task
Under Windows 10 system, based on "saving each frame of video as an image" in web5 with python and Jupiter notebook, the similarity of the ordered series of pictures is calculated through two methods: user-defined mean hash algorithm and each channel histogram, and the pictures with a gap greater than a certain value are selected and saved to judge the number of shots of the original video.
ffmpeg is used to intercept segments in long video, convert them into images, and estimate the number of shots.
I mean hash algorithm
Import the required libraries.
os and shutil libraries are used to assist each other in creating, deleting and traversing files or folders.
os.remove(r "fill in the file path"): delete the file (use with caution. If you make a mistake, the file will not be found)
os.makedirs("./p"): create a new folder p under the current working path
os.listdir("./p"): traverse the files in the p folder and return the list of files in the folder OS. Removediers (". / p"): delete the empty folder p under the current working path (the folder must be empty, otherwise an error will be reported)
shutil.rmtree("./p",ignore_errors=True) # deletes the folder. It can also be deleted if it is not empty
import cv2 import numpy as np import matplotlib.pyplot as plt from PIL import Image import inspect import os import shutil
Define a function to convert an image expression:
Change the picture specification to 8 * 8 and convert it to grayscale image
Traverse each grid of picture 8 * 8, and overlay the pixels of each grid to find its mean value
Traverse each grid of the picture 8 * 8, and judge the size of the pixel value and the mean value. If it is greater than the mean value, it returns 1, and if it is less than the mean value, it returns 0. Finally, a 64 bit binary number is obtained
Color image img[i,j,c]: i represents the number of rows of the picture, j represents the number of columns of the picture, and c represents the number of channels of the picture (RGB three channels correspond to 0, 1 and 2 respectively). The coordinates start at the upper left corner.
Grayscale image gray[i,j]: returns the pixel value in row i and column j of the image
def aHash(img):
#Zoom to 8x8
"""plt.imshow(img)
plt.axis("off")
plt.show()"""
img=cv2.resize(img,(8,8))
"""plt.imshow(img)
plt.axis("off")
plt.show()"""
#Convert to grayscale
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#s is the pixel and the initial value is 0, hash_ STR is the hash value, and the initial value is' '
s=0
hash_str=""
#Ergodic accumulation for pixel sum
for i in range(8):
for j in range(8):
s=s+gray[i,j]
#Gray average
avg=s/64
#The gray level is greater than the average value of 1. On the contrary, it is 0 to generate the hash value of the picture
for i in range(8):
for j in range(8):
if gray[i,j]>avg:
hash_str=hash_str+"1"
else:
hash_str=hash_str+"0"
return hash_strDefine the function, compare the difference between the two image expressions, and get the size of the image difference. The greater the return value gap, the greater the difference
If statement, if the hash lengths of the two figures are different, return - 1, indicating an error in parameter transmission
for loop, traverse each bit of 64 bit binary number of two images to judge the difference. If it is different, gap+1 indicates that the difference is greater
def cmpHash(hash1,hash2):
gap=0
#If the hash length is different, - 1 is returned, indicating an error in parameter transmission
if len(hash1)!=len(hash2):
return -1
for i in range(len(hash1)):
if hash1[i]!=hash2[i]:
gap=gap+1
return gapDelete the folder named P under the current working path and generate an empty folder p to prevent the files in the folder from being confused due to multiple runs of the same code
Traverse the folder that holds the ordered series of images pic
Save the first picture with the same name in folder pic to folder p
shutil.rmtree("./p",ignore_errors=True)
os.makedirs("./p")
filelist=os.listdir("./pic")
cv2.imwrite(os.path.join("./p",filelist[0]),img1)Method 1: when traversing and comparing, the two adjacent images are not compared, but when the two adjacent images are sufficiently similar, the left image remains unchanged, and the right image traverses from the first image. Compare the two images until the similarity is too low, save the right image, and replace the current right image with the left image, and the right image continues to traverse until the traversal is completed.
for i in range(len(filelist)-1):
img2=cv2.imread("./pic/"+"image{}".format(i+1)+".jpg")
gap=cmpHash(aHash(img1),aHash(img2))
if gap>35:
cv2.imwrite(os.path.join("./p","image{}".format(i+1)+".jpg"),img2)
img1_name="image{}".format(i+1)
img1=cv2.imread("./pic/"+"image{}".format(i+1)+".jpg")Operation results: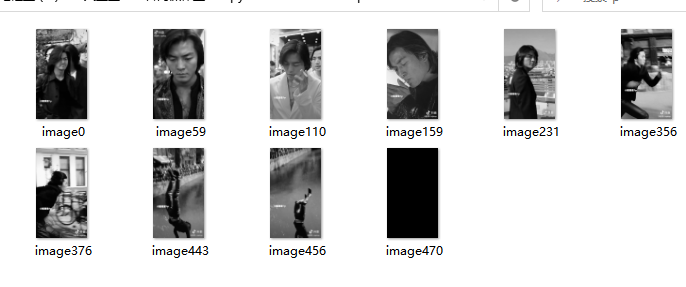
Method 2: traverse the pictures and compare two adjacent pictures each time. If the difference is too large, save the right picture
for i in range(len(filelist)-1):
img1=cv2.imread("./pic/image{}.jpg".format(i))
img2=cv2.imread("./pic/image{}.jpg".format(i+1))
gap=cmpHash(aHash(img1),aHash(img2))
if gap>23:
cv2.imwrite(os.path.join("./p/image{}.jpg".format(i+1)),img2) Operation results:
From the practical situation of the two judgment methods, the former is more unstable, the number of recognized shots (i.e. the number of saved pictures) does not completely decrease with the increase of the set gap critical value, and when the number of saved pictures of the latter two is close, the gap critical value of the former is often greater
Full code:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
import inspect
import shutil
def aHash(img):
img=cv2.resize(img,(8,8))
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
s=0
hash_str=""
for i in range(8):
for j in range(8):
s=s+gray[i,j]
avg=s/64
for i in range(8):
for j in range(8):
if gray[i,j]>avg:
hash_str=hash_str+"1"
else:
hash_str=hash_str+"0"
return hash_str
def cmpHash(hash1,hash2):
gap=0
if len(hash1)!=len(hash2):
return -1
for i in range(len(hash1)):
if hash1[i]!=hash2[i]:
gap=gap+1
return gap
shutil.rmtree("./p",ignore_errors=True)
os.makedirs("./p")
filelist=os.listdir("./pic")
cv2.imwrite(os.path.join("./p",filelist[0]),img1)
"""for i in range(len(filelist)-1):
img2=cv2.imread("./pic/"+"image{}".format(i+1)+".jpg")
gap=cmpHash(aHash(img1),aHash(img2))
if gap>35:
cv2.imwrite(os.path.join("./p","image{}".format(i+1)+".jpg"),img2)
img1_name="image{}".format(i+1)
img1=cv2.imread("./pic/"+"image{}".format(i+1)+".jpg")"""
for i in range(len(filelist)-1):
img1=cv2.imread("./pic/image{}.jpg".format(i))
img2=cv2.imread("./pic/image{}.jpg".format(i+1))
gap=cmpHash(aHash(img1),aHash(img2))
if gap>23:
cv2.imwrite(os.path.join("./p/image{}.jpg".format(i+1)),img2)
Ⅱ calculation of histogram similarity of each channel
Import required libraries
import cv2 import numpy as np import matplotlib.pyplot as plt import os import shutil
Define the function, change the image specification, and separate the RGB three channels
zip() The function is used to take the iteratable object as a parameter, package the corresponding elements in the object into tuples, and then return a list composed of these tuples.
cv2.split(): split the channel, input the image matrix array, and output the three-dimensional matrix array split into each point in the order of BGR color
cv2.merge(): merge channels
calculate(a,b) is the function defined later to calculate the histogram coincidence degree of each channel. The greater the value, the higher the coincidence degree
Calculate the average of the coincidence degree of each channel to obtain the complete similarity
def classify_hist_with_split(image1,image2,size=(256, 256)):
# After resizing the image, it is separated into three RGB channels, and then the similarity value of each channel is calculated
image1=cv2.resize(image1,size)
image2=cv2.resize(image2,size)
# plt.imshow(image1)
# plt.show()
# plt.axis('off')
# plt.imshow(image2)
# plt.show()
# plt.axis('off')
sub_image1=cv2.split(image1)
sub_image2=cv2.split(image2)
sub_data=0
for im1,im2 in zip(sub_image1,sub_image2):
sub_data+=calculate(im1,im2)
sub_data=sub_data/3
return sub_dataDefine a function to calculate the similarity value of the histogram of a single channel
CV2. Calchist (images, channels, mask, histsize, ranges [, hist [, aggregate]]) - > hist images: input images channels: select the color channel of the image Mask: Mask (mask, mask) is an np array with the same size as image, in which the part to be processed is specified as 1 and the part not to be processed is specified as 0. Generally, it is set to None, indicating that the whole image is processed histSize: how many bins (columns) are used, usually 256 ranges: the range of pixel values, generally [0255], representing 0 ~ 255
abs(): return absolute value
def calculate(image1, image2):
hist1=cv2.calcHist([image1],[0],None,[256],[0.0,255.0])
hist2=cv2.calcHist([image2],[0],None,[256],[0.0,255.0])
# plt.plot(hist1,color="r")
# plt.plot(hist2,color="g")
# plt.show()
# Calculate the coincidence degree of histogram
degree=0
for i in range(len(hist1)):
if hist1[i]!=hist2[i]:
degree=degree+(1-abs(hist1[i]-hist2[i])/max(hist1[i],hist2[i]))
else:
degree=degree+1 #Statistical similarity
degree=degree/len(hist1)
return degreeTwo practical methods similar to mean hash algorithm
filelist=os.listdir("./pic")
print(type(filelist))
print(len(filelist))
shutil.rmtree("./pp",ignore_errors=True)#Delete a folder, or a non empty folder
os.makedirs("./pp")
a=range(len(filelist)-1)
cv2.imwrite(os.path.join("./pp",filelist[0]),img1)
"""#When traversing the comparison, it is not the comparison of two adjacent pictures, but when the two adjacent pictures are similar enough, the first picture remains unchanged, the second picture is postponed, and the two pictures continue to be compared
for i in a:
img2=cv2.imread("./pic/"+"image{}".format(i+1)+".jpg")
#print(img1_name,"image{}".format(i+1),sep=",")
n=classify_hist_with_split(img1, img2)
#print(n)
if n<0.42:
cv2.imwrite(os.path.join("./pp","image{}".format(i+1)+".jpg"),img2)
#img1_name="image{}".format(i+1)
img1=cv2.imread("./pic/"+"image{}".format(i+1)+".jpg")"""
for i in a:
img1=cv2.imread("./pic/image{}.jpg".format(i))
img2=cv2.imread("./pic/image{}.jpg".format(i+1))
n=classify_hist_with_split(img1, img2)
if n<0.55:
cv2.imwrite(os.path.join("./pp/image{}.jpg".format(i+1)),img2)It is worth noting that: for the results of the mean hash algorithm, the larger the gap is, the larger the gap is; for the results of histogram similarity, the larger the n is, the larger the similarity is, the smaller the gap is. The numerical range of the results of the two algorithms is also different, the former is ≥ 1 integer level, and the latter is ≤ 1 decimal level.
III. video clip intercepted by ffmpeg
Open the command prompt cmd in the directory where the ffmpeg program is located and enter the following code (two pieces of code to intercept two pieces of video):
-i input path
-ss start time
-t duration (Note: non end time)
The output path is written directly without - starting with a letter
ffmpeg -i G:/vip film/Let the bullet fly/Let the bullet fly.mp4 -ss 01:54:17 -t 00:00:18 G:/Junior/Homework of each course/python/week6/out1.mp4
ffmpeg -i G:/vip film/Let the bullet fly/Let the bullet fly.mp4 -ss 01:18:00 -t 00:00:18 G:/Junior/Homework of each course/python/week6/out2.mp4
After the video is cut, enter the following code in the command prompt:
Convert each frame of the two videos into an image in the order of image1, image2... (Note: the first image is not image0)
The reason why the absolute path is not written here is that the ffmpeg program location is in the same directory as the out1 and out2 folders (these two folders must be created in advance. Ffmpeg does not provide automatic creation function, but only reports an error)
ffmpeg -i out2.mp4 -r 10 -f image2 out2/image%d.jpg
ffmpeg -i out1.mp4 -r 10 -f image2 out1/image%d.jpg
The two videos have different contents and the subsequent processing logic is the same, so out1 is used as an example.
The naming of series pictures starts from image1, which is different from the code written earlier. By default, it starts from image0. You can modify the naming of series pictures for operation. You can choose to modify the previous code. Here, take modifying the naming of pictures as an example.
filelist=os.listdir("./out1")
for i in range(len(filelist)):
infile="./out1/image{}.jpg".format(i+1)
outfile="./out1/image{}.jpg".format(i)
Image.open(infile).save(outfile)
os.remove(infile)Full code:
#Mean hash algorithm, histogram comparison of each channel, and renaming of a series of files
import cv2
import numpy as np
import matplotlib.pyplot as plt
import os
import shutil
#Mean hash algorithm
def aHash(img):
img=cv2.resize(img,(8,8))
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
s=0
hash_str=""
for i in range(8):
for j in range(8):
s=s+gray[i,j]
avg=s/64
for i in range(8):
for j in range(8):
if gray[i,j]>avg:
hash_str=hash_str+"1"
else:
hash_str=hash_str+"0"
return hash_str
def cmpHash(hash1,hash2):
n=0
if len(hash1)!=len(hash2):
return -1
for i in range(len(hash1)):
if hash1[i]!=hash2[i]:
n=n+1
return n
# The similarity is calculated by obtaining the histogram of each RGB channel
def classify_hist_with_split(image1,image2,size=(256, 256)):
# After resizing the image, it is separated into three RGB channels, and then the similarity value of each channel is calculated
image1=cv2.resize(image1,size)
image2=cv2.resize(image2,size)
sub_image1=cv2.split(image1)
sub_image2=cv2.split(image2)
sub_data=0
for im1,im2 in zip(sub_image1,sub_image2):
sub_data+=calculate(im1,im2)
sub_data=sub_data/3
return sub_data
# Calculate the similarity value of histogram of single channel
def calculate(image1, image2):
hist1=cv2.calcHist([image1],[0],None,[256],[0,255])
hist2=cv2.calcHist([image2],[0],None,[256],[0,255])
# Calculate the coincidence degree of histogram
degree=0
for i in range(len(hist1)):
if hist1[i]!=hist2[i]:
degree=degree+(1-abs(hist1[i]-hist2[i])/max(hist1[i],hist2[i]))
else:
degree=degree+1 #Statistical similarity
degree=degree/len(hist1)
return degree
#Renaming series files started from image1, but now it starts from image0
filelist=os.listdir("./out1")
for i in range(len(filelist)):
infile="./out1/image{}.jpg".format(i+1)
outfile="./out1/image{}.jpg".format(i)
Image.open(infile).save(outfile)
os.remove(infile)
shutil.rmtree("./out1p",ignore_errors=True)
os.makedirs("./out1p")
cv2.imwrite(os.path.join("./out1p/image0.jpg"),cv2.imread("./out1/image0.jpg"))
#Operation results of mean hash algorithm
for i in range(len(filelist)-1):
img1=cv2.imread("./out1/image{}.jpg".format(i))
img2=cv2.imread("./out1/image{}.jpg".format(i+1))
gap=cmpHash(aHash(img1),aHash(img2))
if gap>30:
cv2.imwrite(os.path.join("./out1p/image{}.jpg".format(i+1)),img2)
#Practical operation results of calculating similarity by histogram of each channel
shutil.rmtree("./out1pp",ignore_errors=True)
os.makedirs("./out1pp")
cv2.imwrite(os.path.join("./out1pp/image0.jpg"),cv2.imread("./out1/image0.jpg"))
for i in range(len(filelist)-1):
img1=cv2.imread("./out1/image{}.jpg".format(i))
img2=cv2.imread("./out1/image{}.jpg".format(i+1))
n=classify_hist_with_split(img1, img2)
if n<0.55:
cv2.imwrite(os.path.join("./out1pp/image{}.jpg".format(i+1)),img2)Operation results:
Mean hash algorithm: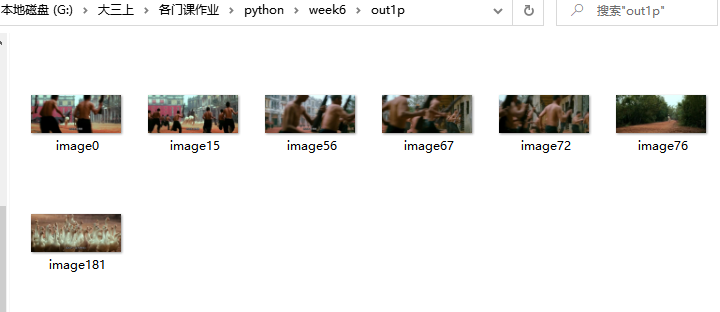
Histogram of each channel: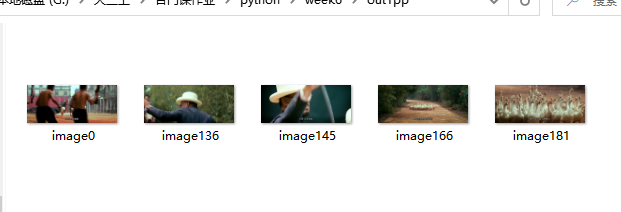
IV. code bug
1. When using two non adjacent pictures to judge the similarity, although the result will not report an error, the saved pictures have been very chaotic.
The right figure is always traversed in order, but the results are displayed in 1, 10100101... 109, 11110111. It can be seen that the logic of traversal order is not the size of numerical value, but the size of ASCII code




for i in range(len(filelist)-1) traversal is theoretically in the order of mantissa from small to large, that is, image0 image1 image2, but in fact, the order is not the same
View filelist:
Therefore, the index of filelist[i] is no longer used in the future, and image{}.jpg".format(i) is used instead