Web page parsing tool
BS4
Beautiful soup is a Python library that can extract data from HTML or XML files. Its use is more simple and convenient than regular, and can often save us a lot of time.
Official Chinese documents
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
install
pip install beautifulsoup4
Parser
| Parser | usage method | advantage | inferiority |
|---|---|---|---|
| Python standard library | BeautifulSoup(markup, "html.parser") | Python's built-in standard library has moderate execution speed and strong document fault tolerance | Python versions before 2.7.3 or 3.2.2) have poor fault tolerance |
| lxml HTML parser | BeautifulSoup(markup, "lxml") | High speed and strong fault tolerance of documents | C language library needs to be installed |
| lxml XML parser | BeautifulSoup(markup, ["lxml", "xml"])``BeautifulSoup(markup, "xml") | Fast, the only parser that supports XML | C language library needs to be installed |
| html5lib | BeautifulSoup(markup, "html5lib") | The best fault tolerance parses documents in a browser way and generates documents in HTML5 format | Slow, independent of external expansion |
Since this parsing process will affect the speed of the whole crawler system in large-scale crawling, lxml is recommended, which will be much faster, and lxml needs to be installed separately:
pip install lxml soup = BeautifulSoup(html_doc, 'lxml') # appoint
Tip: if the format of an HTML or XML document is incorrect, the results returned in different parsers may be different, so specify a parser.
Node object
Tag
Tag means tag. Tag also has many methods and properties.
NavigableString
BeautifulSoup
Comment
Tag and traversing the document tree
The tag object can be said to be the most important object in the beautiful soup. Extracting data through the beautiful soup basically revolves around this object. First, a node can contain multiple child nodes and multiple strings. For example, the HTML node contains the head and body nodes. Therefore, beautiful soup can represent an HTML web page with such a layer of nested nodes.
Basic grammar
from bs4 import BeautifulSoup#Guide Package soup=BeautifulSoup(html_str,'lxml') type(soup) bs4.BeautifulSoup
# coding=utf-8
from bs4 import BeautifulSoup
html_data = """
<html>
<body>
<div id="info">
<span><span class="pl">director</span>: <span class="attrs"><a href="/celebrity/1362276/" rel="v:directedBy">Xing Wenxiong</a></span></span><br>
<span><span class="pl">Screenwriter</span>: <span class="attrs"><a href="/celebrity/1362276/">Xing Wenxiong</a></span></span><br>
<span class="actor"><span class="pl">to star</span>: <span class="attrs"><span><a href="/celebrity/1319032/" rel="v:starring">Mary</a> / </span><span><a href="/celebrity/1355058/" rel="v:starring">Wei Xiang</a> / </span><span><a href="/celebrity/1362567/" rel="v:starring">Chen Minghao</a> / </span><span><a href="/celebrity/1319540/" rel="v:starring">Zhou Dayong</a> / </span><span><a href="/celebrity/1363857/" rel="v:starring">Huang Cailun</a> / </span><span style="display: none;"><a href="/celebrity/1350408/" rel="v:starring">Allen</a> / </span><span style="display: none;"><a href="/celebrity/1394939/" rel="v:starring">Gao Haibao</a> / </span><span style="display: none;"><a href="/celebrity/1386801/" rel="v:starring">Han Xiao</a> / </span><span style="display: none;"><a href="/celebrity/1444360/" rel="v:starring">Sun Guiquan</a> / </span><span style="display: none;"><a href="/celebrity/1426220/" rel="v:starring">Xu Meng</a> / </span><span style="display: none;"><a href="/celebrity/1467304/" rel="v:starring">Full volume dipper</a> / </span><span style="display: none;"><a href="/celebrity/1467305/" rel="v:starring">Bu junnan</a> / </span><span style="display: none;"><a href="/celebrity/1316008/" rel="v:starring">Zhang Zhizhong</a> / </span><span style="display: none;"><a href="/celebrity/1367242/" rel="v:starring">Zhang Jianxin</a> / </span><span style="display: none;"><a href="/celebrity/1398260/" rel="v:starring">Ma Chi</a> / </span><span style="display: none;"><a href="/celebrity/1353283/" rel="v:starring">Tao Liang</a> / </span><span style="display: none;"><a href="/celebrity/1403276/" rel="v:starring">Gianluca ·Zopa</a></span><a href="javascript:;" class="more-actor" title="More stars">more...</a></span></span><br>
<span class="pl">type:</span> <span property="v:genre">comedy</span><br>
<span class="pl">Producer country/region:</span> Chinese Mainland<br>
<span class="pl">language:</span> Mandarin Chinese<br>
<span class="pl">Release date:</span> <span property="v:initialReleaseDate" content="2022-02-01(Chinese Mainland)">2022-02-01(Chinese Mainland)</span><br>
<span class="pl">Film length:</span> <span property="v:runtime" content="109">109 minute</span><br>
<span class="pl">also called:</span> Too Cool To Kill<br>
<span class="pl">IMDb:</span> tt16254308<br>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_data, "lxml")
print(soup.span.text, type(soup.span.text))
print(soup.a.string, type(soup.a.string))
# Progeny label
body = soup.body
# The first way
# print(list(body.children))
# The second way
# print(body.contents)
# Descendant label
# tags_des = body.descendants
# print(list(tags_des))
# Label brother
span = body.span
# print(list(span.next_siblings))
# Parent label
p_parent = span.parent
print(p_parent)
1.find_all
The method of accessing attributes directly through attributes can only be applied to some relatively simple scenarios, so beautiful soup also provides a method of searching the entire document tree, find_all().
-
name, find_all('b ') can directly find all B tags in the whole document tree and return to the list
-
Through attribute search, it is not enough for us to search only by tag name, because there may be many tags with the same name, so we need to search by tag attribute at this time. At this time, we can search for attributes by passing attrs a dictionary parameter. soup.find_all(attrs={'class': 'sister'})
-
Through text search, in find_ In the all () method, you can also search according to the text content. soup.find_all(text="Elsie")
-
Limit the search scope to child node find_ The all () method will search for all descendant nodes by default. If the recursive parameter is set to false, the search scope can be limited to the direct child nodes. soup.html.find_all("title", recursive=False)
-
The regular expression is used to filter the search results. In beautiful soup, it can also cooperate with re module The object compiled by compile is passed into find_all() method, you can search through regular. tags = soup.find_all(re.compile("^b"))
soup = BeautifulSoup(html_data, "lxml") # html = soup.find_all("html", recursive=False) # print(html[0].find_all("a", recursive=True)) # print(html[0].find_all("a", recursive=False)) p = soup.find_all('div',attrs={'id':"info"}) print(p[0].find_all("span", recursive=False))# No recursive query, only child elements will be found, not descendants
2.CSS selector
In beautiful soup, CSS selectors are also supported for searching. Use select() to pass in the string parameter, and you can use the syntax of CSS selector to find the tag.
soup = BeautifulSoup(html_data, "lxml")
print(soup.select("span>a"))
Xpath
brief introduction
Xpath is a language for finding information in XML documents. Xpath can be used to traverse elements and attributes in XML documents. Compared with beautiful soup, Xpath is more efficient in extracting data.
install
pip install lxml
grammar
Select the path in the XML / XPath node. Nodes are selected along the path or step.
The most useful path expressions are listed below:


from .items from ..per //div/p[@class="box"]
predicate
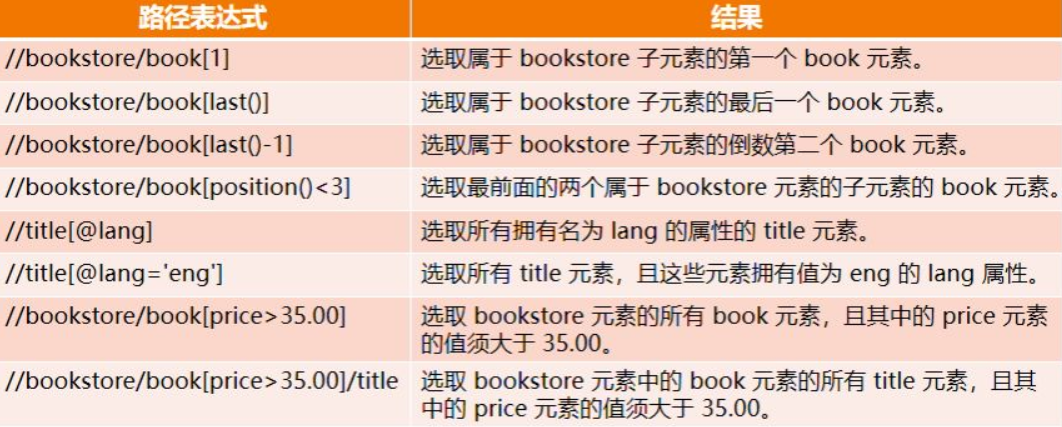
The predicate is used to find a specific node or some specific nodes or nodes containing a specified value. The predicate is embedded in square brackets. In the following table, we list some path expressions with predicates and the results of the expressions. example:
<book><price value=50>/<title>
Select unknown node
XPath wildcards can be used to pick unknown nodes
| wildcard | describe | Expression |
|---|---|---|
| * | Matches any element node. | //book/* |
| @* | Matches any attribute node. | //book[@*] |
| node() | Match any type of node | node() |
Select multiple paths
You can select several paths by using the "|" operator in the path expression. In the following table, some path expressions and the results of these expressions are listed:
Get the text under the node
Use text() to get the text under a node, and use string() to get all the text under a node.
<a>i love you <span>you love me</span></a> /a/text() i love you /a/string() i love you you love me