Only in cluster mode mongo Can be used changeStream The function of, This function is mainly to monitor in real time mongo Changes to the database, And obtain the changed information, changeStream The principle is to monitor all the time mongo of opLog Log changes to this file, To read this file, as we all know, we have mongo The database will operate opLog This file is recorded. We just need to get it opLog Just change the information No matter how encapsulated, changeStream The principle is the same, that is, keep going read opLog This file, then get the updated message, and finally return the message, Of course, such operations also support some filtering conditions and some parameters
Mongo native driver uses changeStream function
The main core is several dependencies
<properties>
<driver.version>4.1.1</driver.version>
</properties>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver-sync</artifactId>
<version>${driver.version}</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver-core</artifactId>
<version>4.1.1</version>
</dependency>
<!-- reactive -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver-reactivestreams</artifactId>
<version>${driver.version}</version>
</dependency>
The way of operation is also relatively simple
public class MongoChangeStreamTest {
private MongoClient mongoClient;
private MongoDatabase database;
@Before
public void init(){
mongoClient = MongoClients.create("mongodb://127.0.0.1:37017,127.0.0.1:37018,127.0.0.1:37019");
database = mongoClient.getDatabase("myrepo");
}
@Test
public void testChange(){
MongoCollection<Document> collection = database.getCollection("cs");
Document doc = new Document("name", "MongoDB")
.append("type", "database")
.append("count", 1)
.append("age", 21)
.append("info", "xx");
collection.insertOne(doc);
}
@Test
public void testChangeStream(){
MongoCollection<Document> collection = database.getCollection("cs");
collection.find().forEach(doc -> System.out.println(doc.toJson()));
ChangeStreamIterable<Document> watch = collection.watch();
MongoCursor<ChangeStreamDocument<Document>> iterator = watch.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
@Test
public void testWatch(){
MongoCollection<Document> collection = database.getCollection("cs");
collection.watch(asList(Aggregates.match(Filters.in("operationType", asList("insert", "update", "replace", "delete")))))
.fullDocument(FullDocument.UPDATE_LOOKUP)
.forEach(System.out::println);
}
@After
public void close(){
mongoClient.close();
}
}
Spring operation changeStream
The above are several usages. These are the java driver package provided by mongo. Of course, we can also use spring to help us integrate them,
The first is to introduce dependency
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
Spring provides us with configurable usage. The general meaning is that there is a listener container in spring. I can put my own defined listeners into it. Of course, my own defined listeners can choose various operation types, such as I want to filter some operations and monitor some collection operations, These can be realized through configuration,
@Configuration
public class MongoConfig {
@Bean
MessageListenerContainer messageListenerContainer(MongoTemplate template, DocumnetMessageListener documnetMessageListener) {
Executor executor = Executors.newSingleThreadExecutor();
MessageListenerContainer messageListenerContainer = new DefaultMessageListenerContainer(template, executor) {
@Override
public boolean isAutoStartup() {
return true;
}
};
ChangeStreamRequest<Document> request = ChangeStreamRequest.builder(documnetMessageListener)
.collection("cs") //The name of the collection that needs to be monitored. The name of the default monitoring database is not specified
.filter(newAggregation(match(where("operationType").in("insert", "update", "replace")))) //Filter the operation types that need to be monitored. You can specify filter conditions as required
.fullDocumentLookup(FullDocument.UPDATE_LOOKUP) //When you do not change the field settings of the document, only the updated information will be sent_ Lookup returns all the information of the document
.build();
messageListenerContainer.register(request, Document.class);
return messageListenerContainer;
}
}
@Component
@Slf4j
public class DocumnetMessageListener implements MessageListener<ChangeStreamDocument<Document>, Document> {
@Override
public void onMessage(Message<ChangeStreamDocument<Document>, Document> message) {
System.out.println("receive message: " + message);
log.info("Received Message in collection: {},message raw: {}, message body:{}",
message.getProperties().getCollectionName(), message.getRaw(), message.getBody());
}
}
It is probably the above two configuration classes. One configuration class specifies to inject the listening container into the Spring container, and then specify the listening rules. The other is to inject the self-defined listener into the container, and then implement the rules after listening to the message.
It is also very simple to use. Let's share the test cases
In short, let's start the container and make it work, and then keep the current thread.
@Test
public void testWatch3() throws InterruptedException {
System.out.println(mars.getDatabase().getName());
messageListenerContainer.start();
Thread.currentThread().join();
}
Here's the point
Do you think this is over?
Unfortunately, the task I received is not to understand how they are used and then use them in the project. My task is to analyze how Spring is implemented, and then write this implementation into our current project, so that others can easily implement this function like using Spring. Generally speaking, we should write a framework for this aspect ourselves. Like Spring, I read it online. github actually has many frameworks about mongodb, such as morphia, but it doesn't seem to support this function. Finally, I chose to copy Spring.
First, go to the source code of Spring to find the code in this area
This is probably the structure. These are the core codes in this aspect. Of course, other functions will also be used. I see that there seem to be functions in Aggregation, and Converter. This aspect also feels like a large module, so I really don't have the ability to deal with it for the time being, Later I will explain their respective functions and possible alternatives.
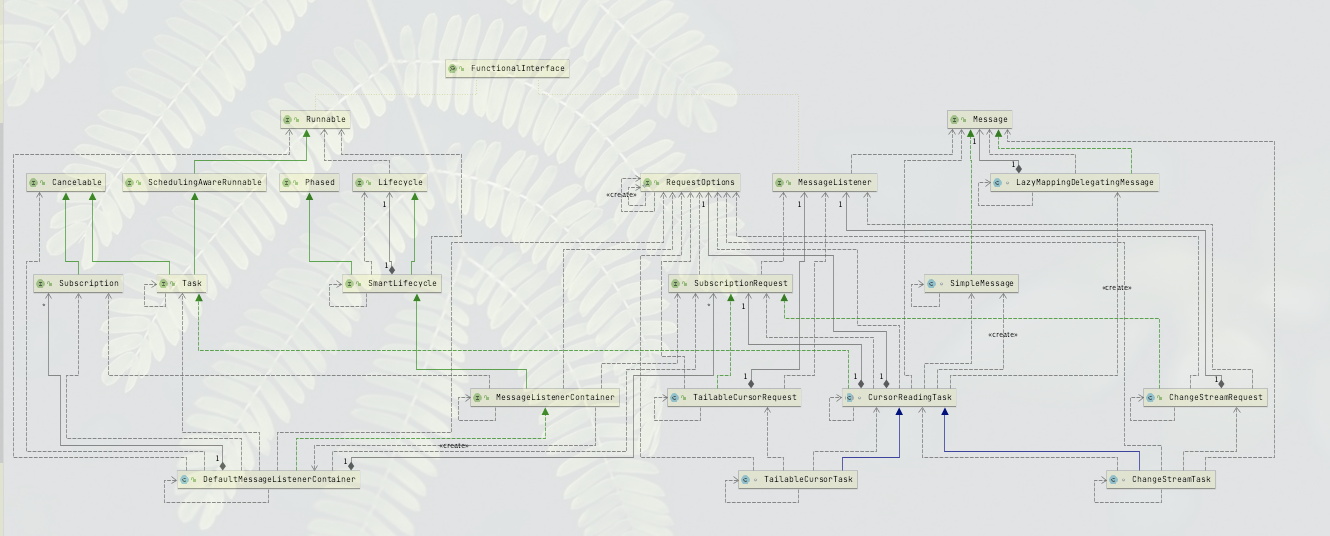
You can see the overall framework. The CursorReadingTask class plays a starting role, and ChangeStreamTask is one of its implementations
An important method implementation in this class is to initialize the cursor
@Override
protected MongoCursor<ChangeStreamDocument<Document>> initCursor(MongoTemplate template, RequestOptions options,
Class<?> targetType) {
List<Document> filter = Collections.emptyList();
BsonDocument resumeToken = new BsonDocument();
Collation collation = null;
FullDocument fullDocument = ClassUtils.isAssignable(Document.class, targetType) ? FullDocument.DEFAULT
: FullDocument.UPDATE_LOOKUP;
BsonTimestamp startAt = null;
boolean resumeAfter = true;
if (options instanceof ChangeStreamRequest.ChangeStreamRequestOptions) {
ChangeStreamOptions changeStreamOptions = ((ChangeStreamRequestOptions) options).getChangeStreamOptions();
filter = prepareFilter(template, changeStreamOptions);
if (changeStreamOptions.getFilter().isPresent()) {
Object val = changeStreamOptions.getFilter().get();
if (val instanceof Aggregation) {
collation = ((Aggregation) val).getOptions().getCollation()
.map(org.springframework.data.mongodb.core.query.Collation::toMongoCollation).orElse(null);
}
}
if (changeStreamOptions.getResumeToken().isPresent()) {
resumeToken = changeStreamOptions.getResumeToken().get().asDocument();
resumeAfter = changeStreamOptions.isResumeAfter();
}
fullDocument = changeStreamOptions.getFullDocumentLookup()
.orElseGet(() -> ClassUtils.isAssignable(Document.class, targetType) ? FullDocument.DEFAULT
: FullDocument.UPDATE_LOOKUP);
startAt = changeStreamOptions.getResumeBsonTimestamp().orElse(null);
}
MongoDatabase db = StringUtils.hasText(options.getDatabaseName())
? template.getMongoDbFactory().getMongoDatabase(options.getDatabaseName())
: template.getDb();
ChangeStreamIterable<Document> iterable;
if (StringUtils.hasText(options.getCollectionName())) {
iterable = filter.isEmpty() ? db.getCollection(options.getCollectionName()).watch(Document.class)
: db.getCollection(options.getCollectionName()).watch(filter, Document.class);
} else {
iterable = filter.isEmpty() ? db.watch(Document.class) : db.watch(filter, Document.class);
}
if (!options.maxAwaitTime().isZero()) {
iterable = iterable.maxAwaitTime(options.maxAwaitTime().toMillis(), TimeUnit.MILLISECONDS);
}
if (!resumeToken.isEmpty()) {
if (resumeAfter) {
iterable = iterable.resumeAfter(resumeToken);
} else {
iterable = iterable.startAfter(resumeToken);
}
}
if (startAt != null) {
iterable.startAtOperationTime(startAt);
}
if (collation != null) {
iterable = iterable.collation(collation);
}
iterable = iterable.fullDocument(fullDocument);
return iterable.iterator();
}
You need to pass in Mongo's operation template and operation options. This operation option is RequestOptions. We can clearly see that the internal class of changestreamrequesoptions has an implementation for it and the method of preparing filter,
List<Document> prepareFilter(MongoTemplate template, ChangeStreamOptions options) {
if (!options.getFilter().isPresent()) {
return Collections.emptyList();
}
Object filter = options.getFilter().orElse(null);
if (filter instanceof Aggregation) {
Aggregation agg = (Aggregation) filter;
AggregationOperationContext context = agg instanceof TypedAggregation
? new TypeBasedAggregationOperationContext(((TypedAggregation<?>) agg).getInputType(),
template.getConverter().getMappingContext(), queryMapper)
: Aggregation.DEFAULT_CONTEXT;
return agg.toPipeline(new PrefixingDelegatingAggregationOperationContext(context, "fullDocument", denylist));
}
if (filter instanceof List) {
return (List<Document>) filter;
}
throw new IllegalArgumentException(
"ChangeStreamRequestOptions.filter mut be either an Aggregation or a plain list of Documents");
}
It can be seen that we have used the function of Aggregation. We can see that this function is mainly implemented to filter, similar to operation, and also to use the type converter in the operation template. The type converter is a huge and complex problem. I remember it was first proposed by spring MVC, You can even use our function to manually inject @ Bean into the container,
Because we didn't use the operation template of mongo, but used our own operation template, so we can't use it. The converter is not so flexible, and it has become a static tool class (this code I think is too soulless). The filter can't understand for the time being, so in the end, I chose to give up,
So in the end it looks like this
List<Document> prepareFilter(MongoTemplate template, ChangeStreamOptions options) {
if (!options.getFilter().isPresent()) {
return Collections.emptyList();
}
Object filter = options.getFilter().orElse(null);
if (filter instanceof List) {
return (List<Document>) filter;
}
throw new IllegalArgumentException(
"ChangeStreamRequestOptions.filter mut be either an Aggregation or a plain list of Documents");
}
There is no need to change anything else. Finally, the project was successfully launched, but one problem is that filtering of various operations is not supported at present. This is related to the function of Aggregation, which will be continuously improved in the future.
What I said later is vague and difficult to understand. If you have any questions, you can add my WX to communicate q1050564479.