The summary is taken from Mr. Gao GitHub
https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/MobileNetV1_CIFAR10.ipynb
https://github.com/OUCTheoryGroup/colab_demo/blob/master/202003_models/MobileNetV2_CIFAR10.ipynb
MobileNet v1
The core of Mobilenet v1 is to split the convolution into two parts: epthwise+Pointwise.
Depthwise processes a three channel image using 3 × The convolution kernel of 3 is completely carried out on the two-dimensional plane. The number of convolution kernels is the same as the number of input channels, so three feature map s will be generated after operation. The parameters of convolution are: 3 × three × 3 = 27, as follows:
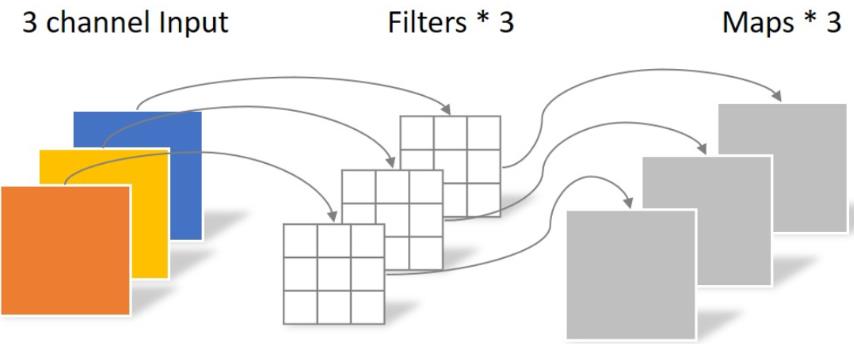
Pointwise differs in that the size of the convolution kernel is 1 × one × k. K is the number of input channels. Therefore, the convolution operation here will weight and fuse the feature maps of the previous layer. There are several feature maps with several filter s. The number of parameters is: 1 × one × three × 4 = 12, as shown in the figure below:
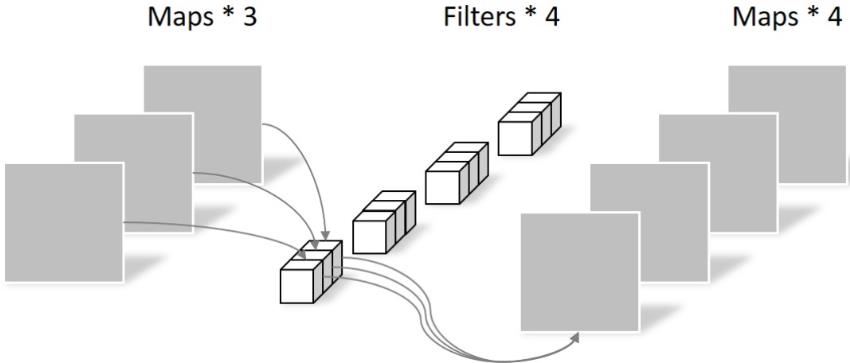
Therefore, it can be seen that the number of parameters can be greatly reduced by using Depthwise+Pointwise to obtain four feature map s.
MobileNet v2
Main problems of MobileNet V1: The structure is very simple, but the residual learning in RestNet is not used; On the other hand, Depthwise Conv does greatly reduce the amount of computation, but in practice, it is found that many trained kernel s are empty.
The first major change of MobileNet V2: an Inverted residual block is designed
MobileNet V2 first uses 1x1 convolution to increase the number of channels, then uses Depthwise 3x3 convolution, and then uses 1x1 convolution to reduce the dimension. The author calls it an Inverted residual block, which is wide in the middle and narrow on both sides.
The second major change of MobileNet V2: remove the ReLU6 in the output part
ReLU6 is used in MobileNet V1. ReLU6 is an ordinary ReLU, but the maximum output value is limited to 6. This is to have a good numerical resolution when the mobile terminal device float16/int8 has low precision. The output of Depthwise is relatively shallow, and the application of ReLU will cause information loss, so ReLU is removed at the end.
HybridSN
Code of hyperspectral classification network HybridSN class:
#Define HybridSN class
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN,self).__init__()
#3d convolution
self.conv3d_1=nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.conv3d_2=nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3= nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
#Two dimensional convolution
self.conv2d= nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
#Full connection layer
self.fc1=nn.Linear(18496,256)
self.fc2=nn.Linear(256,128)
self.fc3=nn.Linear(128,16)
self.dropout=nn.Dropout(p=0.4)
def forward(self,x):
out=self.conv3d_1(x)
out=self.conv3d_2(out)
out=self.conv3d_3(out)
out=self.conv2d(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out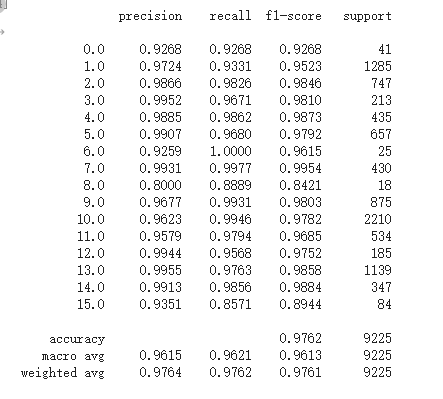
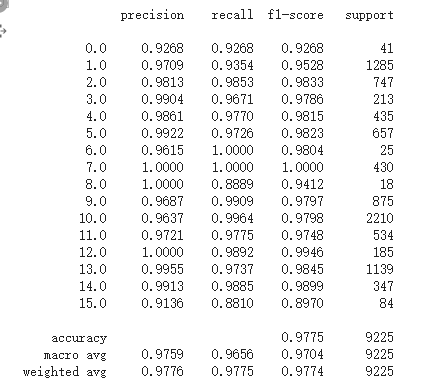
The possible reason for the different classification results each time is that the neural network algorithm initializes the random weight, so using the same data training will get different results.