Friends who have seen my previous ResNet18 and ResNet34 may wonder whether the method of building 18 and 34 layers can be directly used in the construction of ResNet above 50 layers. I have also tried. However, the network construction above ResNet50 is not like 18 to 34 layers, which can be completed by simply modifying the number of convolution units. The three networks above ResNet50 are the same, but the number of layers is different, so 34 to 50 layers can be used as a construction watershed.
In addition, I'm a beginner of PyTorch and deep neural network, and I don't know much about the efficient construction of using BasicBlock and BottleNeck, so here is a construction method of simple violent stacking network layer similar to the first two resnets
ResNet50 network architecture
ResNet for all different layers:
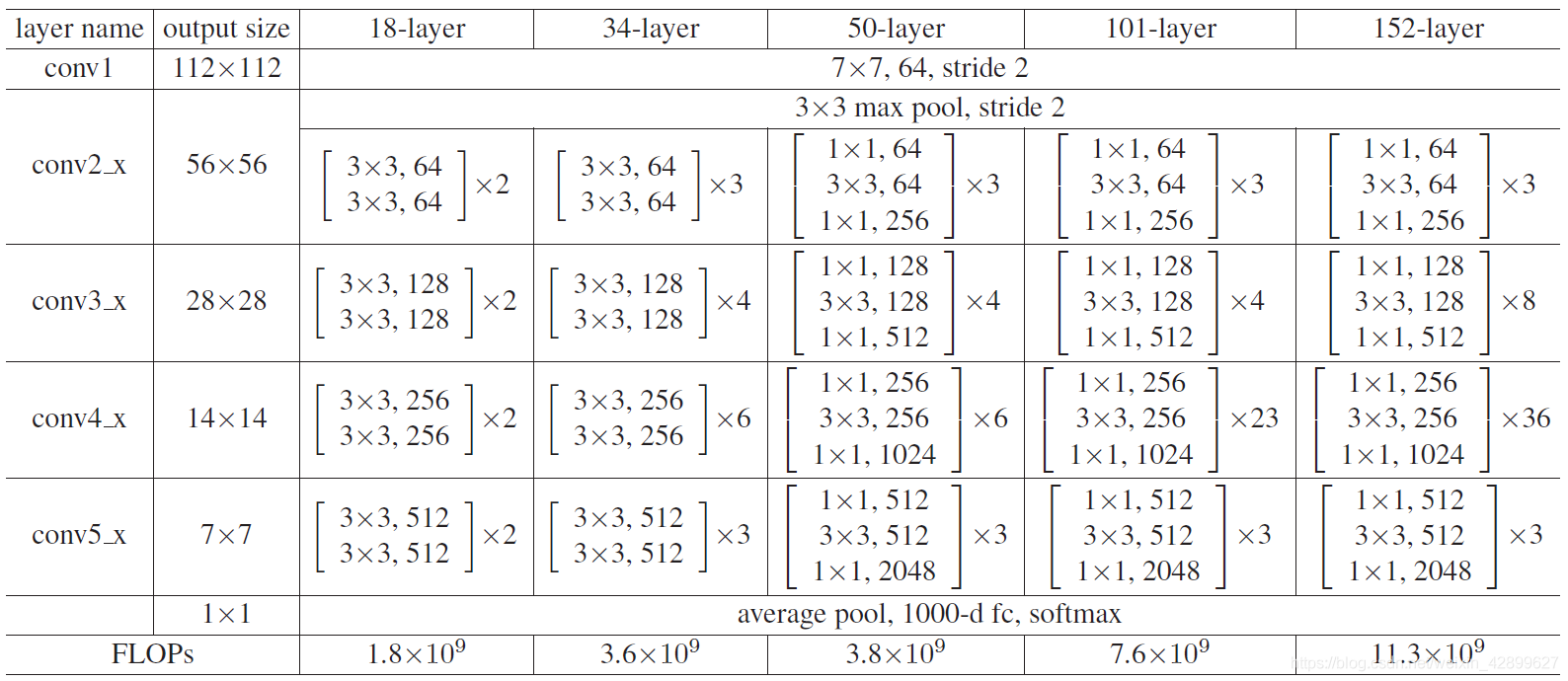
Here are the detailed parameters and execution flow chart of ResNet50 network:
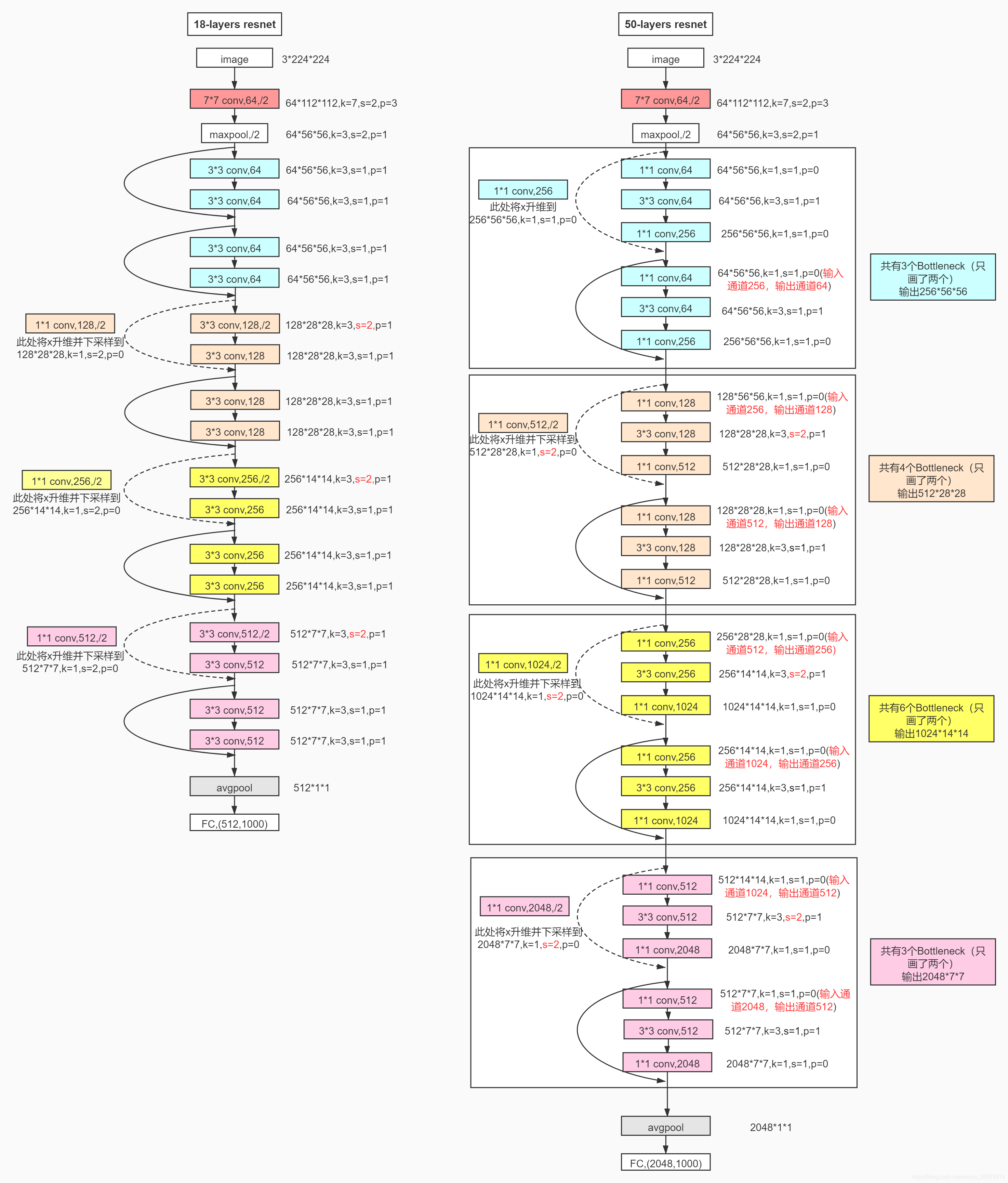
Direct code
model.py model part:
import torch
import torch.nn as nn
from torch.nn import functional as F
"""
there ResNet50 The construction of is a form of violence, which is directly accumulated to complete the construction, but it is not adopted BasicBlock and BottleNeck
first DownSample Class for defining shortcut Model function to complete two layer Dotted line between shortcut,be responsible for layer1 The rise of the dotted line is 4 times channel And others layer 2 times of the dotted line channel
Observe each layer Rise at the dotted line of channel Just rise channel The number before and after is different, and stride Different, for kernel_size and padding Both are 1 and 0, respectively. Do not act DownSample Model parameters of network class
parameter in_channel That is, the number of channels before the rise, out_channel That is, the number of channels after the rise, stride That is, every rise channel different stride Step size, for layer1 Ascending channel stride=1,other layer Ascending channel stride=2,Pay attention to different
"""
"""
Be sure to pay attention to:
In this network ResNet50 In class forward Inside the function: layer1_shortcut1.to('cuda:0');layer2_shortcut1.to('cuda:0')And other statements will be instantiated DownSample
Network model train.py Defined in the training script GPU In the same environment, the following errors will be reported without this sentence:
Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
"""
class DownSample(nn.Module):
def __init__(self, in_channel, out_channel, stride): # Number of channel s before and after incoming downsampling and stripe step size
super(DownSample, self).__init__() # Inherit parent class
self.down = nn.Sequential( # Define a model container down
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, padding=0, bias=False), # It is responsible for the only and important convolution of dashed shortcut
nn.BatchNorm2d(out_channel), # Between convolution and ReLU nonlinear activation, add BatchNormalization
nn.ReLU(inplace=True) # At the end of shortcut, add an activation function and set inplace=True to operate in place to save memory
)
def forward(self, x):
out = self.down(x) # The forward propagation function only completes the operation of the down container
return out
"""
first ResNet50 Class, not used BottleNeck Unit complete ResNet50 The building above the floor can be used directly forward Plus the front DownSample Model class functions, specifying ResNet50 Build model with all parameters
"""
class ResNet50(nn.Module):
def __init__(self, classes_num): # ResNet50 only transmits one classification number and writes all the data involved. For specific data, please refer to the following picture
super(ResNet50, self).__init__()
# Before entering layer 1234, preprocessing is carried out, mainly convolution and pooling, from [batch, 3, 224, 224] = > [batch, 64, 56, 56]
self.pre = nn.Sequential(
# Convolution channel is upgraded from 3 channels of original data to 64 channels with 64 convolution cores. The size, step size and padding of convolution cores are fixed
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64), # The convolution is followed by BatchNormalization
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # Preprocess the last maximum pool operation, and the data is fixed
)
"""
every last layer The operation of is divided into one-time operation first,And used many times next form, first Responsible for each layer Cubic convolution of the first unit (with dotted line) of, next Responsible for the cubic convolution of the remaining units (direct connection)
"""
# --------------------------------------------------------------
self.layer1_first = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1, stride=1, padding=0, bias=False), # layer1_ The first convolution keeps the channel unchanged for the first time, which is different from the first convolution of other layers
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False), # layer1_first second convolution stripe and other layers_ The first string is different
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False), # layer1_ The first third convolution is the same as other layers, and the channel is increased by 4 times
nn.BatchNorm2d(256) # Note that the ReLU activation function is not added at the end of the last convolution
)
self.layer1_next = nn.Sequential(
nn.Conv2d(256, 64, kernel_size=1, stride=1, padding=0, bias=False), # layer1_ The first convolution of next is responsible for reducing the channel and reducing the amount of training parameters
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False), # layer1_ The last convolution of the next is responsible for adding the channel to the shortcut
nn.BatchNorm2d(256)
)
# -------------------------------------------------------------- # The operation of layer234 is basically the same. Only layer2 is introduced here
self.layer2_first = nn.Sequential(
nn.Conv2d(256, 128, kernel_size=1, stride=1, padding=0, bias=False), # And layer1_ The first convolution is different, and the channel needs to be reduced to 1 / 2
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1, bias=False), # Note that stripe = 2 here is the same as layer34, but different from layer1
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False), # Raise channel again
nn.BatchNorm2d(512)
)
self.layer2_next = nn.Sequential(
nn.Conv2d(512, 128, kernel_size=1, stride=1, padding=0, bias=False), # Responsible for the general operation of the cycle
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512)
)
# --------------------------------------------------------------
self.layer3_first = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
self.layer3_next = nn.Sequential(
nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
# --------------------------------------------------------------
self.layer4_first = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
self.layer4_next = nn.Sequential(
nn.Conv2d(2048, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # After the final adaptive mean pooling, it is [batch, 2048, 1, 1]
# Define the last full connection layer
self.fc = nn.Sequential(
nn.Dropout(p=0.5), # Inactivate neurons with a probability of 0.5
nn.Linear(2048 * 1 * 1, 1024), # First full connection layer
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(1024, classes_num) # The second full connection layer outputs class results
)
"""
forward()The forward propagation function is responsible for ResNet Class, and then with the above DownSample Class perfect combination
"""
def forward(self, x):
out = self.pre(x) # Preprocess the input and output out = [batch, 64, 56, 56]
"""
Each floor layer The operation consists of two parts, the first is the convolution unit with dotted line, and the other is the ordinary convolution unit completed by loop shortcut Directly connected convolution unit
"""
layer1_shortcut1 = DownSample(64, 256, 1) # Instantiate a network model layer1 using DownSample_ Shortcut1, the parameter is the ascending channel data at the dotted line. Note that stripe = 1
layer1_shortcut1.to('cuda:0')
layer1_identity1 = layer1_shortcut1(out) # Call layer1_shortcut1 calculates the identity at the dotted line for the convolution unit input out, which is used to add with the convolution unit output later
out = self.layer1_first(out) # Call layer1_first completes the first special convolution unit of layer1
out = F.relu(out + layer1_identity1, inplace=True) # Add the identity to the output of the convolution unit and activate the function through relu
for i in range(2): # Use the loop to complete the convolution unit with the same input and output operations
layer_identity = out # Direct connection identity equals input
out = self.layer1_next(out) # The input passes through the ordinary convolution unit
out = F.relu(out + layer_identity, inplace=True) # The two results are added and then passed through the activation function
# --------------------------------------------------------------Later, layer234 is similar, and only layer2 is introduced here
layer2_shortcut1 = DownSample(256, 512, 2) # Note that the input and output channel s of layer234 are different, and the same is true for stripe = 2
layer2_shortcut1.to('cuda:0')
layer2_identity1 = layer2_shortcut1(out)
out = self.layer2_first(out)
out = F.relu(out + layer2_identity1, inplace=True) # Complete the first convolution unit of layer2
for i in range(3): # Loop the remaining convolution units of layer2
layer_identity = out
out = self.layer2_next(out)
out = F.relu(out + layer_identity, inplace=True)
# --------------------------------------------------------------
layer3_shortcut1 = DownSample(512, 1024, 2)
layer3_shortcut1.to('cuda:0')
layer3_identity1 = layer3_shortcut1(out)
out = self.layer3_first(out)
out = F.relu(out + layer3_identity1, inplace=True)
for i in range(5):
layer_identity = out
out = self.layer3_next(out)
out = F.relu(out + layer_identity, inplace=True)
# --------------------------------------------------------------
layer4_shortcut1 = DownSample(1024, 2048, 2)
layer4_shortcut1.to('cuda:0')
layer4_identity1 = layer4_shortcut1(out)
out = self.layer4_first(out)
out = F.relu(out + layer4_identity1, inplace=True)
for i in range(2):
layer_identity = out
out = self.layer4_next(out)
out = F.relu(out + layer_identity, inplace=True)
# The last full connection layer
out = self.avg_pool(out) # After the final adaptive mean pooling, it is [batch, 2048, 1, 1]
out = out.reshape(out.size(0), -1) # Flatten the convolution input [batch, 2048, 1, 1] to [batch, 2048*1*1]
out = self.fc(out) # After the last full connection unit, the output classification is out
return out
The training of ResNet50 can refer to the training and testing part of my ResNet18:
Use PyTorch to build ResNet18 network and use CIFAR10 data set to train and test
After the violent construction of handwritten ResNet50 network model, I realized that in order to build ResNet and other complex networks, the premise must be clear about the whole process of the model
For example, the in of dimension upgrading operation in each shortcut in ResNet50_ channel,out_ channel,kernel_ The parameter size of size, stripe and padding changes
What are the specific parameters of each convolution unit and how to maximize and simplify the code;
In addition, in building a complex network model, we must build and test step by step. Each step must be understood and justified, and finally the whole network can be built
Another unexpected gain is the discovery of such errors during training:
Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
The original reason is that the input data type is torch cuda. Floattensor, indicating that the input data is in GPU. The data type of model parameters is torch Floattensor, indicating that the model is still in the CPU
Therefore, add the instantiated DownSample network to and train in the forward() function of ResNet50 Py solves the error under the same GPU of the network model instantiated by ResNet50