Use the json header file to view the coco format json
You can use the json of coco2017 to test with me
#Use the json header file to read into the coco dataset
import json
with open("/home/fengsiyuan/detectron2/datasets/coco/annotations/coco_ycbv_train_000000.json",'r') as load_f:
f = json.load(load_f)
print(f.keys())

#Take a look at the annotations information in this file f['annotations']
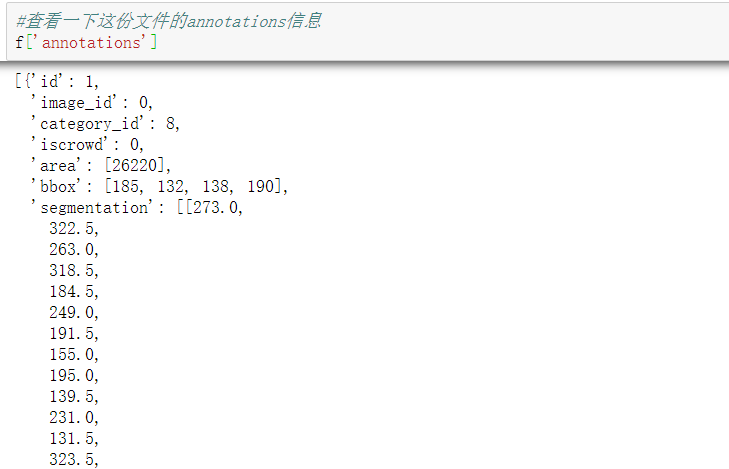
#Read the information of the first annotation box in annotations f['annotations'][0]
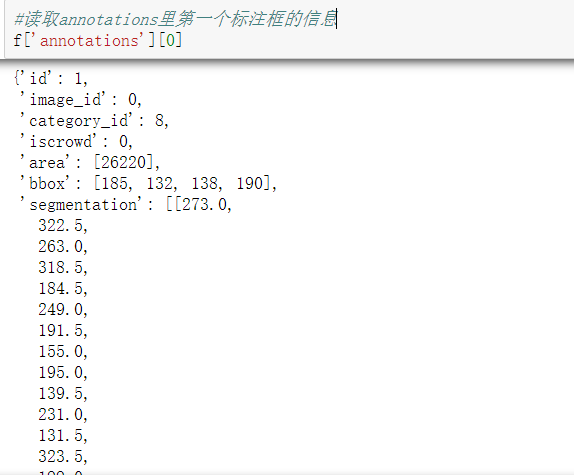
#Read the first bbox f['annotations'][0]['bbox']
#Read the info information of this file f['info']
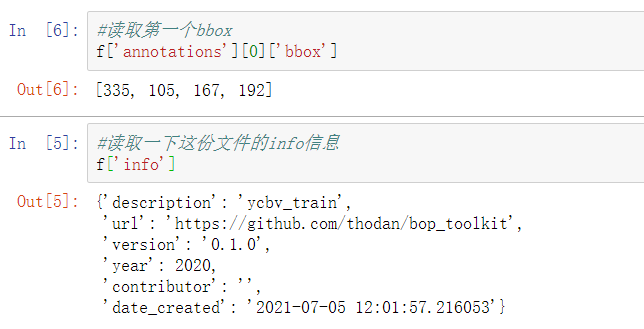
#Read the licenses information in this file f['licenses']
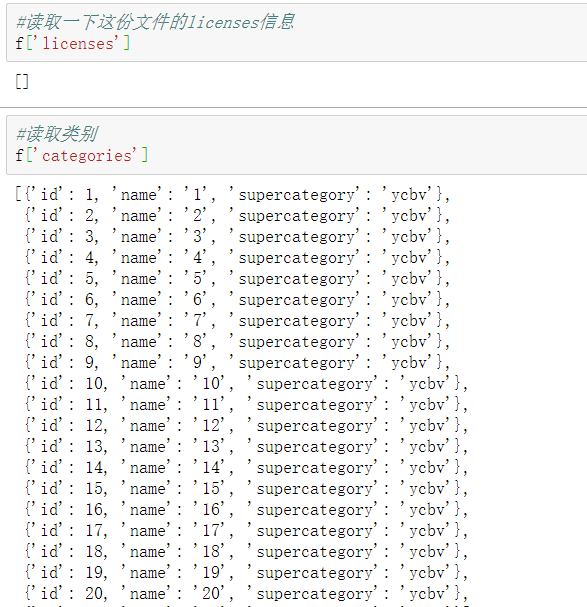
#Read category f['categories']
#Read picture information f['images']
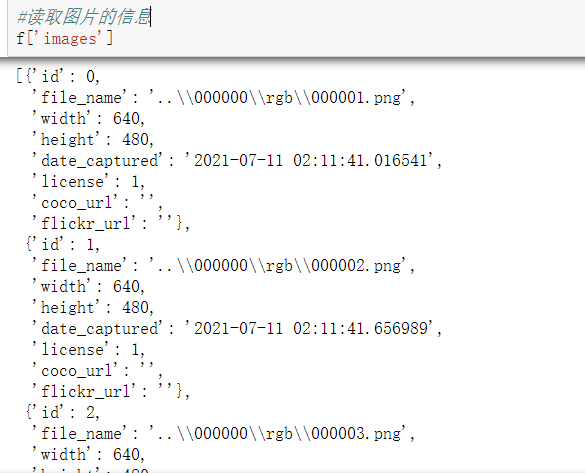
#Try reading the box with id=0 f['images'][0]
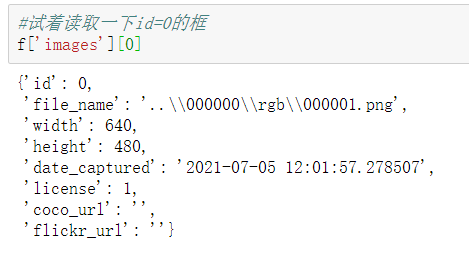
#Try reading the file path again #Then modify the file path according to this f['images'][0]['file_name']
#File pointer closed #Reference code [Python file open, close, file pointer]( https://blog.csdn.net/Smile_Mr/article/details/83179473) load_f.close()
Use the COCO API to view JSON in COCO format
[COCO dataset] Introduction to COCO API super detailed notes
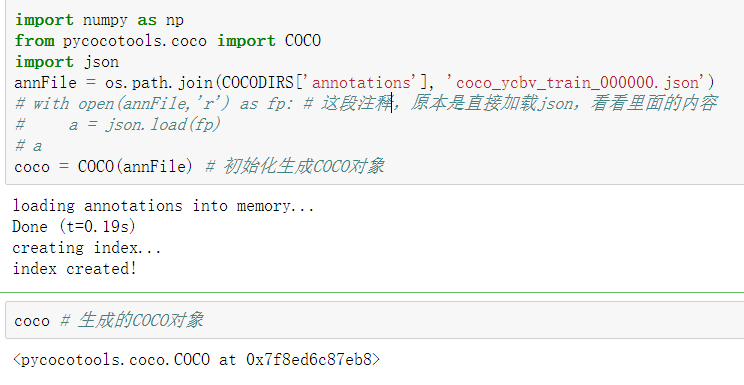
load annotations file(Load here instances_val2017.json),generate COCO object import numpy as np from pycocotools.coco import COCO import json annFile = os.path.join(COCODIRS['annotations'], 'coco_ycbv_train_000000.json') # with open(annFile,'r') as fp: # This comment was originally to load json directly to see the contents # a = json.load(fp) # a coco = COCO(annFile) # Initializing and generating COCO objects
coco # Generated COCO object
- coco. Getcat id s() this function is used to obtain the IDs of all categories contained in the loading object (i.e. the sequence number of category)
- coco.getAnnIds() gets all the tag information contained in the loading object (that is, the Segmentation of all pictures, that is, the divided coordinate data)
- coco.getImgIds() gets the original image id corresponding to all tags
categories = coco.loadCats(coco.getCatIds()) # loadCats() needs to pass in the category id sequence (catIds) to be loaded #categories[:10] # For beautiful output, only 10 pieces of data are displayed categories[:]#Show all data
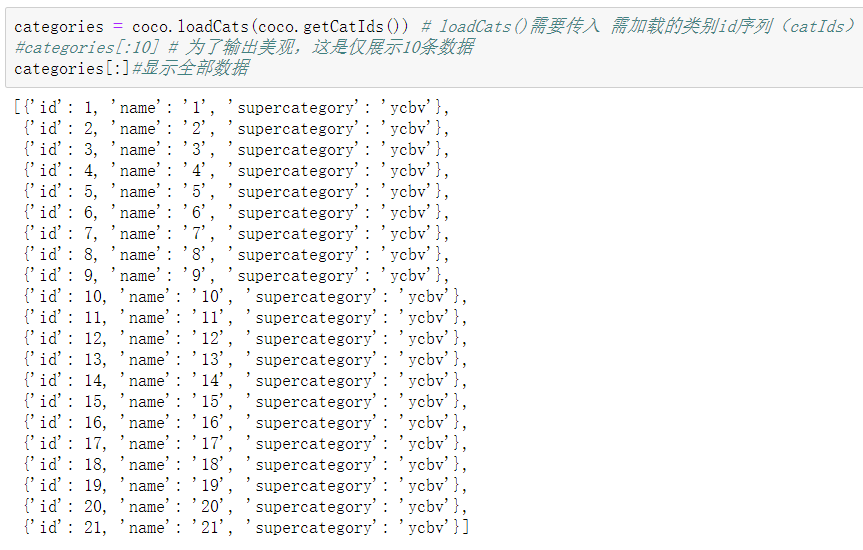
names = [cat['name'] for cat in categories] #names[:10]#For beautiful output, we only show ten categories here names[:]#Show all categories

Get the category sequence number of the specified name (find the category id with category name x)
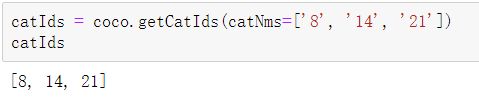
Here, the category id corresponding to 8, 14 and 21 is obtained because my dataset json file only contains objects of categories 8, 14 and 21
catIds = coco.getCatIds(catNms=['8', '14', '21']) catIds
Get all picture IDs that match cat id s
That is, the categories we obtained above are 8, 14 and 21, so we can obtain the id corresponding to the pictures containing these three categories in the picture
- Note that getImgIds takes the intersection, not the union. Adding an id will only return the empty string ¶
imgIds = coco.getImgIds(catIds=catIds) imgIds
Randomly select a picture from the sequence numbers of all the pictures that meet the above conditions (here, the random function of numpy) and load the information of the picture through loadImgs()
img_info = coco.loadImgs(imgIds[np.random.randint(0, len(imgIds))]) img_info
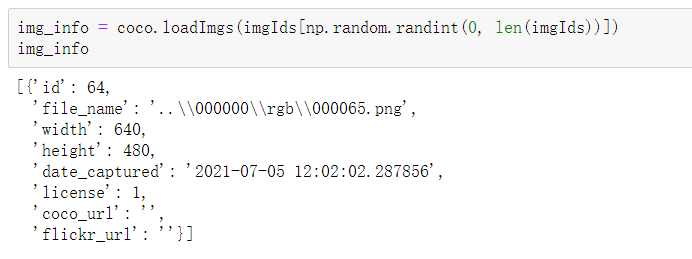
You can see that loadImgs() returns a list, and each element is the specific information of a corresponding image
Since what we need here is a picture information, we use the following method to extract the first information
img_info = coco.loadImgs(imgIds[np.random.randint(0, len(imgIds))])[0] #Select only one picture to try (the bottom line of code can only be run once, so we annotated the bottom and selected the above code to run) #img_info = img_info[0] img_info
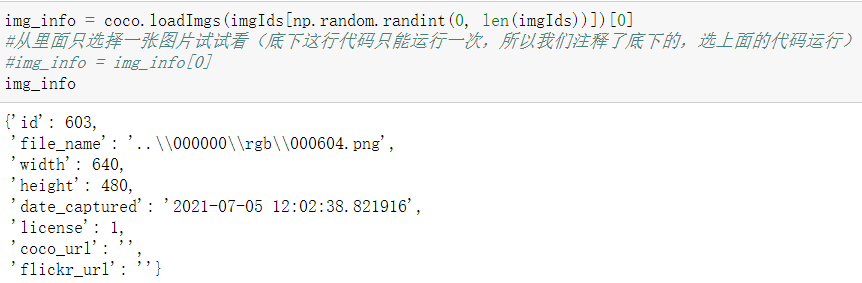
You can see that the obtained picture information includes:
- license
- file_name
- coco_url
- height
- width
- date_captured
- flickr_url
- id
Modify the coco format json using the json header file
Let me take the filename of the json file I modified ycbv as an example
import json
dic = {}
with open("/home/fengsiyuan/detectron2/datasets/coco/annotations/data_train.json",'r',encoding='utf8') as load_f:
f = json.load(load_f)
print(f.keys())

#Read picture information f['images']
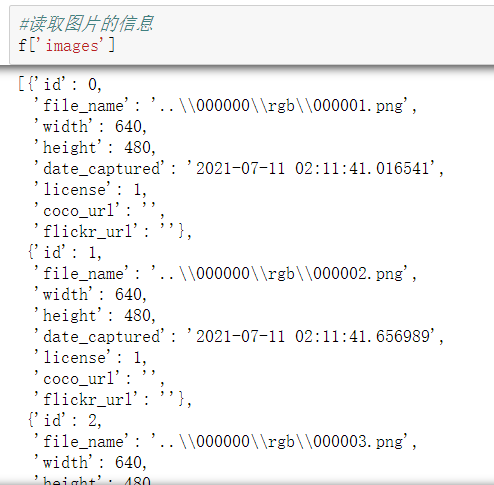
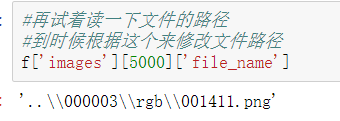
As you can see, the file in my file_name is'... \ 000000 \ RGB \ 00000 1 Png 'format. I can't use this format in detectron2, so I want to use python's string function to change it to' / 000000 / RGB / 00000 1 png’
for num in range(0,len(f['images'])):
#print(num)
#print(img[num]['file_name'])
str = f['images'][num]['file_name']
str = str.replace('..\\','')
str = str.replace('\\','/')
#print(str)
f['images'][num]['file_name']=str
print(f['images'][num]['file_name'])
#Save all the processing just now to dic, and then close load_f
dic = {}
dic = f
load_f.close()
Now reopen the file and use the jump function to overwrite the modified content into the file
with open("/home/fengsiyuan/detectron2/datasets/coco/annotations/data_train.json",'w') as load_f:
json.dump(dic,load_f)
load_f.close()
Check the result of the modification
#Check the modification results
with open("/home/fengsiyuan/detectron2/datasets/coco/annotations/data_train.json",'r',encoding='utf8') as load_f:
f = json.load(load_f)
print(f.keys())
f['images'][113197]
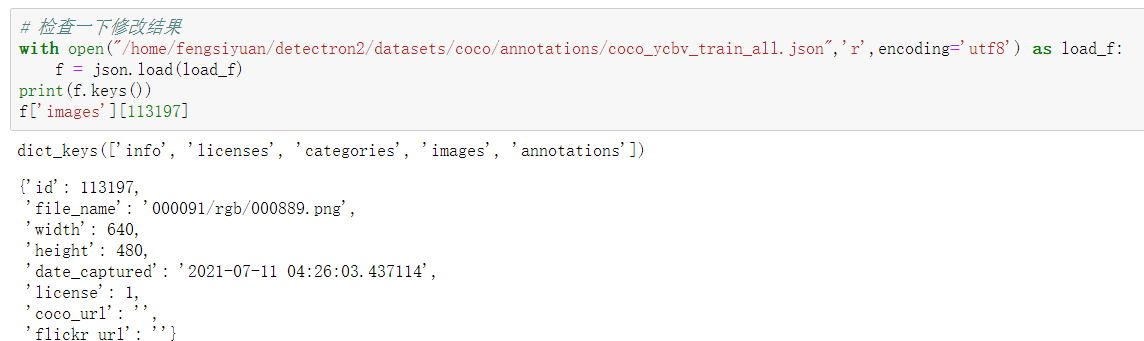
As you can see, the file of the file_name has been modified to the format we want. So we close the file pointer
load_f.close()