1. Premise environment
Install pypharm, and install the Scrapy frame in pypharm
2. Create a Scrapy project
Find Terminal in the lower left corner of pychart, as shown below:

Click Terminal to enter the command line window, as shown below:

In this window, execute the following command to create a Scrapy project
scrapy startproject entry name Example: scrapy startproject menu
Enter the project directory, find the spiders folder, and create a crawler under its directory with the following command.
scrapy genspider Crawler name domain name Example: scrapy genspider getmenu https://www.meishij.net/
At this time, our project catalogue is like this
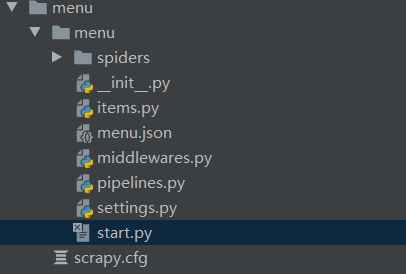
In order to run the crawler easily, I created a start Py file to start the crawler.
start.py
from scrapy import cmdline
cmdline.execute('scrapy crawl getmenu'.split()) #Getmenu should be replaced by the name of the crawler I created. The crawler name I created above is getmenu
3. Modify basic configuration
3.1 configure simulation request
In the configuration file settings Py containing user_ In the line of agent, change its value to the user agent of the browser=
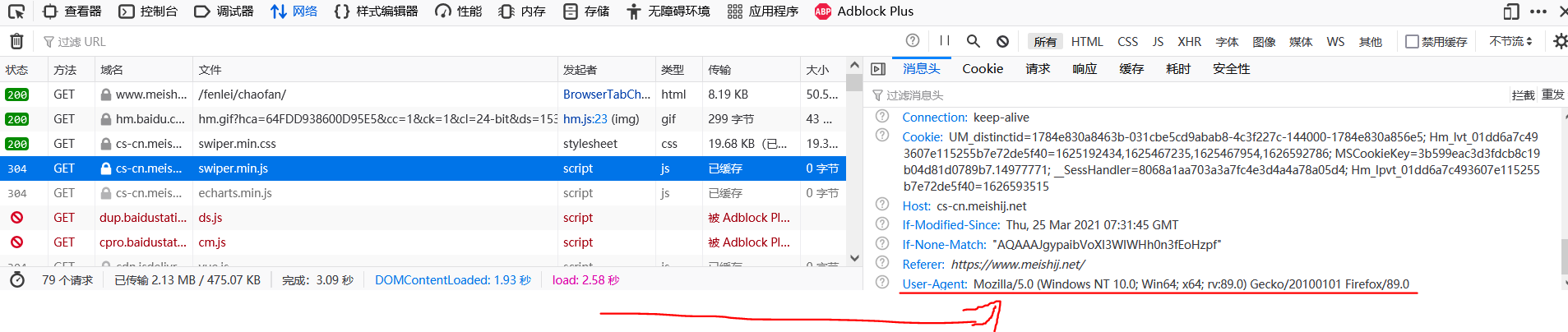
USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0'
Access method of user agent: open the browser, enter a web page casually, press F12 or right-click - check element, the following window appears, and click "network", the window is as follows:
 Then refresh the page and a pile of requests will be displayed, as shown in the following figure:
Then refresh the page and a pile of requests will be displayed, as shown in the following figure:
 Click a request randomly, and the detailed request information will be displayed. At this time, you can find the user agent in the detailed request information
Click a request randomly, and the detailed request information will be displayed. At this time, you can find the user agent in the detailed request information
3.2 configure crawler interval
In the configuration file settings Download found in PY_ Delay, and set the time interval you want, in seconds (s)
DOWNLOAD_DELAY = 0.1 #Crawl a piece of data every 0.1s
Of course, settings There are many parameters in py that can be set. If you can't use it at present, you won't configure it first.
4. Write the code of the crawler
When crawling web page data, we often need to simply analyze the structure of the web page. Only in this way can we write an efficient crawler program.
4.1 determine the target web address of the crawler
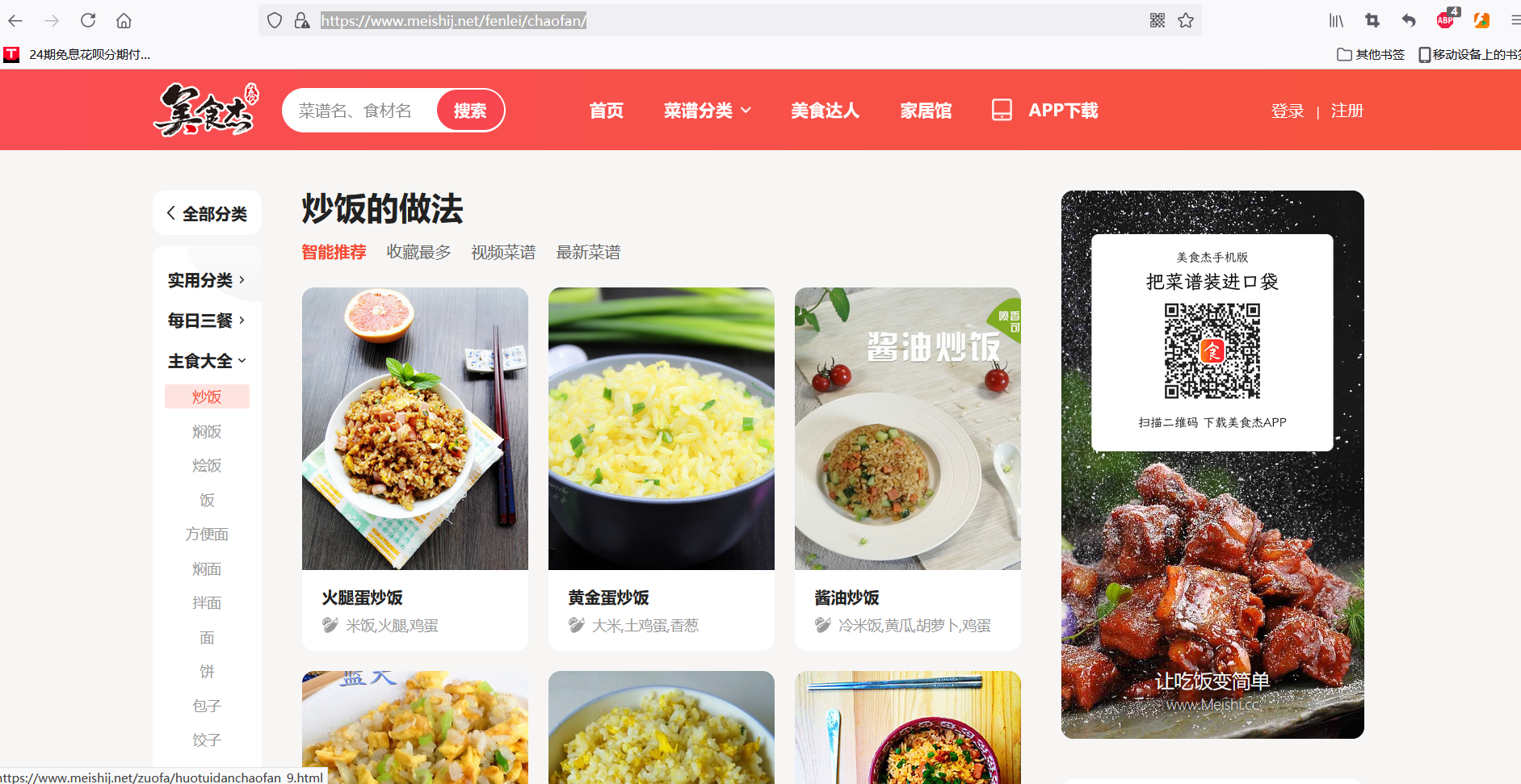
My target website is: https://www.meishij.net/fenlei/chaofan/ (fried rice division of Meijie, as shown in the figure below)
4.2 determine the data items to be crawled
The data items I want to crawl include: recipe name, recipe picture, practice steps, main materials, auxiliary materials and other recipe details. In the above target website, only the recipe picture and name are displayed, which is not detailed enough to meet my requirements. Therefore, you may need to write secondary or multiple url requests to enter the details page of the recipe.
After determining the data items to be crawled, in order to facilitate the storage, modification and other operations of the crawled data, write items Py file (of course, if you just want to observe what data you crawl, you can output it every time you crawl a piece of data in the crawler). items.py is as follows:
import scrapy
class MenuItem(scrapy.Item):
name = scrapy.Field() #Recipe name
img = scrapy.Field() #Menu picture
step = scrapy.Field() #Practice steps
material1 = scrapy.Field() #Main material
material2 = scrapy.Field() #accessories
energy = scrapy.Field() #quantity of heat
sugar = scrapy.Field() #sugar content
fat = scrapy.Field() #Fat
needtime = scrapy.Field() #Time required
uptime = scrapy.Field() # Upload time (this one does not need to be obtained by crawler. Insert the system time when generating each crawler record)
level = scrapy.Field() #Difficulty level
4.3 writing Crawlers
Above, we have planned what data to crawl from what website, and the next step is to write a crawler.
First of all, we need to ensure that we can crawl the entire page from the target URL. The following code verifies whether the following can be crawled https://www.meishij.net/fenlei/chaofan/ Page.
from datetime import datetime
import scrapy
from ..items import MenuItem
class GetmenuSpider(scrapy.Spider):
name = 'getmenu'
allowed_domains = ['https://www.meishij.net']
start_urls = ['https://www.meishij.net/fenlei/chaofan / '] # crawl the target web address
def parse(self, response):
print(response.text) #Print crawled pages
Then run start Py, execute the crawler program, and the results are as follows:
 From the print results in the figure, we can see that the content of this website can be crawled successfully.
From the print results in the figure, we can see that the content of this website can be crawled successfully.
Next, according to items Py file you want to crawl the data items to see if the data in this website can meet your requirements.
Through observation, in this website( https://www.meishij.net/fenlei/chaofan/ ), only menu names and menu pictures can be crawled, while data items such as practice steps, main materials, calories and sugar content are not stored on this page at all. So we randomly click in a recipe and check its details page below( https://www.meishij.net/zuofa/huangjindanchaofan_22.html As an example), as follows:
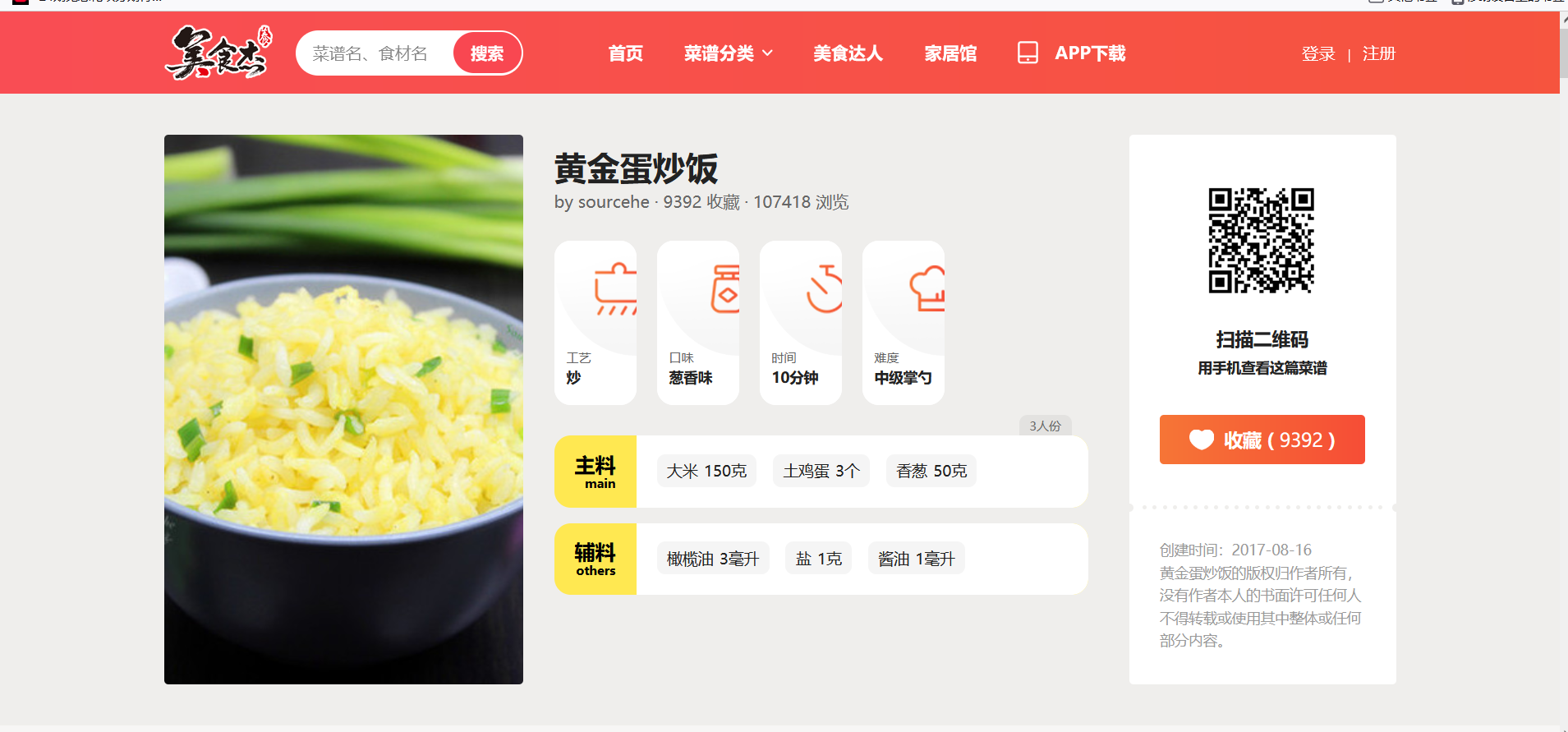 I was surprised to find that all the data items I want to crawl are in this page (manual dog head) [/ doge], so I just need to go through the target website, that is, the website where the crawler starts( https://www.meishij.net/fenlei/chaofan/ )Jump to the corresponding recipe details website, and then crawl.
I was surprised to find that all the data items I want to crawl are in this page (manual dog head) [/ doge], so I just need to go through the target website, that is, the website where the crawler starts( https://www.meishij.net/fenlei/chaofan/ )Jump to the corresponding recipe details website, and then crawl.
So, how to jump to the corresponding recipe details website in the target website? We need to properly analyze the source code of the target website
.
On the target page, press F12 or right-click - check element to open the following window:
 Right click on a recipe - check elements
Right click on a recipe - check elements
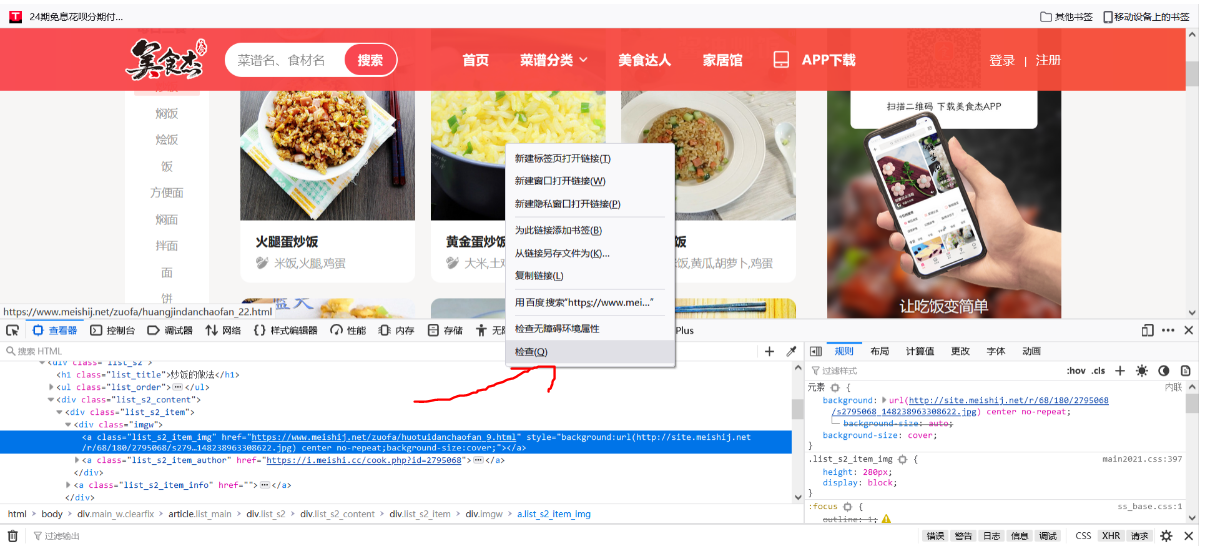 Click as follows:
Click as follows:
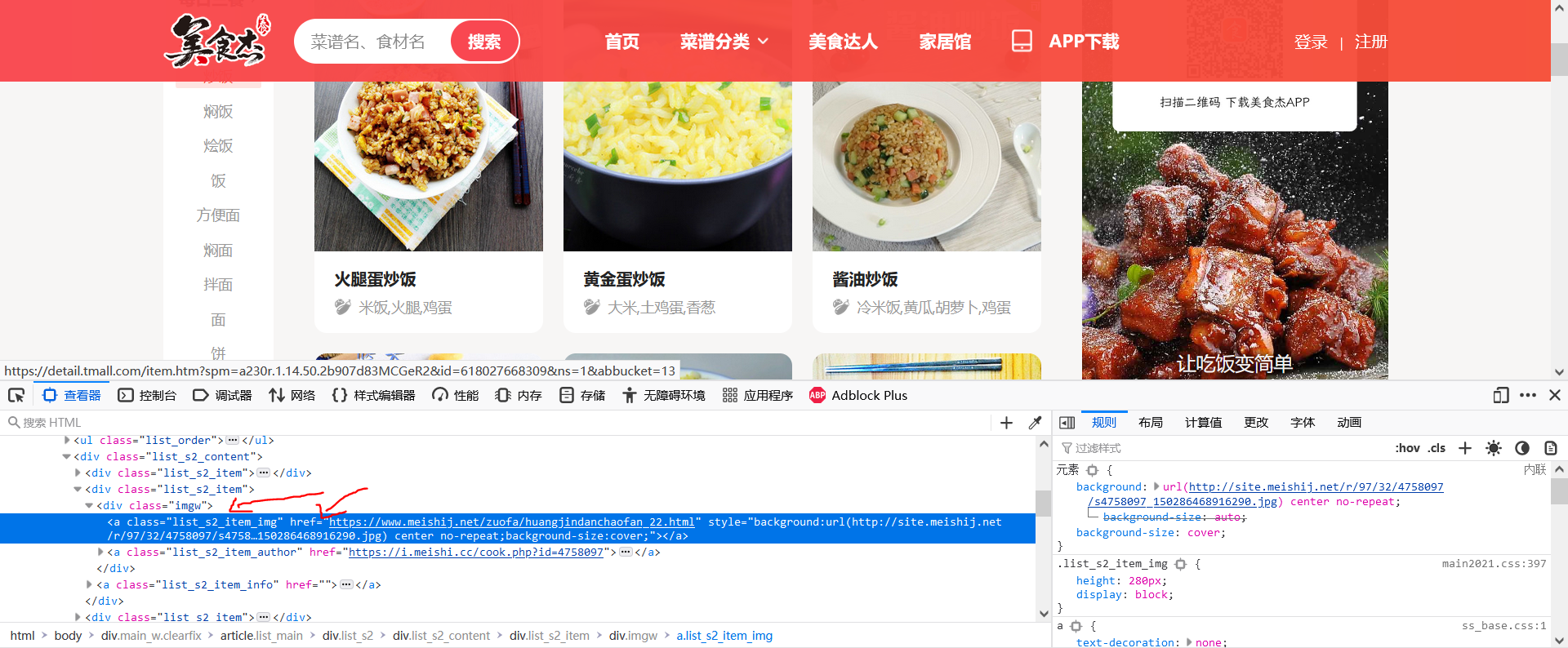 As can be seen from the above figure, under the div of class = "imgw", there is an a tag of class = "list_s2_item_img". Its href attribute is the link of recipe details. Therefore, if you want to enter the details of each recipe, you should enter it through this link.
As can be seen from the above figure, under the div of class = "imgw", there is an a tag of class = "list_s2_item_img". Its href attribute is the link of recipe details. Therefore, if you want to enter the details of each recipe, you should enter it through this link.
At this time, the crawler code is as follows:
import scrapy
class GetmenuSpider(scrapy.Spider):
name = 'getmenu'
allowed_domains = ['https://www.meishij.net']
start_urls = ['https://www.meishij.net/fenlei/chaofan/']
def parse(self, response):
urls = response.xpath('//div[@class="imgw"]/a[@class="list_s2_item_img"]/@href').extract() # menu details link
#Each time you crawl to a link, it will be submitted to the next function to crawl the recipe details.
for url in urls:
yield scrapy.Request(url, callback=self.parse2, dont_filter=True) # Submit url to next level
def parse2(self, response):
print(response.text)
In the above code, the parse function is used to start crawling from it. It only crawls the link corresponding to each recipe on the web page, and each link is submitted to the parse2 function. The parse2 function crawls the details of a single recipe.
Through the above method, we can use the target website( https://www.meishij.net/fenlei/chaofan/ )To enter the details page of all recipes (21 items) on the previous page, the parse2 function will be written below to crawl the details page of the recipe.
4.3.1 name, difficulty, time required, main ingredients and auxiliary ingredients of climbing recipe
Click a menu details page, move the mouse to the menu name, and then right-click - check the elements, as shown in the following figure
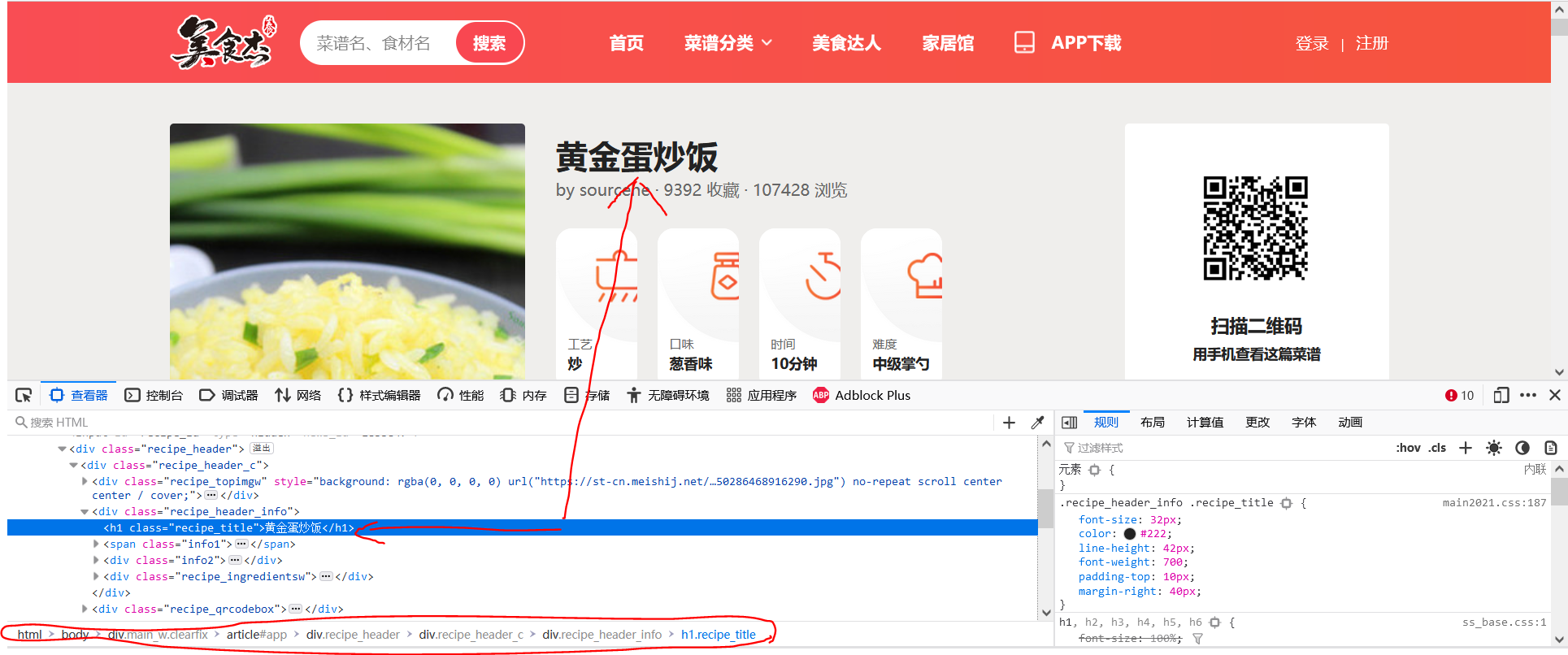 As can be seen from the above figure, the recipe name is stored in the h1 tag under the div of class="recipe_title", and its class="recipe_title" is contained in the div of class="recipe_header_info". Move the mouse to the div of class="recipe_header_info", and it is found that the div stores the following information
As can be seen from the above figure, the recipe name is stored in the h1 tag under the div of class="recipe_title", and its class="recipe_title" is contained in the div of class="recipe_header_info". Move the mouse to the div of class="recipe_header_info", and it is found that the div stores the following information
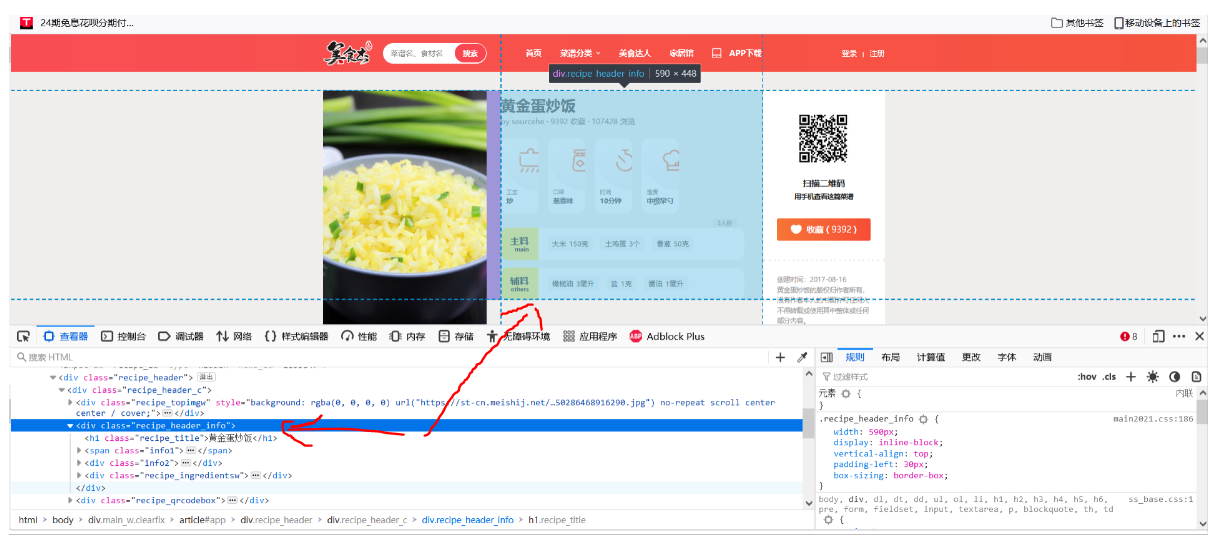
It can be seen from the figure that the menu name, difficulty, required time, main ingredients and auxiliary ingredients are all in this div, and these are the data we need to crawl. At this time, the crawler code is as follows:
import scrapy
from ..items import MenuItem
class GetmenuSpider(scrapy.Spider):
name = 'getmenu'
allowed_domains = ['https://www.meishij.net']
start_urls = ['https://www.meishij.net/fenlei/chaofan/']
def parse(self, response):
urls = response.xpath('//div[@class="imgw"]/a[@class="list_s2_item_img"]/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse2, dont_filter=True) # Submit url to next level
def parse2(self, response):
menuitem = MenuItem()
#Recipe name
menuitem['name'] = response.xpath('//div[@class="recipe_header_c"]/div[2]/h1/text()').extract()
#Main material + integration
mat1 = ""
material1list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[1]/div[2]/strong/a/text()').extract()
for i in range(0, len(material1list)):
mat1 = mat1 + material1list[i]
menuitem['material1'] = mat1
#Batching + integration
mat2 = ""
material2list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[2]/div[2]/strong/a/text()').extract()
for i in range(0, len(material2list)):
mat2 = mat2 + material2list[i]
menuitem['material2'] = mat2
#Difficulty level
menuitem['level'] = response.xpath('//div[@class="info2"]/div[4]/strong/text()').extract()
#Time required
menuitem['needtime'] = response.xpath('//div[@class="info2"]/div[3]/strong/text()').extract()
print(menuitem)
Run start Py starts the crawler, and the results are shown in the figure below
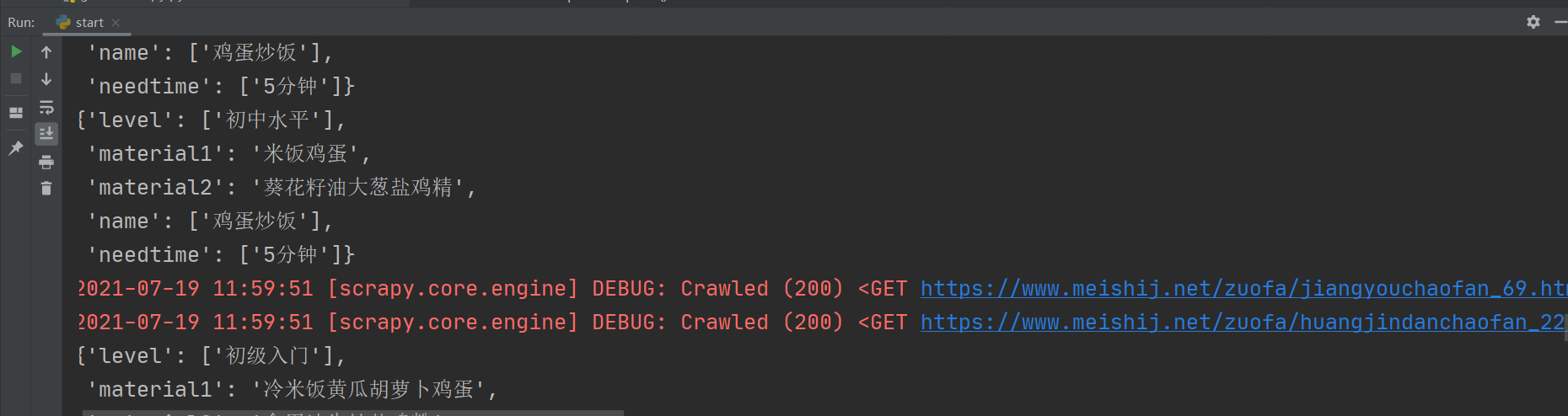 As can be seen from the figure, we have obtained the menu name, difficulty, required time, main ingredients and auxiliary ingredients. However, except for the main ingredients and auxiliary ingredients, the values of other data items are a list, which is very inconvenient for us to operate the data (for example, if we want to save the crawler data into the MySQL database, the list type data cannot be saved), Therefore, we convert the data of list type into string type. At this time, the crawler code is as follows:
As can be seen from the figure, we have obtained the menu name, difficulty, required time, main ingredients and auxiliary ingredients. However, except for the main ingredients and auxiliary ingredients, the values of other data items are a list, which is very inconvenient for us to operate the data (for example, if we want to save the crawler data into the MySQL database, the list type data cannot be saved), Therefore, we convert the data of list type into string type. At this time, the crawler code is as follows:
import scrapy
from ..items import MenuItem
class GetmenuSpider(scrapy.Spider):
name = 'getmenu'
allowed_domains = ['https://www.meishij.net']
start_urls = ['https://www.meishij.net/fenlei/chaofan/']
def parse(self, response):
urls = response.xpath('//div[@class="imgw"]/a[@class="list_s2_item_img"]/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse2, dont_filter=True) # Submit url to next level
def parse2(self, response):
menuitem = MenuItem()
#Recipe name
menuitem['name'] = response.xpath('//div[@class="recipe_header_c"]/div[2]/h1/text()').extract()
#Main material + integration
mat1 = ""
material1list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[1]/div[2]/strong/a/text()').extract()
for i in range(0, len(material1list)):
mat1 = mat1 + material1list[i]
menuitem['material1'] = mat1
#Batching + integration
mat2 = ""
material2list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[2]/div[2]/strong/a/text()').extract()
for i in range(0, len(material2list)):
mat2 = mat2 + material2list[i]
menuitem['material2'] = mat2
#Difficulty level
menuitem['level'] = response.xpath('//div[@class="info2"]/div[4]/strong/text()').extract()
#Time required
menuitem['needtime'] = response.xpath('//div[@class="info2"]/div[3]/strong/text()').extract()
#Format -- list to string
menuitem['name'] = ''.join(menuitem['name'])
menuitem['level'] = ''.join(menuitem['level'])
menuitem['needtime'] = ''.join(menuitem['needtime'])
print(menuitem)
Run start Py starts the crawler, and the results are shown in the figure below
 So far, we have successfully crawled the menu name, including difficulty, required time, main ingredients and auxiliary ingredients. The data to be crawled include:
So far, we have successfully crawled the menu name, including difficulty, required time, main ingredients and auxiliary ingredients. The data to be crawled include:
4.3.2 climb the menu picture link
Similarly to the above method, it is not difficult to find the src attribute of the img tag under the first div under the div of the picture link class="recipe_header_c".
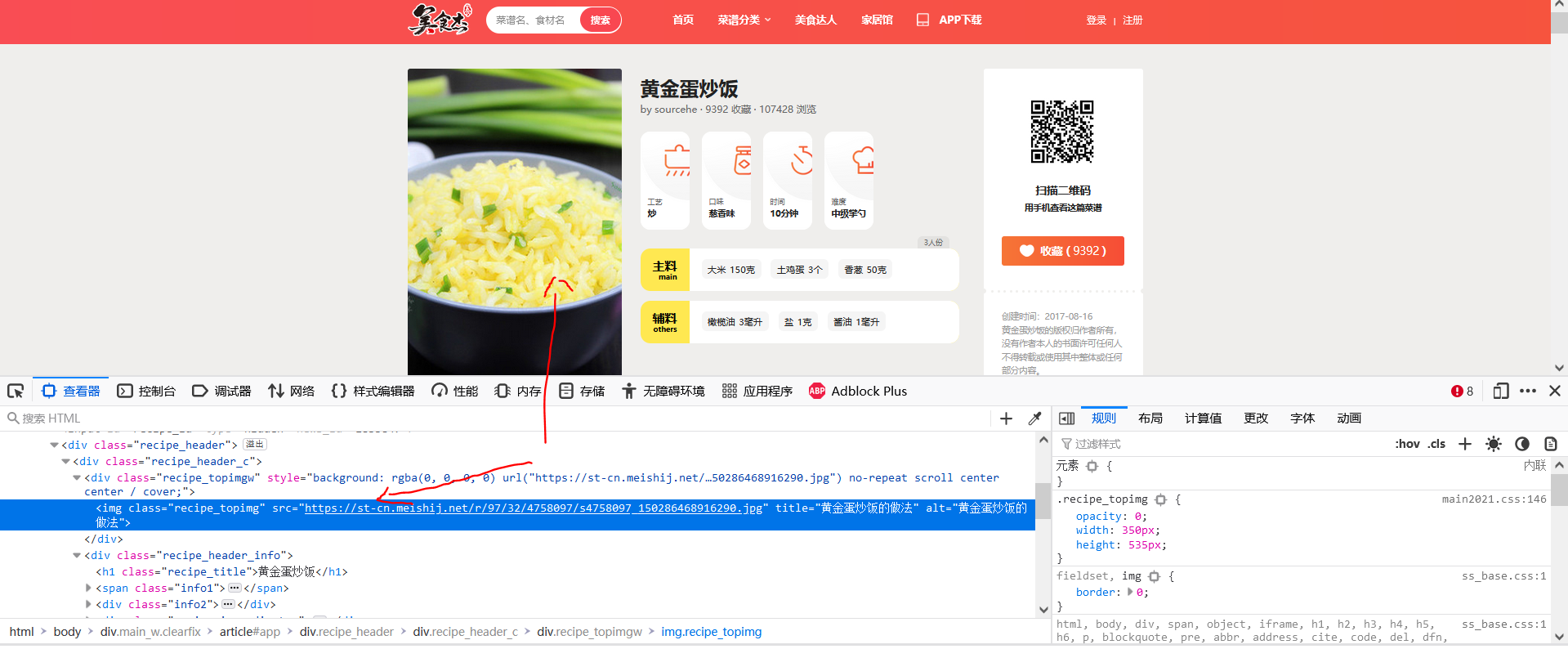 Therefore, the following code should be added to parse2 of the crawler code
Therefore, the following code should be added to parse2 of the crawler code
#Menu picture
menuitem['img'] = response.xpath('//div[@class="recipe_header_c"]/div[1]/img/@src').extract()
4.3.3 practice steps of crawling recipes
Similarly to the above methods, it is not difficult to find that there are many div's of class="recipe_step". After verification, they are the div's for storing steps, and each div stores one step. At this time, we need to get all the steps, that is, get all the div's for storing steps, and then take out the content of the p tag of the div of class="step_content", which is the content of each step
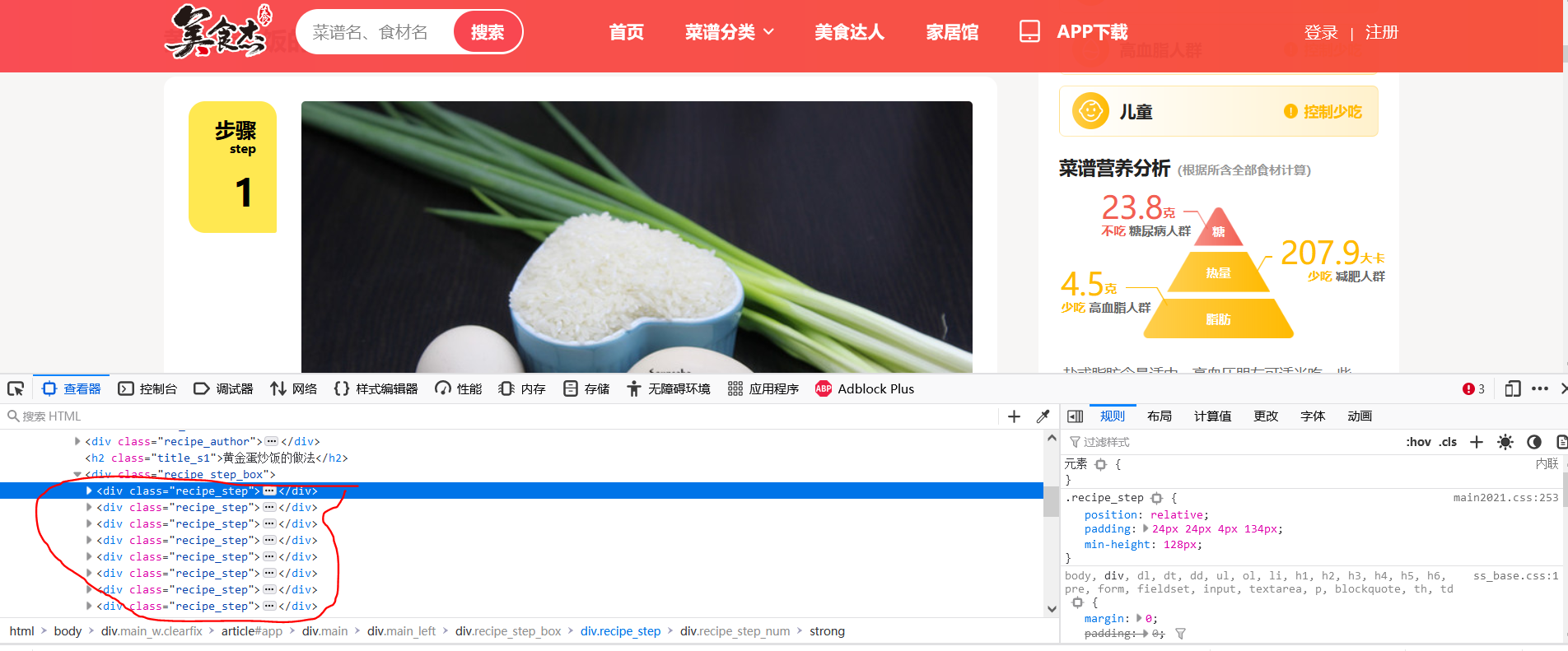 Therefore, in order to crawl the recipe steps, the following code should be added to parse2 of the crawler Code:
Therefore, in order to crawl the recipe steps, the following code should be added to parse2 of the crawler Code:
#Step + integration
steplist = response.xpath('//div[@class="recipe_step"]/div[@class="step_content"]/p/text()').extract() # here are the steps of a recipe
step = ""
for i in range(0, len(steplist)): #Traverse the step list and synthesize a string as the recipe step
step = step + steplist[i]
menuitem['step'] = step
4.3.4 crawling heat, sugar content and fat content
Similarly to the above method, it is not difficult to find that calories, sugar content and fat content are included in the div of class="jztbox", as shown in the figure below
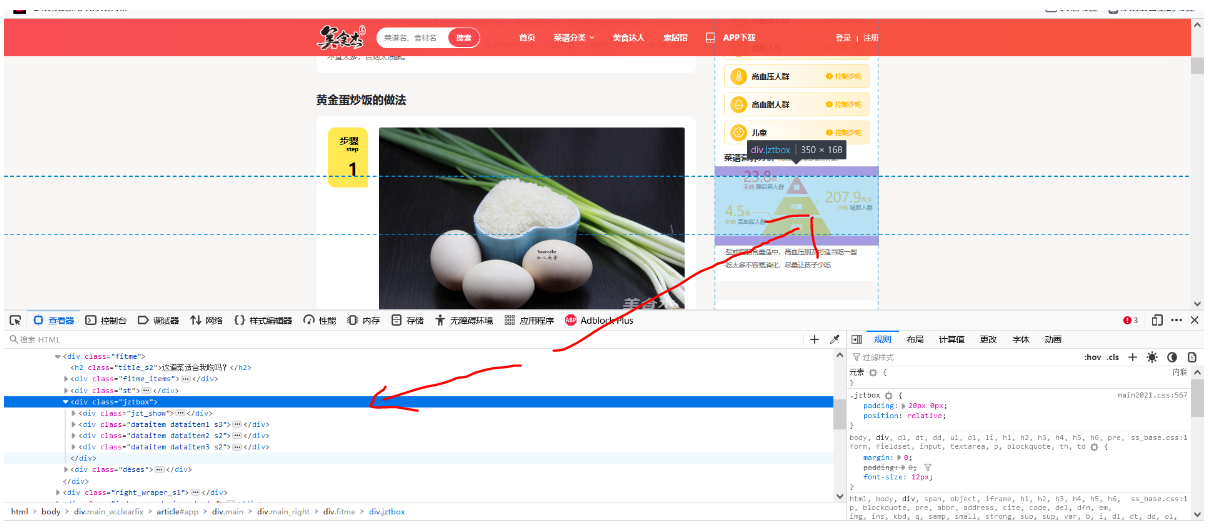 After observation, the content of heat under the third div under the div of class="jztbox", the content of sugar under the second div under the div of class="jztbox", the content of fat under the first div under the fourth div of class="jztbox", so the following code should be added to parse2 of crawler Code:
After observation, the content of heat under the third div under the div of class="jztbox", the content of sugar under the second div under the div of class="jztbox", the content of fat under the first div under the fourth div of class="jztbox", so the following code should be added to parse2 of crawler Code:
menuitem['energy'] = response.xpath('//div[@class="jztbox"]/div[3]/div[1]/text()').extract()
menuitem['sugar'] = response.xpath('//div[@class="jztbox"]/div[2]/div[1]/text()').extract()
menuitem['fat'] = response.xpath('div[@class="jztbox"]/div[4]/div[1]/text()').extract()
At this time, the crawler code is as follows:
import scrapy
from ..items import MenuItem
class GetmenuSpider(scrapy.Spider):
name = 'getmenu'
allowed_domains = ['https://www.meishij.net']
start_urls = ['https://www.meishij.net/fenlei/chaofan/']
def parse(self, response):
urls = response.xpath('//div[@class="imgw"]/a[@class="list_s2_item_img"]/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse2, dont_filter=True) # Submit url to next level
def parse2(self, response):
menuitem = MenuItem()
#Recipe name
menuitem['name'] = response.xpath('//div[@class="recipe_header_c"]/div[2]/h1/text()').extract()
#Main material + integration
mat1 = ""
material1list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[1]/div[2]/strong/a/text()').extract()
for i in range(0, len(material1list)):
mat1 = mat1 + material1list[i]
menuitem['material1'] = mat1
#Batching + integration
mat2 = ""
material2list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[2]/div[2]/strong/a/text()').extract()
for i in range(0, len(material2list)):
mat2 = mat2 + material2list[i]
menuitem['material2'] = mat2
#Difficulty level
menuitem['level'] = response.xpath('//div[@class="info2"]/div[4]/strong/text()').extract()
#Time required
menuitem['needtime'] = response.xpath('//div[@class="info2"]/div[3]/strong/text()').extract()
# Menu picture
menuitem['img'] = response.xpath('//div[@class="recipe_header_c"]/div[1]/img/@src').extract()
# Step + integration
steplist = response.xpath('//div[@class="recipe_step"]/div[@class="step_content"]/p/text()').extract()
step = ""
for i in range(0, len(steplist)):
step = step + steplist[i]
menuitem['step'] = step
#Heat, sugar and fat content
menuitem['energy'] = response.xpath('//div[@class="jztbox"]/div[3]/div[1]/text()').extract()
menuitem['sugar'] = response.xpath('//div[@class="jztbox"]/div[2]/div[1]/text()').extract()
menuitem['fat'] = response.xpath('div[@class="jztbox"]/div[4]/div[1]/text()').extract()
#Format -- list to string
menuitem['name'] = ''.join(menuitem['name'])
menuitem['level'] = ''.join(menuitem['level'])
menuitem['needtime'] = ''.join(menuitem['needtime'])
menuitem['img'] = ''.join(menuitem['img'])
menuitem['energy'] = ''.join(menuitem['energy'])
menuitem['sugar'] = ''.join(menuitem['sugar'])
menuitem['fat'] = ''.join(menuitem['fat'])
print(menuitem)
5. Store crawler data to database (MySQL)
5.1 install MySQL DB plug-in
MySQL DB is used to connect to the database in python and transfer this file( mysqlclient-2.0.1-cp37-cp37m-win_amd64.whl Extract code: 6666) and copy it to the workspace of pycham (my workplace is customized), then enter the folder where the file is located in the Terminal command window and execute install mysqlclient-2.0.1-cp37-cp37m-win_amd64.whl, wait for the installation to complete.
To verify whether the installation is successful, you only need to py file
import MySQLdb
No error can be reported
5.2 preliminary preparation of database
Create a new database with the name of menu
Create a user with username user2 and password 123
Create a table for cookbook2
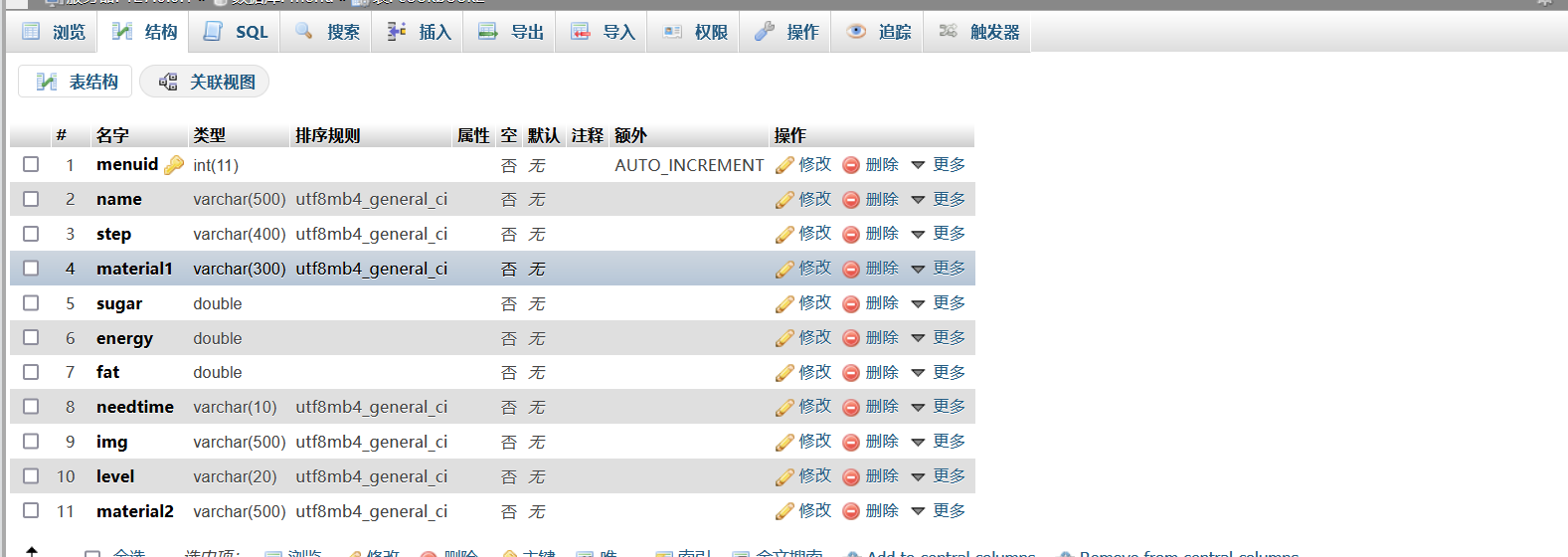
The structure of cookbook2 is as follows (pay attention to the encoding format and set the one that can display Chinese, otherwise there may be garbled code or insertion failure)
5.3 database connection configuration
In settings Py file, add the following code:
mysql_host='127.0.0.1' #address mysql_user='user2' #Authorized user name mysql_passwd='123' #Authorized access password mysql_db='menu' #Database name mysql_tb='cookbook2' #Table name mysql_port=3306 #Port, default 3306
In settings Py file found item_ Pipeline, and add the following code:
'menu.pipelines.MenusqlPipeline': 2,
My ITEM_PIPELINES are as follows:
ITEM_PIPELINES = {
#The smaller the number, the higher the priority
#menu.pipelines.Class, class and pipelines Py, such as menu pipelines. MenusqlPipeline
'menu.pipelines.MenuPipeline': 300,
'menu.pipelines.MenusqlPipeline': 2, #Submit to database
}
In pipelines Py add the following code:
import MySQLdb
from .settings import mysql_host,mysql_db,mysql_user,mysql_passwd,mysql_port
class MenusqlPipeline(object):
def __init__(self):
host=mysql_host
user=mysql_user
passwd=mysql_passwd
port=mysql_port
db=mysql_db
self.connection=MySQLdb.connect(host,user,passwd,db,port,charset='utf8')
self.cursor=self.connection.cursor()
def process_item(self, item, spider):
sql = "insert into cookbook2(name,step,sugar,energy,fat,material1,needtime,img,level,material2) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
#Note that the order in which params is added should be consistent with the order in which sql statements are inserted, otherwise dislocation or even insertion failure will occur
params=list()
params.append(item['name'])
params.append(item['step'])
params.append(item['sugar'])
params.append(item['energy'])
params.append(item['fat'])
params.append(item['material1'])
params.append(item['needtime'])
params.append(item['material2'])
params.append(item['img'])
params.append(item['level'])
self.cursor.execute(sql,tuple(params))
self.connection.commit()
return item
def __del__(self):
self.cursor.close()
self.connection.close()
5.4 start crawler
Add return menuitem to the last line of the crawler, as follows:
import scrapy
from ..items import MenuItem
class GetmenuSpider(scrapy.Spider):
name = 'getmenu'
allowed_domains = ['https://www.meishij.net']
start_urls = ['https://www.meishij.net/fenlei/chaofan/']
def parse(self, response):
urls = response.xpath('//div[@class="imgw"]/a[@class="list_s2_item_img"]/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse2, dont_filter=True) # Submit url to next level
def parse2(self, response):
menuitem = MenuItem()
#Recipe name
menuitem['name'] = response.xpath('//div[@class="recipe_header_c"]/div[2]/h1/text()').extract()
#Main material + integration
mat1 = ""
material1list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[1]/div[2]/strong/a/text()').extract()
for i in range(0, len(material1list)):
mat1 = mat1 + material1list[i]
menuitem['material1'] = mat1
#Batching + integration
mat2 = ""
material2list = response.xpath(
'//div[@class="recipe_ingredientsw"]/div[2]/div[2]/strong/a/text()').extract()
for i in range(0, len(material2list)):
mat2 = mat2 + material2list[i]
menuitem['material2'] = mat2
#Difficulty level
menuitem['level'] = response.xpath('//div[@class="info2"]/div[4]/strong/text()').extract()
#Time required
menuitem['needtime'] = response.xpath('//div[@class="info2"]/div[3]/strong/text()').extract()
# Menu picture
menuitem['img'] = response.xpath('//div[@class="recipe_header_c"]/div[1]/img/@src').extract()
# Step + integration
steplist = response.xpath('//div[@class="recipe_step"]/div[@class="step_content"]/p/text()').extract()
step = ""
for i in range(0, len(steplist)):
step = step + steplist[i]
menuitem['step'] = step
#Heat, sugar and fat content
menuitem['energy'] = response.xpath('//div[@class="jztbox"]/div[3]/div[1]/text()').extract()
menuitem['sugar'] = response.xpath('//div[@class="jztbox"]/div[2]/div[1]/text()').extract()
menuitem['fat'] = response.xpath('div[@class="jztbox"]/div[4]/div[1]/text()').extract()
#Format -- list to string
menuitem['name'] = ''.join(menuitem['name'])
menuitem['level'] = ''.join(menuitem['level'])
menuitem['needtime'] = ''.join(menuitem['needtime'])
menuitem['img'] = ''.join(menuitem['img'])
menuitem['energy'] = ''.join(menuitem['energy'])
menuitem['sugar'] = ''.join(menuitem['sugar'])
menuitem['fat'] = ''.join(menuitem['fat'])
# print(menuitem)
return menuitem
By running start Py start the crawler to check whether the database is successfully inserted: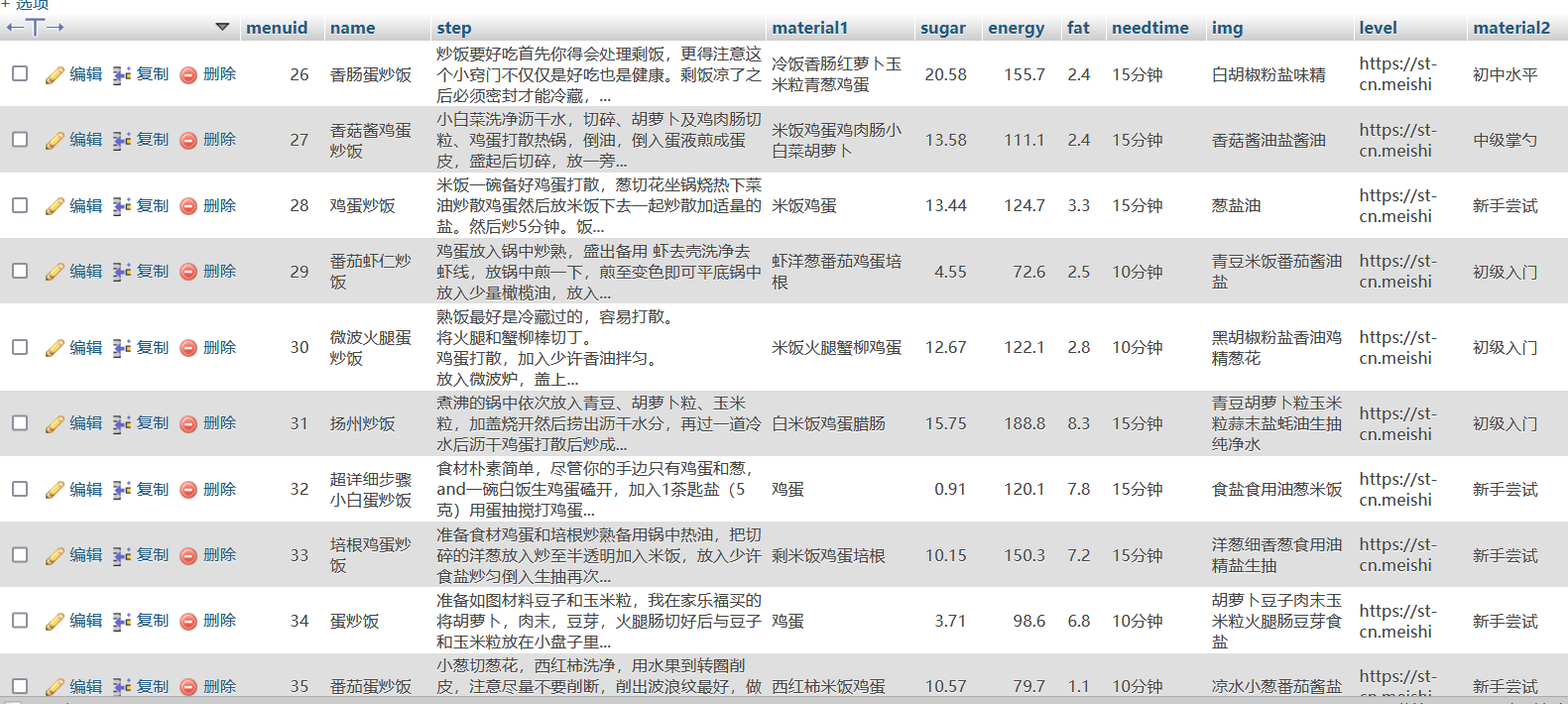 Insert succeeded!
Insert succeeded!