ThreadLocalMap uses the open address method to solve the conflict problem, and our protagonist HashMap uses the linked list method to deal with the conflict. What is the linked list method?
data structure
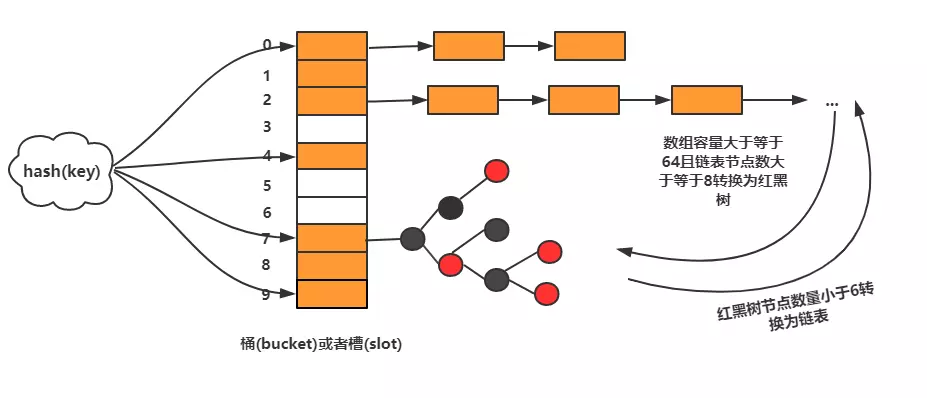
In the hash table, each "bucket" or "slot" corresponds to a list, and all elements with the same hash value are placed in the list corresponding to the same slot.
Jdk8 is different from jdk7. JDK7 has no red-black tree and only lists are mounted in arrays. In jdk8, when the bucket capacity is greater than or equal to 64 and the number of linked list nodes is greater than or equal to 8, it is converted to a red-black tree. When the number of red-black tree nodes is less than 6, it will be converted to linked list.
insert
But when inserting, we only need to calculate the corresponding slot position by hash function and insert it into the corresponding list or red-black tree. If the number of elements exceeds a certain value at this time, it will be expanded and rehash will be carried out at the same time.
Find or delete
Calculate the corresponding slot by hashing function, then traverse the list or delete it.
Why did the list turn into a red-black tree?
As mentioned in the previous article, how many slots are free can be determined by the loading factor. If the value exceeds the loading factor, it will expand dynamically. HashMap will expand to twice the original size (the initial capacity is 16, that is, the slot (array) size is 16). However, no matter how reasonable the load factor and hash function are set, it can not avoid the situation of too long list. Once the list is too long to find and delete elements, it will be time-consuming, affecting the performance of HashMap. So JDK8 optimizes it. When the length of the list is greater than or equal to 8, the list will be converted to red-black tree, making use of the characteristics of red-black tree. Points (the worst time complexity for finding, inserting and deleting is O(logn)) can improve the performance of HashMap. When the number of nodes is less than 6, the red-black tree will be converted into a linked list. Because in the case of small amount of data, red-black trees need to maintain balance. Compared with linked lists, the performance advantages are not obvious, and the encoding difficulty is much greater than linked lists.
Source code analysis
Construction methods and important attributes
public HashMap(int initialCapacity, float loadFactor); public HashMap(int initialCapacity); public HashMap();
In the construction method of HashMap, initialization capacity (bucket size) and load factor can be specified separately. If no default values are specified, they are 16 and 0.75, respectively. Several important attributes of HashMap are as follows:
// Initialization capacity, must be 2 n power
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// Default value of load factor
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// The Minimum Length of Link List Nodes when Converting from Link List to Red-Black Tree
static final int TREEIFY_THRESHOLD = 8;
// Minimum capacity of the array when converted to a red-black tree
static final int MIN_TREEIFY_CAPACITY = 64;
// When resize operates, the number of red-black tree nodes less than 6 is converted to a linked list.
static final int UNTREEIFY_THRESHOLD = 6;
// HashMap threshold, used to determine whether expansion is required (threshold = capacity * loadFactor)
int threshold;
// Load factor
final float loadFactor;
// struct Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
// An array of stored data
transient Node<K,V>[] table;
// Red-Black Tree Node
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
The table above is an array that stores data (which can be called a bucket or slot), and the array mounts a linked list or a red-and-black tree. It is worth noting that the HashMap is constructed without initializing the array capacity, but only when the first put element is initialized.
Design of hash function
int hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); int index = hash & (tab.length-1);
As can be seen from the above, when the key is null, it is time to put it in the first place in the array. We usually do this when we locate where the key should be stored in the array. HashCode ()% tab.length. But when tab.length is the n-th power of 2, it can be converted to A%-B = A & (B-1); therefore, index = hash & (tab.length-1) is understandable.
This is designed with the idea of the method of dividing the residue, which may reduce hash conflicts.
The method of dividing the residue: divide the keyword K by a number p not greater than the length m of the hash table, and take the residue as the address of the hash table.
For example, x/8 = x > 3, that is to say, the quotient of x/8 is obtained by shifting x to the right of three places, and the part that is removed (the last three places) is x%8, which is the remainder.
Why is the operation of hash value (h = key. hashCode ()^ (h > > > > 16)? Why do you move 16 bits to the right? Is it not good to use key. hashCode () & (tab. length - 1) directly?
If we do this, because tab.length must be much smaller than hash value, only low bits participate in the operation, while high bits do nothing, which will bring the risk of hash conflict.
The hashcode itself is a 32-bit shaping value. The shaping calculated by XOR operation after shifting 16 bits to the right will have the properties of high and low bits, and a very random hash value can be obtained. By dividing the residue method, the index obtained will have a lower probability of reducing the conflict.
insert data
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. Initialize an array if it is not initialized
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. If the current node is not inserted into the data (not collided), then a new node is inserted directly.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 3. If the same key already exists in the collision, then it is covered.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 4. When a tree structure is found after collision, it is mounted on the tree.
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 5. End insertion, if the number of nodes in the list reaches the upper line, it will be converted to red-black tree.
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 6. Collision in the list
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 7. Replace old value with new value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 8. Operational thresholds are expanded
if (++size > threshold)
resize();
// Implementation of LinkedHashMap
afterNodeInsertion(evict);
return null;
}
Brief description of the logic of put, which is divided into the following steps:
- First, determine whether or not to initialize. If not, initialize the array with an initial capacity of 16.
- Get array subscripts by hash &(n-1). If the position is empty, it means no collision, insert data directly.
- If a collision occurs and the same key exists, it will be covered directly in subsequent processing.
- When the collision is found to be a tree structure, it is mounted directly on the red-black tree.
- When the collision is found to be linked list structure, tail insertion is carried out, and when the linked list capacity is greater than or equal to 8, it is converted to tree node.
- If a collision is found in the linked list, the direct coverage is handled later.
- The same key was found before, replacing the old value with the new value directly
- When the capacity of map (the number of storage elements) is larger than the threshold value, the capacity of map is expanded to twice the previous capacity.
Capacity expansion
In the resize() method, if you find that the current array is not initialized, the array is initialized. If it has been initialized, it will expand the capacity of the array to twice as much as before, and rehash (moving the data of the old array to the new array). The rehash process of JDK8 is interesting. Compared with JDK7, many optimizations have been made. Let's take a look at the rehash process here.
// Array expansion to the previous two times the size of code omission, here we mainly analyze the rehash process.
if (oldTab != null) {
// Traversing through old arrays
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 1. If there is no collision in the old array, move directly to the position of the new array.
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 2. If there is a collision and the node type is a tree node, the tree node is split (mounted in an expanded array or converted to a linked list)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 3. When dealing with conflicts is a linked list, the order of the original nodes will be preserved.
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 4. Determine whether the element is in its original position after expansion (very clever here, the following will be analyzed)
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 5. Elements are not in their original position
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 6. Copy elements that have not changed index after expansion to a new array
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 7. Copy the expanded index-changed elements to the new array
if (hiTail != null) {
hiTail.next = null;
// 8. After index changes, the new subscript is j+oldCap, which is also clever here. Here's an analysis
newTab[j + oldCap] = hiHead;
}
}
}
}
}
The above code shows the entire rehash process, first traversing the elements in the old array, and then doing the following
- If there is no data collision in the old array (no linked list or red-black tree is mounted), then the element is directly assigned to the new array, where index = E. hash & (newCap - 1).
- If there is a collision and the node type is a tree node, the tree node is split (mounted into an expanded array or converted to a linked list)
- If there is a collision and the nodes are linked lists, the rehash process will preserve the original order of the nodes (JDK7 will not be retained, which is also the cause of the multi-threaded dead cycle in jdk7).
- To determine whether the element is still in its original position after expansion, we use (e. hash & oldCap) == 0 to determine, and oldCap represents the size of the array before expansion.
- Update the directional relationship between hiTail and hiHead by finding that the element is not in its original position
- Copy elements that have not changed index after expansion to a new array
- Copy the elements that have changed the index position after expansion to the new array with the subscript j + oldCap.
In Points 4 and 5, the list elements are divided into two parts (do. while part), one is the unchanged element of index after rehash, and the other is the changed element of index. Two pointers are used to point to the head and tail nodes respectively.
For example, when oldCap=8, 1 - > 9 - > 17 is mounted on tab[1], while after expansion, 1 - > 17 is mounted on tab[1], and 9 is mounted on tab[9].
So how do you determine if index is changed after rehash? How much index has changed since then?
The design here is very clever, remember that the size of the array in HashMap is the n power of 2? When we calculate the index position, we use E. hash & (tab. length - 1).
Here we discuss the process of expanding array size from 8 to 16.
tab.length -1 = 7 0 0 1 1 1
e.hashCode = x 0 x x x x
==============================
0 0 y y y
It can be found that the location of index before expansion is determined by the lower three positions of hashCode. What about after expansion?
tab.length -1 = 15 0 1 1 1 1
e.hashCode = x x x x x x
==============================
0 z y y y
After expansion, the location of index is determined by the lower four bits, while the lower three bits are the same as before expansion. That is to say, the location of index after expansion is determined by high bytes. That is to say, we only need to calculate hashCode and high bit to get whether index is changed.
And just after the expansion, the high position is the same as the high position of oldCap. For example, the 15 binary above is 1111, while the 8 binary is 1000, their high bits are the same. So we can judge whether index is changed by the result of E. hash & oldCap operation.
Likewise, if the index changes after expansion. The value of the new index is also different from that of the old index. The new value is exactly the value of oldIndex + oldCap. So when index changes, the new index is j + oldCap.
At this point, the resize method ends and the element is inserted into its place.
get()
The get() method is relatively simple, and the most important thing is to find where the key is stored.
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1. First (n-1) & hash determines the location of elements
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 2. Determine whether the first element is the one we need to look for
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 3. If a node is a tree node, it looks for elements in the red-black tree.
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
4. Finding the corresponding node in the linked list
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
remove
The process of finding nodes by remove method is the same as that by get(). Here we mainly analyze how to deal with the process after finding nodes.
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 1. Delete the tree node, if it is not balanced, it will move the node position again.
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
// If the deleted node is the first node in the list, the second node is assigned to the first node directly.
else if (node == p)
tab[index] = node.next;
// The deleted node is the intermediate node of the list, where p is the prev node of the node.
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
In remote method, the most complex part should be the remove TreeNode part, because after deleting the red-black tree node, it may need to degenerate into linked list node, and it may also need mobile node location because it does not meet the characteristics of the red-black tree.
There's more code, so I won't post it here. But it also proves why red and black trees are not all used to replace linked lists.
Dead Cycle Problem Caused by JDK7 Expansion
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
// Thread B pauses after executing here
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
// The elements are put on the list header, so the expanded data will be inverted.
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
When expanding the capacity, the above code can easily lead to a dead cycle. How? Assuming that two threads A and B are executing this code, the array size is expanded from 2 to 4, tab [1]= 1 - > 5 - > 9 before expansion.
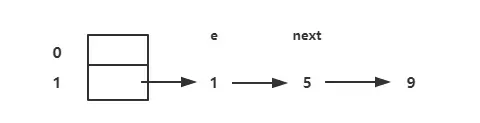
Before expansion
Thread B continues to execute when thread B executes to next = e.next and thread A executes the complete segment of code but has not set the internal table to a new new table.
When thread A has finished executing, the element mounted on tab[1] is 9 - > 5 - > 1. Note that the order here is reversed. At this time e = 1, next = 5;
tab[i] in the order of number of cycles, 1. tab[i] = 1, 2. tab[i] = 5 - > 1, 3. tab[i] = 9 - > 5 - > 1

After thread A is executed
Similarly, we analyze threads B according to the number of loops.
- When the first loop is completed, newTable[i]=1, e = 5
- After the second cycle is completed: newTable [i] = 5 - > 1, e = 1.
- In the third loop, E has no next, so next points to null. When e.next = newTable [i] (1 - > 5), a ring of 1 - > 5 - > 1 is formed, and then newTable[i]=e is executed, at which time newTable [i] = 1 - > 5 - > 1.
Dead loops occur when the get at the location of the array looks for the corresponding key, causing 100% CPU problems.
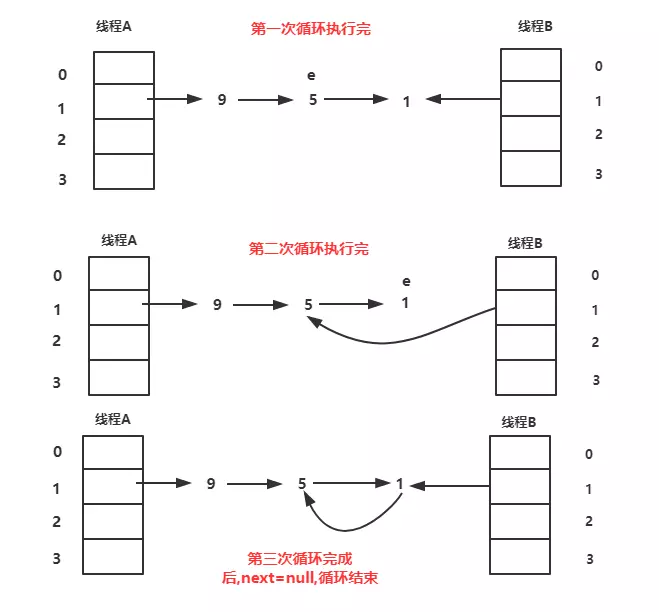
Thread B executes the expansion process
JDK8 does not have this problem, it has an optimization here, it uses two pointers to point to the head node and the tail node respectively, and also guarantees the original order of elements.
Of course, HashMap is still insecure, so Concurrent HashMap is recommended for multithreaded concurrency.
summary
1.HashMap Principle, Internal Data Structure?
The underlying layer uses hash tables (arrays plus linked lists) to store, and if the linked list is too long, it will turn the linked list into a red-black tree to search within the O(logn) time complexity.
2. Talk about the put method process in HashMap?
Hash the key and calculate the subscript
If there is no hash collision, put it directly into the slot
If the collision is linked to the back in the form of a linked list
If the list length exceeds the threshold (the default threshold is 8), the list is converted to a red-black tree.
Replace old values if nodes already exist
If the slot is full (capacity * load factor), resize is required
3. How to implement hash function in HashMap? What other hash implementations are there?
High 16 bits remain unchanged, low 16 bits and high 16 bits differ or
(n-1) & hash obtains subscript
What other hash implementations are there? (Search for information and blog)
4. How HashMap resolves conflicts? Expansion process. If a value moves to a new array after expansion in the original array, the position must change. How to locate the value in the new array?
Add nodes to the list
The capacity is doubled and the hash value is recalculated for each node.
This value can only be in two places: one is in the original subscript position, and the other is in the position with the subscript < original subscript + original capacity >.
5. Apart from HashMap, what are the solutions to hash conflict?
Open Address Method, Chain Address Method
6. For an Entry chain in HashMap which is too long, the time complexity of searching may reach O(n), how to optimize it?
JDK 1.8 has been implemented to convert the linked list to a red-black tree