1. grab all the files of a official account.
Charles + wechat for computer + pycharm+python
2. Analysis
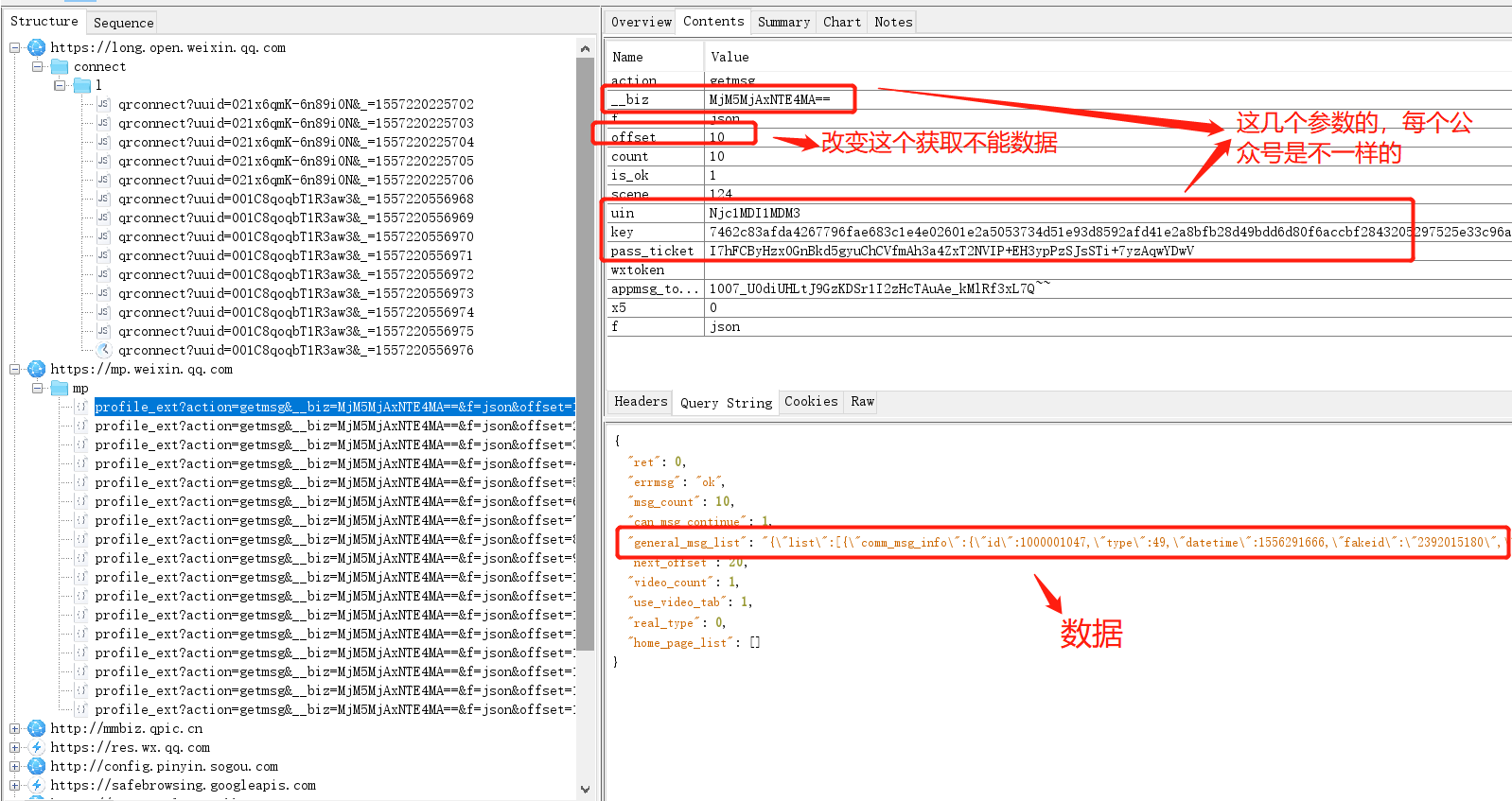
After analysis: every official account list page is connected.
At the beginning of https://mp.weixin.qq.com/mp/profile_ext, only a few references to each official account are taken at the time of grasping.
Grab:
3. Code
import requests import json import time def parse(__biz, uin, key, pass_ticket, appmsg_token="", offset="0"): """ //Article information acquisition """ url = 'https://mp.weixin.qq.com/mp/profile_ext' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400", } params = { "action": "getmsg", "__biz": __biz, "f": "json", "offset": str(offset), "count": "10", "is_ok": "1", "scene": "124", "uin": uin, "key": key, "pass_ticket": pass_ticket, "wxtoken": "", "appmsg_token": appmsg_token, "x5": "0", } res = requests.get(url, headers=headers, params=params, timeout=3) data = json.loads(res.text) print(data) # Get information list msg_list = eval(data.get("general_msg_list")).get("list", []) for i in msg_list: # Remove text links try: # Article title title = i["app_msg_ext_info"]["title"].replace(',', ',') # Article summary digest = i["app_msg_ext_info"]["digest"].replace(',', ',') # Article links url = i["app_msg_ext_info"]["content_url"].replace("\\", "").replace("http", "https") # Article release time date = i["comm_msg_info"]["datetime"] print(title, digest, url, date) with open('article.csv', 'a') as f: f.write(title + ',' + digest + ',' + url + ',' + str(date) + '\n') except: pass # Judge whether page 1 can be continued-Can page 0-It's all over if 1 == data.get("can_msg_continue", 0): time.sleep(3) parse(__biz, uin, key, pass_ticket, appmsg_token, data["next_offset"]) else: print("Crawling completed") if __name__ == '__main__': # Request parameters __biz = input('biz: ') uin = input('uin: ') key = input('key: ') pass_ticket = input('passtick: ') # analytic function parse(__biz, uin, key, pass_ticket, appmsg_token="", offset="0")
By grasping the parameters of __biz, UIN, key and pass_ticket of different official account, we can complete the official account.
Note: before running the program, after obtaining the required parameters with the package grabbing tool, you need to close the charles or fiddle package grabbing tool first, and then run the program, otherwise an error will be reported. (this program needs to be crawled after the wechat on the computer is logged in. If the simulator is used, the uni and key parameters on the simulator are different from those on the computer, and the general request cannot succeed!)