In the first section, we briefly introduce the basic principle of crawler. Understanding the principle can help us better realize the code. Python provides many tools to implement HTTP requests, but the third-party open source library provides richer functions. You don't need to start writing from socket communication. For example, use Python's built-in module urlib to request a URL code. An example is as follows:
import ssl
from urllib.request import Request
from urllib.request import urlopen
context = ssl._create_unverified_context()
# HTTP request
request = Request(url="https://foofish.net/pip.html",
method="GET",
headers={"Host": "foofish.net"},
data=None)
# HTTP response
response = urlopen(request, context=context)
headers = response.info() # Response header
content = response.read() # Responder
code = response.getcode() # Status code
Before initiating a Request, first build the Request object Request and specify the url address, Request method and Request header. The Request body data here is empty. Because you do not need to submit data to the server, you can also not specify it. The urlopen function will automatically establish a connection with the target server and send an HTTP Request. The return value of the function is a Response object Response, which contains attributes such as Response header information, Response body and status code.
However, the built-in module provided by Python is too low-level and needs to write a lot of code. You can consider requests when using a simple crawler. Requests has nearly 30k Star in GitHub, which is a very Python framework. Let's get familiar with how this framework is used
Install requests
pip install requests
GET request
>>> r = requests.get("https://httpbin.org/ip")
>>> r
<Response [200]> # Response object
>>> r.status_code # Response status code
200
>>> r.content # Response content
'{\n "origin": "183.237.232.123"\n}\n'
POST request
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})
Custom request header
This is often used. The server anti crawler mechanism will judge whether the user agent in the client request header comes from a real browser. Therefore, when we use Requests, we often specify the UA to disguise as a browser to initiate Requests
>>> url = 'https://httpbin.org/headers'
>>> headers = {'user-agent': 'Mozilla/5.0'}
>>> r = requests.get(url, headers=headers)
Parameter transfer
Many times, there will be a long string of parameters behind the URL. In order to improve readability, requests supports extracting the parameters and passing them as method parameters (params) without attaching them to the URL, such as the request url http://bin.org/get?key=val , available
>>> url = "http://httpbin.org/get"
>>> r = requests.get(url, params={"key":"val"})
>>> r.url
u'http://httpbin.org/get?key=val'
Specify Cookie
Cookies are the credentials for web browsers to log in to the website. Although cookies are also part of the request header, we can separate them and specify them with Cookie parameters
>>> s = requests.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
>>> s.text
u'{\n "cookies": {\n "from-my": "browser"\n }\n}\n'
Set timeout
When a request is initiated and the response of the server is very slow and you don't want to wait too long, you can specify timeout to set the request timeout in seconds. When the connection to the server fails after this time, the request will be forcibly terminated.
r = requests.get('https://google.com', timeout=5)
Set agent
Too many requests sent over a period of time are easy to be judged as crawlers by the server, so we often use proxy IP to disguise the real IP of the client.
import requests
proxies = {
'http': 'http://127.0.0.1:1080',
'https': 'http://127.0.0.1:1080',
}
r = requests.get('http://www.kuaidaili.com/free/', proxies=proxies, timeout=2)
Session
If you want to maintain the login (Session) state with the server without specifying cookies every time, you can use Session. The API provided by Session is the same as requests.
import requests
s = requests.Session()
s.cookies = requests.utils.cookiejar_from_dict({"a": "c"})
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {"a": "c"}}'
Small trial ox knife
Now let's use Requests to complete a simple crawler to crawl the user's attention list of Zhihu column. For example, find any column and open its Follow list . Use Chrome to find the request address to get the fan list: https://zhuanlan.zhihu.com/api/columns/pythoneer/followers?limit=20&offset=20
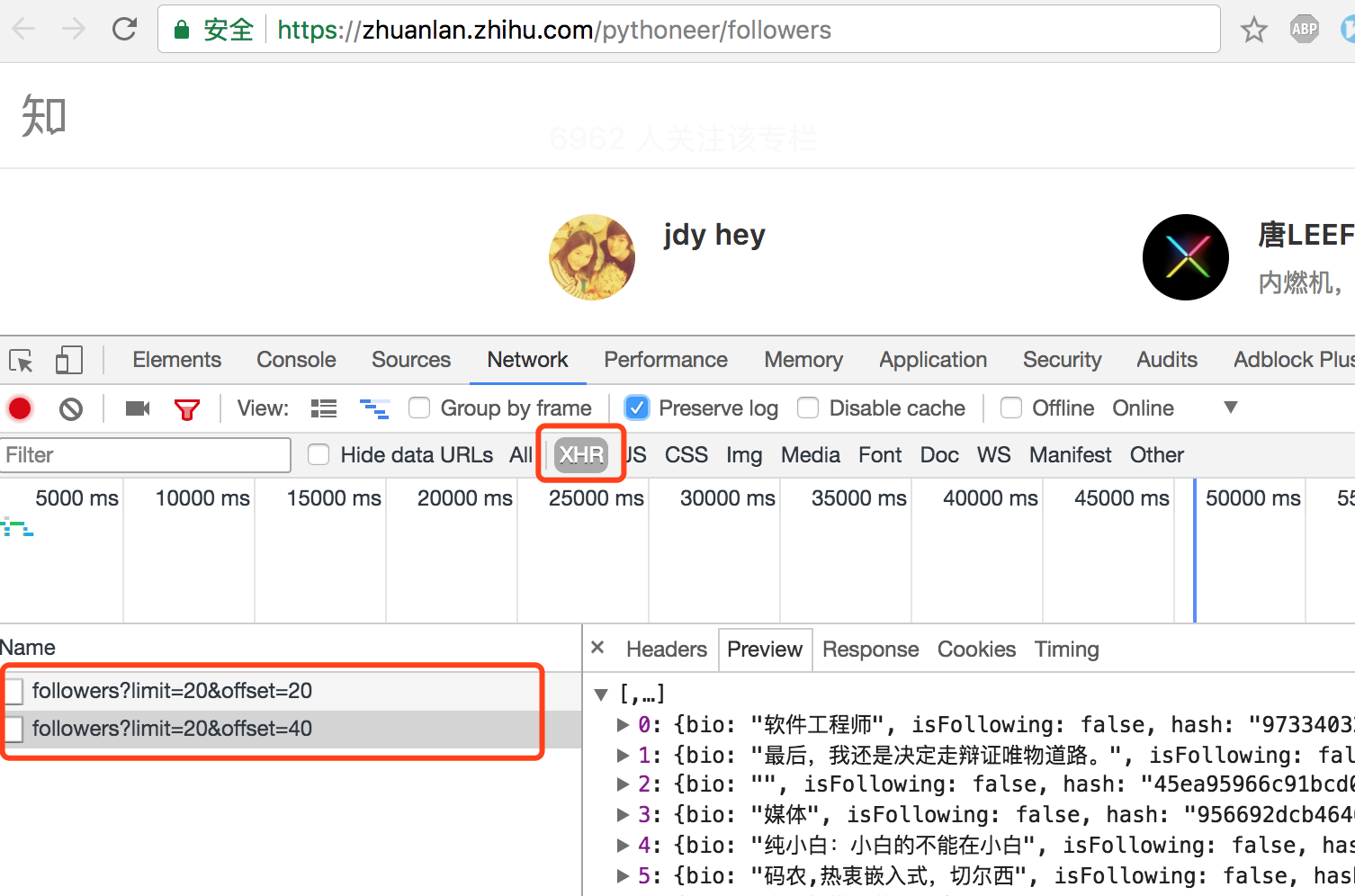
Then we use Requests to simulate the browser to send Requests to the server
import json
import requests
class SimpleCrawler:
init_url = "https://zhuanlan.zhihu.com/api/columns/pythoneer/followers"
offset = 0
def crawl(self, params=None):
# UA must be specified, otherwise the server will determine that the request is illegal
headers = {
"Host": "zhuanlan.zhihu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
response = requests.get(self.init_url, headers=headers, params=params)
print(response.url)
data = response.json()
# 7000 indicates all concerns
# More paging loads, recursive calls
while self.offset < 7000:
self.parse(data)
self.offset += 20
params = {"limit": 20, "offset": self.offset}
self.crawl(params)
def parse(self, data):
# Store to file in json format
with open("followers.json", "a", encoding="utf-8") as f:
for item in data:
f.write(json.dumps(item))
f.write('\n')
if __name__ == '__main__':
SimpleCrawler().crawl()
Summary
This is the simplest single thread crawler based on requests to know the column fan list. Requests are very flexible. The request header, request parameters and Cookie information can be directly specified in the request method. If the return value response is in json format, you can directly call json() method to return python object. For more usage of requests, please refer to the official documents: http://docs.python-requests.org/en/master/
[like] [follow] don't get lost