This article is a small Demo during the postgraduate period. At that time, some machine learning algorithms were used to predict the odds. In this process, due to the need for data, crawlers were used to climb the data of Scout nets. The following is a small part of the code, showing an example of crawling some of the data.
Target site
Here, take the game data of 32 national teams participating in the 2018 Russian World Cup on the Scout website in the past 6 years as an example.
- http://zq.win007.com/cn/CupMatch/648.html
Website analysis
1, Constructing crawling ideas according to web content
Firstly, the grouping and points of 32 national teams shortlisted in the group match are listed on the theme page of the world cup of the Scout network

Click the name of any participating national team (such as Egypt) to link to the national team's special page, which contains all the competition results and relevant data of the team from 2011 to now, that is, the content we want to climb.

Therefore, the whole crawling idea is proposed as follows: grab the names of participating national teams and their corresponding national team data statistics links from the 2018 season world cup (World Cup), schedule points - scouting network, and use these links as secondary websites to grab the corresponding national team's game data statistics in recent years. Save the information in the last csv file.
2, Web page html analysis
First, find the information location we want to grab on the primary website in the developer tool. What we're going to climb is
The content and href attribute of the a tag in the third tag in.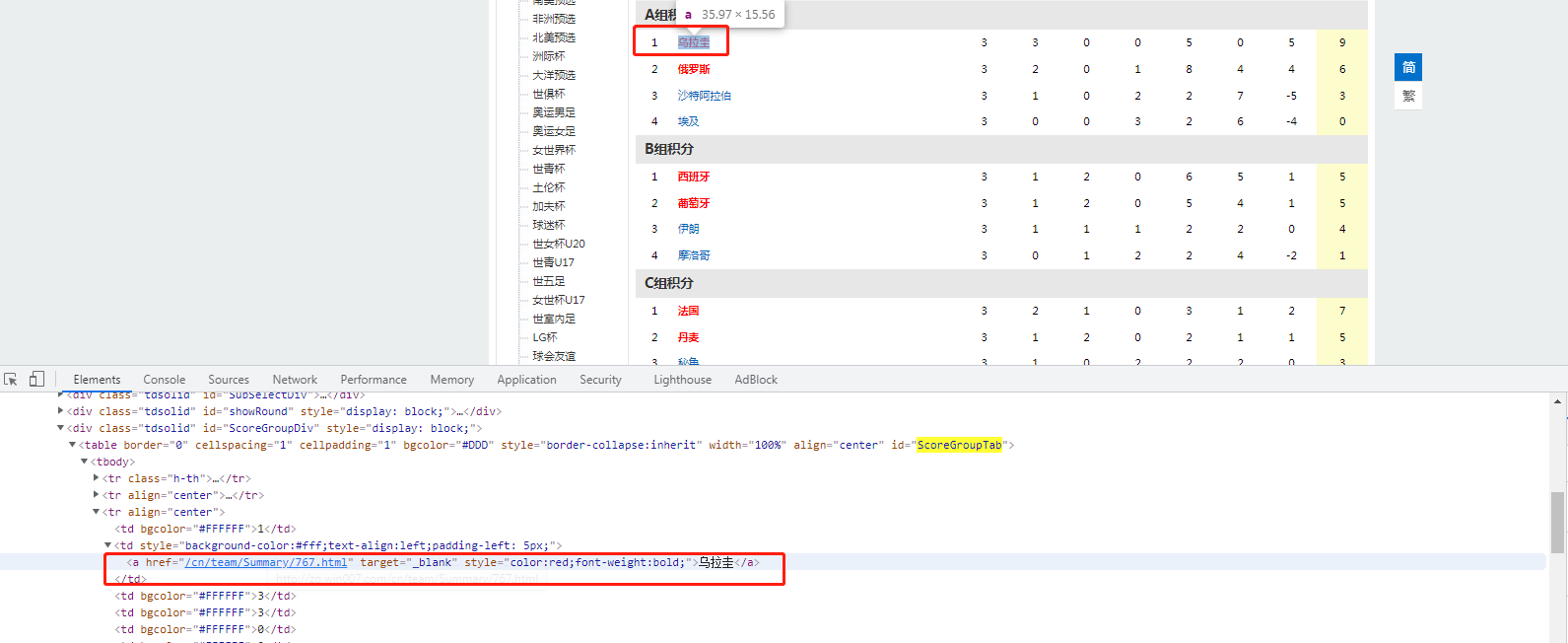
However, when you right-click the page to view the source code, there is no code in the source code. Note that the contents of this part of the table tag are dynamically loaded through ajax, not written in the source code. The developer tool also shows that the web page uses the jquery framework to write javascript scripts. (the table of national team game data statistics is also loaded dynamically by ajax, so I won't repeat the analysis here.)
Look at the file returned by the server when requesting the web page, where bomhelper JS contains the following information:
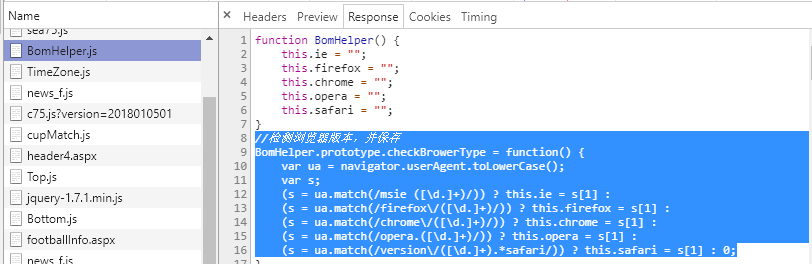
3, Configuring selenium and chrome
Now that we have determined the method of using selenium library + chrome browser, we must first install selenium library and the corresponding browser driver (chromedriver.exe)
selenium library installation
This is very simple. Like the common python package installation, you can use:
pip install selenium
Downloading and installing chromedriver
open https://sites.google.com/a/chromium.org/chromedriver/downloads , download the chromedriver.com that matches the browser version exe. For example, my browser is Chrome/93.0.4577.15. So I chose this version.
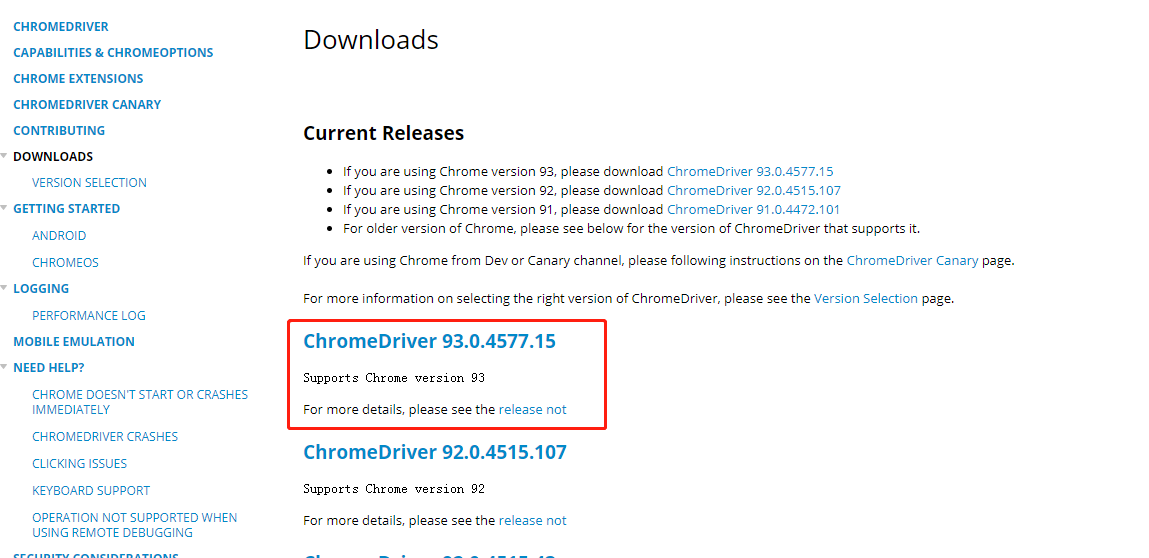
The download is a zip file. After decompression, there is a chromedriver Exe file, move the file to the installation directory of the computer's Chrome browser, my name is: C:\Program Files, (x86)\Google\Chrome\Application, and add the path to the path of the environment variable.
Verify that the chromedriver is available
Open python and enter the following:
from selenium import webdriver driver = webdriver.Chrome()
After clicking run, if a chrome browser window is successfully opened and the program does not report an error, the configuration is successful.
Crawler code
#Import required packages
from selenium import webdriver
import time
import traceback
#Send url request
def getDriver(url):
try:
# Note the version of chromedriver
driver = webdriver.Chrome()
driver.get(url)
time.sleep(1)
return driver
except:
return ''
#Get sub link list
def getURLlist(url, teamURLlist):
driver = getDriver(url)
try:
#Find all a tags that contain child links
a_list = driver.find_elements_by_xpath('//table[@id="ScoreGroupTab"]/tbody/tr/td[2]/a')
if a_list:
for i in a_list:
#teamURLlist is used to store child links
teamURLlist.append(i.get_attribute('href'))
driver.close()
return teamURLlist
else:
return []
except:
traceback.print_exc()
return []
#Get game data
def getMatchInfo(teamURLlist, fpath):
with open (fpath, 'w') as f:
#Be careful not to have spaces after commas
f.write('match,time,home team,score,visiting team,foul,Yellow card,Red card,Ball control rate,Shoot (straight),Pass (success),Pass success rate,Number of passes,score\n')
if teamURLlist:
for url in teamURLlist:
driver = getDriver(url)
# The data in the table is divided into many pages, although all the data are in driver page_ Visible in source.
# However, except for the first page, other data style attributes are "display: None", and selenium cannot directly operate on these elements.
# We need to modify the value of display through JavaScript
# Write a piece of javascript code for the browser to execute. This sets the style attribute of all tr tags in html to display='block '
js = 'document.querySelectorAll("tr").forEach(function(tr){tr.style.display="block";})'
driver.execute_script(js)
#Next, you can climb down all the game performance data
infolist = driver.find_elements_by_xpath('//div[@id="Tech_schedule"]/table/tbody/tr')
# The first tr contains the title information of the table, which is excluded
for tr in infolist[1:]:
td_list = tr.find_elements_by_tag_name('td')
matchinfo = []
for td in td_list:
# The style attribute of part td is also "display:none", and the corresponding value of info is',
# These td correspond to corner kick, offside, header, save, tackle and other information. If it's not very important, you won't climb.
info = td.text
if info: # Remove empty characters
matchinfo.append(td.text)
matchinfo.append(',') #Add comma as separator
matchinfo.append('\n') #Add a newline at the end of the list
#Write a game information to a file
f.writelines(matchinfo)
#After each web page is crawled, turn off the open browser, or there will be a lot of browser windows open in the end.
driver.close()
def main():
#First level website: top 32 grouping information
start_url = 'http://zq.win007.com/cn/CupMatch/75.html'
#Save file and path
output = r'D:/03-CS/web scraping cases/qiutan/worldcup2018.csv'
startlist = []
resultlist = getURLlist(start_url, startlist)
getMatchInfo(resultlist, output)
print('\nfinished\n')
main()
Summary
This process mainly uses the following knowledge points:
The combination of selenium+chrome is used to simulate the chome browser sending requests, handle ajax asynchronous loading data and the server's restrictions on the browser sending requests.
Solved how to crawl the tag content with the attribute display: none: write a javascript code to modify the attribute and submit it to a webdriver for execution.
Another point is that the website is estimated to be crawled a lot. Anti crawling measures should be taken. The page load is very slow, which needs to be optimized.