Using go to realize mysql batch test data generation TDG
Component code: https://gitee.com/dn-jinmin/tdg
Download go get gitee com/dn-jinimin/tdg
At present, it is only for mysql and only supports batch addition of multiple single tables. The associated addition has not been completed
01. Let's go
The main reason for developing TDG is that many friends will face a problem when learning database index, SQL optimization and their own project development; There is no data to test;
For example, SQL optimization is the most obvious. In the current system, when the amount of data is more than 500w and 1000w, establish an index and try to optimize it. This effect is more intuitive than the analysis of several data only through explain. I have also encountered this problem

There are many ways to generate test data; For example, use the storage engine of the database, or write one by yourself with a program, so you accidentally write one, and then consolidate it;

Developed with go and compiled into executable file, which can be downloaded and used directly;
Warm tip: please pay attention to the code document configuration during use. If you are careless, you will;

__ Of course, I hope this tool can bring you good help. The following is an introduction to the implementation of the tool and its implementation ideas. Your personal ability is limited. If you have better opinions in use, you are welcome to give advice. I hope you can star Thanks ω・) ノ
02. Conception
mysql writes data
The normal way mysql writes data is to execute the following SQL commands to write data
insert into table_name (col1,col2)values(data1, data2)
If there is a copy of XXX SQL files can be passed
source xxx.sql
You can also use the in mysql
load data xxx xxx.txt
Several problems need to be solved on how to quickly generate test data in batch by mysql
- How to generate quickly?
- How to generate for a table
- Data needs to be generated for different field requirements
- You can customize the generation of different tables
This is a problem that must be considered and solved for mysql how to efficiently generate test data. My thinking process (because the length is too long, the word..... Is omitted here)
tdg implementation ideas
Firstly, the overall idea is based on sql and written by insert; The method of batch adding with insert statement; The following format
insert into table_name (col1,col2) values(data1, data2),(data1,data2)
tdg's SQL generation is divided into three parts
1. SQL start and table_name
insert into table_name
2. Field column
(col1, col2)
3. Write data
values(data1, data2),(data1, data2)
tdg is to build a batch new insert statement for the generation and splicing of SQL, and write the generated data into mysql;
03. Concrete realization
The overall implementation can be divided into four nodes: initial knowledge, data generation rules, SQL generation and SQL writing
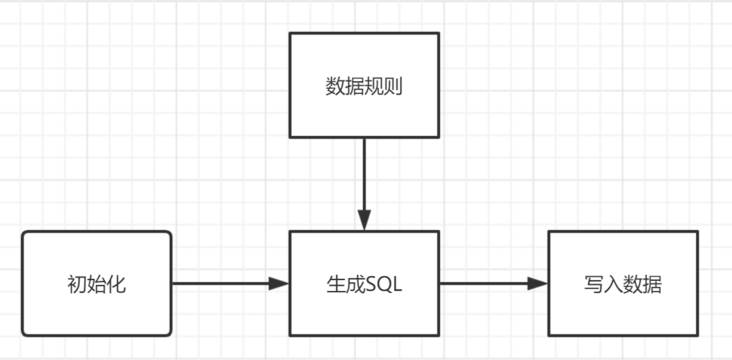
Data generation rules
Here, let's first understand how the rules are implemented, because in mysql, we will have corresponding requirements for fields because of the characteristics of data. For example, id can be int or string, order will have its own requirements, and there will be many types of data requirements for phone, date, name, etc;
Therefore, the design of rules is mainly based on the type corresponding to the application of columns. The design will include the following rules
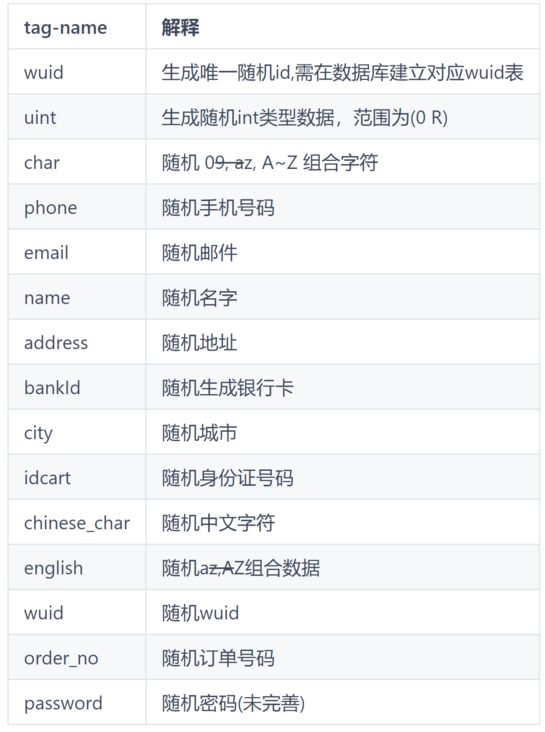
These rules will be loaded during initialization; The overall design is to define a unified rule interface in build / file Go in
type Column struct {
// Field label to determine the field generation method
Tag string `json:"tag"`
// Field fixed length
Len int `json:"len"`
// Length range
FixedLen interface{} `json:"fixed_len"`
// Field maximum
Max int `json:"max"`
// Field minimum
Min int `json:"min"`
// Other parameters
Params interface{} `json:"params"`
// Default value
Default struct {
Value interface{} `json:"value"`
Frequency int `json:"frequency"`
} `json:"default"`
// Specify random content
Content []interface{} `json:"content"`
}
type Tag interface {
Name() string
Handler(column *Column) string
Desc() string
}Name() represents the label name of the rule, the specific random method of the handler, and the description of the Desc printout; Considering the richness of rules, a unified column structure is defined as the parameters of the handler, and different rules can randomly generate the desired results according to the parameter settings in the column; The following is an example,
type Char struct{}
func (*Char) Name() string {
return "char"
}
func (*Char) Handler(column *Column) string {
var ret strings.Builder
chLen := column.Len
// Fixed length, fixed length priority is greater than variable length
if column.FixedLen != nil {
chLen = column.PrepareFixedLen()
}
ret.Grow(chLen)
// Variable length
for i := 0; i < chLen; i++ {
ret.WriteByte(chars[RUint(62)])
}
return ret.String()
}
func (*Char) Desc() string {
return "Random character 0~9, a~z, A~Z"
}
All rules are defined in build / tag In go; The final rule is loaded into build / field Go in
type Field map[string]Tag
func NewField(cap int) Field {
return make(map[string]Tag, cap)
}
func (field Field) Register(tag string, option Tag)
func (field Field) TagRandField(column *Column, sql *strings.Builder)initialization:
There is a Table structure in tdg, which represents a Table
type Table struct {
TableName string `json:"table_name"`
Columns map[string]*Column `json:"columns"`
Debug bool `json:"debug"`
Count int `json:"count"`
Status int `json:"status"`
columns []string
sqlPrefix *[]byte
}Load table JSON configuration, in which MySQL connection, table name, field of table and overall tdg data generation strategy will be defined
{
"tdg": {
"data_one_init_max_memory": 104857600,
"build_sql_worker_num": 5,
"insert_sql_worker_num": 10,
"build_batches_count": 2000,
// ..
},
"mysql": {
"addr": "",
"user" : "",
"pass" : "",
"charset" : "",
"dbname": "",
"table_prefix": ""
},
"tables": {
"member": {
"status": 0,
"table_name": "member",
"count": 10,
"columns": {
"username": {
"tag": "name",
"fixed_len": "6|14"
},
//..
}
},
"member_info": {
"table_name": "member_info",
"count": 1,
"status": 0,
"columns": {
//..
}
}
}
}At the same time, some custom rules will be loaded, and the loaded data information will be stored in build and driven by build
type Build struct {
oneInitMaxMemory int
insertSqlWorkerNum int
buildSqlWorkerNum int
buildBatchesCount int
mysqlDsn string
cfg *Config
tables map[string]*Table
field Field
db *gorm.DB
wg sync.WaitGroup
}When you first know it, you will insert the prefix into table for all tables to be added_ Name (col1, col2) values
sql generation and writing
For these two processes, the concurrent worker mode is adopted in the implementation, and multiple GetSql and insert processes are constructed to coordinate and complete the tasks together
In run
func (b *Build) Run() {
b.buildSqlWorkerPool(sqlCh, buildTaskCh)
b.insertSqlWorkerPool(sqlCh, ctx)
for _, table := range b.tables {
go func(table *Table, ctx *Context) {
// Whether the data table is written
if table.Status == -1 {
return
}
task := &buildTask{
table: table,
quantity: b.buildBatchesCount,
sqlPrefix: table.prepareColumn(),
}
degree, feel := deg(table.Count, b.buildBatchesCount)
ctx.addDegree(degree) // Statistical times
for i := 0; i < degree; i++ {
// Last processing
if feel > 0 && i == degree -1 {
task.quantity = feel
}
buildTaskCh <- task
}
}(table, ctx)
}
}In the process design, each table will be generated by task, and how many SQL will be generated and written at a time; The task is calculated through deg, and the task information is buildTask. The task is sent through the channel buildTask ch
At the same time, the number of workers corresponding to insertSql and getSql will be created in run
In getSql, different rules will be called according to the tag to generate random values and splice SQL
func (b *Build) getSql(quantity int, sqlPrefix *[]byte,table *Table, sqlCh chan *strings.Builder) {
// ..
for i := 0; i < quantity; i++ {
table.randColums(sql, b.field)
if i == quantity-1 {
break
}
sql.WriteByte(',')
}
sqlCh <- sql
}After generating SQL, send the result to sqlch channel; insertSql reads and writes with gorm
func (b *Build) insert(sql *strings.Builder, ctx *Context) {
if !b.cfg.NoWrite {
if err := b.db.Exec(sql.String()).Error; err != nil {
if b.cfg.Debug {
ctx.errs = append(ctx.errs, err)
}
if !b.cfg.TDG.SkipErr {
ctx.Cancel()
return
}
}
}
ctx.complete++
if ctx.complete == ctx.degree {
ctx.Cancel()
}
}The basic implementation is as above