Requests request is to simulate a browser request with python's requests module and return html source code
There are two types of simulated browser requests, one that does not require user login or authentication, and the other that requires user login or authentication.
1. Requests that do not require user login or authentication
This is a simple way to get html source code by sending a request directly using the requests module
#!/usr/bin/env python # -*- coding:utf8 -*- import requests #Import Simulated Browser Request Module http =requests.get(url="http://www.iqiyi.com/") #Send http request http.encoding = "utf-8" #http request encoding neir = http.text #Get http string code print(neir)
Get html source
I don't know what to add to my learning
python learning communication deduction qun, 784758214
There are good learning video tutorials, development tools and e-books in the group.
Share with you the current talent needs of the python enterprise and how to learn Python from a zero-based perspective, and what to learn
<!DOCTYPE html>
<html>
<head>
<title>Drawer New Hot List-Aggregate Daily Hot, Funny, Funny Information </title>
<meta charset="utf-8" />
<meta name="keywords" content="New drawer hot list, information, paragraphs, pictures, unsuitable for public places, technology, news, rhythm, funny"/>
<meta name="description" content="
Drawer New Hot List, a collection of daily jokes, hot pictures, interesting news.It aggregates a huge amount of content from microblogs, portals, communities, bbs, social networking sites, and generates the hottest lists through user recommendations.Look at the new hot list of drawers and get a good view of the hot and interesting information every day.
" />
<meta name="robots" content="index,follow" />
<meta name="GOOGLEBOT" content="index,follow" />
<meta name="Author" content="Funny"/>
<meta http-equiv="X-UA-Compatible" content="IE=EmulateIE8">
<link type="image/x-icon" href="/images/chouti.ico" rel="icon"/>
<link type="image/x-icon" href="/images/chouti.ico" rel="Shortcut Icon"/>
<link type="image/x-icon" href="/images/chouti.ico" rel="bookmark"/>
<link type="application/opensearchdescription+xml"
href="opensearch.xml" title="new drawer hot list" rel="search"/>2. Requests requiring user login or authentication
When getting this kind of page, we first need to know the whole login process. Generally, the login process is that when the user first visits, the cookie file is automatically generated in the browser. When the user enters the login information, the cookie file is generated with the user. If the login information is correct, the cookie will be generated for the user.
Authorization, after authorization, you can bring authorized cookie s when you visit pages that need to be logged in later
1. First visit the home page and see if there are auto-generated cookie s
#!/usr/bin/env python
# -*- coding:utf8 -*-
import requests #Import Simulated Browser Request Module
### 1. Visit the home page to get cookie s before you log in
i1 = requests.get(
url="http://dig.chouti.com/",
headers={'Referer': 'http://dig.chouti.com/'}
)
i1.encoding = "utf-8" #http request encoding
i1_cookie = i1.cookies.get_dict()
print(i1_cookie) #Return the obtained cookie
#Return: {'JSESSIONID':'aaaTztKP-KaGLbX-T6R0v','gpsd':'c227f059746c839a28ab136060fe6ebe','route':'f8b4f4a95eeeb2efcff5fd5e417b8319'}You can see that a cookie has been generated, indicating that if the login information is correct, the background will authorize the cookie here, and later visit the page that needs to be logged in with the authorized cookie.
2. Let the program login to authorized cookie s automatically
First, we use our browser to access the login page, randomly enter the login password and account, get the url of the login page, and the fields needed for login
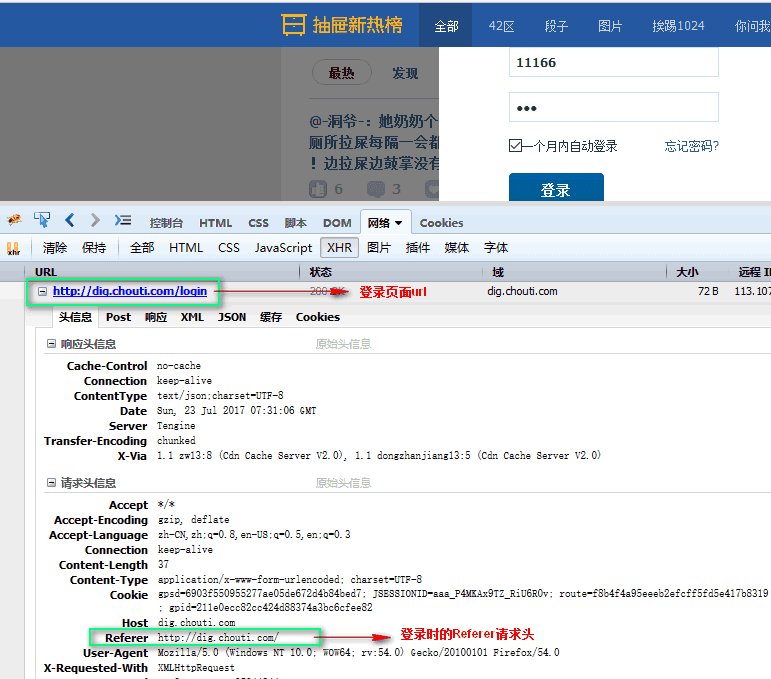
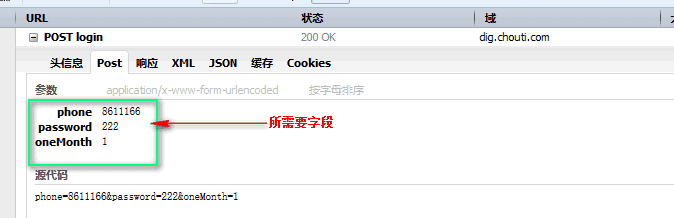
Log on authorization with cookie s
#!/usr/bin/env python
# -*- coding:utf8 -*-
import requests #Import Simulated Browser Request Module
### 1. Visit the home page to get cookie s before you log in
i1 = requests.get(
url="http://dig.chouti.com/",
headers={'Referer':'http://dig.chouti.com/'}
)
i1.encoding = "utf-8" #http request encoding
i1_cookie = i1.cookies.get_dict()
print(i1_cookie) #Return the obtained cookie
#Return: {'JSESSIONID':'aaaTztKP-KaGLbX-T6R0v','gpsd':'c227f059746c839a28ab136060fe6ebe','route':'f8b4f4a95eeeb2efcff5fd5e417b8319'}
### 2. The user logs on, carries the last cookie, and authorizes the random characters in the cookie behind the scenes
i2 = requests.post(
url="http://dig.chouti.com/login ", #login url
data={ #Logon field
'phone': "8615284816568",
'password': "279819",
'oneMonth': ""
},
headers={'Referer':'http://dig.chouti.com/'},
cookies=i1_cookie #Carry cookie s
)
i2.encoding = "utf-8"
dluxxi = i2.text
print(dluxxi) #View the response from the server after login
#Return: {result": {code": {9999","message":"","data": {complateReg": {0","destJid":"cdu_50072007463"}} Sign in successfully3. After successful login, it means that the background has authorized the cookie so that when we visit the page that needs to be logged in, we can just carry the cookie, such as getting a personal Center
#!/usr/bin/env python
# -*- coding:utf8 -*-
import requests #Import Simulated Browser Request Module
### 1. Visit the home page to get cookie s before you log in
i1 = requests.get(
url="http://dig.chouti.com/",
headers={'Referer':'http://dig.chouti.com/'}
)
i1.encoding = "utf-8" #http request encoding
i1_cookie = i1.cookies.get_dict()
print(i1_cookie) #Return the obtained cookie
#Return: {'JSESSIONID':'aaaTztKP-KaGLbX-T6R0v','gpsd':'c227f059746c839a28ab136060fe6ebe','route':'f8b4f4a95eeeb2efcff5fd5e417b8319'}
### 2. The user logs on, carries the last cookie, and authorizes the random characters in the cookie behind the scenes
i2 = requests.post(
url="http://dig.chouti.com/login ", #login url
data={ #Logon field
'phone': "8615284816568",
'password': "279819",
'oneMonth': ""
},
headers={'Referer':'http://dig.chouti.com/'},
cookies=i1_cookie #Carry cookie s
)
i2.encoding = "utf-8"
dluxxi = i2.text
print(dluxxi) #View the response from the server after login
#Return: {result": {code": {9999","message":"","data": {complateReg": {0","destJid":"cdu_50072007463"}} Sign in successfully
### 3. Access pages that require login to view and access with authorized cookie s
shouquan_cookie = i1_cookie
i3 = requests.get(
url="http://dig.chouti.com/user/link/saved/1",
headers={'Referer':'http://dig.chouti.com/'},
cookies=shouquan_cookie #Access with authorized cookie s
)
i3.encoding = "utf-8"
print(i3.text) #View pages that require login to view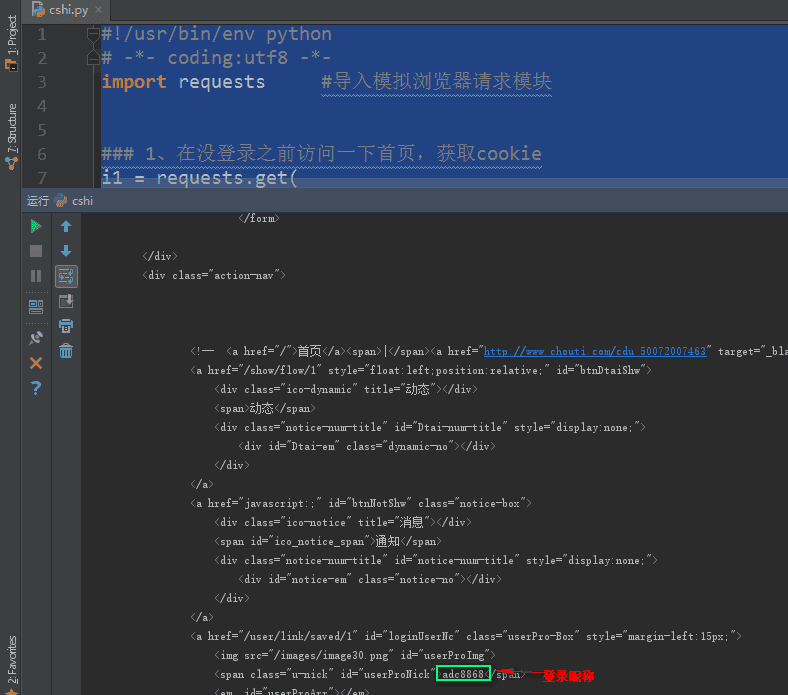
Getting html source for login page is successful
All Code
get() method, send get request
Encoding property, set request encoding
cookies.get_dict() Get cookies
post() Send a post request
text Gets Server Response Information
#!/usr/bin/env python
# -*- coding:utf8 -*-
import requests #Import Simulated Browser Request Module
### 1. Visit the home page to get cookie s before you log in
i1 = requests.get(
url="http://dig.chouti.com/",
headers={'Referer':'http://dig.chouti.com/'}
)
i1.encoding = "utf-8" #http request encoding
i1_cookie = i1.cookies.get_dict()
print(i1_cookie) #Return the obtained cookie
#Return: {'JSESSIONID':'aaaTztKP-KaGLbX-T6R0v','gpsd':'c227f059746c839a28ab136060fe6ebe','route':'f8b4f4a95eeeb2efcff5fd5e417b8319'}
### 2. The user logs on, carries the last cookie, and authorizes the random characters in the cookie behind the scenes
i2 = requests.post(
url="http://dig.chouti.com/login ", #login url
data={ #Logon field
'phone': "8615284816568",
'password': "279819",
'oneMonth': ""
},
headers={'Referer':'http://dig.chouti.com/'},
cookies=i1_cookie #Carry cookie s
)
i2.encoding = "utf-8"
dluxxi = i2.text
print(dluxxi) #View the response from the server after login
#Return: {result": {code": {9999","message":"","data": {complateReg": {0","destJid":"cdu_50072007463"}} Sign in successfully
### 3. Access pages that require login to view and access with authorized cookie s
shouquan_cookie = i1_cookie
i3 = requests.get(
url="http://dig.chouti.com/user/link/saved/1",
headers={'Referer':'http://dig.chouti.com/'},
cookies=shouquan_cookie #Access with authorized cookie s
)
i3.encoding = "utf-8"
print(i3.text) #View pages that require login to viewIf you are still confused in the world of programming, you can join us in Python learning to deduct qun:784758214 and see how our forefathers learned.Exchange experience.From basic Python scripts to web development, crawlers, django, data mining, and so on, zero-based to project actual data are organized.For every Python buddy!Share some learning methods and small details that need attention, Click to join us python learner cluster
Note: If your login requires an Authentication Code, you will need to do image processing, identify the Authentication Code according to the picture of the Authentication Code, and write the Authentication Code to the login field