Today, we use Python to sort out the relationships in the Dream of Red Mansions.
Don't ask me why the Dream of Red Mansions is, not the Three Kingdoms of the Marsh or the Westward Journey, because I have also identified that the Red Mansion is the undisputed peak of Chinese classical fiction, and do not accept refutation! The Dream of Red Mansions is also one of the few novels that I have read repeatedly, and I have the deepest feelings for it.
Okay, it's not sour. Let's get dry.
Data preparation
- A TXT Document of Dream of Red Mansions
- List of Twelve Chai + Jia Baoyu Characters in Jinling
The list of characters is as follows:
Baoyu nr Daiyu nr Baochai nr Xiangyun nr Sister Feng nr Li Wannr Yuanchun nr Yingchun nr Tanchun nr Xichunnr Miaoyu nr Qiaojie nr Qin's nr
This list is also used for word segmentation. The following nr is the meaning of a person's name.
data processing
Read the data and load the dictionary
with open("The Dream of Red Mansion.txt", encoding='gb18030') as f:
honglou = f.readlines()
jieba.load_userdict("renwu_forcut")
renwu_data = pd.read_csv("renwu_forcut", header=-1)
mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]
In this way, we read the Dream of Red Mansions into the variable honglou, and also load our custom dictionary into the jieba library through load_userdict.
Word Segmentation and Extraction of Text
tmpNames = []
names = {}
relationships = {}
for h in honglou:
h.replace("Jia Fei", "New Year")
h.replace("Li Gongcai", "Li Wan")
poss = pseg.cut(h)
tmpNames.append([])
for w in poss:
if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist:
continue
tmpNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
- First of all, because the article "Jia Fei", "Yuan Chun", "Li Gong Tai", "Li Wan" mix seriously, so here do the replacement treatment directly.
- Then use the pseg tool provided by the jieba library to do word segmentation, which returns the part of speech of each participle.
- Then make a judgment that only those words that meet the requirements and are included in the list of dictionaries we provide will be retained.
- Every time a person appears, an additional one will be added to facilitate the determination of the size of the person node when drawing the diagram behind.
- For names that exist in our custom dictionary, save tmpNames in a temporary variable.
Handling Personal Relationships
for name in tmpNames:
for name1 in name:
for name2 in name:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] += 1
For those who appear in the same paragraph, we think that they are closely related. Every time they appear at the same time, the relationship increases by 1.
Save to file
with open("relationship.csv", "w", encoding='utf-8') as f:
f.write("Source,Target,Weight\n")
for name, edges in relationships.items():
for v, w in edges.items():
f.write(name + "," + v + "," + str(w) + "\n")
with open("NameNode.csv", "w", encoding='utf-8') as f:
f.write("ID,Label,Weight\n")
for name, times in names.items():
f.write(name + "," + name + "," + str(times) + "\n")
- Document 1: Character Relations Table, which contains the first person to appear, the next person to appear and the number of times to appear together
- Document 2: Character Ratio Table, including the overall number of occurrences of the figure, the more the number of occurrences, the greater the proportion of that figure.
Making Relational Charts
Drawing with pyecharts
def deal_graph():
relationship_data = pd.read_csv('relationship.csv')
namenode_data = pd.read_csv('NameNode.csv')
relationship_data_list = relationship_data.values.tolist()
namenode_data_list = namenode_data.values.tolist()
nodes = []
for node in namenode_data_list:
if node[0] == "Baoyu":
node[2] = node[2]/3
nodes.append({"name": node[0], "symbolSize": node[2]/30})
links = []
for link in relationship_data_list:
links.append({"source": link[0], "target": link[1], "value": link[2]})
g = (
Graph()
.add("", nodes, links, repulsion=8000)
.set_global_opts(title_opts=opts.TitleOpts(title="Character Relations in the Red Chamber"))
)
return g
- First, read the two files as lists
- For "Baoyu", because of its large proportion, if zooming uniformly, it will cause other characters'node s to be too small and the display is not beautiful, so here we do a zooming first.
The final diagram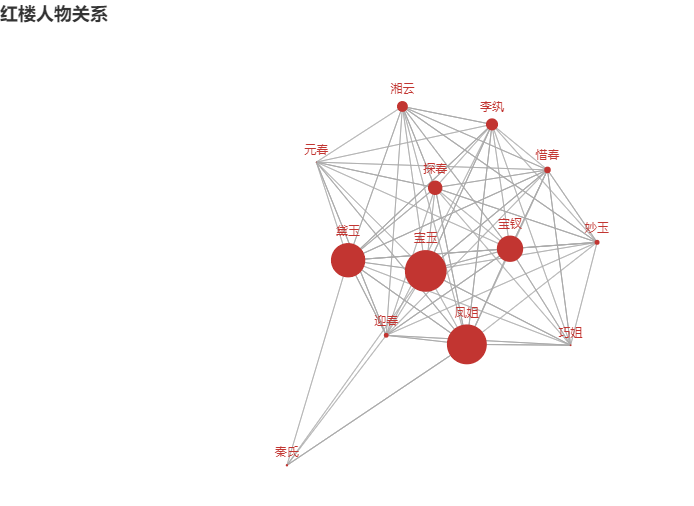
All code has been uploaded to Github:
https://github.com/zhouwei713/data_analysis/tree/master/honglou
Finally, I have prepared a more comprehensive dictionary of people in the Red Chamber, which can be found in the code warehouse - "renwu_total". Interested partners can also try to create a full-character relationship map.