SQL DDL: user defined function UDF
What is UDF?
In addition to built-in functions, Hive supports functions that allow you to write user-defined functions to expand the functions of functions.
User defined functions need to be written in Java language, and the completed UDF can be packaged as Jar and loaded into Hive for use.
UDF can be divided into UDF, UDAF and UDTF according to different functions.
UDF processes each line of data and outputs the result of the same number of lines. It is a one-to-one processing method, such as converting each line of string to uppercase.
UDAF (user-defined aggregate function) processes multiple rows and outputs a single result, which is a one to many processing method. Generally, UDAF is used in conjunction with group by, for example, first operate group by according to the city, and then count the total number of people in each city.
UDTF (user defined table generation function) processes one row of data and outputs multiple results in a many to one processing mode. For example, each row of string is divided into multiple rows according to spaces for storage. After using UDTF, the number of rows in the table will increase.
User defined function operation
Print the code into Jar package and upload it to the cluster. You can create temporary and permanent functions in Hive through Jar package. The temporary function is valid in Hive's life cycle. After Hive is restarted, the function fails, and the permanent function takes effect permanently.
Create command of temporary function:
ADD JAR[S] <local_or_hdfs_path>; CREATE TEMPORARY FUNCTION <function_name> AS <class_name>; DROP TEMPORARY FUNCTION [IF EXISTS] <function_name>;
Create command of permanent function:
CREATE PERMANENT FUNCTION <function_name> AS <class_name>
[USING JAR|FILE|ARCHIVE '<file_uri>' [, JAR|FILE|ARCHIVE '<file_uri>'] ];
DROP PERMANENT FUNCTION [IF EXISTS] <function_name>;
After the function is created, you can view all functions:
SHOW FUNCTIONS;
You can also view the details of a function separately:
DESCRIBE FUNCTION <function_name>;
UDF writing
Creating a UDF can inherit org apache. hadoop. Hive. ql.exec. UDF or org apache. hadoop. Hive. ql.udf. generic. GenericUDF class. The UDF class is directly inherited, and the function implementation is relatively simple. However, the Hive reflection mechanism is used at runtime, resulting in performance loss, and complex types are not supported. GenericUDF is more flexible and has better performance. It supports complex data types (List, Struct), but its implementation is more complex.
In the newer Hive version, org apache. hadoop. Hive. ql.exec. The UDF class has been abandoned. It is recommended to use GenericUDF to complete the implementation of UDF. But org apache. hadoop. Hive. ql.exec. UDF is easy to implement and is still very popular among many developers.
UDF implementation mode 1: inherit UDF classes
UDF development process
The development process of inheriting UDF classes for UDF is as follows:
- Inherit org apache. hadoop. hive. ql.exec. UDF class
- Implement the evaluate() method, and implement one-to-one single line conversion in the method
Case description
Now let's write the development of three actual cases, which need to realize the following functions:
Function 1: convert each row of data into lowercase form
Function 2: input yyyy MM DD HH: mm: SS A time string in the form of SSS, which returns the timestamp in milliseconds
Function 3: generate a random string of specified length as UUID for each row of data
UDF development: function 1
The development of function 1 is relatively simple, creating Java classes and inheriting org apache. hadoop. hive. ql.exec. UDF, and then implement the evaluate() method. Because each row of data needs to be converted to lowercase, the parameter of the evaluate() method is of type Text. First, judge the null value. If it is not empty, it will be converted to lowercase and returned.
Why do these use Text instead of String? Actually, everything is OK. However, the Text type is the Writable wrapper class of Hadoop, which is serialized and implemented. It is more convenient for data transmission in Hadoop cluster, and the Writable object is reusable and more efficient.
Common Hadoop wrapper classes are:
BooleanWritable:Standard Boolean value ByteWritable:Single byte value DoubleWritable:Double byte value FloatWritable:Floating point number IntWritable:integer LongWritable:Long integer number Text:use UTF8 Format stored text NullWritable:When<key, value>Medium key or value Use when empty
Before the UDF method, you can use the annotation Description to add Description information to the method.
The specific implementation of function 1 is as follows:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.io.Text;
@org.apache.hadoop.hive.ql.exec.Description(name = "Lower",
extended = "Example: select Lower(name) from src;",
value = "_FUNC_(col)-take col Each line of string data in the field is converted to lowercase")
public final class Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
In test Test in Java:
import org.apache.hadoop.io.Text;
public class Test {
public static void testLower(String in){
Lower lower = new Lower();
Text res = lower.evaluate(new Text(in));
System.out.println(res);
}
public static void main(String[] args) {
testLower("UDF");
}
}

After passing the test, you need to type the code into Jar package first.
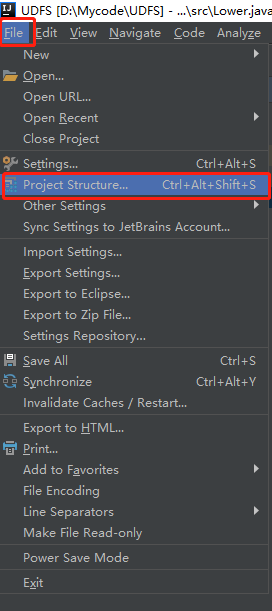
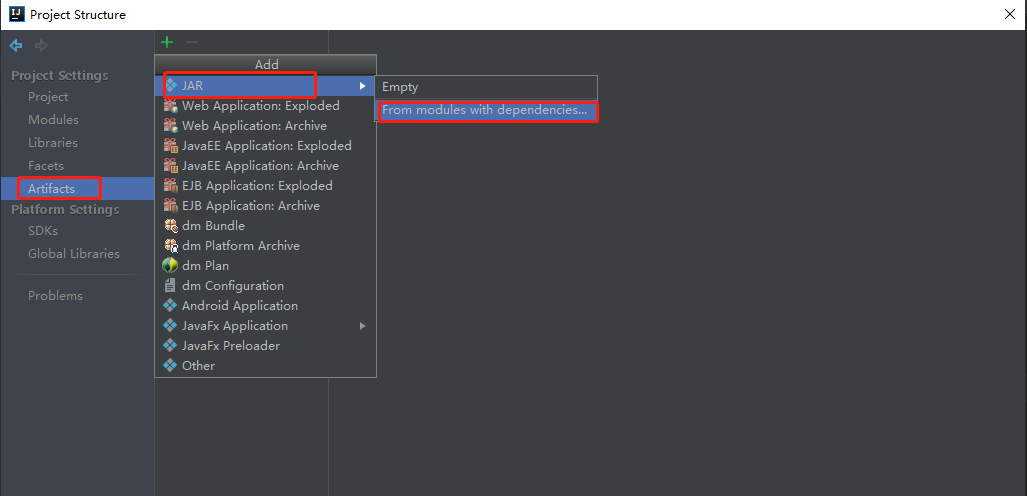
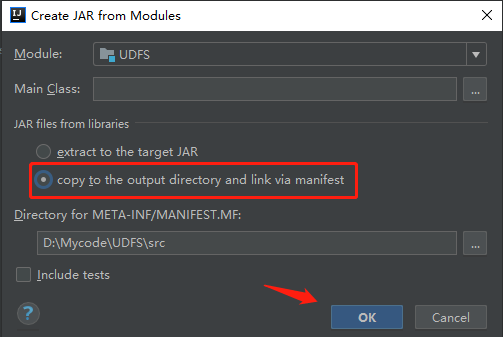
Because hadoop and hive dependencies already exist in the cluster, the dependencies in the code need to be removed.
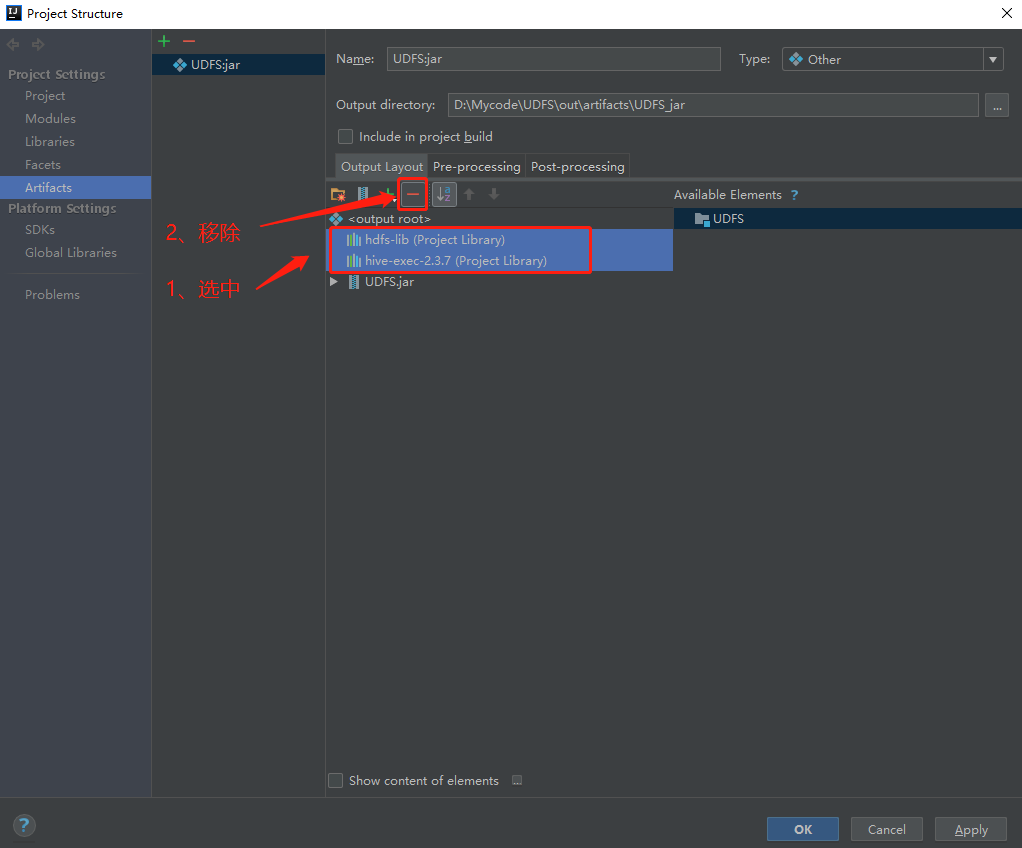
Compile the source code and generate the jar package.
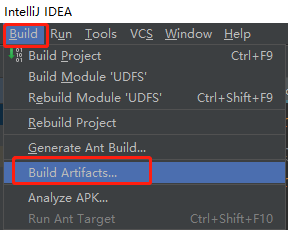
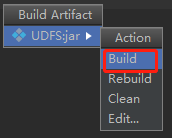
Find the compiled jar package and upload it to the / root directory of Node03 node.
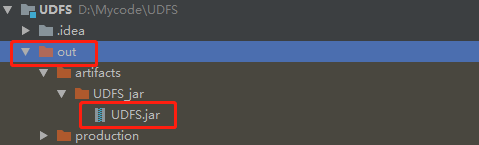
In beeline, add the jar package to hive using SQL.
add jars file:///root/UDFS.jar;

Create a temporary function UDF through the lower class in the jar package_ Lower, of course, you can also create permanent functions. In the tutorial, all subsequent functions will be created as temporary functions for convenience.
--Create temporary function create temporary function udf_lower as "Lower"; --Create permanent function create permanent function udf_lower as "Lower";

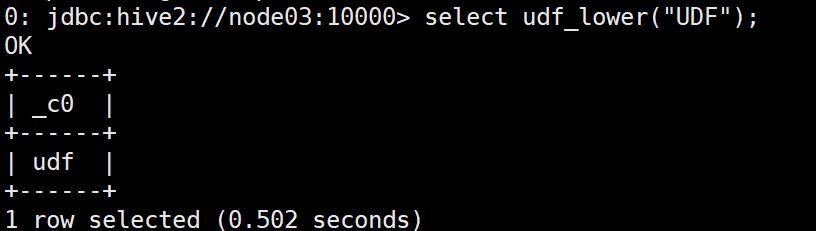
After the function is created, it can be called in SQL:
select udf_lower("UDF");
UDF development: function 2
The development of function 2 is also relatively simple. Similarly, create a java class TimeCover and inherit org apache. hadoop. hive. ql.exec. UDF, and then implement the evaluate() method.
In the method, pass yyyy MM DD HH: mm: SS The time string in SSS format will return the timestamp (in milliseconds). The specific implementation is as follows:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import java.time.LocalDate;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
@org.apache.hadoop.hive.ql.exec.Description(name = "TimeCover",
extended = "Example: select TimeCover(create_time) from src;",
value = "_FUNC_(col)-take col The form of each line in the field is yyyy-MM-dd hh:mm:ss.SSS Converts the time string of to a timestamp")
public class TimeCover extends UDF {
public LongWritable evaluate(Text time){
String dt1 = time.toString().substring(0,time.toString().indexOf("."));
String dt2 = time.toString().substring(time.toString().indexOf(".")+1);
DateTimeFormatter dtf=DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss");
long millisec;
LocalDate date = LocalDate.parse(dt1, dtf);
millisec = date.atStartOfDay(ZoneId.systemDefault()).toInstant().toEpochMilli() + Long.parseLong(dt2);
LongWritable result = new LongWritable(millisec);
return result;
}
}
Write test methods for testing:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
public class Test {
private static void testTimeCover(String in){
TimeCover timeCover = new TimeCover();
LongWritable res = timeCover.evaluate(new Text(in));
System.out.println(res.get());
}
public static void main(String[] args) {
testTimeCover("2021-01-17 05:25:30.001");
}
}
Make a jar package and create a temporary function in hive for testing. It should be noted here that hive needs to be restarted when adding jar packages with the same name repeatedly.
add jars file:///root/UDFS.jar;
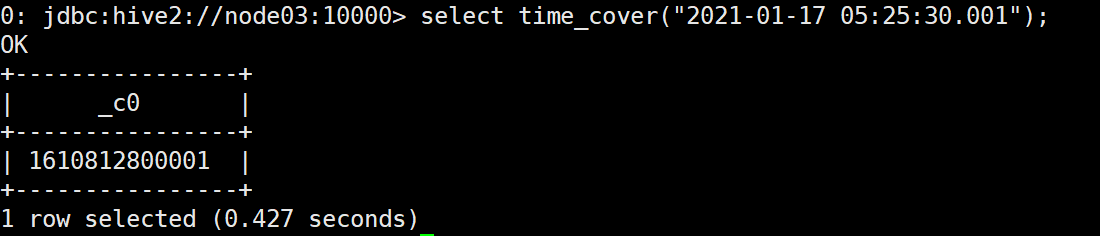
create temporary function time_cover as "TimeCover";
select time_cover("2021-01-17 05:25:30.001");
The DateTimeFormatter class is used for time processing here. If you are familiar with Java development, you should know that it is thread safe. During Hive's UDF development, we must avoid the use of thread unsafe classes, such as SimpleDateFormat. The use of thread unsafe classes will bring many problems when running in a distributed environment, produce wrong running results, and will not produce error reports, because it is not the problem of the program itself; This situation is very difficult to troubleshoot. It is normal during local testing, and there will be problems in the cluster, so we must have this awareness during development.
UDF development: function 3
The requirement of function 3 is to generate a random string of specified length as UUID for each row of data, which is different from the previous two UDFs. The first two UDFs take a field as a parameter and convert each row of data in this column; The third function is to pass in a specified value and generate a new column of data. For example, select UUID(32) from src, pass in parameter 32, and generate a 32-bit random string for each row of data.
The code implementation is relatively simple. The specific implementation is as follows:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
/*
Generates a random string of a specified length (up to 36 bits)
*/
@org.apache.hadoop.hive.ql.exec.Description(name = "UUID",
extended = "Example: select UUID(32) from src;",
value = "_FUNC_(leng)-Generates a random string of a specified length(Up to 36 bits)")
@UDFType(deterministic = false)
public class UUID extends UDF {
public Text evaluate(IntWritable leng) {
String uuid = java.util.UUID.randomUUID().toString();
int le = leng.get();
le = le > uuid.length() ? uuid.length() : le;
return new Text(uuid.substring(0, le));
}
}
Write test methods for testing:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
public class Test {
private static void testUUID(int in){
UUID uuid = new UUID();
Text res = uuid.evaluate(new IntWritable(in));
System.out.println(res);
}
public static void main(String[] args) {
testUUID(10);
}
}
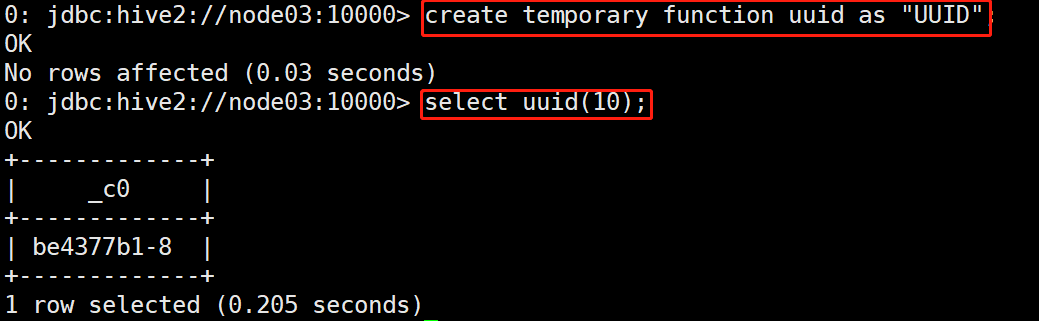
Make a Jar package and create a temporary function in hive for testing.
add jars file:///root/UDFS.jar; create temporary function uuid as "UUID"; select uuid(10);
UDF development considerations
When inheriting UDF classes for development, the evaluate() method is called by default; Of course, you can also inherit the UDFMethodResolver class and change the default entry method.
The three UDF functions that have been implemented now return data. If evaluate() does not return data, it can return null. For example, this scenario will be used in data cleaning. The return type of UDF can be Java type or Writable class. Of course, Writable wrapper class is recommended.
UDF implementation mode 2: inherit GenericUDF class
Inherit org apache. hadoop. hive. ql.udf. generic. Genericudf class is used to develop UDF, which is recommended by the community. It can handle complex type data and is more flexible than UDF classes. But the implementation will be slightly more complex.
Development process
The specific process of UDF development using GenericUDF is as follows:
- Inherit org apache. hadoop. hive. ql.udf. generic. Genericudf class
- Implement the initialize, evaluate, getDisplayString methods
The functions of the three rewritten methods are as follows:
| Interface method | Return value | describe |
|---|---|---|
| initialize | ObjectInspector | Global initialization is generally used to check the number and type of parameters, initialize the parser, and define the return value type |
| evaluate | Object | Perform data processing and return the final result |
| getDisplayString | String | The string content displayed by the function during HQL explain parsing |
GenericUDF actual case
Now, complete a UDF development case to practice. In this case, the complex data type Map will be processed.
In the table, the student's score field data is saved in Map type:
{"computer":68, "chinese": 95, "math": 86, "english": 78}
Now, we need to develop UDF to calculate the average of each student's grade. That is, extract the Map data saved in each row. After obtaining the scores (68, 95, 86, 78), complete the calculation of the average value ((68 + 95 + 86 + 78) / 4) and return the results. Accuracy requirements: keep two decimal places.
First, import related packages, inherit GenericUDF, and rewrite its three methods:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.MapObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.text.DecimalFormat;
@org.apache.hadoop.hive.ql.exec.Description(name = "AvgScore",
extended = "Example: select AvgScore(score) from src;",
value = "_FUNC_(col)-yes Map Calculate the average of student scores saved by type")
public class AvgScore extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {...}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {...}
@Override
public String getDisplayString(String[] strings) {...}
}
In the AvgScore class, you need to define class properties to save basic information. The UDF name and return value precision defined here also contain an object of the parameter resolution class MapObjectInspector. Because GenericUDF parses and converts the incoming data through parameter parsing objects, it has better flexibility than directly inheriting UDF classes and supports the processing of various complex types of data.
@org.apache.hadoop.hive.ql.exec.Description(name = "AvgScore",
extended = "Example: select AvgScore(score) from src;",
value = "_FUNC_(col)-yes Map Calculate the average of student scores saved by type")
public class AvgScore extends GenericUDF {
// UDF name
private static final String FUNC_NAME="AVG_SCORE";
// Parameter resolution object
private transient MapObjectInspector mapOi;
// Return value precision
DecimalFormat df = new DecimalFormat("#.##");
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {...}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {...}
@Override
public String getDisplayString(String[] strings) {...}
}
Then rewrite the initialize method to detect the number and type of parameters, initialize the data parsing object, and define the final return value type of UDF.
The formal parameter ObjectInspector [] in the initialize method is the data object of the parameter list passed in by UDF when calling. In the case of AvgScore(score), if the score field is passed in, the length of the ObjectInspector [] list is 1. The ObjectInspector object contains the data of the score field and its parameter number, type and other attributes.
In the method, data type detection is required for parameters. The data types supported by GenericUDF are in objectinspector Category. Including basic data type: PRIMITIVE, complex data type: list, map, structure, union.
In addition, you also need to initialize the ObjectInspector object for data parsing and specify the data type to be parsed. The data analysis classes provided include PrimitiveObjectInspector, ListObjectInspector, mapobjectinspector, structobjectinspector, etc.
The initialize function needs to return the data type of the final output of the UDF when returning. Here, because the average value of the score is calculated, the final result is of type Double and returns javaDoubleObjectInspector.
The initialize function actually defines the input and output of data, and checks the data type and number.
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// Number of detection function parameters
if (objectInspectors.length != 1) {
throw new UDFArgumentException("The function AVG_SCORE accepts only 1 arguments.");
}
// Detect the function parameter type. The provided types include primary, list, map, structure and union
if (!(objectInspectors[0].getCategory().equals(ObjectInspector.Category.MAP))) {
throw new UDFArgumentTypeException(0, "\"map\" expected at function AVG_SCORE, but \""
+ objectInspectors[0].getTypeName() + "\" " + "is found");
}
// Initializes the ObjectInspector object for data parsing
// The classes provided include PrimitiveObjectInspector, ListObjectInspector, mapobjectinspector, structobjectinspector, etc
mapOi = (MapObjectInspector) objectInspectors[0];
// Defines the data type of the output result of the UDF function
return PrimitiveObjectInspectorFactory.javaDoubleObjectInspector;
}
Next, you need to rewrite the evaluate method, use the data parsing object for data parsing, and calculate the average value.
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// Get input data
Object o = deferredObjects[0].get();
// The data is parsed and processed by the ObjectInspector object
double v = mapOi.getMap(o).values().stream().mapToDouble(a -> Double.parseDouble(a.toString())).average().orElse(0.0);
// Returns the operation result. The result data type has been defined in initialize
return Double.parseDouble(df.format(v));
}
Finally, rewrite getDisplayString method to complete the output of string information.
@Override
public String getDisplayString(String[] strings) {
// The string content displayed by the function during HQL explain parsing
return "func(map)";
}
Package it into jar and create temporary functions in hive.
add jars file:///root/UDFS.jar; create temporary function avg_score as "AvgScore";
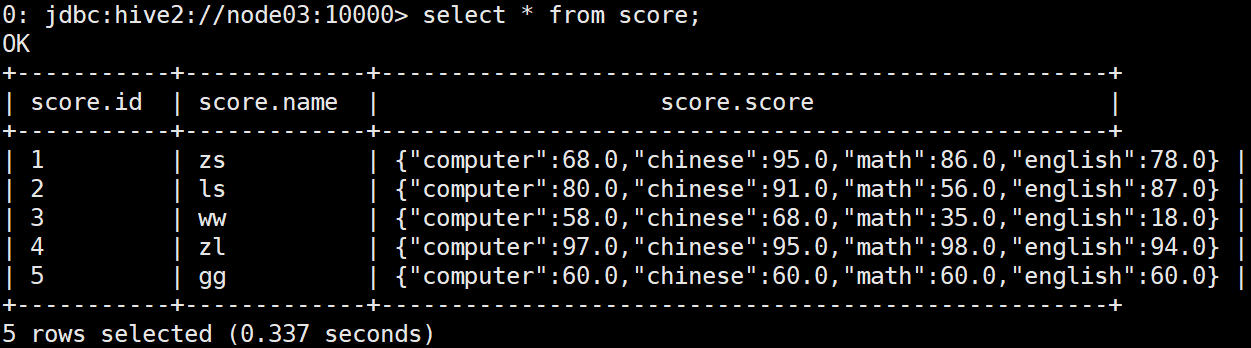
Create test data score Txt and upload it to / TMP / hive of HDFS_ data_ Under score Directory:
# Data file content 1,zs,computer:68-chinese:95-math:86-english:78 2,ls,computer:80-chinese:91-math:56-english:87 3,ww,computer:58-chinese:68-math:35-english:18 4,zl,computer:97-chinese:95-math:98-english:94 5,gg,computer:60-chinese:60-math:60-english:60 # Upload to HDFS hadoop fs -mkdir -p /tmp/hive_data/score hadoop fs -put score.txt /tmp/hive_data/score/
Create the data table required for the test in Hive:
create external table score(id int, name string, score map<string, double>) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY '\n' LOCATION '/tmp/hive_data/score/';
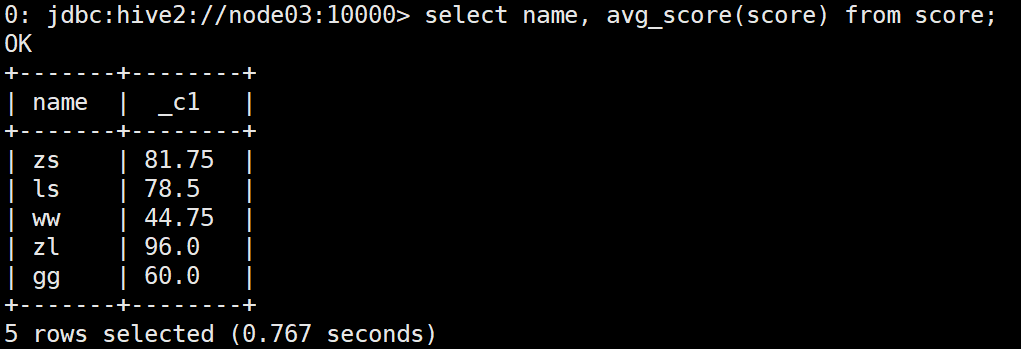
Use the UDF function to calculate the average score:
select name, avg_score(score) from score;