positive? inactive? Neutral? Sentences can be analyzed using the Stanford CoreNLP component and a few lines of code.
This article describes how to implement such tasks in Java using emotion tools integrated into Stanford CoreNLP, an open source library for natural language processing.
Stanford CoreNLP emotion classifier
To perform emotion analysis, you need an emotion classifier, a tool that can identify emotional information based on predictions learned from the training data set.
In Stanford CoreNLP, emotion classifier is based on recurrent neural network (RNN) deep learning model, which is trained on Stanford emotion tree (SST).
SST dataset is a corpus with emotion tags, which deduces each syntactically possible phrase from thousands of used sentences, so as to capture the composition effect of emotion in the text. Simply put, this allows the model to identify emotions based on how words form the meaning of phrases, not just by evaluating words in isolation.
To better understand the structure of SST datasets, you can Stanford CoreNLP emotion analysis page Download the dataset file.
In Java code, the Stanford CoreNLP emotion classifier uses the following.
First, you build a text processing pipeline by adding annotators needed to perform emotion analysis, such as tokenization, splitting, parsing, and emotion. In the case of Stanford CoreNLP, the annotator is an interface to operate on annotation objects, where the latter represents a piece of text in a document. For example, you need to use the ssplit annotator to split a sequence of tags into sentences.
Stanford CoreNLP calculates emotions based on each sentence. Therefore, the process of dividing text into sentences always follows the application of emotional annotator.
Once the text is divided into sentences, the parsing annotator will perform syntactic dependency parsing and generate a dependency representation for each sentence. Then, the emotion annotator processes these dependency representations and compares them with the underlying model to build a binary tree with emotion tags (annotations) of each sentence.
Simply put, the nodes of the tree are determined by the markers of the input sentence and contain comments indicating the prediction categories of all phrases derived from the sentence from the five emotion categories from very negative to very positive. Based on these predictions, the emotion annotator calculates the emotion of the whole sentence.
Set up Stanford CoreNLP
Before starting to use Stanford CoreNLP, you need to make the following settings:
To run Stanford CoreNLP, you need Java 1.8 or later.
Download the Stanford CoreNLP package and extract it to a local folder on your machine.
Download address: https://nlp.stanford.edu/software/stanford-corenlp-latest.zip
This article takes decompressing the above code to the following directory as an example:
c:/softwareInstall/corenlp/stanford-corenlp-4.3.2
After completing the above steps, you can create a Java program that runs the Stanford CoreNLP pipeline to process text.
First, create a maven project and manually add stanford-core nlp-4.3 2 add to Libraries:
In the following example, you will implement a simple Java program that runs the Stanford CoreNLP pipeline to emotionally analyze text containing multiple sentences.
First, implement an nlppipline class, which provides methods to initialize the pipeline and use this pipeline to split the submitted text into sentences, and then classify the emotion of each sentence. The following is the nlppipline class code:
package com.zh.ch.corenlp;
import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.util.CoreMap;
import java.util.Properties;
public class NlpPipeline {
StanfordCoreNLP pipeline = null;
public void init()
{
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, parse, sentiment");
pipeline = new StanfordCoreNLP(props);
}
public void estimatingSentiment(String text)
{
int sentimentInt;
String sentimentName;
Annotation annotation = pipeline.process(text);
for(CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class))
{
Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
System.out.println(sentimentName + "\t" + sentimentInt + "\t" + sentence);
}
}
}
The init() method initializes the Stanford corenlp pipeline, which also initializes the word splitter, dependency parser, and sentence splitter required to use the emotion tool. To initialize the pipeline, pass the Properties object with the corresponding annotator list to the Stanford corenlp() constructor. This will create a custom pipeline ready to perform emotion analysis on the text.
In the estimatingSentiment() method of the NlpPipeline class, we call the process() method of the pipe object created before, and process the incoming text. The process() method returns a comment object that stores the analysis of the submitted text.
Next, the annotation object is iterated, and a sentence level CoreMap object is obtained in each iteration. For each of these objects, a Tree object containing emotion annotations used to determine the emotion of the underlying sentence is obtained.
Pass the Tree object to the getPredictedClass() method of rnncorenannotations class to extract the number code of the predicted emotion of the corresponding sentence. Then, get the name of the predicted emotion and print the result.
To test the above functions, use the main() method that calls the init() method to implement a class, then call the estimatingSentiment() method of the nlpPipeline class to pass the example text to the latter.
In the following implementation, text is specified directly for simplicity. The sample sentences are intended to cover the entire emotional rating range available to Stanford CoreNLP: very positive, positive, neutral, negative and very negative.
package com.zh.ch.corenlp;
import java.io.FileReader;
import java.io.IOException;
public class Main {
static NlpPipeline nlpPipeline = null;
public static void processText(String text) {
nlpPipeline.estimatingSentiment(text);
}
public static void main(String[] args) {
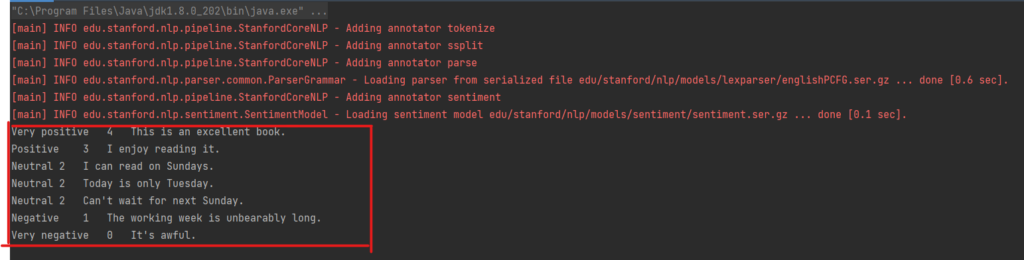
String text = "This is an excellent book. I enjoy reading it. I can read on Sundays. Today is only Tuesday. Can't wait for next Sunday. The working week is unbearably long. It's awful.";
nlpPipeline = new NlpPipeline();
nlpPipeline.init();
processText(text);
}
}
Execution results:
Analyze online customer reviews
As you learned from the previous example, Stanford CoreNLP can return the emotion of a sentence. However, there are many use cases that need to analyze the emotions of multiple texts, and each text may contain more than one sentence. For example, you may want to analyze the emotions of tweets or customer comments from e-commerce websites.
To calculate the emotions of multiple sentence text samples using Stanford CoreNLP, you may use several different techniques.
When processing tweets, you may analyze the emotions of each sentence in the tweet. If there are some positive or negative sentences, you can rank the whole tweet separately and ignore the sentences with neutral emotions. If all (or almost all) sentences in a tweet are neutral, the tweet can be listed as neutral.
However, sometimes you don't even have to analyze each sentence to estimate the emotion of the whole text. For example, when analyzing customer comments, you can rely on their title, which usually consists of a sentence.
To complete the following example, you need a set of customer comments. You can use the NlpBookReviews.csv Comments in the document. This file contains a set of actual comments downloaded from Amazon's web page with the help of Amazon Review Export, a Google Chrome browser extension that allows you to download product comments and their titles and ratings into a comma separated value (CSV) file (you can use this tool to explore a different set of comments for analysis.)
Add the following code to NlpPipeline
public String findSentiment(String text) {
int sentimentInt = 2;
String sentimentName = "NULL";
if (text != null && text.length() > 0) {
Annotation annotation = pipeline.process(text);
CoreMap sentence = annotation
.get(CoreAnnotations.SentencesAnnotation.class).get(0);
Tree tree = sentence
.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
}
return sentimentName;
}
You may notice that the above code is similar to the code in the estimatingSentiment() method defined in the previous section. The only significant difference is that you did not iterate the sentences in the input text this time. Instead, you will only get the first sentence, because in most cases, the title of the comment consists of one sentence.
The following code will read the comments from the CSV file and pass them to the newly created findSentiment() for processing, as follows:
public static void processCsvComment(String csvCommentFilePath) {
try (CSVReader reader = new CSVReaderBuilder(new FileReader(csvCommentFilePath)).withSkipLines(1).build())
{
String[] row;
while ((row = reader.readNext()) != null) {
System.out.println("Review: " + row[1] + "\t" + " Amazon rating: " + row[4] + "\t" + " Sentiment: " + nlpPipeline.findSentiment(row[1]));
}
}
catch (IOException | CsvValidationException e) {
e.printStackTrace();
}
}
Execution results:

Full code:
NlpPipeline.java
package com.zh.ch.corenlp;
import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.neural.rnn.RNNCoreAnnotations;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.util.CoreMap;
import java.util.Properties;
public class NlpPipeline {
StanfordCoreNLP pipeline = null;
public void init() {
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, parse, sentiment");
pipeline = new StanfordCoreNLP(props);
}
public void estimatingSentiment(String text) {
int sentimentInt;
String sentimentName;
Annotation annotation = pipeline.process(text);
for(CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class))
{
Tree tree = sentence.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
System.out.println(sentimentName + "\t" + sentimentInt + "\t" + sentence);
}
}
public String findSentiment(String text) {
int sentimentInt = 2;
String sentimentName = "NULL";
if (text != null && text.length() > 0) {
Annotation annotation = pipeline.process(text);
CoreMap sentence = annotation
.get(CoreAnnotations.SentencesAnnotation.class).get(0);
Tree tree = sentence
.get(SentimentCoreAnnotations.SentimentAnnotatedTree.class);
sentimentInt = RNNCoreAnnotations.getPredictedClass(tree);
sentimentName = sentence.get(SentimentCoreAnnotations.SentimentClass.class);
}
return sentimentName;
}
}
Main.java
package com.zh.ch.corenlp;
import com.opencsv.CSVReader;
import com.opencsv.CSVReaderBuilder;
import com.opencsv.exceptions.CsvValidationException;
import java.io.FileReader;
import java.io.IOException;
public class Main {
static NlpPipeline nlpPipeline = null;
public static void processCsvComment(String csvCommentFilePath) {
try (CSVReader reader = new CSVReaderBuilder(new FileReader(csvCommentFilePath)).withSkipLines(1).build())
{
String[] row;
while ((row = reader.readNext()) != null) {
System.out.println("Review: " + row[1] + "\t" + " Amazon rating: " + row[4] + "\t" + " Sentiment: " + nlpPipeline.findSentiment(row[1]));
}
}
catch (IOException | CsvValidationException e) {
e.printStackTrace();
}
}
public static void processText(String text) {
nlpPipeline.estimatingSentiment(text);
}
public static void main(String[] args) {
String text = "This is an excellent book. I enjoy reading it. I can read on Sundays. Today is only Tuesday. Can't wait for next Sunday. The working week is unbearably long. It's awful.";
nlpPipeline = new NlpPipeline();
nlpPipeline.init();
// processText(text);
processCsvComment("src/main/resources/NlpBookReviews.csv");
}
}
Code address:
corenlp-examples