1, Background
When we use logstash to read data from the outside, the values read by default are of string type. Suppose we need to modify the type of field value at this time. If we change from string to integer, or delete the field, modify the name of the field, give a default value to the field, we can use mutate filter at this time.
2, Demand
1. Read data from the file. The data in the file conforms to the csv format, that is, it is separated by and by default.
2. Delete the read field, modify the value of the field, modify the type of the field, give a default value, merge the field, etc.
3, Implementation steps
1. Install csv codec plug-in
be careful ⚠️:
By default, the csv codec plug-in is not installed. We need to install it manually. Execute the following command: bin / logstash plugin install logstash codec CSV
# Enter the installation directory of logstash cd /Users/huan/soft/elastic-stack/logstash/logstash # Monitor whether the csv codec plug-in is installed bin/logstash-plugin list --verbose # Install csv plug-in bin/logstash-plugin install logstash-codec-csv

2. Prepare the file data to be read
| user_ real_name | user_ english_name | age | address | education | strip_blank | language | default_value | create_time |
|---|---|---|---|---|---|---|---|---|
| Zhang San | zhangSan | 20 | Hubei Province; Luotian County | Education - Bachelor degree | Remove leading and trailing spaces | java | Default value | 20210512 08:47:03 |
| Li Si | lisi | 18 | Hubei Province; Huanggang | Education - Junior College | Remove the first space | C | 20210512 03:12:20 |
3. Write pipeline, read and output data
input {
file {
id => "mutate-id"
path => ["/Users/huan/soft/elastic-stack/logstash/logstash/pipeline.conf/filter-mutate/mutate.csv"]
start_position => "beginning"
sincedb_path => "/Users/huan/soft/elastic-stack/logstash/logstash/pipeline.conf/filter-mutate/sincedb.db"
codec => csv {
columns => ["user_real_name","user_english_name","age","address","education","strip_blank","language","default_value","create_time"]
charset => "UTF-8"
separator => ","
skip_empty_columns => false
convert => {
"age" => "integer"
}
}
}
}
output {
stdout {
codec => rubydebug {
}
}
}
- csv codec plug-in explanation
- columns: defines the column names of a set of parsed csv, which is also the field names of later stage
- charset: character encoding
- separator: defines what is used to separate a row of data read. csv files are generally separated by, or tab. The default is comma
- skip_empty_columns: whether to skip empty columns if the value is empty.
- true: skip
- false: do not skip
- convert: data type conversion. By default, the type of the value read is string. Here, the data type of the value of the age field is converted to integer
4. Use of mutate plug-in
Preconditions:
1. Unless otherwise specified, the data of the test data is the data in the file data to be read in the implementation step > preparation
matters needing attention:
1. Both update and replace are the values of the updated field, but if the value of the field updated by update does not exist, it will have no effect, but replace will add this field.
2. The target value of the copy field. If it exists, the value will be overwritten. Otherwise, a new field will be added.
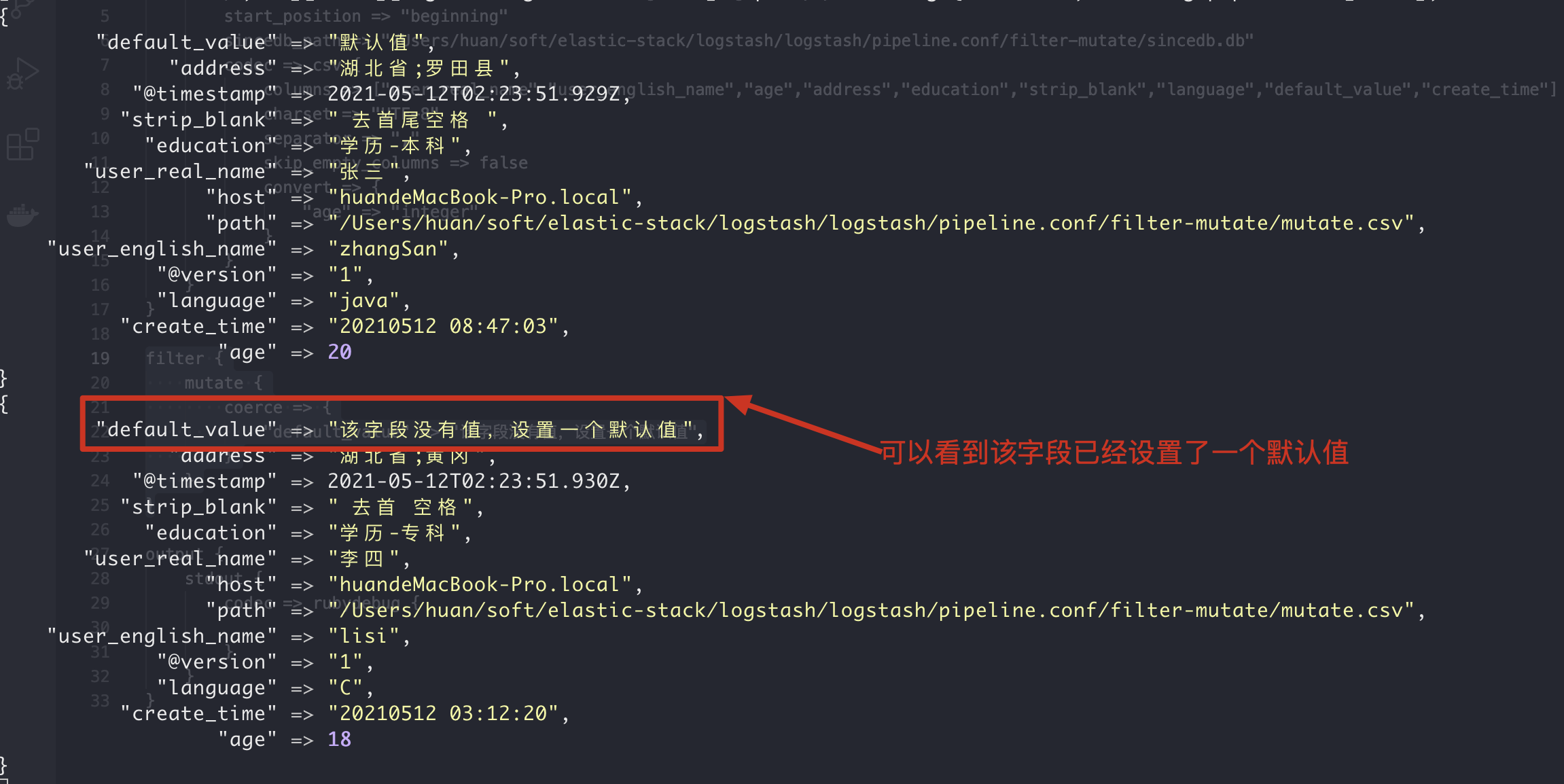
1. coerce sets the default value for the field
If a field already exists and its value is null, we can use coerce to set the default value for it
1. Writing method of configuration file
filter {
mutate {
coerce => {
"default_value" => "This field has no value. Set a default value"
}
}
}
2. Execution results
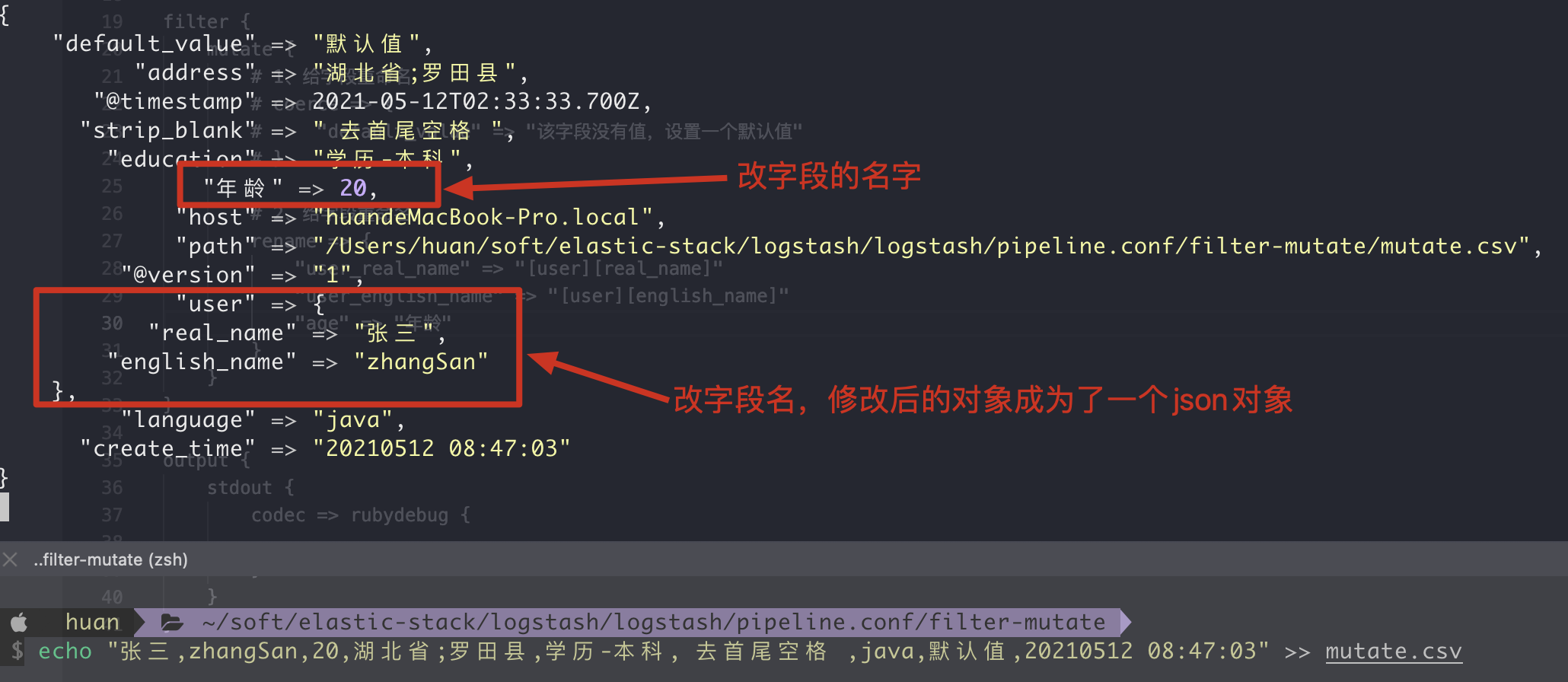
2. rename renames the field
1. Writing method of configuration file
filter {
mutate {
rename => {
"user_real_name" => "[user][real_name]"
"user_english_name" => "[user][english_name]"
"age" => "Age"
}
}
}
2. Execution results
3. update updates the value of the field
1. Writing of configuration file
filter {
mutate {
# 1. Update the value of the field
update => {
"user_address" => "The user's address is: %{address}"
}
}
}
2. Execution results
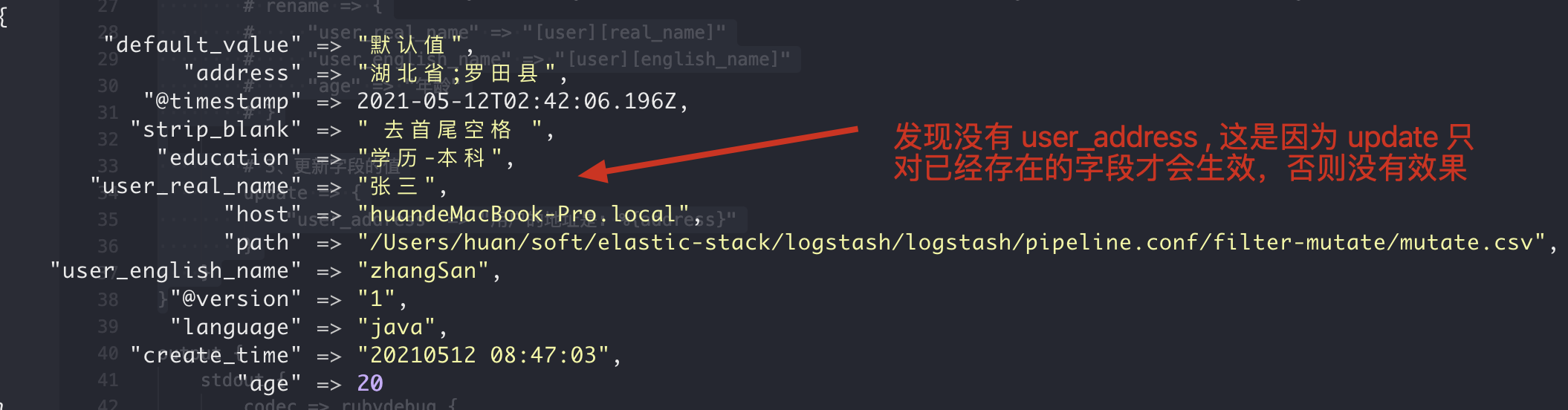
3. Explain
Update to update the value. The updated field must exist, otherwise it will have no effect.
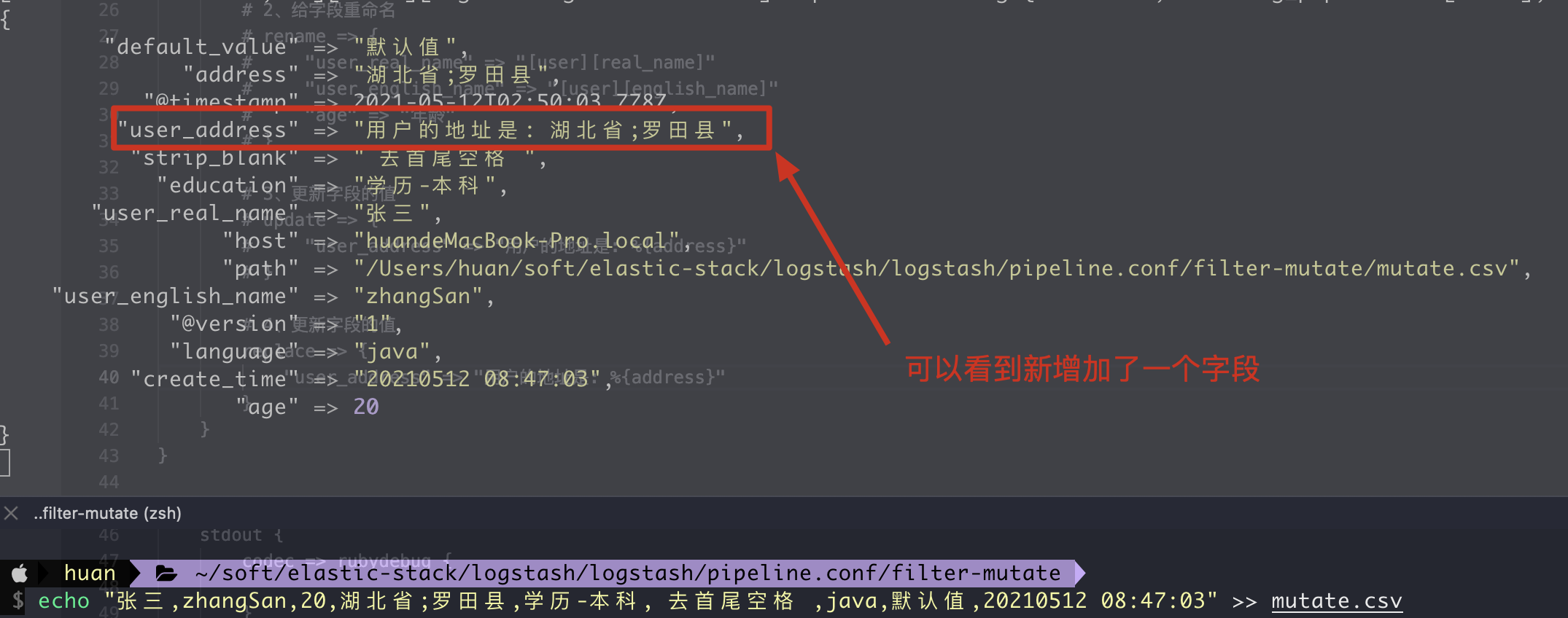
4. replace updates the value of the field
1. Writing method of configuration file
filter {
mutate {
# 1. Update the value of the field
replace => {
"user_address" => "The user's address is: %{address}"
}
}
}
2. Execution results
5. convert data type conversion
1. Data types that can be converted
integer,integer_eu,float,float_eu,string,boolean
2. Writing method of configuration file
filter {
mutate {
# 1. Data type conversion
convert => {
"age" => "string"
}
}
}
3. Execution results
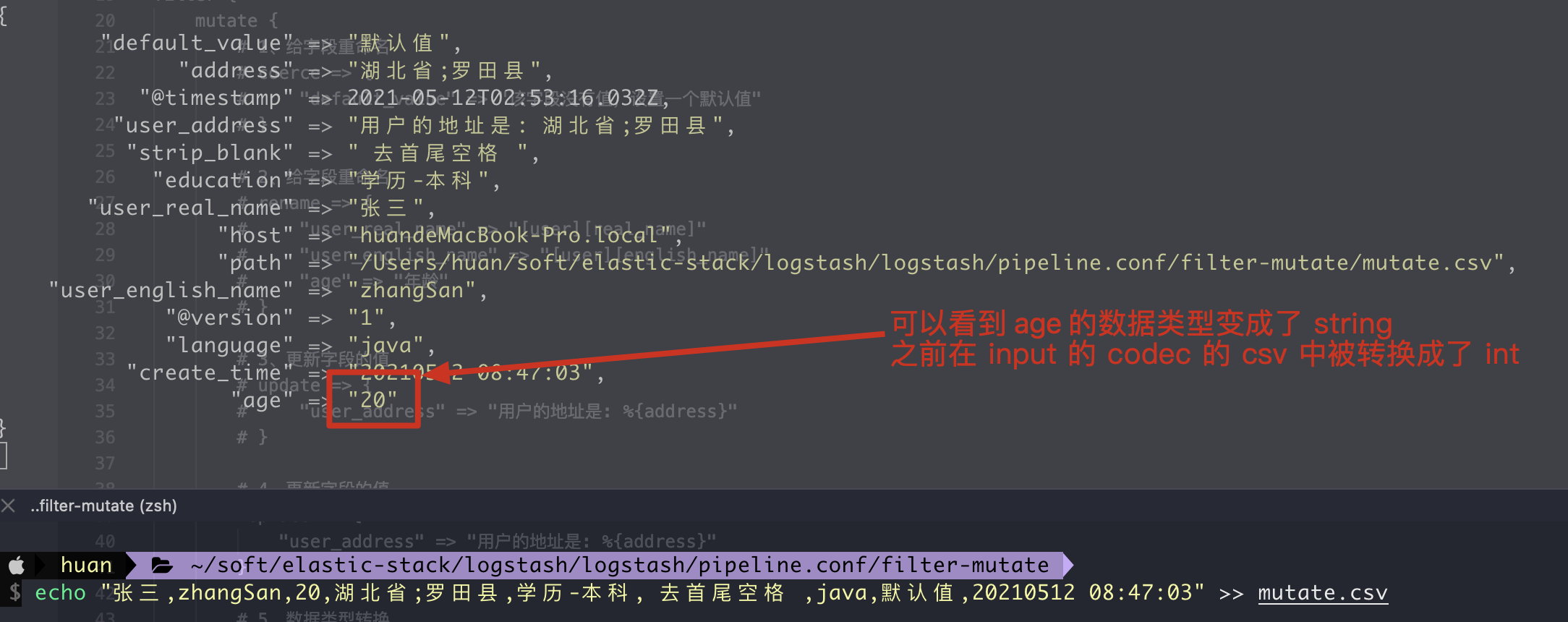
6. gsub replaces the contents of the field
1. Writing method of configuration file
filter {
mutate {
# 1. Replace the content of the field. The second parameter can be written in regular expression. The replaced field can only be string type or string type array
gsub => [
"address", ";", "--"
]
}
}
2. Execution results
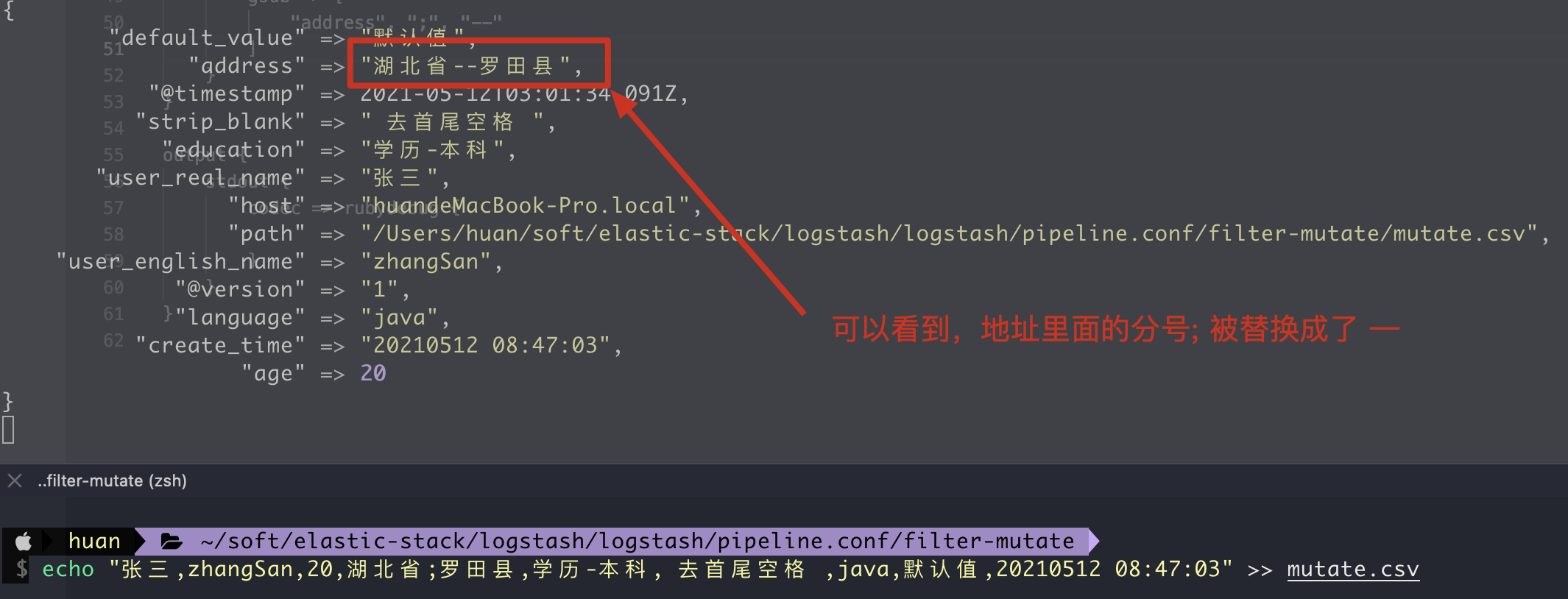
7. Uppercase, capitalize, lowercase, uppercase, lowercase
1. Configuration file writing method
filter {
mutate {
# 1.1 capitalization
uppercase => ["language"]
# 2.2 figures
# lowercase => ["user_english_name"]
# 3.3 initial capitalization
capitalize => ["user_english_name"]
}
}
Priority needs attention.
2. Execution results

8. strip removes leading and trailing spaces
1. Writing method of configuration file
filter {
mutate {
# Remove leading and trailing spaces
strip => ["strip_blank"]
}
}
2. Execution results
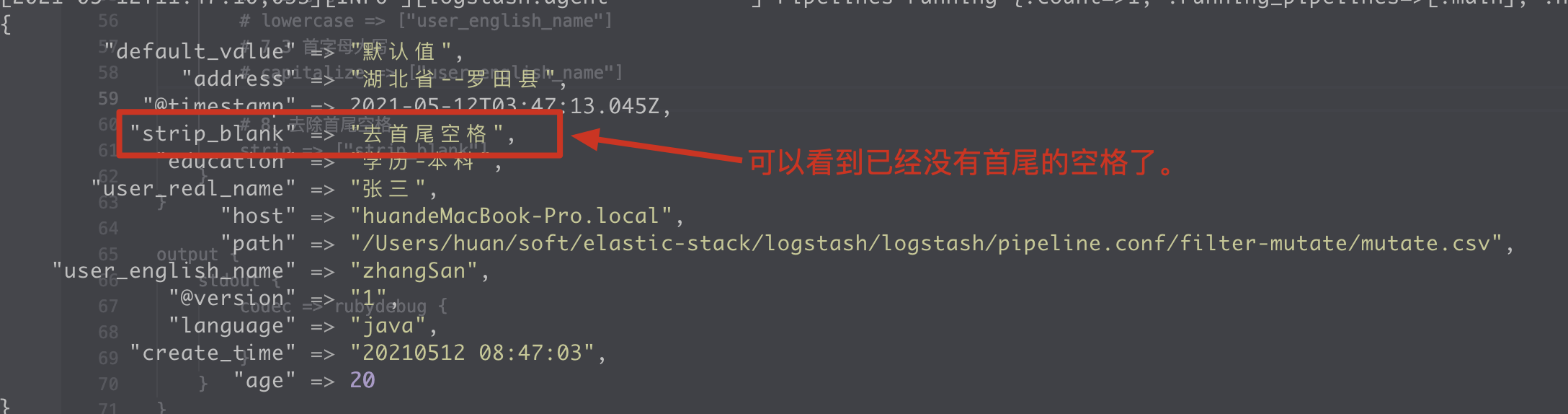
9. Remove remove field
1. Writing method of configuration file
filter {
mutate {
# Remove the field. If the value of username in the Event is zhangsan, the field name foo will be removed_ zhangsan this field.
remove_field => ["user_real_name","foo_%{username}"]
}
}
2. Execution results
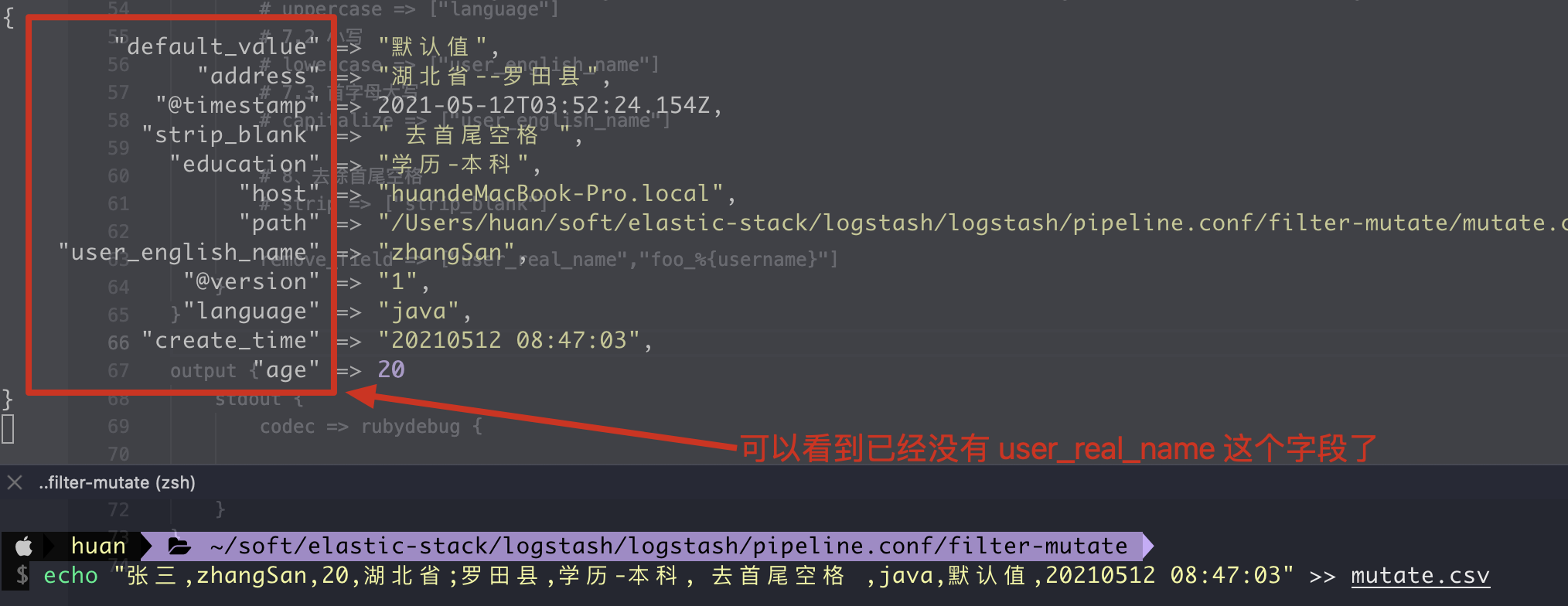
10. split cut field
1. Writing method of configuration file
filter {
mutate {
# 1. Cut field
split => {
"address" => ";"
}
}
}
2. Execution results
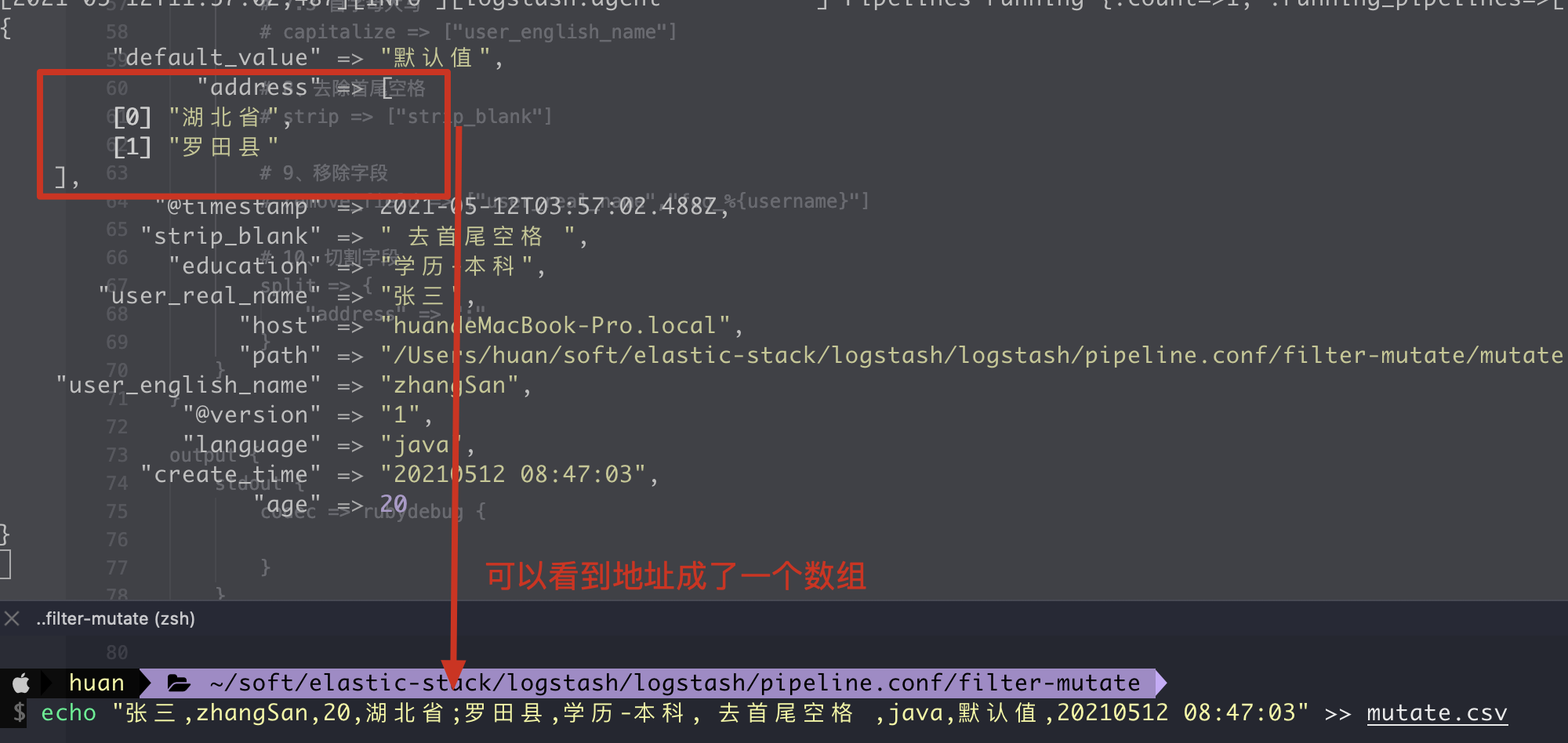
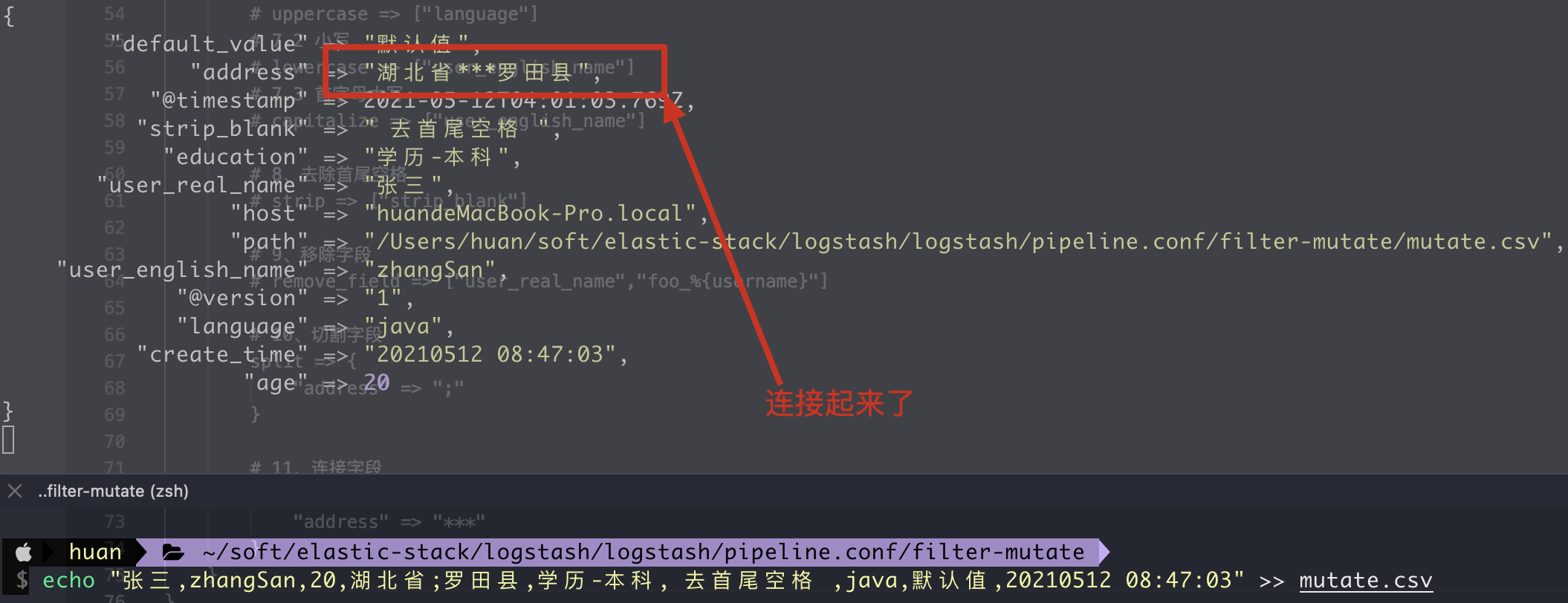
11. join connection field
1. Writing method of configuration file
filter {
mutate {
# 1. Cut field
split => {
"address" => ";"
}
# 2. Connection field
join => {
"address" => "***"
}
}
}
First use split to cut into an array, and then use join to connect
2. Execution results
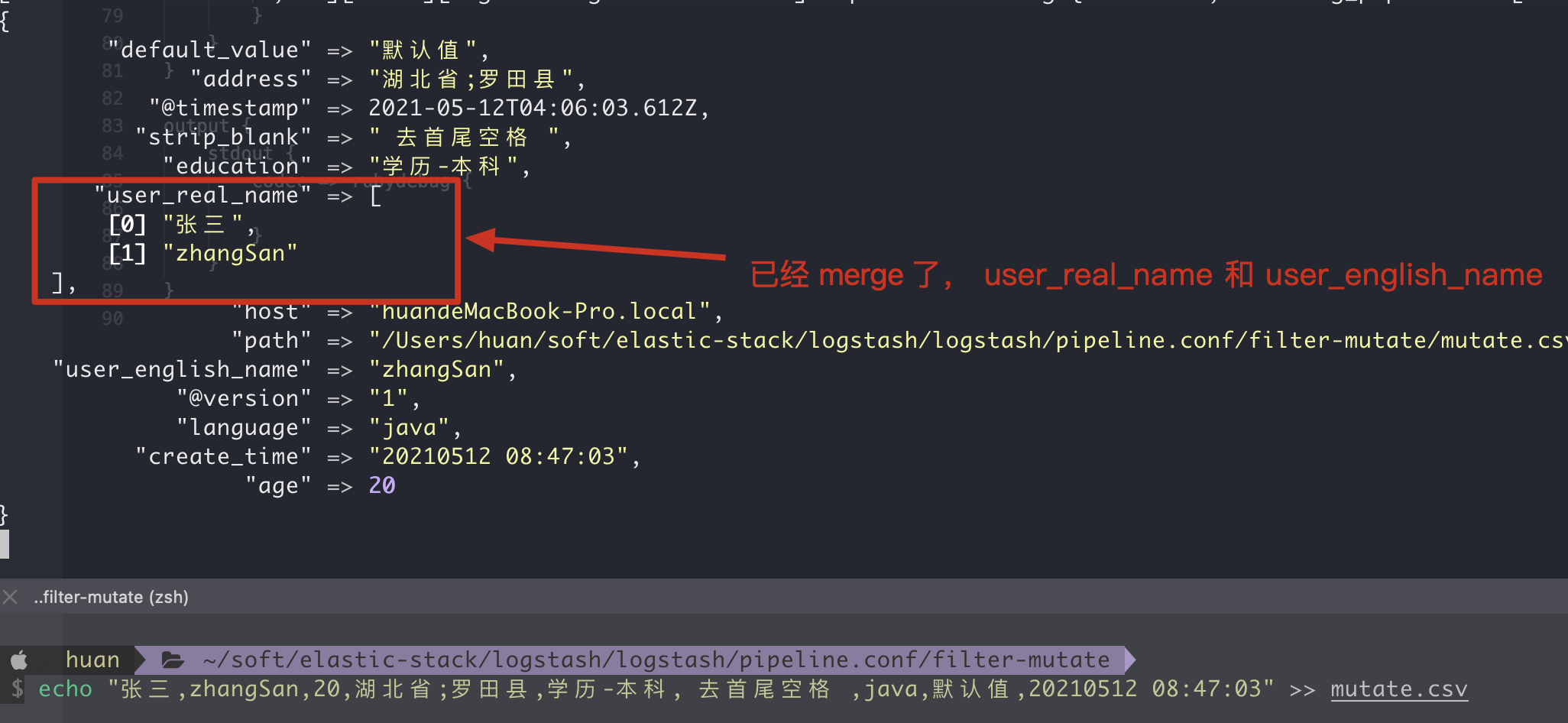
12. Merge field merge
1. Situations that can be merged
`array` + `string` will work `string` + `string` will result in an 2 entry array in `dest_field` `array` and `hash` will not work
2. Writing method of configuration file
filter {
mutate {
# 1. Field merge
merge => {
"user_real_name" => "user_english_name"
}
}
}
3. Execution results
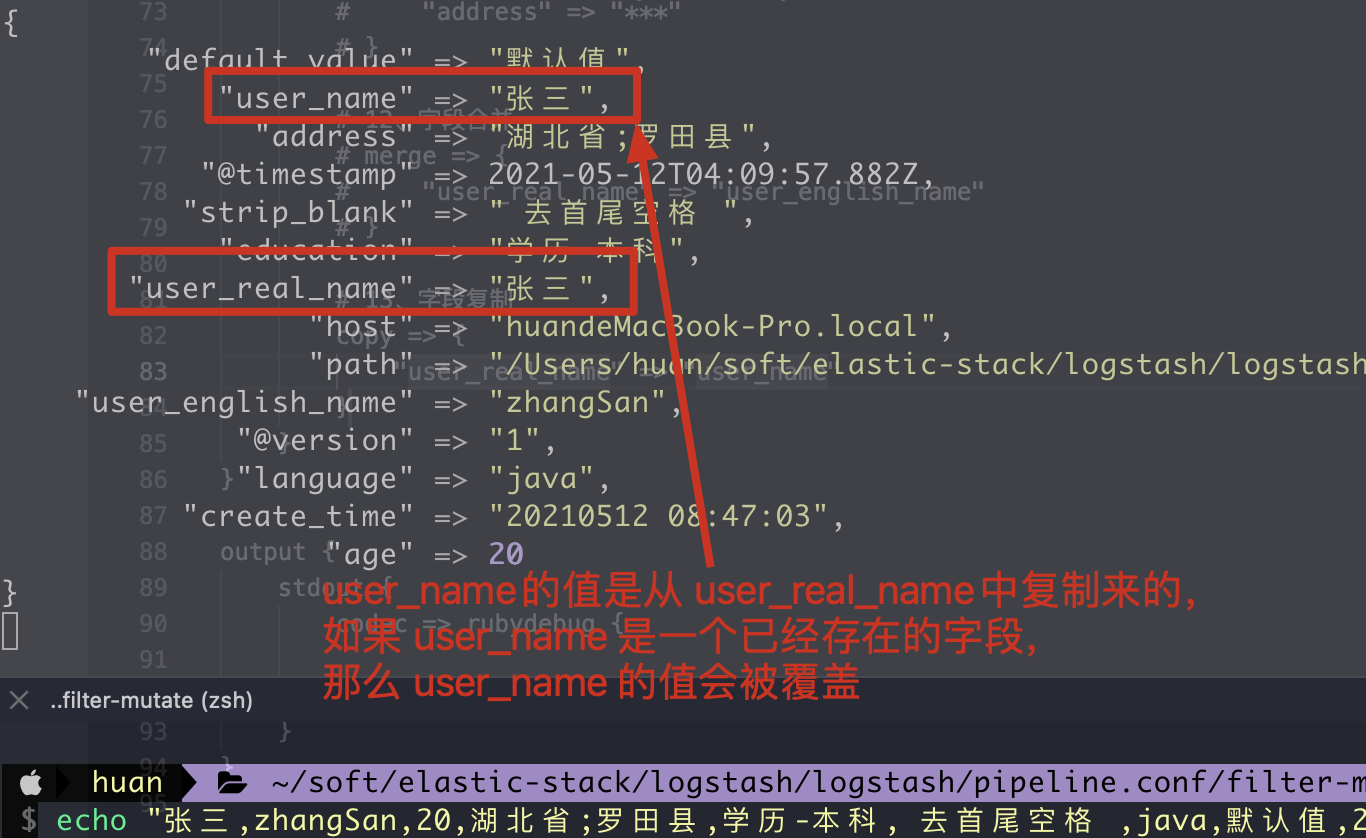
13. Copy copy field
1. Configuration file writing method
filter {
mutate {
# 1. Field copy, if user_ If the field name already exists, the value of this field will be overwritten, otherwise a new field value will be added
copy => {
"user_real_name" => "user_name"
}
}
}
2. Execution results
4, Change priority
1. The order in which mutate is executed in the configuration file
coerce,rename,update,replace,convert,gsub,uppercase,capitalize,lowercase,strip,remove,split,join merge,copy
Core is executed first and copy is executed last.
2. Priority of multiple mutate blocks
filter {
# Mutate block 1 will execute before mutate2 below
mutate {}
# mutate block 2
mutate {}
}
be careful ⚠️:
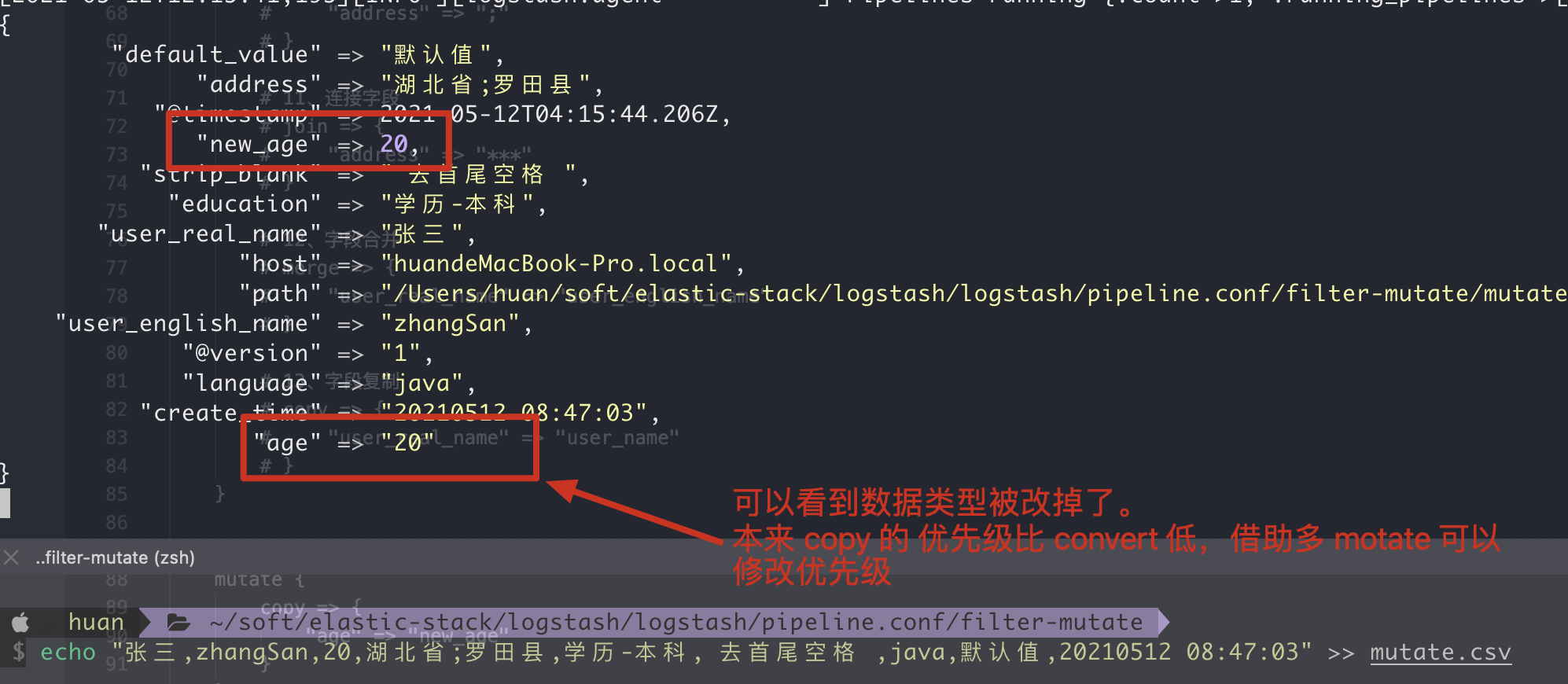
Suppose we need to copy the field age first, and then convert the data type, then we can use multiple mutate blocks above to execute.
1. Writing method of configuration file
filter {
# Test the priority of multiple mutate blocks
mutate {
copy => {
"age" => "new_age"
}
}
mutate {
convert => {
"age" => "string"
}
}
}
If you put convert and copy in a mutate block, you will find that the results are different.
2. Execution results
5, Reference documents
1,https://www.elastic.co/guide/en/logstash/7.12/working-with-plugins.html
2,https://www.elastic.co/guide/en/logstash/current/plugins-codecs-csv.html
3,https://www.elastic.co/guide/en/logstash/current/plugins-filters-mutate.html