function will be called to return a pipeline composed of Stmt for the corresponding Stage of ComputeOp. The general process related codes are as follows:
MakePipeline(Stage, unordered_map<IterVar, Range>, Stmt, ...) // schedule_ops.cc
producer = s->op->BuildProvide(stage, ...) // ComputeOpNode::BuildProvide() in compute_op.cc
ComputeType ctype = DetectComputeType(this, stage)
MakeComputeStmt(...) // compute_op.cc
ComputeLoopNest n = ComputeLoopNest::Create(...) // compute_op.cc
ComputeLoopNest ret
// make main loop nest
ret.main_nest = MakeLoopNest(stage, dom_map, ...) // op_utils.cc
vector<vector<Stmt>> nest
nest.resize(leaf_iter_vars.size() + 1)
for iter_var in leaf_iter_vars:
nest[i + 1].emplace_back(For(var, 0, dom->extent, kind, no_op))
nest[i + 1].emplace_back(AttrStmt(iv, tir::attr::loop_scope, iv->var, no_op))
...
n.init_nest.emplace_back(MakeIfNest(n.init_predicates))
n.main_nest.emplace_back(MakeIfNest(n.main_predicates))
if has reduce_axis:
...
else:
vector<Stmt> provides
...
// Array<Stmt> -> SeqStmt
Stmt provide = SeqStmt::Flatten(provides) // stmt.h
provide = MergeNest(n.main_nest, provide) // ir_utils.cc
return Substitute(provide, n.main_vmap) // stmt_functor.cc
Stmt pipeline = producer
pipeline = s->op->BuildRealize(stage, dom_map, pipeline)
// set the sizes of allocated buffers
BaseComputeOpNode::BuildRealize(stage, realize_map, body) // compute_op.cc
Stmt realize = body
realize = tir::ProducerRealize(...)
pipeline = AttrStmt(s->op, tir::attr::realize_scope, ..., pipeline)
return pipeline
The main steps of MakePipeline() function are as follows:
- The ComputeOpNode::BuildProvide() function mainly creates the loop corresponding to ComputeOp, nested the corresponding Stmt objects and concatenated them into a pipeline.
- First, use the DetectComputeType() function to detect the calculation type. It traverses all currently valid IterVar objects of the current Stage and determines the calculation type according to their properties. For the simple example above, it is ComputeType::kNormal.
- Then call the corresponding function according to the type to create the Stmt object. This corresponds to calling the MakeComputeStmt() function.
-
According to the result of Stage object and boundary derivation, create the ComputeLoopNest object through the ComputeLoopNest::Create() function. This object represents circular nesting. It has several main members:
- init_ Predictions and main_ Predictions: type is vector < primexpr >. Represents the boundary judgment of each loop, which is generated by calling the makebundcheck() function.
- init_nest and main_nest: type is vector < vector < stmt > >. Where main_nest is the most important object that represents loop nesting. For the above example, after split, there are two for loops.
-
According to main_ Predictions creates the corresponding Stmt (if any), which is used to judge whether the prediction is valid in the loop and add it to the main_nest structure.
-
Take different path s according to whether there is reduce axis. If not (as in this example), for each output in the body of ComputeOp, create a ProducerStore object, and then nest it with the main main object through the MergeNest() function_ Nest merge.
-
Based on main through the Substitute() function_ Replace with VMap (prepared in the MakeLoopNest() function).
-
- If double buffer (e.g. s[A].double_buffer) is set in the schedule, the corresponding AttrStmt is added. It achieves the overlap of calculation and memory access by increasing additional buffer. It is not used in this example.
- If the incoming consumer has a definition and is not no op (it refers to the EvaluateNode without definition, const init, or SeqStmtNode with length of 0), add SeqStmt to connect the producer and consumer in series. It is also not applicable in this example.
- Call the BuildRealize() function. For each output tensor, a producer realize node is added to the pipeline.
- Finally, add the AttrStmt node in the pipeline to label the scope of the operation and return the pipeline.
For the previous vecadd example, the obtained pipeline is roughly as follows:
The IR (TIR) after the completion of the whole lower() function is printed as follows:
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"global_symbol": "main", "tir.noalias": True}
buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024], []),
B: Buffer(B_2: Pointer(float32), float32, [1024], []),
A: Buffer(A_2: Pointer(float32), float32, [1024], [])}
buffer_map = {A_1: A, B_1: B, C_1: C} {
for (i.outer: int32, 0, 16) {
for (i.inner: int32, 0, 64) {
C_2[((i.outer*64) + i.inner)] = ((float32*)A_2[((i.outer*64) + i.inner)] + (float32*)B_2[((i.outer*64) + i.inner)])
}
}
}
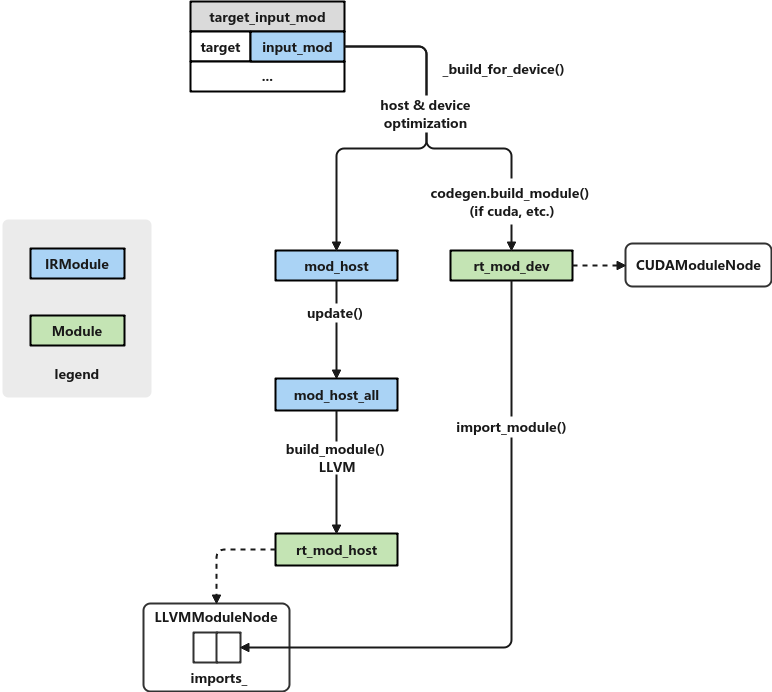
After Lowering is completed, the next step is build. The main process codes of build are as follows:
build() # driver/build_module.py
input_mod = lower(inputs, args, ...)
mod_host_all = tvm.IRModule()
for tar, input_mod in target_input_mod.items():
# build the lowered functions for a device with the given compilation
mod_host, mdev = _build_for_device(input_mod, tar, target_host)
# input_mod type: IRModule
mod_mixed = input_mod
# Apply passes: ThreadSync, InferFragment, LowerThreadAllreduce, MakePackedAPI, SplitHostDevice
...
# Device optimizations: Filter, LowerWarpMemory, ,Simplify, LowerDeviceStorageAccessInfo, LowerIntrin
...
mod_dev = opt_device(mod_mixed) # IRModule
# Host optimization: LowerTVMBuiltin, LowerDeviceStorageAccessInfo, CustomDataType, LowerIntrin, CombineContextCall
...
mod_host = opt_host(mod_mixed) # IRModule
# Build IRModule into Module
# If there are dev functions
rt_mod_dev = codegen.build_module(mod_dev, target) # target/codegen.py
_ffi_api.Build(mod, target) # codegen.py
# mod_host type: IRModule, rt_mod_dev type: Module
return mod_host, rt_mod_dev
mod_host_all.update(mod_host)
# Insert functions in another Module to current one
_ffi_api.Module_Update()
IRModuleNode::Update() # ir/module.cc
device_modules.append(mdev)
# Generate a unified host module (type: runtime.Module)
rt_mod_host = codegen.build_module(mod_host_all, target_host)
# Create LLVMModuleNode and return the corresponding Module
_ffi_api.Build(mod, target) # target/codegen.cc
# Import all modules
for mdev in device_modules:
rt_mod_host.import_module(mdev)
_LIB.TVMModImport(mod, dep) # c_runtime_api.cc
GetModuleNode(mod)->Import(...) # runtime/module.cc
imports_.emplace_back(...)
return rt_mod_host # runtime.module.Module
target_ input_ Mod contains the IRModule to be compiled and the corresponding target information output by the previous lowering. For example, if LLVM(CPU) is the target, that is: {"llvm - keys = CPU - link params = 0", IRModule}. If cuda is target, It may be {"cuda -keys=cuda,gpu -max_num_threads=1024 -thread_warp_size=32", IRModule}. For a simple case (such as this article), target_input_mod contains only one element, and the _build_for_device() function returns the IRModule on the host side and the Module on the target side (in case of cuda platform, the C + + layer corresponds to CUDAModuleNode object). Then generate a unified host Module from the IRModule on the host side, and then import the Module (if any) corresponding to the target generated earlier into it.
Here, where mod_host_all and Mod_ The type of host is TVM ir. module. IRModule. rt_ mod_ The types of host and mdev are TVM runtime. module. Module. Note that mdev only exists when the target is a non CPU (such as GPU) platform, and mdev is empty when the target is llvm (i.e. for CPU).
The general diagram of this process is as follows:
The core and important part is the Build() function, which is implemented in CodeGen CC file. It will call the compilation function to the specific back end for object code generation. As for CUDA platform, the corresponding function is defined in build_cuda_on.cc file, llvm_module.cc file. Taking the llvm backend as an example, the main process related codes are:
TVM_REGISTER_GLOBAL("target.build.llvm")
.set_body_typed([](IRModule mod, Target target) -> runtime::Module {
auto n = make_object<LLVMModuleNode>();
n->Init(mod, target); // llvm_module.cc
InitializeLLVM();
llvm::InitializeAllTargetInfos();
llvm::InitializeAllTargets();
...
unique_ptr<CodeGenLLVM> cg = CodeGenLLVM::Create(...) // codegen_llvm.cc
// Call the corresponding codegen backend according to the target.
const PackedFunc* f = runtime::Registry::Get("tvm.codegen.llvm.target_" + target);
handle = (*f)()
return unique_ptr<CodeGenLLVM>(handle);
vector<PrimFunc> funcs;
for kv : mod->functions:
...
f = Downcast<PrimFunc>(kv.second);
if (f->HasNonzeroAttr(tir::attr::kIsEntryFunc))
entry_func = global_symbol.value();
funcs.push_back(f);
cg->Init("TVMMod", ...);
CodeGenCPU::Init() // codegen_cpu.cc
CodeGenLLVM::Init() // codegen_llvm.cc
for f in funcs:
cg->AddFunction(f); // codegen_cpu.cc
CodeGenLLVM::AddFunction();
AddFunctionInternal(f);
llvm::FunctionType* ftype = llvm::FunctionType::get(...);
// kGlobalSymbol: "global_symbol"
global_symbol = f->GetAttr<String>(tvm::attr::kGlobalSymbol);
function_ = llvm::Function::Create(...);
llvm::BasicBlock* entry = llvm::BasicBlock::Create(..., function_);
IRBuilder::SetInsertPoint(entry);
this->VisitStmt(f->body);
builder_->CreateRet(ConstInt32(0));
if entry_func.length() != 0:
cg->AddMainFunction(entry_func); // codegen_cpu.cc
// tvm_module_main : "__tvm_main__"
llvm::GlobalVariable* global = new llvm::GlobalVariable(*module_, ..., tvm_module_main);
global->setInitializer(llvm::ConstantDataArray::getString(*ctx_, entry_func_name))
global->setDLLStorageClass(llvm::GlobalVariable::DLLExportStorageClass);
module_ = cg->Finish(); // CodeGenCPU::Finish() in codegen_cpu.cc
CodeGenLLVM::Finish(); // codegen_llvm.cc
CodeGenCPU::AddStartupFunction();
function_ = llvm::Function::Create(ftype, llvm::Function::InternalLinkage,"__tvm_module_startup", module_.get());
llvm::BasicBlock* startup_entry = llvm::BasicBlock::Create(*ctx_, "entry", function_);
llvm::appendToGlobalCtors(*module_, function_, 65535);
builder_->CreateRet(nullptr);
CodeGenLLVM::Optimize(); // codegen_llvm.cc
// Function pass manager
FPassManager fpass(module_.get());
// Module pass manager
MPassManager mpass;
mpass.add(llvm::createTargetTransformInfoWrapperPass(getTargetIRAnalysis()));
fpass.add(llvm::createTargetTransformInfoWrapperPass(getTargetIRAnalysis()));
llvm::PassManagerBuilder builder;
builder.Inliner = llvm::createFunctionInliningPass(builder.OptLevel, ...);
builder.LoopVectorize = true;
builder.SLPVectorize = true;
...
// Run the function passes
for mod in module_:
fpass.run(mod);
fpass.doFinalization();
// Run the module passes.
mpass.run(*module_);
return runtime::Module(n);
});
The function first creates the LLVMModuleNode object, then calls its Init () function to initialize it, and finally encapsulates it into a Module object to return. The Init() function mainly converts the TIR generated before to LLVM IR. It is mainly divided into several steps:
-
The InitializeLLVM() function initializes the LLVM environment. Here is mainly a large lump of initialization functions that routinely call LLVM.
-
Create a CodeGenLLVM object for code generation. Here, because the target string is x86-64, the factory function is named TVM codegen. llvm. target_ x86-64. Codegenx86 is created in this factory function_ 64 object. Because the inheritance relationship is CodeGenX86_64 - > codegencpu - > CodeGenLLVM, so the pointer of CodeGenLLVM is returned.
-
The functions member in the parameter mod of type IRModule contains the functions in the module. In this step, these functions are stored in the array funcs of type PrimFunc. For the function marked as the entry function (kIsEntryFunc), record it in the entry_func variable.
-
Next, initialize the previously created CodeGenX86_64 object. First call CodeGenCPU::Init(), which will call CodeGenLLVM::Init(). The former mainly creates a lump of TVM runtime types and functions. The latter creates objects for codegen in llvm, such as IRBuilder, llvm::Module, and llvm::MDBuilder.
-
For each function previously placed in the funcs array, call the CodeGenCPU::AddFunction() function to generate code. The only function for the case covered in this article is vecadd().
- First, llvm::Function and llvm::BasicBlock objects are generated, corresponding to functions and basic blocks respectively. Previously, the name of the function was global in the loewr() function_ The attribute of symbol is set to the corresponding function name (such as vecadd). This attribute is taken out here as the symbol when generating the function link.
- Through the VisitStmt() function, each node in the IRModule is traversed and converted to the corresponding data structure in the LLVM to generate the LLVM IR. This is the most critical step. TIR built with great efforts is mainly for the conversion here. For example, codegenllvm:: visitstmt will be called for ForNode_ (ForNode * OP) function. It then calls the CreateSerialFor() function to generate the corresponding LLVM IR. In the optimization pass, MakePackedAPI (make_packed_api.cc) will add an AttrStmt, which corresponds to a compute_scope whose value is the target function name plus the suffix _compute_. in this way, during code generation, the CodeGenCPU::CreateComputeScope() function (why add compute_scope is mentioned in the comment of the function) will be called. Therefore, the final binary (it can be exported through fadd.export_library("vecadd.so") statement) it will look like this:

-
The AddMainFunction() function sets the main function. As in the above example, there is only one function vecadd(), which is also the main function. This symbol will be placed in runtime::symbol::tvm_module_main (i.e. _tvm_main_) In this global variable. We can verify this by compiling binary. Use the objdump command to dump the exported so file. You can see the following paragraph. If the hexadecimal of 0x766563616464 inside is converted to ASCII, it is the symbol name of the main function: vecadd.
0000000000003c87 <__tvm_main__>:
3c87: 76 65 jbe 3cee <__GNU_EH_FRAME_HDR+0x5e>
3c89: 63 61 64 movslq 0x64(%rcx),%esp
3c8c: 64 fs
- Finally, call the CodeGenCPU::Finish() function to generate the backend code from LLVM IR. It actually calls the CodeGenLLVM::Finish() function, which will call the CodeGenLLVM::Finish() function. It mainly calls the CodeGenCPU::AddStartupFunction() function and CodeGenLLVM::Optimize() function. Former creation_ tvm_ module_ The startup function, and then fill in some functions that need to be called at startup. The latter mainly uses LLVM pass to do some optimization. Mainly vectorization and function inlining. There are two kinds of Automatic Vectorization in llvm. For details, see Auto-Vectorization in LLVM.
In fact, the compilation has not been completely completed here, but the LLVM module has been built. At this point, the rest is to leave it to LLVM to compile and generate executable binary. The real generation of executable binary is completed by lazyinitiat() function at the first run. The LLVMModuleNode::GetFunction() function is called at runtime. When it finds that an executable binary has not been generated, it calls the LazyInitJIT() function. This function compiles the previously generated llvm::Module into a real binary (which can run on the machine) through llvm::ExecutionEngine, and then GetFunctionAddr() function obtains the corresponding function pointer from it for execution.