Introduction: Web crawlers allow us to get information from web pages efficiently, but the repetition rate of web pages is high. Web pages need to be sorted by content. There are many ways to judge the content of a document is repeated. Semantic fingerprint is one of the more efficient methods.
This paper is selected from "Full Analysis of Web Crawlers - Technology, Principles and Practice".
In modern society, effective information is just as essential to people as oxygen.The Internet makes it easier to collect effective information.When you surf the Internet, crawlers also travel through the network to automatically collect useful information from the Internet.
Web crawlers that automatically collect and filter information enhance the mobility of valid information and allow us to get it more efficiently.As more and more information appears on the web, web crawlers become more and more useful.
It is common for content to be reloaded between different websites.Even on the same website, sometimes different URL addresses may correspond to the same page, or the same content may appear in many ways, so the pages need to be sorted by content.
For example, an enterprise commodity search.Search for commodity names, there is a company issued the same name of the goods, the results of this company issued goods are shown in front, but require a company to show only one similar goods in front, you can reduce the weight of similar duplicate documents, only keep one document without lowering the weight.
There are many ways to determine the content of a document is duplicated. Semantic fingerprinting is more efficient.Semantic fingerprints are the semantics of extracting the binary array representation of a document directly to determine whether a Web page is duplicated by comparing equality.Semantic fingerprints are a very large array, all stored in memory can lead to memory overflow, ordinary databases are too inefficient, so the in-memory database Berkeley DB is used.You can use Berkeley DB to determine if this semantic fingerprint already exists.Another method is to use a Bloom filter to determine if a semantic fingerprint is duplicated.
The method to extract the semantic fingerprint of a web page is to select the most representative set of keywords from the purified web page and use the keyword phrase to generate a semantic fingerprint.Determine whether two pages are similar by comparing their semantic fingerprints.
At one time, there were many news reports about "Luo Yufen's marriage", two of which were compared in the table below.
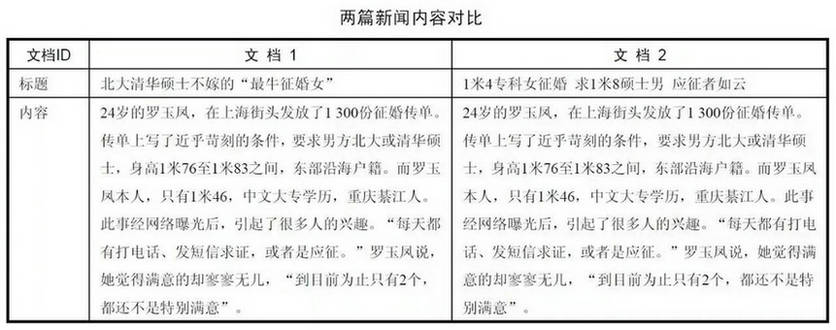
For two news articles with the same content, it is possible to extract the same keywords: "Luo Yufen", "Marriage", "Beida", "Tsinghua", "Master", which means that the semantic fingerprints of the two documents are the same.
In order to improve the accuracy of the semantic fingerprint, synonyms need to be taken into account, for example, "Beijing Hualian" and "Hualian Store" can be regarded as words with the same meaning.The easiest way to judge is to replace synonyms.Replace the phrase "At the beginning of business, more questions surround the decision makers of Hualian in Beijing" with the phrase "At the beginning of business, more questions surround the decision makers of Hualian Store".
The format for designing a synonym dictionary is: one synonym per line, preceded by a base word, followed by one or more replaced synonyms. See the example below.
Hualian Store Beijing Hualian Hualian Supermarket
This can replace "Beijing Hualian" or "Hualian Supermarket" with "Hualian Store".For the specified text, each word in the thesaurus to be replaced is searched from the back and replaced.The implementation code for synonym replacement is divided into two steps.The first step is to find the dictionary of the Trie tree structure.
public void checkPrefix(String sentence,int offset,PrefixRet ret) { if (sentence == null || root == null || "".equals(sentence)) { ret.value = Prefix.MisMatch; ret.data = null; ret.next = offset; return ; } ret.value = Prefix.MisMatch;//The initial return value is set to not match any of the words to be replaced TSTNode currentNode = root; int charIndex = offset; while (true) { if (currentNode == null) { return; } int charComp = sentence.charAt(charIndex) - currentNode.splitchar; if (charComp == 0) { charIndex++; if(currentNode.data != null){ ret.data = currentNode.data;//Candidate Longest Match Word ret.value = Prefix.Match; ret.next = charIndex; } if (charIndex == sentence.length()) { return; //Matched } currentNode = currentNode.eqKID; } else if (charComp < 0) { currentNode = currentNode.loKID; } else { currentNode = currentNode.hiKID; } } }
Followed by the synonym replacement process.
//Enter the text to be replaced and return the replaced text public static String replace(String content) throws Exception{ int len = content.length(); StringBuilder ret = new StringBuilder(len); SynonymDic.PrefixRet matchRet = new SynonymDic.PrefixRet(null,null); for(int i=0;i<len;){ //Check for synonyms starting at the current location synonymDic.checkPrefix(content,i,matchRet); if(matchRet.value == SynonymDic.Prefix.Match) //Replace synonyms if matched { ret.append(matchRet.data);//Output substitutions to results i=matchRet.next;//Next Match Location } else //If there is no match, match from the next character { ret.append(content.charAt(i)); ++i; } } return ret.toString(); }
The semantic fingerprint generation algorithm is shown below.
Step 1: Represent each web page word breaker as a word-based feature, using TF*IDF as the weight of each feature.Place names, proper nouns, etc. Nominal words tend to have higher semantic weights.
Step 2: Sort the feature items by word weight.
Step 3: Select the first n feature items and reorder them by character.If you do not sort, the keywords will not find a corresponding relationship.
Step 4: Call the MD5 algorithm to convert each feature string into a 128-bit string as a fingerprint for the page.
Call a method in fseg.result.FingerPrint.
String fingerPrint = getFingerPrint("","Yesterday, a 17-year-old boy in Yuanming North Road, the provincial capital, fell into a van downstairs while drying a towel on the 6th floor.The van absorbs enormous reacting force energy when it is impacted and deformed, thus "saving" the lives of the teenagers.At present, the injured are not in danger of life.According to a witness, the accident happened at 2:40 p.m. when the young man working in a hairdresser was standing on the balcony to dry a towel and accidentally fell down because the balcony was slippery on a rainy day.The reporter came to the hospital to rescue the wounded and learned that the young man was named Li Jiacheng, 17 years old, from Xifeng City.After Li Jiacheng was injured, his cousin rushed to the hospital to accompany him.According to the doctor, the injured mainly suffered from head injury, and the specific condition of the injury needs further examination."); String md5Value = showBytes(getMD5(fingerPrint)); System.out.println("FingerPrint:"+fingerPrint+" md5:"+md5Value);
MD5 can convert strings to hash values that are virtually conflict-free, but MD5 is slower, and MurmurHash or JenkinsHash can also generate hash values with fewer conflicts. The semantic fingerprint implemented by JenkinsHash, called Lookup3Signature, is provided in Lucene's enterprise search software Solr1.4.The code for calling MurmurHash to generate a 64-bit Hash value is shown below.
public static long stringHash64(String str, int initial) { byte[] bytes = str.getBytes(); return MurmurHash.hash64(bytes, initial); }
This article is selected from Full Resolution of Web Crawler - Technology, Principle and Practice , click this link to view the book on the blog viewpoint website.

To get more exciting articles in time, you can search for "Bowen Viewpoint" in your WeChat or scan the QR code below and pay attention to it.

In addition, this week, there is a popular activity - Questions and Answers from Ali experts in Shuang11!
Le Tin and Ren Chongzheng, the authors of Shuang11, passed Open source Q&A To answer the reader's questions about Dual 11 ~
More good questions, look forward to your question!