HDF
Hierarchical Data Format, also known as HDF5
-
In deep learning, a large amount of data or pictures are usually used to train the network. For such a large data set, if each picture is read separately from the hard disk, preprocessed, and then sent to the network for training, verification or testing, it is too inefficient. If these pictures are put into a file and processed, the efficiency will be higher. There are a variety of data models and libraries to do this, such as HDF5 and TFRecord.
-
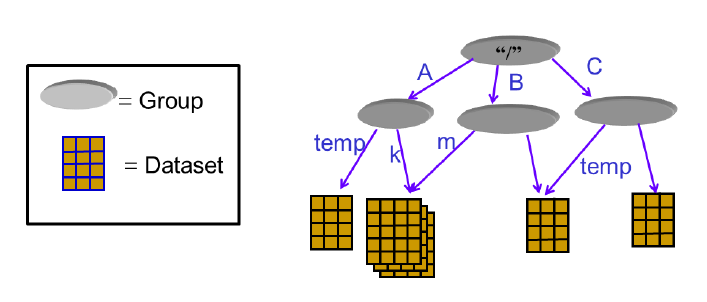
An HDF5 file is a container for storing two types of objects: dataset and group. Dataset is an array like dataset, while group is a folder like container for storing dataset and other groups. When using h5py, you should keep in mind that groups is an analogy dictionary and dataset is an analogy to arrays in Numpy.
-
-
hdf5 files generally take. h5 or. hdf5 as the suffix. Special software is required to open the contents of the preview file. There are two primary objects in the hdf5 file structure: groups and Datasets.
-
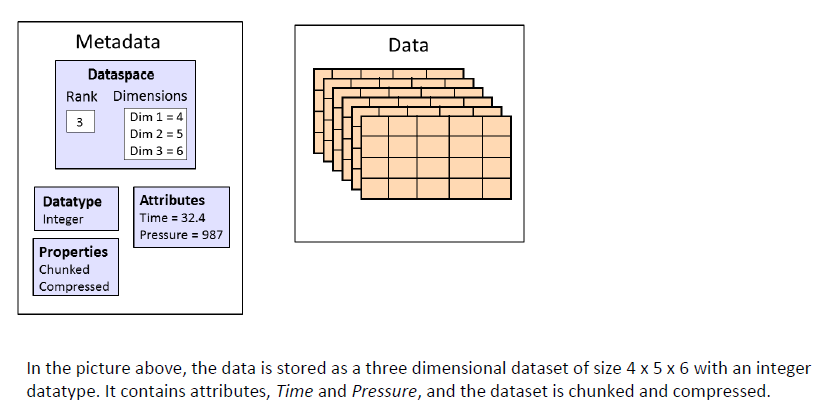
Each dataset can be divided into two parts: raw data values and metadata (a set of data that describes and gives information about other data = > raw data). For each dataset, in addition to the data itself, the dataset also has many attributes,. In hdf5, it also supports the storage of attribute information corresponding to data sets. The collection of all attribute information is called metadata
-
Installation:
pip install h5py
For dataset, you need to create h5 file first, then read h5 file, put dataset in group, and use group to nest hierarchically
1 f = filename.file Get the root directory of the file 2 f.create_group("...../group_name") 3 f.create_dataset("...../dataset_name")
General:
-
The HDF5 format file stores: model weights (Dictionary, no order)
-
json and YAML format files save: model structure (the order is described by json)
-
h5 format: you can save weights and structure s at the same time
Initialization using numpy data
1 #You can also use it directly np Array to dataset initialization,here data It covers shape and dtype,Namely shape = data.shape,.... 2 arr = np.arange(100) 3 dset = f.create_dataset("/mydataset1",data = arr)#i4:32 Bit integer[-2^31,2^31]
Use in data processing
Using python's file operation and array, label the training data and test data set, write the file name into python array according to the data division method, and finally write these processed arrays into hdf5 format file for dataset initialization
Example
1 import h5py 2 import numpy as np 3 coco = h5py.File("D:/annot_coco.h5","r")#coco.name == / Root node 4 # print(coco) 5 # print(coco["bndbox"]) 6 #Just traverse the directly connected primary nodes 7 for name in coco: 8 # Itself is a string 9 print(coco[name]) 10 print(coco[name][:2]) 11 12 # def printname(name): 13 # print(name) 14 # 15 # 16 # 17 # #Traverse the nodes under the whole coco 18 # coco.visit(printname) 19 #dataset.attrs 20 #dataset Objects can have their own properties, However, the total length of all attribute data cannot exceed 64 K, Include attribute name. 21 22 dset.attrs['length'] = 100 23 dset.attrs['name'] = 'This is a dataset' 24 for attr in dset.attrs: 25 print attr, ":", dset.attrs[attr] 26 length : 100 27 name : This is a dataset
be careful:
1 imgname_array = coco["imgname"][:]#inequable,This is standard usage,Or do you have to get it all first,Then go to the index,Otherwise, the result dimensions are different 2 # imgname_ = coco["imgname"][:1]#The axis does not decrease 3 # print(imgname_array.shape) 4 # print(imgname_)#[1,16] 5 # print(type(imgname_dataset)) 6 # print(type(imgname_array)) 7 img = imgname_array[0]
Write string to h5 file
1 test_h5 = h5py.File("D:/test.h5","w") 2 imgname = np.fromstring('000000262145.jpg',dtype=np.uint8).astype('float64')#str_imgname------>float64 3 test_h5 .create_dataset('imgname', data=imgname)#become f8 Then you can go directly to h5 It's written in 4 test_h5.close() 5 """ 6 The final matrix length is the length of the string.---1 The length of a string is the corresponding encoding h5 Length of vector 7 If you want to spell multiple strings into a large one numpy Matrix, write h5 In the file, you must first convert the string to the same length. 8 The usual practice is to fill in the string\x00. 9 """
Read string format from h5 data
1 test_h5 = h5py.File("D:/test.h5","r") 2 img = test_h5['imgname'][:] 3 img = img.astype(np.uint8).tostring().decode('ascii') 4 print(img) 5 test_h5.close()