Foreword: Use requests to crawl the first and second level comments of bilibili comment area and save them in mysql database or csv file
Target data: Name, gender, user rating, user uid, personalized signature, comment time, content, compliment, reply, rpid
 https://www.bilibili.com/video/BV14h411n7ok
https://www.bilibili.com/video/BV14h411n7okCatalog
1. Data Acquisition #Level 1 Comments.
3. Data Acquisition #Secondary Comments
4. Data Cleaning#Secondary Comments
1. Case Analysis
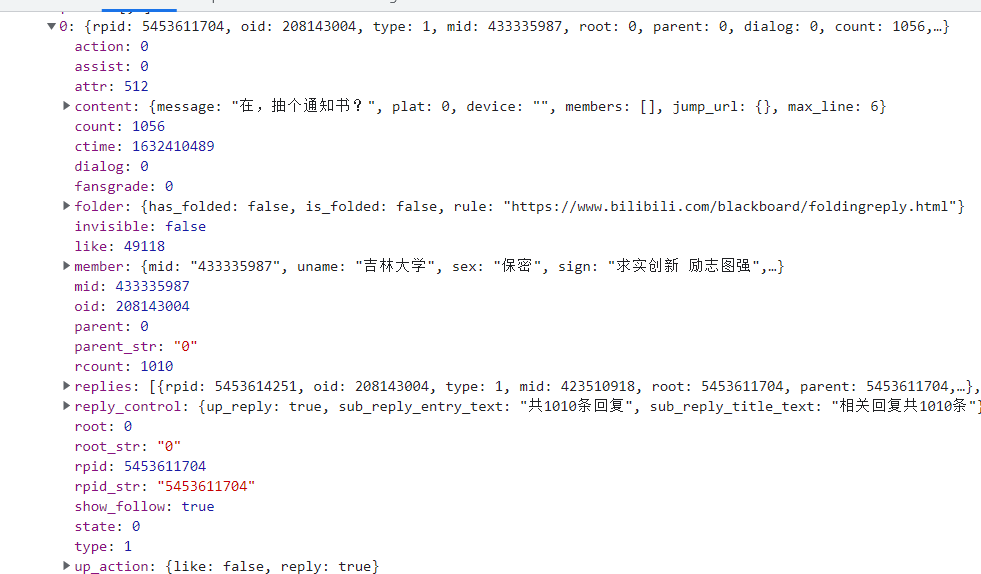
Get the commentary data api first and find that all the data is in a json format file and can be extracted using a dictionary.
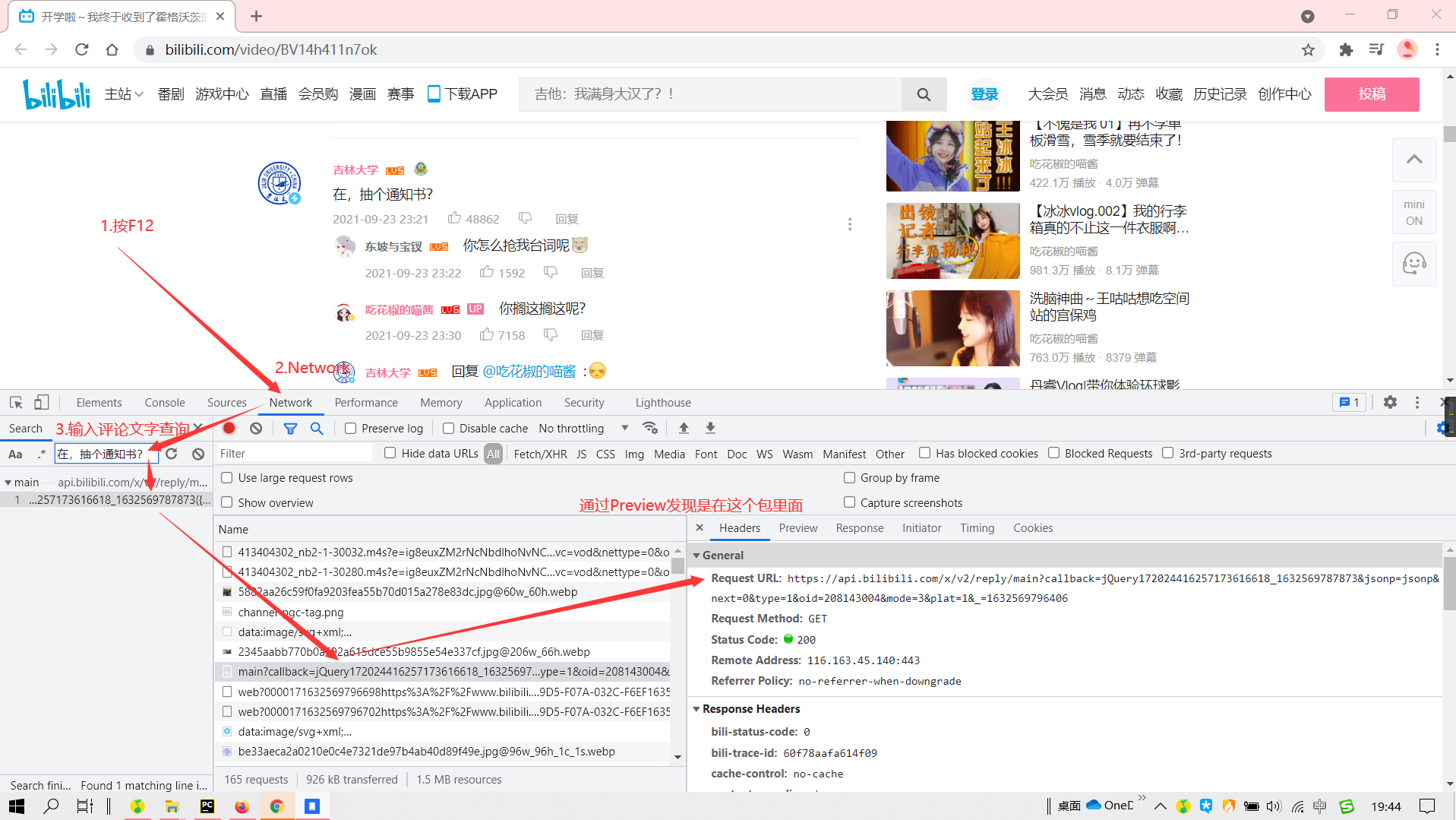
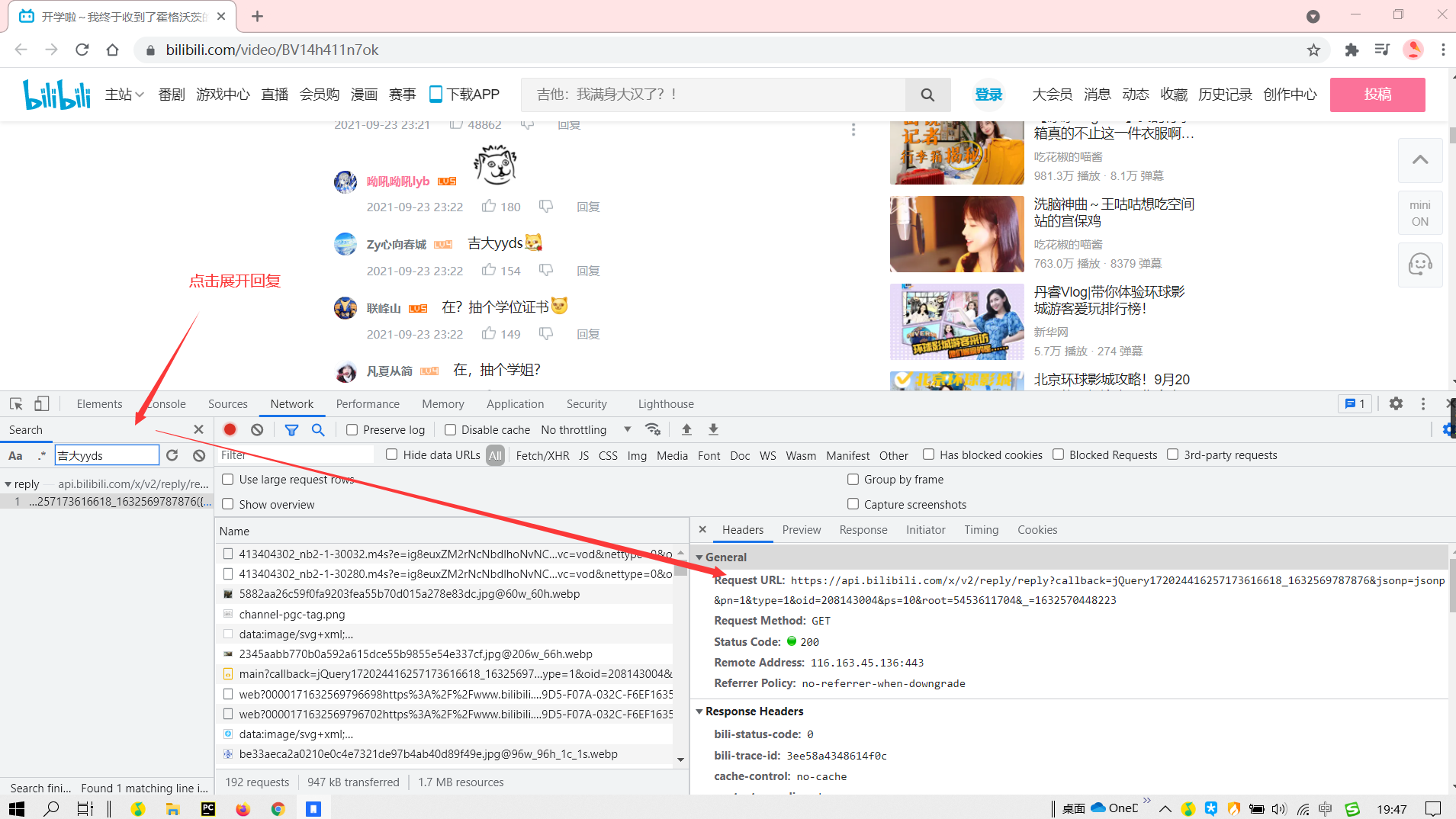
We can get the comment api from f12. Delete the first and last parameters to get
Level 1 Comments:https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=1&oid=208143004&mode=3&plat=1
- next: page flip
- oid: video number (aid)
- mode:1,2 means sorting by heat and time;0, 3 means sort by heat and display comments and user information
Level 2 Comments:https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn=1&type=1&oid=208143004&ps=10&root=5453611704
- * pn: Page flip
- Oid: video oid
- root: rpid of the owner's reply
- ps: Number of single page displays (up to 20)
Why delete the first and last parameters? Because we don't need a js request, the last parameter has no effect.
The remaining parameters are fixed and immutable
Video OIDs can be obtained from video BV numbers and rpid s from first-level Reviews
2. Getting data
1. Data Acquisition #Level 1 Comments.
Define the bilibili bili class. First get oid from the video BV number
import requests
import re
class Bilibili:
def __init__(self, BV):
self.homeUrl = "https://www.bilibili.com/video/BV14h411n7ok"
self.oid_get(BV)
# Get video oid
def oid_get(self, BV):
# Request Video Page
response = requests.get(url=self.homeUrl + BV).text
# Get oid from video bv number with regular expression
self.oid = re.findall("\"aid\":([0-9]*),", response)[0]The url of comment data is constructed using oids. The oid, mode, ps parameters can be preset, but the number of pages for page flips and secondary comments needs to be changed
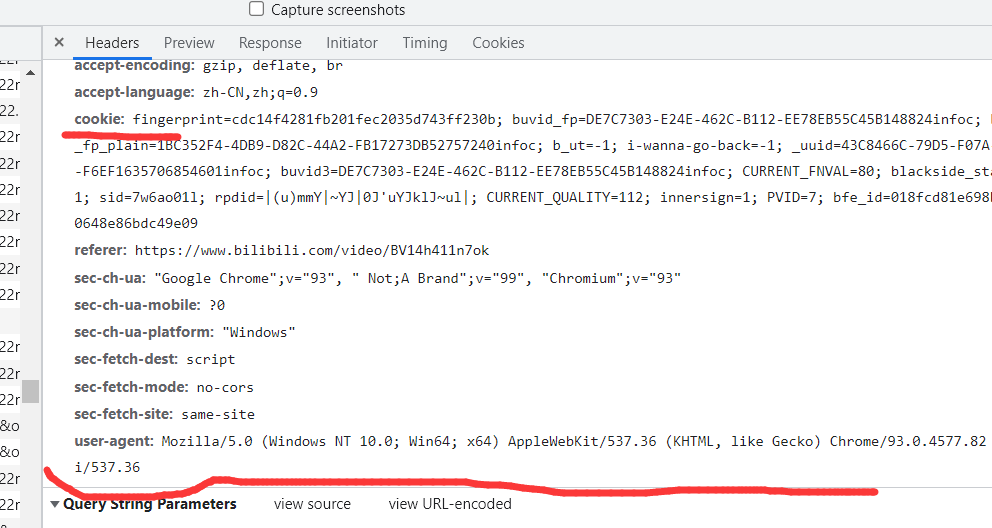
Request header user-agent and cookie need to be set in order to prevent being recognized as a crawler.
The user-agent can be constructed with the fake_user agent library, but there are many problems with this library.
* I simply copied the browser directly. You can do it if you want
https://fake-useragent.herokuapp.com/browsers/0.1.11
Look here. There are many User-Agents inside which you can make your own user agent pool. You need to go online scientifically to access it. You can also find them here. Copy both ua and cookie s (dictionary format)
What is Internet Science?

import requests
import re
import queue
import time
class Bilibili:
def __init__(self, BV, mode, cookies, page):
self.homeUrl = "https://www.bilibili.com/video/"
self.oid_get(BV)
self.replyUrl = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&type=1&oid={oid}&mode={mode}&plat=1&next=".format(oid=self.oid, mode=mode)
self.rreplyUrl = "https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&type=1&oid={oid}&ps=20&root={root}&pn=".format(oid=self.oid, root="{root}")
self.headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"}
self.cookies = cookies
self.q = queue.Queue() # Used to store crawled data, which can be sequentially stored in a database or csv file using multiple threads through a queue
# Here we use queues, the advantage is that they can be crawled and saved with multiple threads, and in order FIFO
self.count = 1 # The count variable specifies the number of main buildings, differing between comments and comments
# Get video oid
def oid_get(self, BV):
response = requests.get(url=self.homeUrl + BV).text
# Regular expression gets oid from video bv number
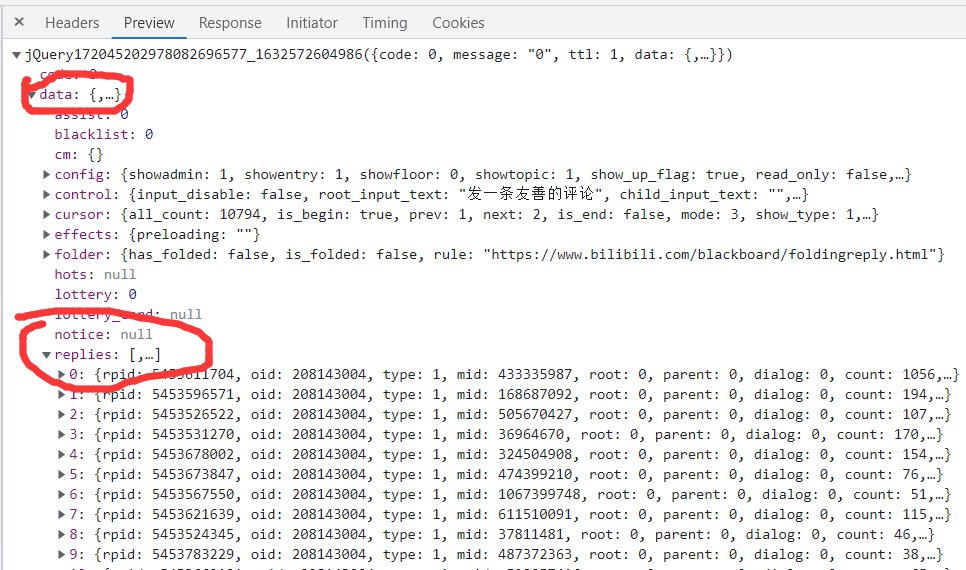
self.oid = re.findall("\"aid\":([0-9]*),", response)[0]Request function needs to pass url, page (maximum number of pages)
Requesting data through the requests library requires data in data->replies
def content_get(self, url, page):
now = 0 # Current Page
while now<=page:
print("page : <{now}>/<{page}>".format(now=now, page=page))
response = requests.get(url=url+str(now), cookies=self.cookies, headers=self.headers, timeout=10).json() # Parse response into json format and get it from a dictionary
replies = response['data']['replies'] # Comments are in data->replies, with 20 entries per page
now += 1
for reply in replies: # Traverse to get each item and use the reply_clean function to extract the data
line = self.reply_clean(reply)
self.count += 1We predefine a reply_clean function to extract data
2. Data cleaning
There is a lot of data in reply, but most of it is useless to us.
def reply_clean(self, reply):
name = reply['member']['uname'] # Name
sex = reply['member']['sex'] # Gender
if sex=="secrecy":
sex = ' '
mid = reply['member']['mid'] # uid of account number
sign = reply['member']['sign'] # Label
rpid = reply['rpid'] # Use for second-level Reviews
rcount = reply['rcount'] # Number of replies
level = reply['member']['level_info']['current_level'] # Grade
like = reply['like'] # Point Ratio
content = reply['content']['message'].replace("\n","") # Comments
t = reply['ctime']
timeArray = time.localtime(t)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) # Comment time, timestamp to standard time format
return [count, name, sex, level, mid, sign, otherStyleTime, content, like, rcount, rpid]Comments are timestamps, which are converted to a human-looking time format using the time library.
At this point, we've got first-level reviews and returned the data as a list type
3. Data Acquisition #Secondary Comments
To increase code reuse, we can change the two functions above
# level_1 determines whether a first-level comment is available or not. If a second-level comment is available, the next-level comment is not requested (comment of comment)
def content_get(self, url, page, level_1=True):
now = 0
while now<=page:
print("page : <{now}>/<{page}>".format(now=now, page=page))
response = requests.get(url=url+str(now), cookies=self.cookies, headers=self.headers, timeout=10).json()
replies = response['data']['replies'] # There are 20 reviews in data->replies
now += 1
for reply in replies:
if level_1:
line = self.reply_clean(reply, self.count)
self.count += 1
else:
line = self.reply_clean(reply)
self.q.put(line)
# Here we can filter that if there is comment on the first level comment, call the function to request the second level comment
if level_1==True and line[-2] != 0:
# Root denotes rpid. It is the root parameter in the secondary comment api. page number, since we set the maximum display to 20, is divided by 20. Round up by 0.5
self.content_get(url=self.rreplyUrl.format(root=str(line[-1])), page=int(line[-2]/20+0.5), level_1=False) # Recursively get secondary comments
By passing the url parameter to content_get, we can request either a first-level or a second-level comment. The json format of the two comments is exactly the same. Both are in data->replies. The self.count parameter indicates the number of main buildings.
4. Data Cleaning#Secondary Comments
# This function can crawl either a level 1 comment or a level 2 comment
# count parameter to see if it's a secondary comment.
def reply_clean(self, reply, count=False):
name = reply['member']['uname'] # Name
sex = reply['member']['sex'] # Gender
if sex=="secrecy":
sex = ' '
mid = reply['member']['mid'] # uid of account number
sign = reply['member']['sign'] # Label
rpid = reply['rpid'] # Use for second-level Reviews
rcount = reply['rcount'] # Number of replies
level = reply['member']['level_info']['current_level'] # Grade
like = reply['like'] # Point Ratio
content = reply['content']['message'].replace("\n","") # Comments
t = reply['ctime']
timeArray = time.localtime(t)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) # Comment time, timestamp to standard time format
# If it is a secondary comment, the first data returned is "Reply", otherwise it is a building
# Second-level comments have no number of responses rcount, third-level comments are shown as replies xxx @ Who Who Who Who Who Who Who Who Who Who Who Who Who Who Who Who Who Who
if count:
return [count, name, sex, level, mid, sign, otherStyleTime, content, like, rcount, rpid]
else:
return ["Reply", name, sex, level, mid, sign, otherStyleTime, content, like, ' ', rpid]
3. Data Storage
Data storage chooses two ways to be secure: csv and mysql databases
1,csv:
With the csv module, while True reads the queue elements repeatedly. If no data comes in for 10 seconds, the crawl is over, or the program is dead. Whether it crawls back or stumbles, it dies
import csv
def csv_writeIn(self, BV):
file = open("bilibili comment_"+BV+".csv", "w", encoding="utf-8", newline="")
f = csv.writer(file)
line1 = ['floor', 'Full name', 'Gender', 'Grade', 'uid', 'Personal Signature', 'Comment Time', 'Comments', 'Point Ratio', 'Number of replies', 'rpid']
f.writerow(line1)
file.flush()
while True:
try:
line = self.q.get(timeout=10)
except:
break
f.writerow(line)
file.flush()
file.close()Execute and open the csv file
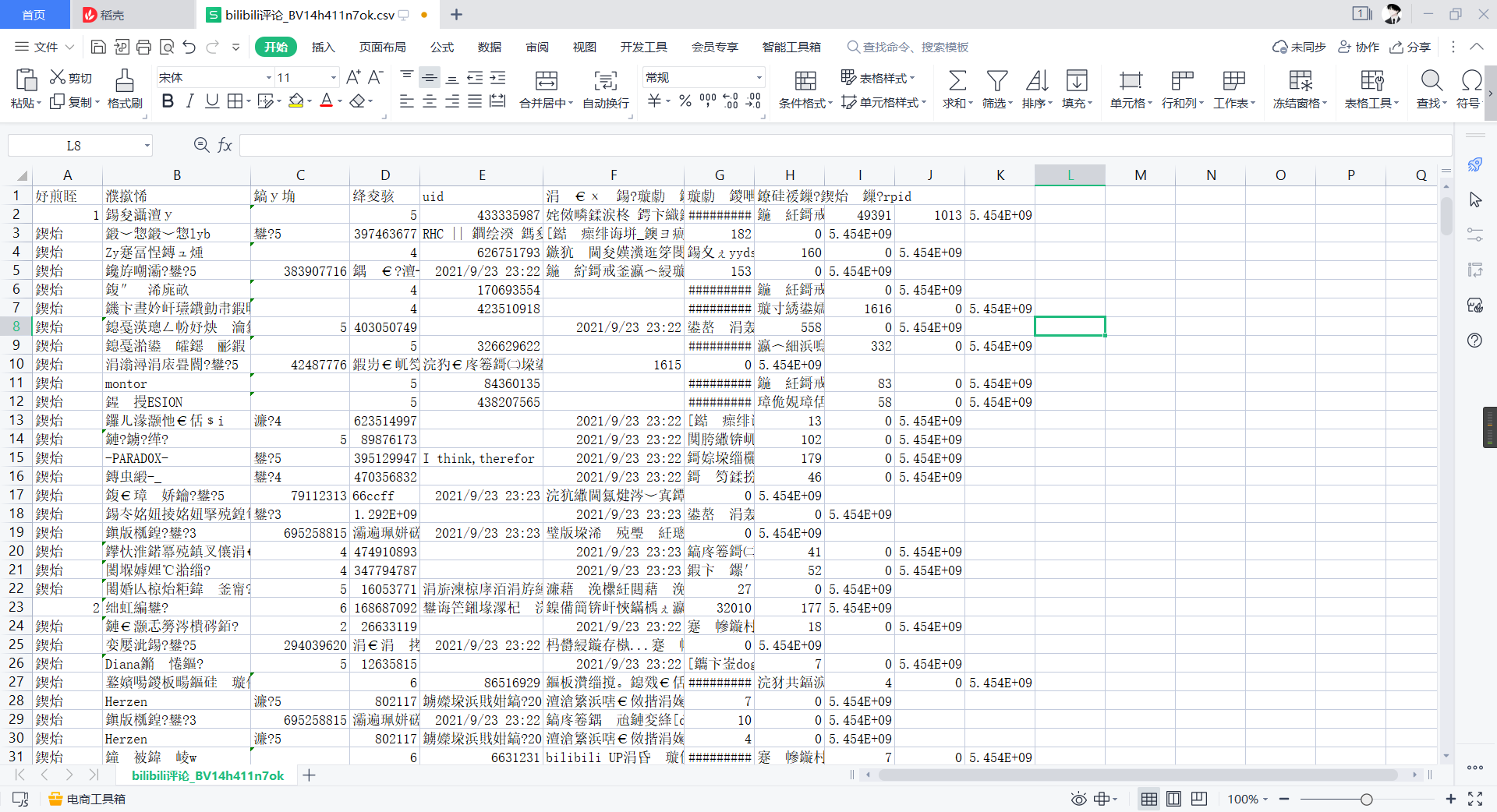
We found that CSV is scrambled. This is because csv's default open encoding method is ANSI and we store it in utf-8
At this point we can choose to open it with Notepad, save it as ANSI encoding, and open it with csv
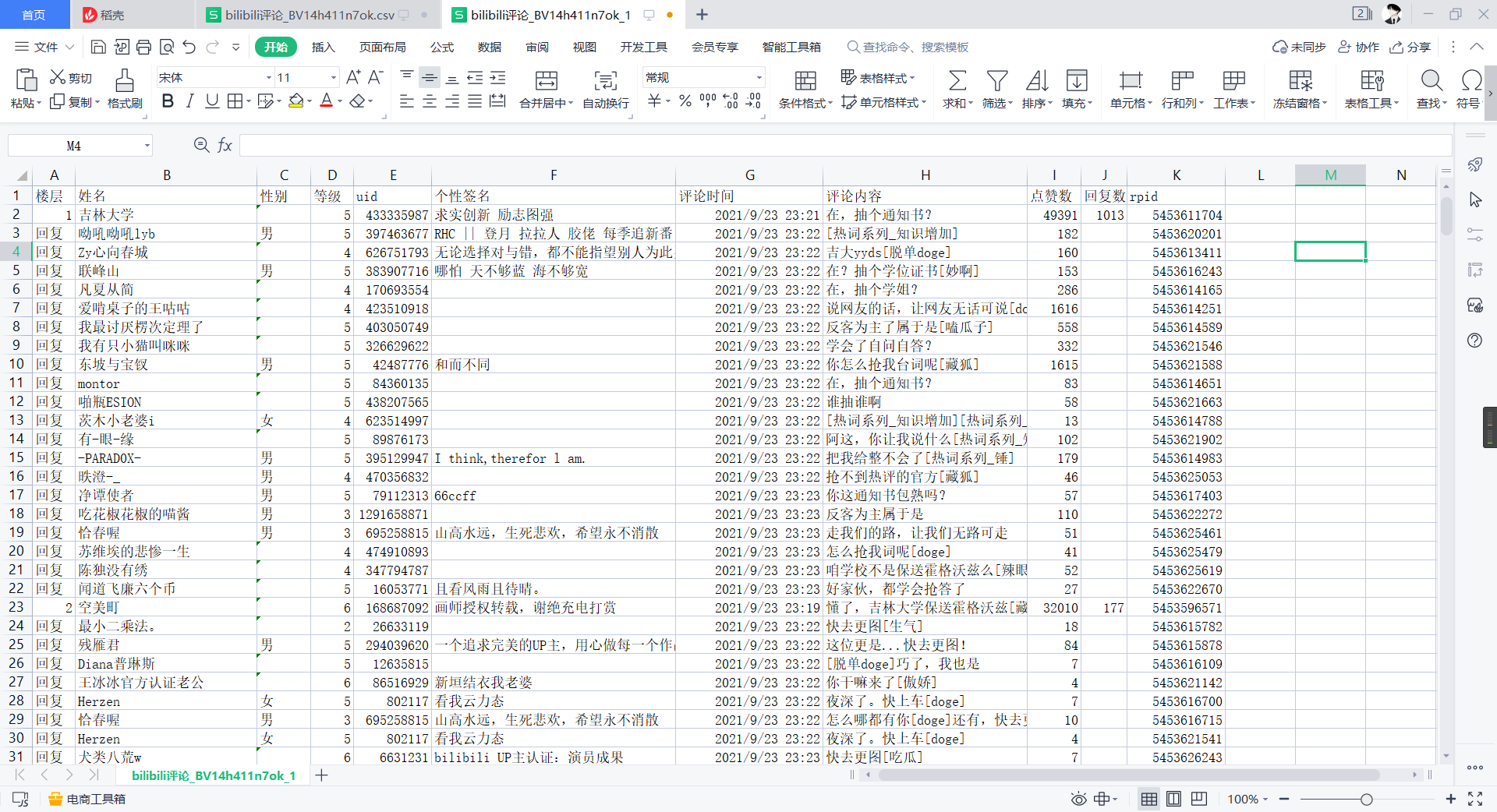
2,mysql
import pymysql as pysql
def mysql_connect(self, host, user, password, BV):
# Connect to the database and exit the program if it fails
try:
self.conn = pysql.connect(host=host, user=user, password=password)
self.cursor = self.conn.cursor()
except:
print("mysql connect error ... ")
exit(1)
# Create libraries, create tables
self.cursor.execute('create database if not exists bilibili')
self.cursor.execute('use bilibili')
sql = '''
create table if not exists {BV} (
floor char(6),
name char(20),
sex char(2),
level char(1),
uid char(10),
sign char(100),
time char(23),
content char(100),
star char(6),
reply char(6),
rpid char(10))
'''
self.cursor.execute(sql.format(BV=BV)) # Create table with video BV number
def mysql_writeIn(self, BV):
sql = '''insert into BV
(`floor`, `name`, `sex`, `level`, `uid`, `sign`, `time`, `content`, `star`, `reply`, `rpid`) value
("{floor}", "{name}", "{sex}", "{level}", "{uid}", "{sign}", "{t}", "{content}", "{star}", "{reply}", "{rpid}")'''
sql = sql.replace('BV', BV)
# Writing to the table with another thread failed to set timeout and quit.
while True:
try:
line = self.q.get(timeout=10)
except:
self.conn.close()
break
# Since the length of the data is fixed, there may be situations where it is too long to write in. Here, take care of one when creating a table, depending on your actual needs. It's too long to do that.
try:
self.cursor.execute(sql.format(floor=line[0], name=line[1], sex=line[2], level=line[3], \
uid=line[4], sign=line[5], t=line[6], content=line[7], \
star=line[8], reply=line[9], rpid=line[10]))
except Exception as e:
print(e)
continue
# Remember to submit or leave blank
self.conn.commit()4. Multithreaded
* We need to call the above sections through functions. Multithreaded Here we use the Thread class of the threading module to construct
Modules are called by the main function.
from threading import Thread
def main(self, page, BV):
self.mysql_connect(host='localhost', user='root', password='SpiderXbest', BV=BV)
T = []
T.append(Thread(target=self.content_get, args=(self.replyUrl, page)))
T.append(Thread(target=self.mysql_writeIn, args=(BV, )))
# T.append(Thread(target=self.csv_writeIn, args=(BV, )))
# Either csv or mysql
print("Start crawling...")
for t in T:
t.start()
for t in T:
t.join()5. Comprehensive.
if __name__ == '__main__':
cookie = "fingerprint=cdc14f481fb201fec2035d743ff230b; buvid_fp=DE7C7303-E24E-462C-B112-EE78EB55C45B148824infoc; buvid_fp_plain=1BC352F4-4DB9-D82C-44A2-FB17273D240infoc; b_ut=-1; i-wann-go-back=-1; _uuid=43C8466C-79D5-F07A-032C-F6EF1635706854601infoc; buvid3=DE703-E24E-462C-B112-EE78EB55C45B148824infoc; CURRENT_FNVAL=80; blackside_state=1; sid=7wo01l; rpdid=|(u)mmY|~YJ|0J'uYJklJ~ul|; CURRENT_QUALITY=112; PVID=4; bfe_id=cade759d3229a3973a5d4e9161f3bc; innersign=1"
cookies = {}
for c in cookie.split(";"):
b = c.split("=")
cookies[b[0]] = b[1]
BV = 'BV14h411n7ok'
bilibili = Bilibili(BV, 0, cookies, 1)
bilibili.main(1, BV)When passing a cookie, it is best to turn it into a dictionary format.
Run the program, try climbing a page
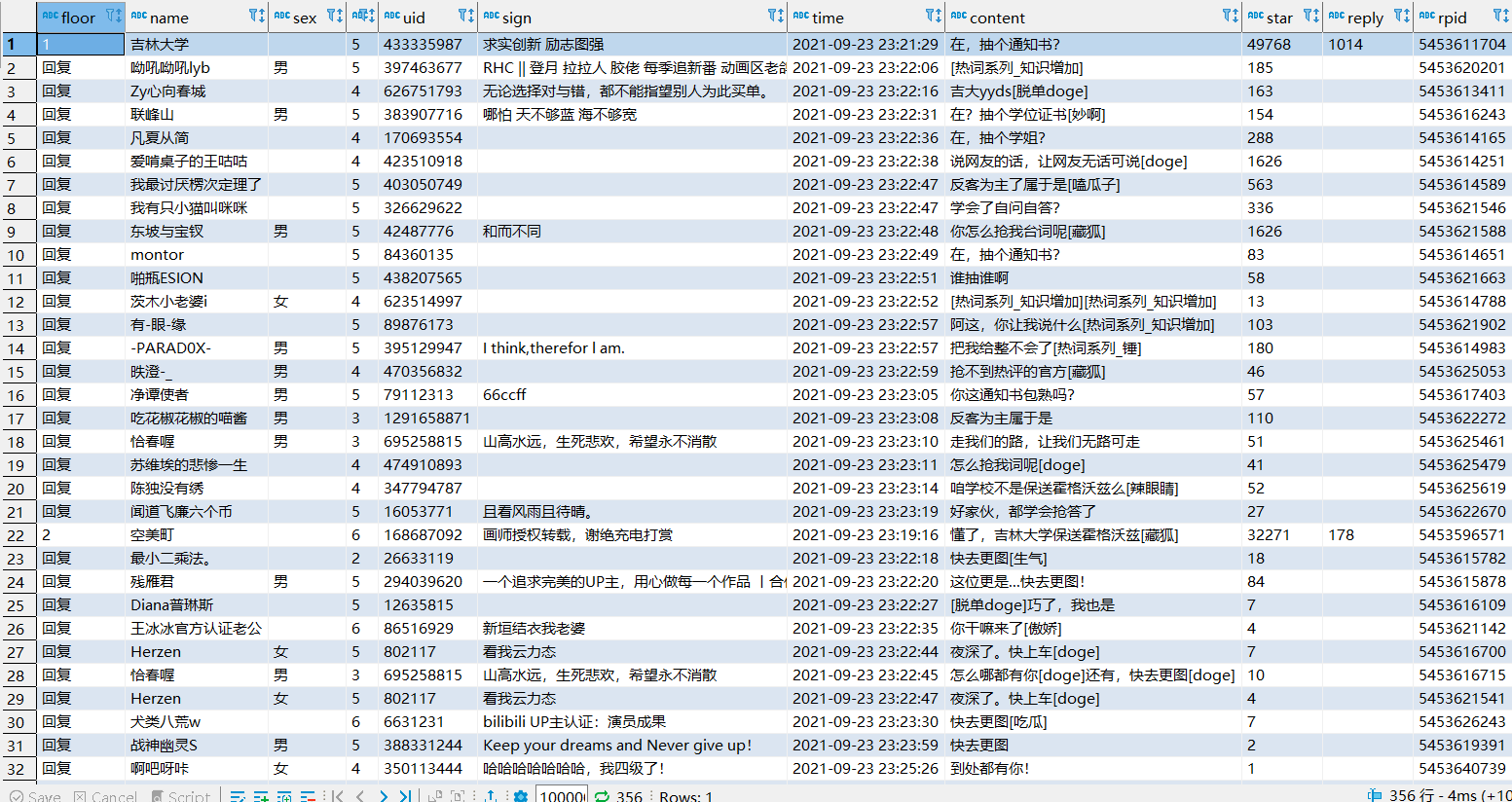
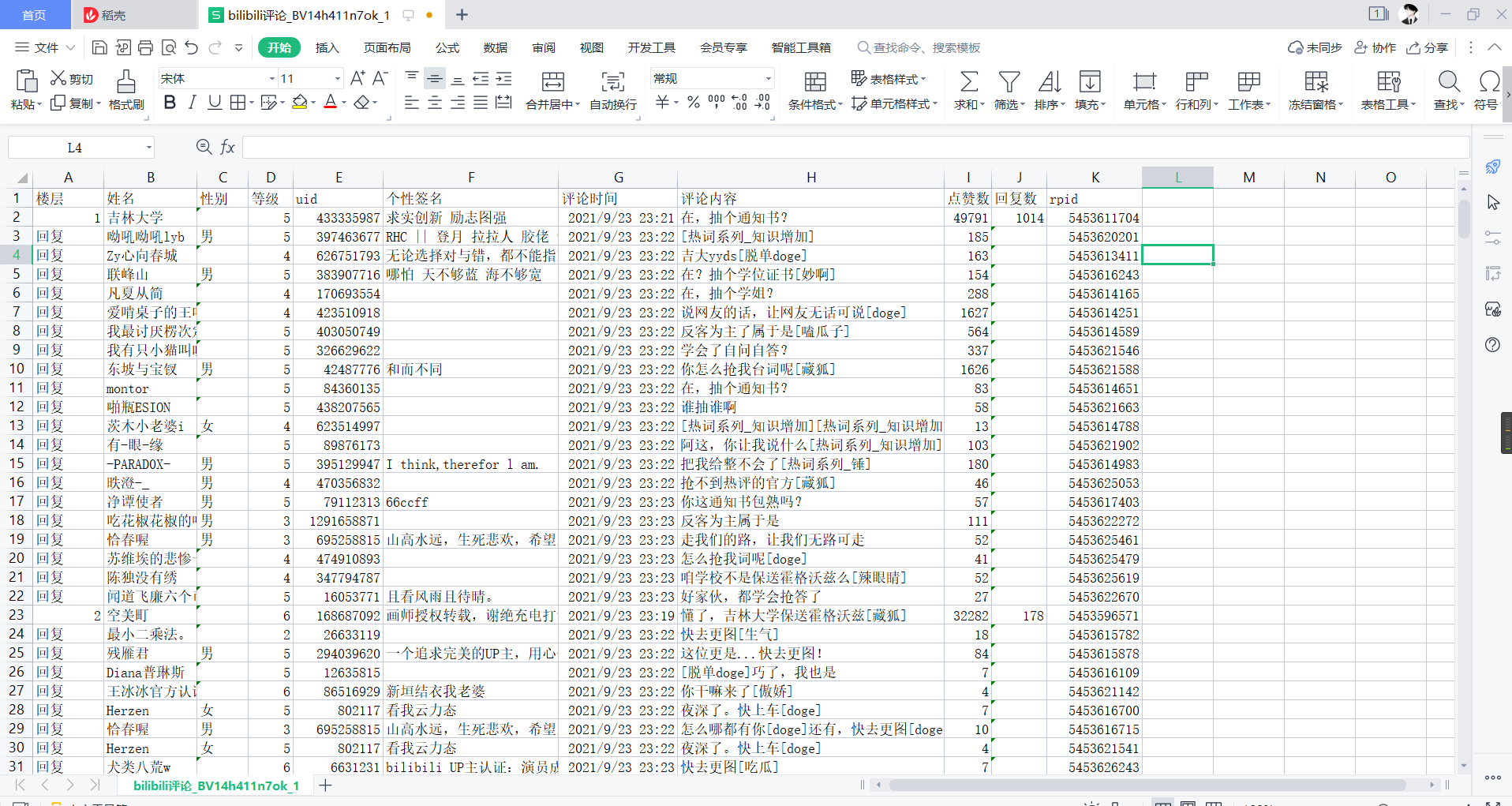
ok, we just crawled one page and only got a maximum of 20 distracted replies. How many pages does a video have? We request a Level 1 comment url in our browser to see it
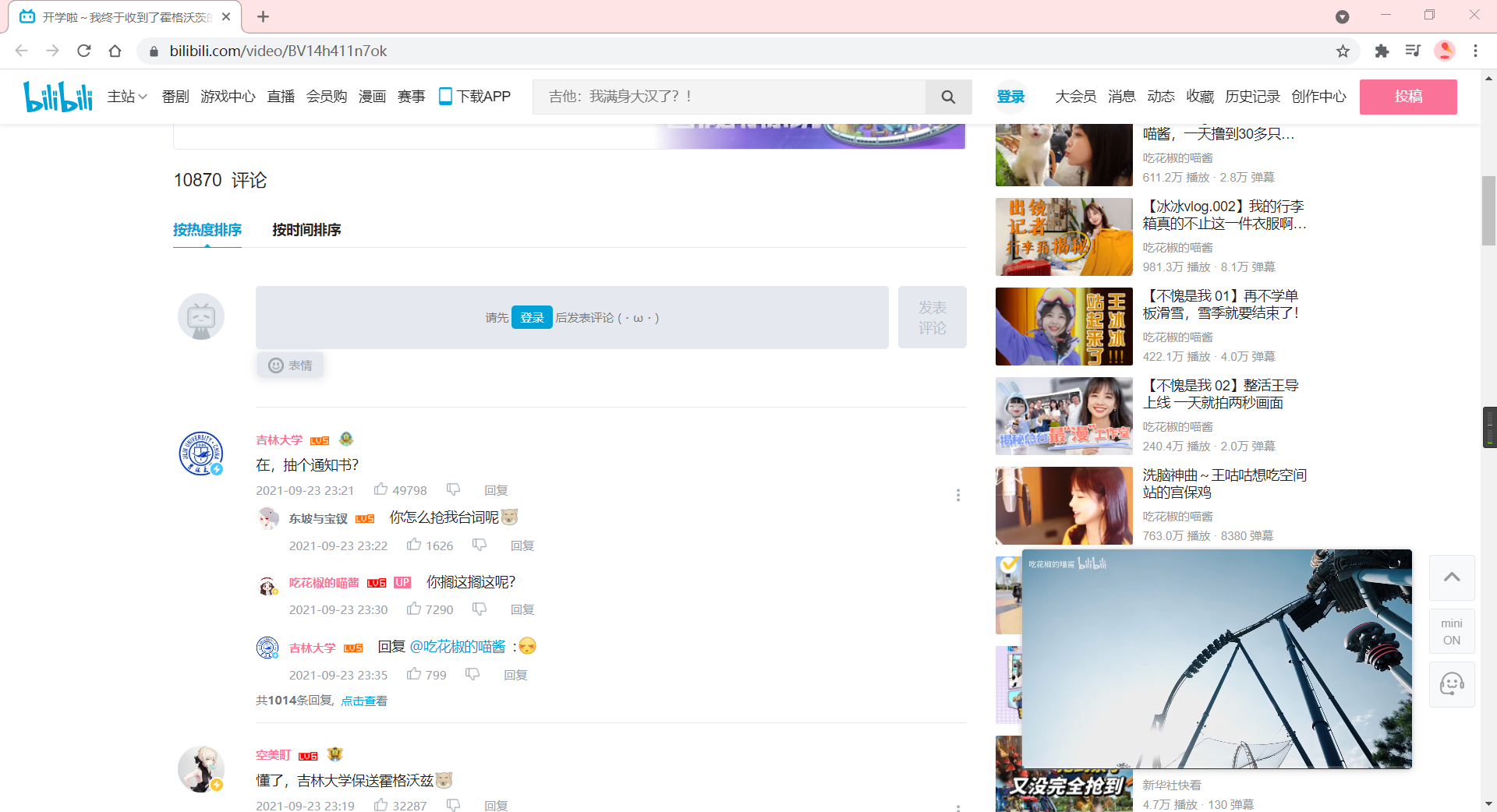
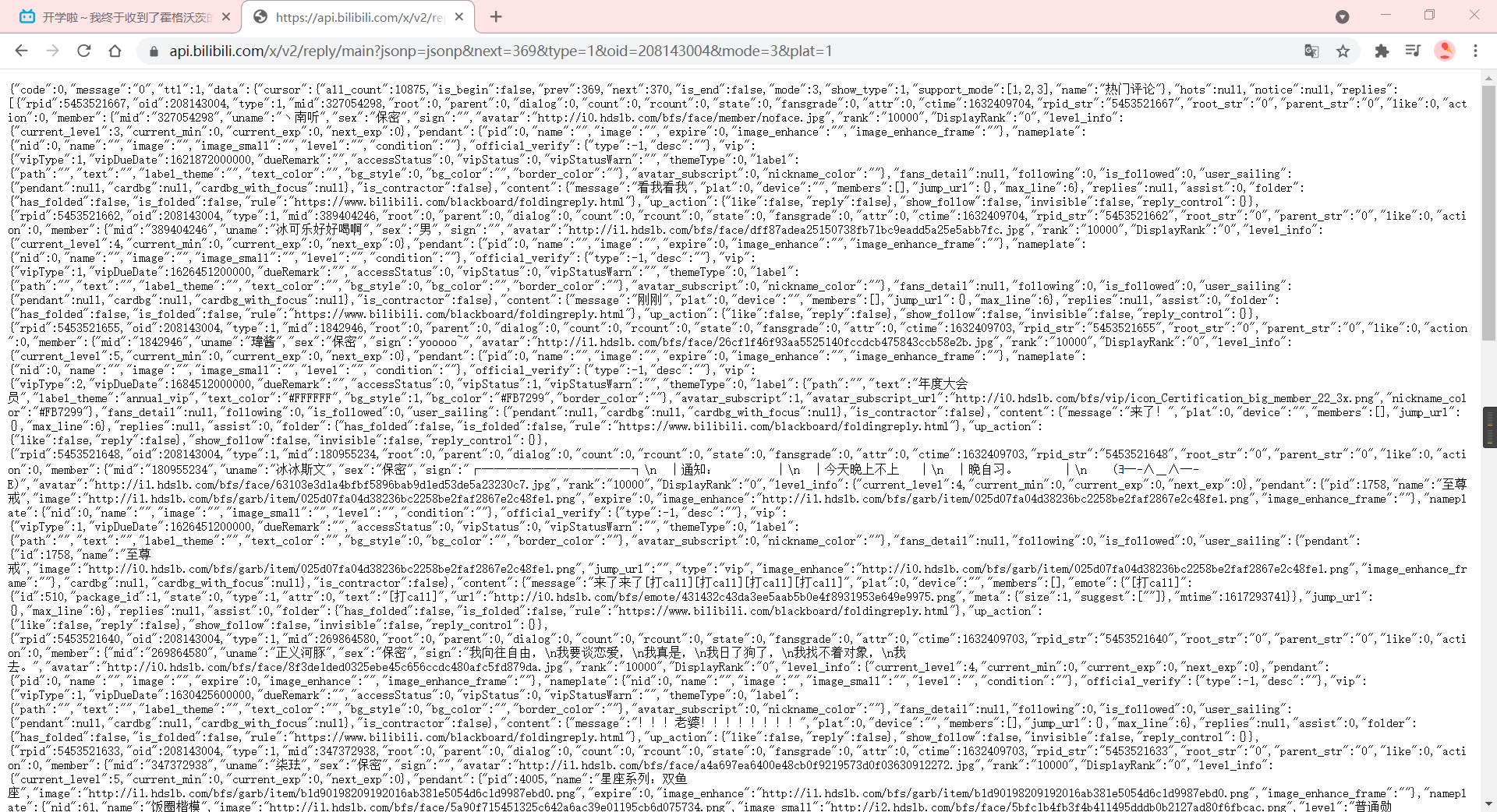
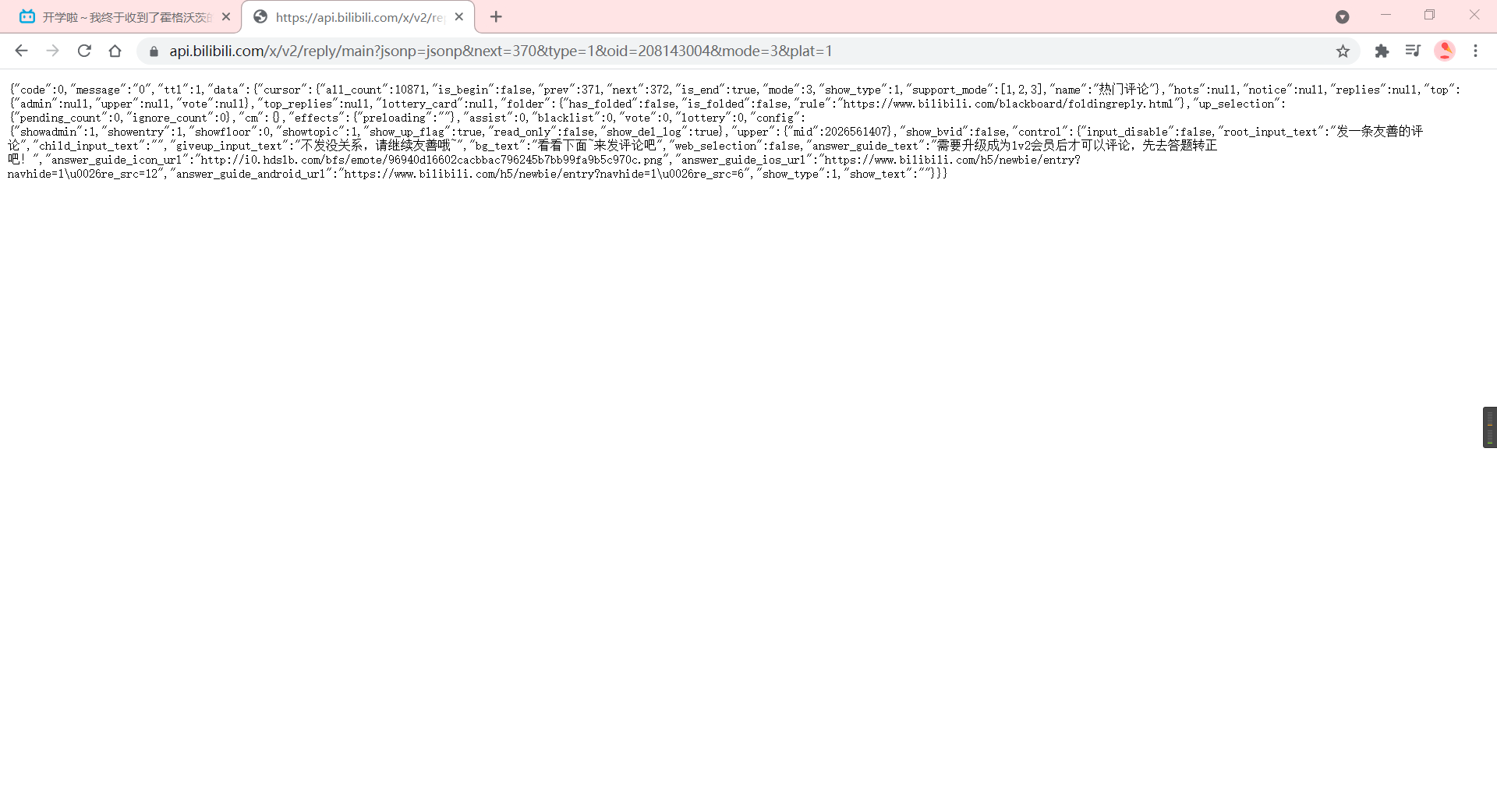
This video has over 10,000 comments and will not move until 370 pages, so we can manually dichotomize to see how many pages there are, or write a judgment function that ends when the replies of the request function content_get are null.
6. Complete Code
# -- coding: utf-8 --
# Author: Bamboo one
# Time : 2021/9/25 10:37
# version : 1.0
# Software: PyCharm
import requests
import re
import time
from fake_useragent import UserAgent
import queue
import csv
import pymysql as pysql
from threading import Thread
class Bilibili:
def __init__(self, BV, mode, cookies, page):
self.homeUrl = "https://www.bilibili.com/video/"
self.oid_get(BV)
self.replyUrl = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&type=1&oid={oid}&mode={mode}&plat=1&next=".format(oid=self.oid, mode=mode)
self.rreplyUrl = "https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&type=1&oid={oid}&ps=20&root={root}&pn=".format(oid=self.oid, root="{root}")
self.headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"}
self.cookies = cookies
self.q = queue.Queue()
self.count = 1
# Get video oid
def oid_get(self, BV):
response = requests.get(url=self.homeUrl + BV).text
# Regular expression gets oid from video bv number
self.oid = re.findall("\"aid\":([0-9]*),", response)[0]
# Is level_1 a first-level comment
def content_get(self, url, page, level_1=True):
now = 0
while now<=page:
if level_1:
print("page : <{now}>/<{page}>".format(now=now, page=page))
response = requests.get(url=url+str(now), cookies=self.cookies, headers=self.headers).json()
replies = response['data']['replies'] # There are 20 reviews in data->replies
now += 1
for reply in replies:
if level_1:
line = self.reply_clean(reply, self.count)
self.count += 1
else:
line = self.reply_clean(reply)
self.q.put(line)
# Here we can filter if there are secondary comments, call functions to request secondary comments
if level_1==True and line[-2] != 0:
self.content_get(url=self.rreplyUrl.format(root=str(line[-1])), page=int(line[-2]/20+0.5), level_1=False) # Recursively get secondary comments
# This function can crawl either a level 1 comment or a level 2 comment
def reply_clean(self, reply, count=False):
name = reply['member']['uname'] # Name
sex = reply['member']['sex'] # Gender
if sex=="secrecy":
sex = ' '
mid = reply['member']['mid'] # uid of account number
sign = reply['member']['sign'] # Label
rpid = reply['rpid'] # Use for second-level Reviews
rcount = reply['rcount'] # Number of replies
level = reply['member']['level_info']['current_level'] # Grade
like = reply['like'] # Point Ratio
content = reply['content']['message'].replace("\n","") # Comments
t = reply['ctime']
timeArray = time.localtime(t)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) # Comment time, timestamp to standard time format
if count:
return [count, name, sex, level, mid, sign, otherStyleTime, content, like, rcount, rpid]
else:
return ["Reply", name, sex, level, mid, sign, otherStyleTime, content, like, ' ', rpid]
def csv_writeIn(self, BV):
print("csv In file data store......")
file = open("bilibili comment_"+BV+".csv", "w", encoding="utf-8", newline="")
f = csv.writer(file)
line1 = ['floor', 'Full name', 'Gender', 'Grade', 'uid', 'Personal Signature', 'Comment Time', 'Comments', 'Point Ratio', 'Number of replies', 'rpid']
f.writerow(line1)
file.flush()
while True:
try:
line = self.q.get(timeout=10)
except:
break
f.writerow(line)
file.flush()
file.close()
def mysql_connect(self, host, user, password, BV):
try:
self.conn = pysql.connect(host=host, user=user, password=password)
self.cursor = self.conn.cursor()
print("mysql Database connection successful!")
except:
print("mysql connect error ... ")
exit(1)
self.cursor.execute('create database if not exists bilibili')
self.cursor.execute('use bilibili')
sql = '''
create table if not exists {BV} (
floor char(5),
name char(20),
sex char(2),
level char(1),
uid char(10),
sign char(100),
time char(23),
content char(100),
star char(6),
reply char(6),
rpid char(10))
'''
self.cursor.execute(sql.format(BV=BV))
def mysql_writeIn(self, BV):
print("mysql In data store ...")
sql = '''insert into BV
(`floor`, `name`, `sex`, `level`, `uid`, `sign`, `time`, `content`, `star`, `reply`, `rpid`) value
("{floor}", "{name}", "{sex}", "{level}", "{uid}", "{sign}", "{t}", "{content}", "{star}", "{reply}", "{rpid}")'''
sql = sql.replace('BV', BV)
while True:
try:
line = self.q.get(timeout=10)
except:
self.conn.close()
break
try:
self.cursor.execute(sql.format(floor=line[0], name=line[1], sex=line[2], level=line[3], \
uid=line[4], sign=line[5], t=line[6], content=line[7], \
star=line[8], reply=line[9], rpid=line[10]))
except Exception as e:
print(e)
continue
self.conn.commit()
def main(self, page, BV, host, user, password):
self.mysql_connect(host=host, user=user, password=password, BV=BV)
T = []
T.append(Thread(target=self.content_get, args=(self.replyUrl, page)))
T.append(Thread(target=self.mysql_writeIn, args=(BV, )))
# T.append(Thread(target=self.csv_writeIn, args=(BV, )))
print("Start crawling...")
for t in T:
t.start()
for t in T:
t.join()
if __name__ == '__main__':
cookie = "fingerprint=cdc14f4281201fec2035d743ff230b; buvid_fp=DE7C73-E24E-462C-B112-EE78EB55C45B148824infoc; buvid_fp_plain=1BC3F4-4DB9-D82C-44A2-FB17273DB52757240infoc; b_ut=-1; i-wanna-go-back=-1; _uuid=4C8466C-79D5-F07A-032C-F6EF1635706854601infoc; buvid3=DE7C7303-E24E-462C-B112-EE78EB545B148824infoc; CURRENT_FNVAL=80; blackside_state=1; sid=7w6ao01l; rpdid=|(u)mmY|~YJ|0J'uYJklJ~ul|; CURRENT_QUALITY=112; PVID=4; bfe_id=cade757b9d3223973a5d4e9161f3bc; innersign=1"
cookies = {}
for c in cookie.split(";"):
b = c.split("=")
cookies[b[0]] = b[1]
BV = 'BV14h411n7ok'
host = host # host name
user = user # User name
password = password # Password
bilibili = Bilibili(BV, 0, cookies, 369)
bilibili.main(369, BV)