Project Description:
Python novice, the first crawler project, web crawler is an activity that can enhance the interest of programming learning, so that Python learning is no longer boring.
Python version 3.7.2
Modules needed: requests, os, beautiful soup
Crawler destination https://www.mzitu.com/xinggan/
Project realization:
First, import the module and configure the request header. If there is no image address, it will be an empty link
# -*- coding:utf-8 -*-import requests,os from bs4 import BeautifulSoup Path = 'D:\\MeiZ\\' header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Referer': 'https://www.mzitu.com/163367'}
I. get the source code of the web page
def getContent(url): ##requests.get returns a response res = requests.get(url,headers = header) ##The beauty soup interpreter uses lxml faster than html5lib soup = BeautifulSoup(res.text,'lxml') return soup
2. Get the atlas address
Right click "check" on the chrome image,
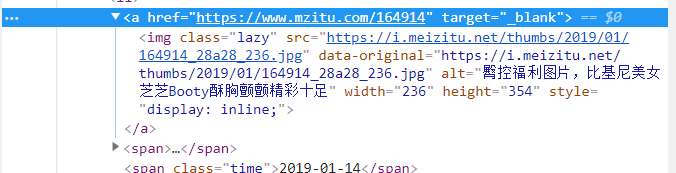
It is found that there are too many a tags to find full text, so you can use img tags to get parent tags through parent
def get_album_list(url): soup = getContent(url) ##Find all img tags and return a list artical = soup.findAll('img',{'class':'lazy'}) ##Set an empty list and save the atlas address artical_list = [] for i in artical: ##Parent method takes the parent label content artical_list.append(i.parent['href']) return artical_list
3. Get the title and page number of atlas

Enter the atlas, use the css selector to take out the title and page number, check the title, and the class name is main title
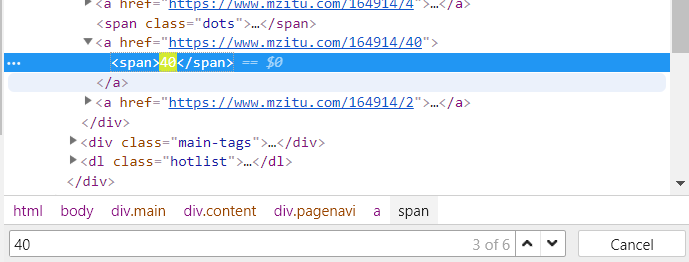
Search page number with span label
def getPage_Title(url): soup = getContent(url) ##css selector returns list ##Take the first one out of the list title = soup.select('.main-title')[0].text ##Page number is 11th in the list page = soup.select('span')[10].text return page,title
IV. access to image address
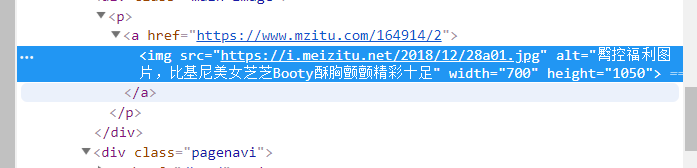
Check the image. The image link is in src of img tag
def getImg_url(url): soup = getContent(url) ##Find based on the properties of the label ##find(name, attrs, recursive, text, **wargs) Img_url = soup.find('img')['src'] return Img_url
V. download pictures
def down_Img(url,title,count): res = requests.get(url,headers = header) ##exception handling try: ##Count count save with open(Path + title + '\\' + str(count) +'.jpg','wb') as file: file.write(res.content) ##The file needs to be closed after writing, otherwise it will be in memory all the time file.close() except: print("ERROR")
Vi. main function series method
##Start program check for D:\MeiZ \ \ directory if not os.path.isdir(Path): os.mkdir(Path)
The atlas list address is https://www.mzitu.com/xinggan/page/ plus the number of pages, the total page number is 135
url = 'https://www.mzitu.com/xinggan/page/' ##Cycle each page for t in range(1,135): url = url + str(t)
##Get atlas address album_list = get_album_list(url) for index in range(0,len(album_list)): ##Loop out the total number of titles and pages Page_Title = getPage_Title(album_list[index]) page_num = Page_Title[0] title = Page_Title[1] print("Downloading:" + title)
##Create subdirectory with title, skip download if it exists if not os.path.isdir(Path + title): os.mkdir(Path + title) for i in range(1,int(page_num)): ##Take the total number of page numbers of the atlas and loop out the address of each picture Page_url = album_list[index] + "/" + str(i) Img_Info = getImg_url(Page_url) down_Img(Img_Info,title,i) print("Downloading" + str(i) + "/" + str(page_num)) else: print("Downloaded skipped")
7. All codes
# -*- coding:utf-8 -*- #__author__ = 'vic' import requests,os from bs4 import BeautifulSoup Path = 'D:\\MeiZ\\' header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Referer': 'https://www.mzitu.com/163367'} ##Web page html def getContent(url): res = requests.get(url,headers = header) soup = BeautifulSoup(res.text,'lxml') return soup ##Get atlas address def get_album_list(url): soup = getContent(url) artical = soup.findAll('img',{'class':'lazy'}) artical_list = [] for i in artical: artical_list.append(i.parent['href']) return artical_list ##Get page number of atlas def getPage_Title(url): soup = getContent(url) page = soup.select('span')[10] title = soup.select('.main-title')[0].text return page.text,title ##Get picture address def getImg_url(url): soup = getContent(url) Img_url = soup.find('img')['src'] return Img_url ##download def down_Img(url,title,count): res = requests.get(url,headers = header) try: with open(Path + title + '\\' + str(count) +'.jpg','wb') as file: file.write(res.content) file.close() except: print("ERROR") if __name__ == '__main__': if not os.path.isdir(Path): os.mkdir(Path) url = 'https://www.mzitu.com/xinggan/page/' for t in range(1,135): url = url + str(t) album_list = get_album_list(url) for index in range(0,len(album_list)): Page_Title = getPage_Title(album_list[index]) page_num = Page_Title[0] title = Page_Title[1] print("Downloading:" + title) if not os.path.isdir(Path + title): os.mkdir(Path + title) for i in range(1,int(page_num)): Page_url = album_list[index] + "/" + str(i) Img_Info = getImg_url(Page_url) down_Img(Img_Info,title,i) print("Downloading" + str(i) + "/" + str(page_num)) else: print(title + "Downloaded skipped")
VIII. Project achievements
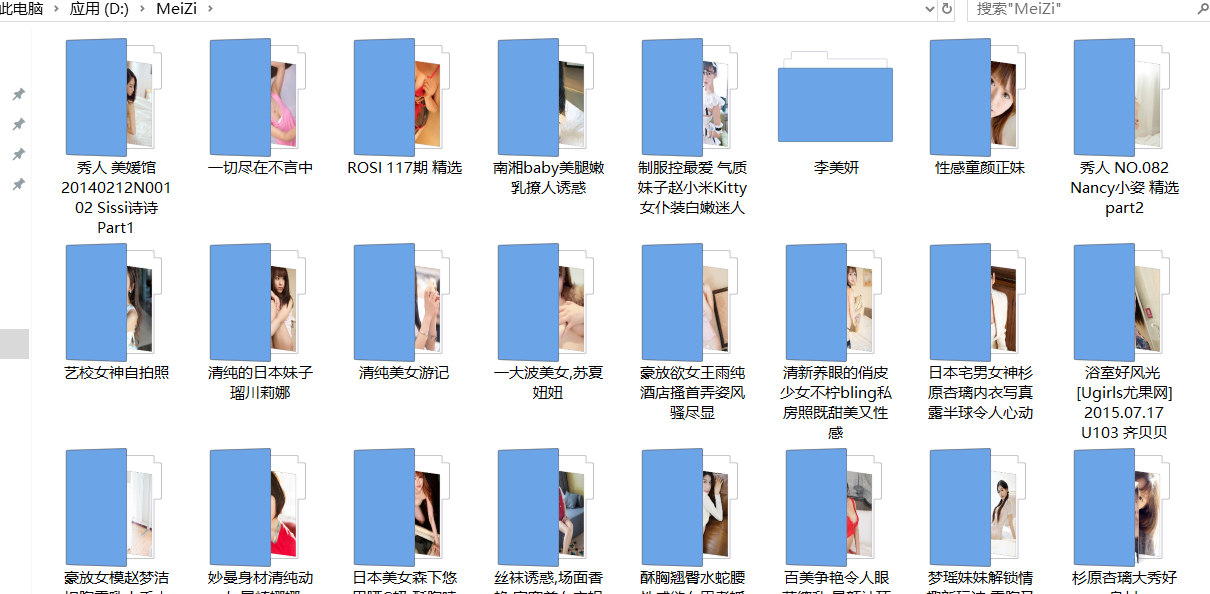
Prepare to climb grass for the next project