Preface
In this paper, we will introduce the process of creating the source table and result table jobs in Blink real-time computing platform.
Table storage channel service
Form store Channel service It is a full incremental integrated service based on the data interface of the table store. Through a set of Tunnel Service API s and SDK s, it provides users with three types of distributed data real-time consumption channels: incremental, full and incremental plus full. By establishing Tunnel Service data channel for data table, users can process the historical stock and new data in the table through flow calculation.
Flow calculation can take Tunnel Service data channel as the input of flow data, and each data is similar to a JSON format, as shown below:
{ "OtsRecordType": "PUT", // Data operation type, including PUT, UPDATE, DELETE "OtsRecordTimestamp": 1506416585740836, //Data write time (microseconds), 0 for full data "PrimaryKey": [ { "ColumnName": "pk_1", //First primary key column "Value": 1506416585881590900 }, { "ColumnName": "pk_2", //Second primary key column "Value": "string_pk_value" } ], "Columns": [ { "OtsColumnType": "Put", // Column operation types, including PUT, delete one version, delete all version "ColumnName": "attr_0", "Value": "hello_table_store", }, { "OtsColumnType": "DELETE_ONE_VERSION", // DELETE operation has no Value field "ColumnName": "attr_1" } ] }
Among them, each primary key and attribute column value of data can be read in BLINK DDL by column name and corresponding type mapping. For example, the DDL we need to define is as follows:
create table tablestore_stream( pk_1 BIGINT, pk_2 VARCHAR, attr_0 VARCHAR, attr_1 DOUBLE, primary key(pk_1, pk_2) ) with ( type ='ots', endPoint ='http://blink-demo.cn-hangzhou.vpc.tablestore.aliyuncs.com', instanceName = "blink-demo", tableName ='demo_table', tunnelName = 'blink-demo-stream', accessId ='xxxxxxxxxxx', accessKey ='xxxxxxxxxxxxxxxxxxxxxxxxxxxx', ignoreDelete = 'false' //Whether to ignore data of delete operation );
If the field name has a prefix, you need to use reverse apostrophe. For example, the OTS field name is TEST.test, and the BLINK DDL is defined as TEST.test. The OtsRecordType, OtsRecordTimestamp fields, and the OtsColumnType field of each Column can be read by property fields:
| Field name | Explain |
|---|---|
| OtsRecordType | Data operation type |
| OtsRecordTimestamp | Data operation time (0 for full data) |
| Column name | Spliced with a specific column name and "OtsColumnType", the operation type of a column |
When OtsRecordType and OtsColumnType fields of some columns are required, Blink provides the HEADER keyword to obtain the property fields in the source table. The specific DDL is:
create table tablestore_stream( OtsRecordType VARCHAR HEADER, OtsRecordTimestamp BIGINT HEADER, pk_1 BIGINT, pk_2 VARCHAR, attr_0 VARCHAR, attr_1 DOUBLE, attr_1_OtsColumnType VARCHAR HEADER, primary key(pk_1, pk_2) ) with ( ... );
WITH parameter
| parameter | Explanatory notes | Remarks |
|---|---|---|
| endPoint | Instance access address of table store | endPoint |
| instanceName | Instance name of the table store | instanceName |
| tableName | Data table name stored in the table | tableName |
| tunnelName | Table stores the data channel name of the data table | tunnelName |
| accessId | Table stores the accessKey read | accessId |
| accessKey | Table store read secret key | |
| ignoreDelete | Whether to ignore real-time data of DELETE operation type | Optional, default is false |
SQL example
For data synchronization, ots sink will write the result table in the form of update:
create table otsSource ( pkstr VARCHAR, pklong BIGINT, col0 VARCHAR, primary key(pkstr, pklong) ) WITH ( type ='ots', endPoint ='http://blink-demo.cn-hangzhou.ots.aliyuncs.com', instanceName = "blink-demo", tableName ='demo_table', tunnelName = 'blink-demo-stream', accessId ='xxxxxxxxxxx', accessKey ='xxxxxxxxxxxxxxxxxxxxxxxxxxxx', ignoreDelete = 'true' ); CREATE TABLE otsSink ( pkstr VARCHAR, pklong BIGINT, col0 VARCHAR, primary key(pkstr, pklong) ) WITH ( type='ots', instanceName='blink-target', tableName='demo_table', accessId ='xxxxxxxxxxx', accessKey ='xxxxxxxxxxxxxxxxxxxxxxxxxxxx', endPoint='https://blink-target.cn-hangzhou.ots.aliyuncs.com', valueColumns='col0' ); INSERT INTO otsSink SELECT t.pkstr, t.pklong, t.col0 FROM otsSource AS t
Flow calculation job establishment process
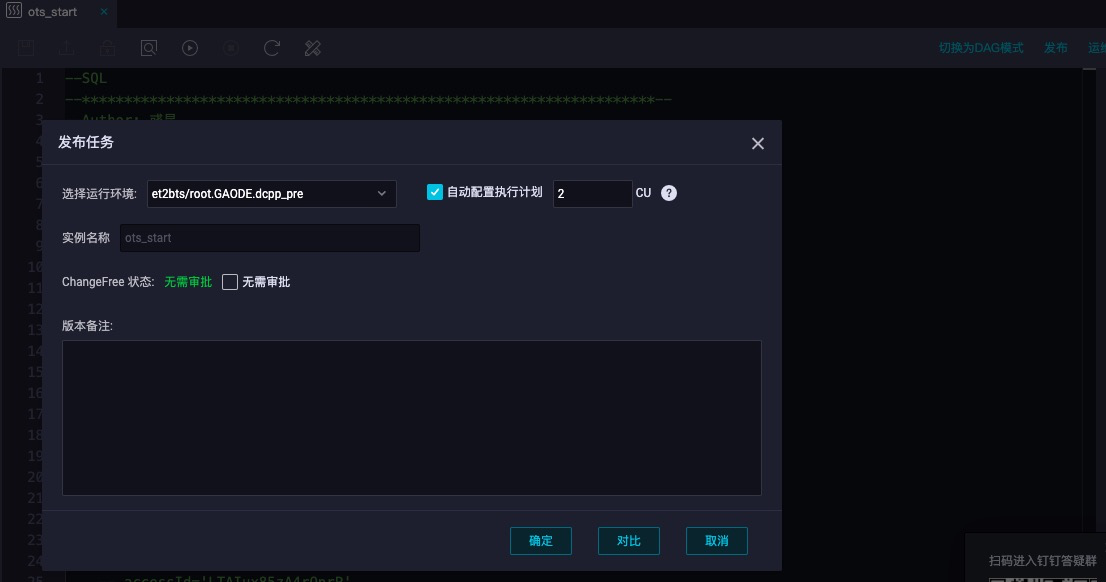
Create a new task in the data development module of Blink real time computing platform, and fill in the node type, Blink version, node name, target folder and other relevant contents, as shown in the following figure: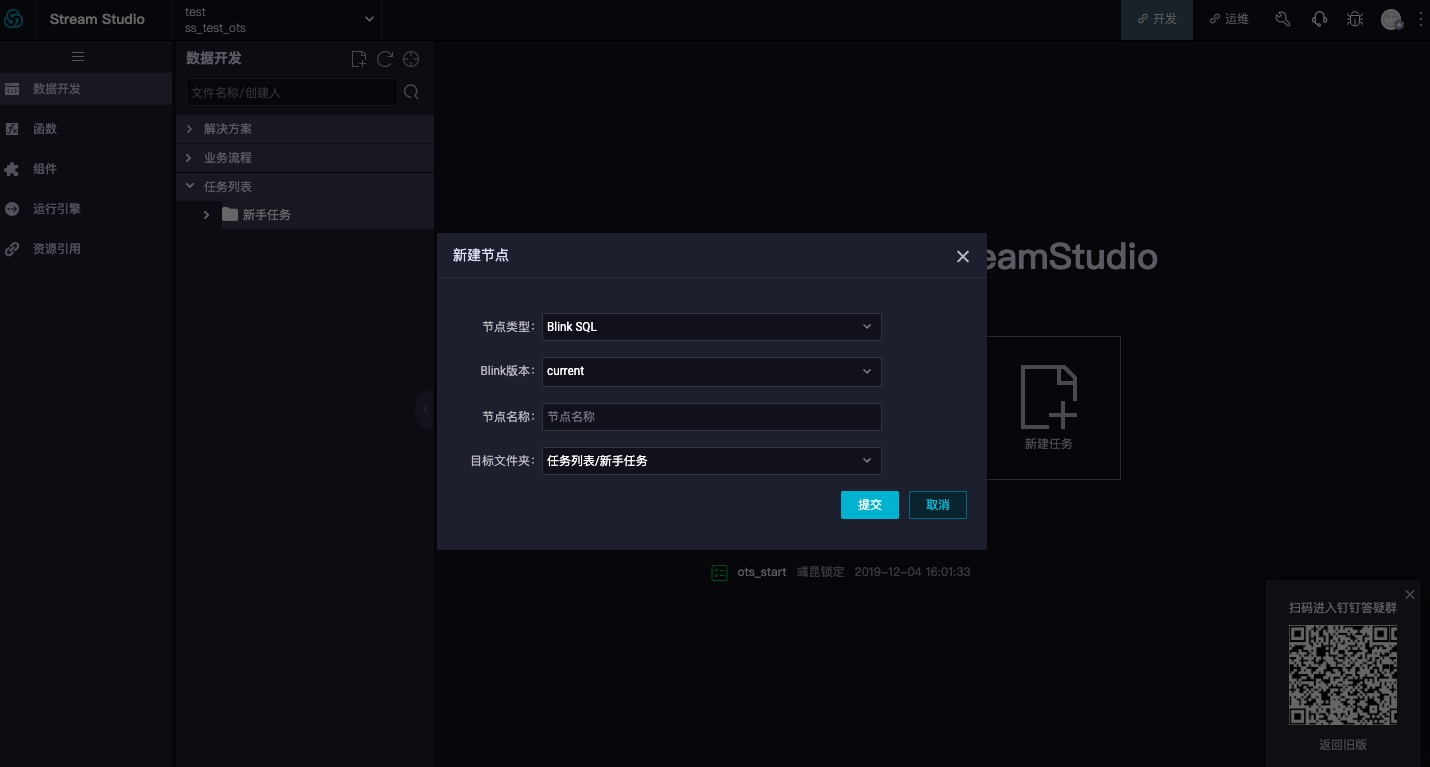
After creating a new task, enter the task and click switch to SQL mode. Develop your own tasks according to the DDL definitions introduced earlier. As shown in the figure below: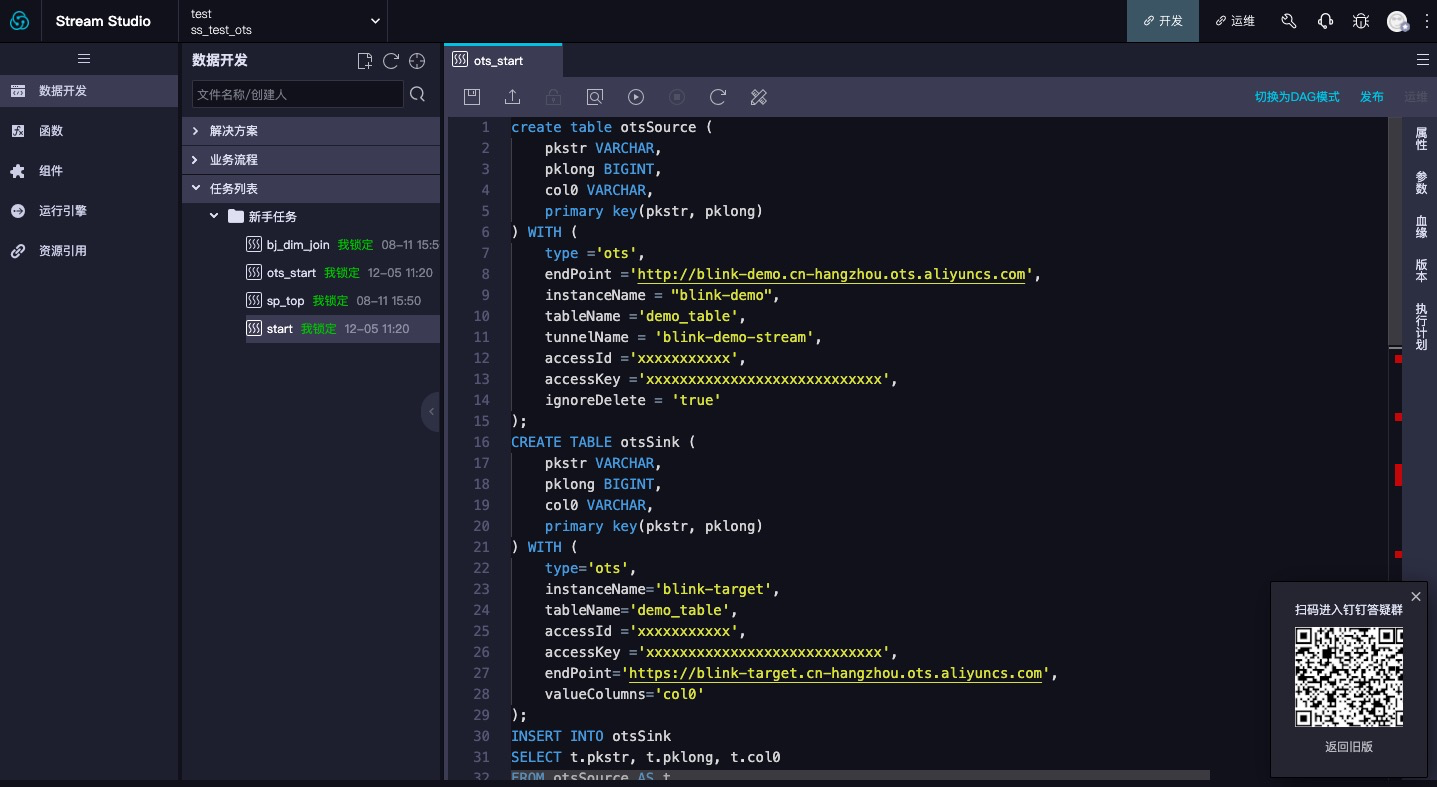
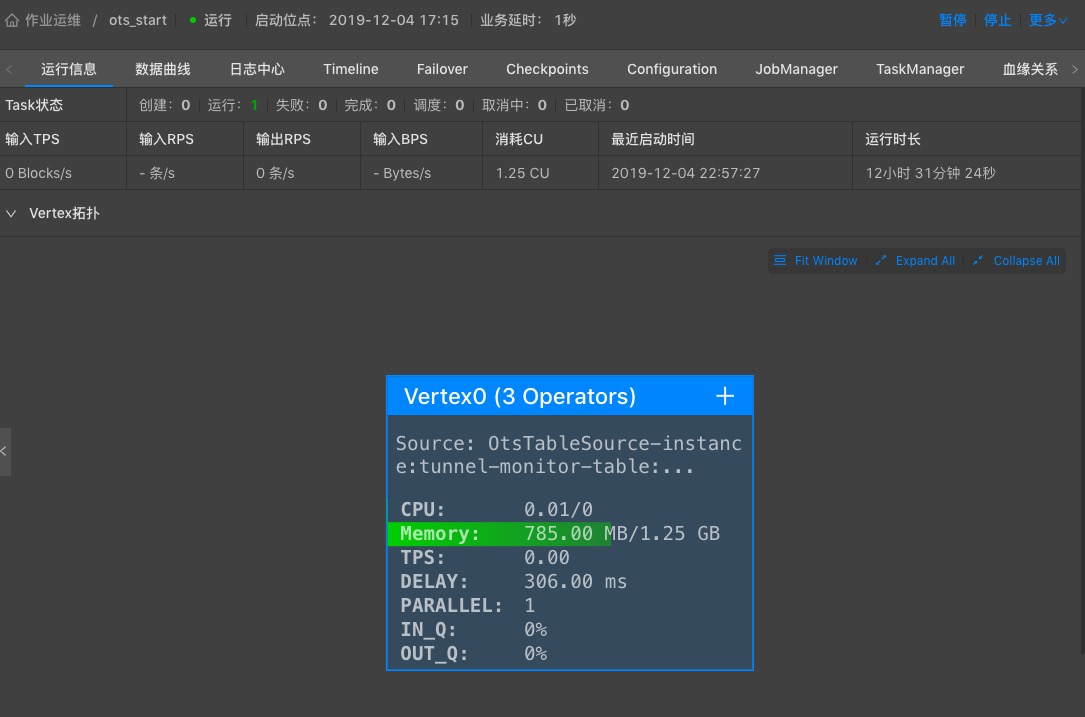
After the job is completed, click publish, select the operation environment and configure the available CU, and the established streaming job will be officially started. You can manage the job and view the relevant information of job operation through the operation and maintenance interface. As shown in the figure below: